
python机器学习笔记:EM算法
完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等。本文对于EM算法,我们主要从以下三个方向学习:
- 1,最大似然
- 2,EM算法思想及其推导
- 3,GMM(高斯混合模型)
1,最大似然概率
我们经常会从样本观察数据中,找到样本的模型参数。最常用的方法就是极大化模型分布的对数似然函数。怎么理解呢?下面看我一一道来。
假设我们需要调查我们学习的男生和女生的身高分布。你会怎么做啊?你说那么多人不可能一个一个的去问吧,肯定是抽样了。假设你在校园随便捉了100个男生和100个女生。他们共200个人(也就是200个身高的样本数据,为了方便表示,下面我们说的“人”的意思就是对应的身高)都在教室了。那么下一步怎么办?你开始喊:“男的左边,女的右边”,然后就统计抽样得到的100个男生的身高。假设他们的身高是服从高斯分布的。但是这个分布的均值 μ 和方差 σ2 我们不知道,这两个参数就是我们要估计的。记做 θ = [ μ, δ ] T。
用数学的语言来说就是:在学校那么多男生(身高)中,我们独立地按照概率密度 p(x | θ) ,我们知道了是高斯分布 N(μ, δ)的形式,其中的未知参数是 θ = [ μ, δ ] T 。抽到的样本集是 X={X1, X2, X3.....Xn},其中 Xi 表示抽到的第 i 个人的身高,这里的 N 就是100,表示抽到的样本个数。
由于每个样本都是独立地从 p(x | θ) 中抽取的,换句话说这 100 个男生中的任何一个,都是随便抽取的,从我们的角度来看这些男生之间是没有关系的。那么,我们从学习这么多男生中为什么恰好抽到了这 100个人呢?抽到这 100 个人的概率是多少呢?因为这些男生(的身高)是服从同一个高斯分布 p(x | θ)的。那么我们抽到男生A(的身高)的概率是 p(xA | θ),抽到男生B的概率是 p(xB | θ),那因为他们是独立的,所以很明显,我们同时抽到男生A和男生B的概率是 p(xA | θ) * p(xB | θ),同理,我同时抽到这 100 个男生的概率就是他们各自概率的乘积了。用数学家的口吻说就是从分布是 p(x | θ) 的总体样本中抽取到这 100 个样本的概率,也就是样本集 X 中各个样本的联合概率,用下式表示:
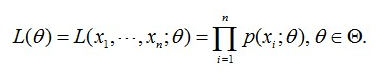
这个概率反映了,在概率密度函数的参数是 θ 时,得到 X 这组样本的概率。因为这里 X 是已知的,也就是说我抽取到这100个人的身高是可以测出来的,也就是已知的。而 θ 是未知的,则上面这个公式只有 θ 是未知的,所以他是关于 θ 的函数。这个函数反映的是在不同的参数 θ 的取值下,取得当前这个样本集的可能性,因此称为参数 θ 相对于样本集 X 的似然函数(likehood function),记为 L(θ)。
这里出现了一个概念,似然函数。还记得我们的目标吗?我们需要在已经抽到这一组样本X的条件下,估计参数 θ 的值。怎么估计呢?似然函数有什么用呢?我们下面先了解一下似然的概念。
直接举个例子:
某位同学与一位猎人一起外出打猎,一只野兔从前方窜过。只听一声枪响,野兔应声倒下,如果要你推测,这一发命中的子弹是谁打的?你就会想,只发一枪便打中,由于猎人命中的概率一般大于这位同学命中的概率,所以这一枪应该是猎人射中的。
这个例子所作的推断就体现了极大似然法的基本思想。下面再说一个最大似然估计的例子。
再例如:假设你去赌场了,但是不知道能不能赚钱,你就在门口堵着出来,出来一个人你就问人家赚钱还是赔钱,如果问了五个人,假设五个人都说自己赚钱了,那么你就会认为,赚钱的概率肯定是非常大的。
从上面两个例子,你得到了什么结论?
总的来说:极大似然估计就是估计模型参数的统计学方法。
回到男生身高的例子。在学校那么多男生中,我一抽就抽到这 100 个男生(表示身高),加入不是其他人,那是不是表示在整个学校中,这 100 个人(的身高)出现的概率最大啊,那么这个概率怎么表示呢?就是上面那个似然函数 L(θ)。所以我们就只需要找到一个参数 θ ,其对应的似然函数 L(θ) 最大,也就是说抽到这 100 个男生(的身高)的概率最大,这个叫做 θ 的最大似然估计量,记为:

有时,可以看到 L(Θ) 是连乘的,所以为了便于分析,还可以定义对数似然函数,将其变为连加的:
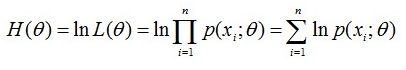
现在我们知道了,要求出 Θ ,只需要使 Θ 的似然函数 L(Θ) 极大化,然后极大值对应的 Θ 就是我们的估计。这里就回到了求最值的问题了。怎么求一个函数的最值?当然是求导,然后令导数为零,那么解这个方程得到的 Θ 就是了(前提是函数L(Θ)连续可微)。那如果 Θ 是包含多个参数的向量,那么如何处理呢?当然是求 L(Θ) 对所有参数的偏导数,也就是梯度了,那么 n 个未知的参数,就有 n 个方程,方程组的解就是似然函数的极值点了,当然就得到了这 n 个参数了。
最后使用PPT整理一下,更直观:


所以,其实最大似然估计你可以把它看做是一个反推。多数情况下我们是根据已知条件来推断结果,而最大似然估计是已经知道了结果,然后寻找使该结果出现的可能性最大的条件,以此作为估计值。比如,如果其他条件一定的话,抽烟者发生肺癌的危险是不抽烟者的五倍,那么如果我们知道有个人是肺癌,我想问你这个人是抽烟还是不抽烟。你如何判断,你可能对这个人一无所知,你所知道的只有一件事,那就是抽烟更容易发生肺癌,那么你会猜测这个人不抽烟吗?我相信你更可能会说,这个人抽烟,为什么?这就是“最大可能”,我只能说他“最有可能”是抽烟的,“他是抽烟的”这一估计才是“最有可能”得到“肺癌” 这样的结果,这就是最大似然估计。
总结一下:极大似然估计,只是概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次实验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆把这个参数作为估计的真实值。
而求最大似然估计值的一般步骤
- 1,写出似然函数
- 2,对似然函数取对数,并整理
- 3,求导数,令导数为0,得到似然方程
- 4,解似然方程,得到的参数即为所求
2,EM算法要解决的问题
上面说到,通过样本观察数据中,找到样本的模型参数。但是在一些情况下,我们得到的观察数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数。怎么办呢?这就是EM算法可以派上用场的地方了。
下面,我们重新回到上面那个身高分布估计的问题。现在,通过抽取得到的那100个男生的身高和已知的其身高服从高斯分布,我们通过最大化其似然函数,就可以得到了对应高斯分布的参数 θ = [ μ, δ ] T 了。那么,对于我们学习的女生的身高分布也可以用同样的方法得到了。
再回到例子本身,如果没有“男的左边,女的右边”这个步骤,或者说这二百个人已经混到一起了,这时候,你从这二百个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个的身高是男生的身高,还是女生的身高。也就是说你不知道抽取的那二百个人里面的每一个人到底是从男生的那个身高分布里面抽取的,还是女生的那个身高分布抽取的。用数学的语言就是:抽取的每个样本都不知道是从那个分布抽取的。
这个时候,对于每一个样本或者你抽取到的人,就有两个东西需要猜测或者估计的了,一是这个人是男生还是女的?二是男生和女生对应的身高的高斯分布的参数是多少?
所以问题就难了。

只有当我们知道了那些人属于同一个高斯分布的时候,我们才能够对这个分布的参数做出靠谱的预测,例如刚开始的最大似然所说的,但现在两种高斯分布的人混在一块了,我们又不知道那些人属于第一个高斯分布,那些人属于第二个,所以就没法估计这两个分布的参数。反过来,只有当我们对这两个分布的参数做出了准确的估计的时候,才能知道到底那些人属于第一个分布,那些人属于第二个分布。
这就成了一个先有鸡还是先有蛋的问题了。鸡说,没有我,谁把你生出来的啊。蛋不服,说,没有我你从哪蹦出来的啊。为了解决这个你依赖我,我依赖你的循环依赖问题,总得有一方要先打破僵局,说,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变换调整我的变换,然后如此迭代着不断互相推导,最终就会收敛到一个解,这就是EM算法的基本思想了。
不知道大家能理解其中的思想吗,然后再举个例子。
例如小时候,老妈给一大袋子糖果给你,叫你和你姐姐等分,然后你懒得去点糖果的个数,所以你也就不知道每个人到底该分多少个,咱们一般怎么做呢?先把一袋糖果目测的分为两袋,然后把两袋糖果拿在左右手,看那个重,如果右手重,那么很明显右手这袋糖果多了,然后你再在右手这袋糖果中抓一把放到左手这袋,然后再感受下那个重,然后再从重的那袋抓一小把放入轻的那一袋,继续下去,直到你感觉两袋糖果差不多相等了为止。然后为了体现公平,你还让你姐姐先选。
EM算法就是这样,假设我们想估计A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM 的意思是“Expectation Maximization”,在我们上面这个问题里面,我们先随便猜一下男生(身高)的正态分布的参数:如均值和方差。例如男生的均值是1米7,方差是 0.1 米(当然了,刚开始肯定没有那么准),然后计算出每个人更可能属于第一个还是第二个正态分布中的(例如,这个人的身高是1米8,那很明显,他最大可能属于男生的那个分布),这个是属于Expectation 一步。有了每个人的归属,或者说我们已经大概地按上面的方法将这 200 个人分为男生和女生两部分,我们就可以根据之前说的最大似然那样,通过这些被大概分为男生的 n 个人来重新估计第一个分布的参数,女生的那个分布同样方法重新估计。这个就是 Maximization。然后,当我们更新了这两个分布的时候,每一个属于这两个分布的概率又变了,那么我们就再需要调整 E 步、.... 如此往复,直到参数基本不再发生变化为止。
这里把每个人(样本)的完整描述看做是三元组 yi = {xi, zi1, zi2},其中, xi 是第 i 个样本的观测值,也就是对应的这个人的身高,是可以观测到的值。zi1和zi2表示男生和女生这两个高斯分布中哪个被用来产生值 xi,就是说这两个值标记这个人到底是男生还是女生(的身高分布产生的)。这两个值我们是不知道的,是隐含变量。确切的说, zij 在 xi 由第 j个高斯分布产生时值为1,否则为0。例如一个样本的观测值为 1.8,然后他来自男生的那个高斯分布,那么我们可以将这个样本表示为 {1.8, 1, 0}。如果 zi1 和 zi2的值已知,也就是说每个人我已经标记为男生或者女生了,那么我们就可以利用上面说的最大似然算法来估计他们各自高斯分布的参数。但是他们未知,所以我们只能用 EM算法。
咱们现在不是因为那个恶心的隐含变量(抽取得到的每隔样本都不知道是那个分布抽取的)使得本来简单的可以求解的问题变复杂了,求解不了吗。那怎么办呢?人类解决问题的思路都是想能否把复杂的问题简单化。好,那么现在把这个复杂的问题逆回来,我假设已经知道这个隐含变量了,哎,那么求解那个分布的参数是不是很容易了,直接按上面说的最大似然估计就好了。那你就问我了,这个隐含变量是未知的,你怎么就来一个假设说已知呢?你这种假设是没有依据的。所以我们可以先给这个分布弄一个初始值,然后求这个隐含变量的期望,当成是这个隐含变量的已知值,那么现在就可以用最大似然求解那个分布的参数了吧,那假设这个参数比之前的那个随机的参数要好,它更能表达真实的分布,那么我们再通过这个参数确定的分布去求这个隐含变量的期望,然后再最大化,得到另一个更优的参数,...迭代,就能得到一个皆大欢喜的结果了。
这里最后总结一下EM算法的思路:

所以EM算法解决问题的思路就是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐藏数据是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。不过没关系,我们基于当前得到的模型参数,继续猜测隐含数据(EM算法的E步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
下面再看看本文中EM算法最后一个例子:抛硬币
Nature Biotech在他的一篇EM tutorial文章《Do, C. B., & Batzoglou, S. (2008). What is the expectation maximization algorithm?. Nature biotechnology, 26(8), 897.》中,用了一个投硬币的例子来讲EM算法的思想。
比如两枚硬币A和B,如果知道每次抛的是A还是B,那可以直接估计(见下图a)。

如果不知道抛的是A还是B(这时就刺激了吧,对的,这就是咱们不知情的隐变量),只观测到5轮循环每轮循环10次,共计50次投币的结果,这时就没法直接估计A和B的正面概率。这时,就轮到EM算法出场了(见下图b)。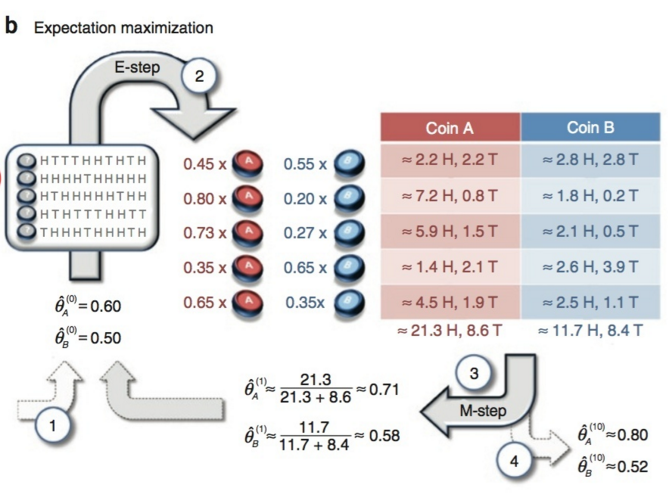
可能直接看,这个例子不好懂,下面我们来通俗化这个例子。
还是两枚硬币A和B,假定随机抛掷后正面朝上概率分别为PA,PB。我们就不抛了,直接使用上面的结果,每一轮都是抛10次,总共5轮:
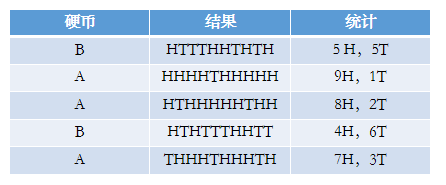
硬币A被抛了30次,在第二轮,第三轮,第五轮分别出现了9次,8次,7次正,所以很容易估计出PA,类似的PB 也很容易计算出来,如下:

但是问题来了,如果我们不知道抛的硬币是A还是B呢(即硬币种类是隐变量),然后再轮流抛五次,得到如下的结果呢?
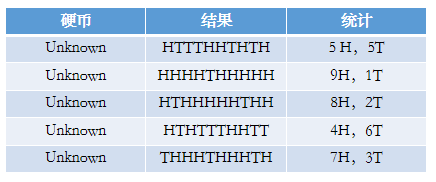
下面问题变得有意思了,现在我们的目标还是没有变,还是估计PA和PB,需要怎么做呢?
思路如下:
显然这里我们多了一个硬币种类的隐变量,设为 z,可以把它看做一个10维的向量(z1, z2, ...z10),代表每次投掷时所使用的硬币,比如z1,就代表第一轮投掷时使用的硬币是A还是B。
- 但是,这个变量Z不知道,就无法去估计PA和PB,所以我们先必须估计出Z,然后才能进一步估计PA和PB。
- 可是要估计Z,我们又得知道PA和PB,这样我们才能用极大似然概率法去估计Z,这不是前面提的鸡生蛋和蛋生鸡的问题吗,如何解?
答案就是先随机初始化一个PA和PB,用它来估计Z,然后基于Z,还是按照最大似然概率法则去估计新的PA和PB,如果新的PA和PB和我们初始化的PA和PB一样,请问这说明了什么?
这说明我们初始化的PA和PB是一个相当靠谱的估计!
这就是说,我们初始化的PA和PB,按照最大似然概率就可以估计出Z,然后基于Z,按照最大似然概率可以反过来估计出P1和P2,当与我们初始化的PA和PB一样时,说明是P1和P2很可能就是真实的值。这里包含了两个交互的最大似然估计。
如果新估计出来的PA和PB和我们初始化的值差别很大,怎么办呢?就是继续用新的P1和P2迭代,直至收敛。
做法如下:
我们不妨,这样,先随便给PA和PB赋一个值,比如:

所以我们的初始值 theta 为:

然后,我们看看第一轮抛掷最可能是哪个硬币,(五正五负):

其实上式很简单就是:PA= 0.6*0.6*0.6*0.6*0.6*0.4*0.4*0.4*0.4*0.4 = 0.0007962624000000002(后面类似)
PB= 0.5**10 = 0.0009765625
然后求出选择PA的概率和PB的概率值

然后依次求出其他四轮中相应的概率。做成表格如下:
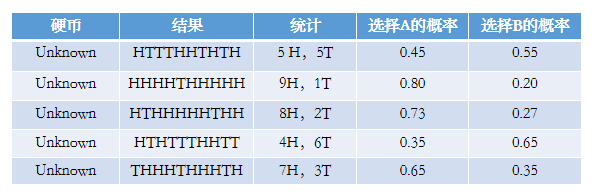
然后我们通过上面的概率值来估计Z,大概是这样的:

这样我们通过最大似然估计法则就估算出来PA和PB的值了,如下:
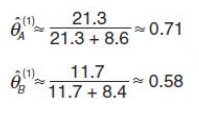
然后我们再次迭代,继续估算,假设我们估算到第10次,就算出PA和PB的值是正确的了,如下:
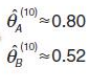
下面我们来对比初始化的PA和PB和新估计的PA和PB,和最终的PA和PB:

我们可以发现,我们估计的PA和PB相比于他们的初始值,更接近于他们的真实值,就这样不断迭代,不断接近真实值,这就是EM算法的奇妙之处。
可以期待,我们继续按照上面的思路,用估计出的PA和PB再来估计Z,再用Z来估计新的PA和PB,反复迭代下去,就可以最终得到PA和PB的真值了。而这里我们假设为 0.8 和 0.52。此时无论怎么迭代,PA和PB的值都会保持在 0.8和0.52不变,于是,我们就找到了PA和PB的最大似然估计。
下面在推导EM算法之前,我们先学习一下Jensen不等式
3,导数性质和Jensen不等式
在学习Jensen不等式之前,我们先说说二阶导数的一些性质。
3.1,二阶导数的性质1
如果有一个函数 f(x) 在某个区间 I 上有 f ''(x)(即二阶导数) > 0 恒成立,那么对于区间 I上的任意 x, y 总有:

如果总有 f''(x) < 0 成立,那么上式的不等号反向。
几何的直观解释:如果有一个函数 f(x) 在某个区间 I 上有 f ''(x)(即二阶导数) > 0 恒成立,那么在区间 I 上 f(x)的图像上的任意两点连出的一条线段,这两点之间的函数图像都在该线段的下方,反之在该线段的上方。
3.2,二阶导数的性质2:判断函数极大值以及极小值
结合一阶,二阶导数可以求函数的极值。当一阶导数等于0,而二阶导数大于0时,为极小值点。当一阶导数等于0,而二阶导数小于0时,为极大值点;当一阶导数和二阶导数都等于0,为驻点 。
驻点:在微积分,驻点(Stationary Point)又称为平稳点、稳定点或临界点(Critical Point)是函数的一阶导数为零,即在“这一点”,函数的输出值停止增加或减少。对于一维函数的图像,驻点的切线平行于x轴。对于二维函数的图像,驻点的切平面平行于xy平面。值得注意的是,一个函数的驻点不一定是这个函数的极值点(考虑到这一点左右一阶导数符号不改变的情况);反过来,在某设定区域内,一个函数的极值点也不一定是这个函数的驻点(考虑到边界条件),驻点(红色)与拐点(蓝色),这图像的驻点都是局部极大值或局部极小值
3.3,二阶导数的性质3:函数凹凸性
设 f(x) 在 [a, b] 上连续,在(a, b)内具有一阶和二阶导数,那么:
- (1)若在(a, b)内 f ''(x) > 0,则 f(x) 在[a, b]上的图形是凹的
- (2)若在(a, b)内 f ''(x) < 0,则 f(x) 在[a, b]上的图形是凸的
3.4 期望
在概率论和统计学中,数学期望(mean)(或均值,也简称期望)是实验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。
需要注意的是:期望值并不一定等同于常识中的“期望”——“期望值”也许与每一个结果都不相等。期望值是该变量输出值的平均数。期望值并不一定包含于变量的输出值集合里。
大数定理规定:随着重复次数接近无穷大,数值的算术平均值几乎肯定地收敛于期望值。
离散型:
如果随机变量只取得有限个数或无穷能按一定次序一一列出,其值域为一个或若干个有限或无限区域,这样的随机变量称为离散型随机变量。
离散型随机变量只取得有限个值或无穷能按一定次序一一列出,其值域为一个或若干个有限或无限区间,这样的随机变量称为离散型随机变量。
离散型随机变量的一切可能的取值 xi 与对应的概率 p(xi) 乘积之和称为该离散型随机变量的数学期望(若该求和绝对收敛),记为E(x)。它是简单算术平均的一种推广,类似加权平均。
公式:
离散型随机变量X的取值为X1, X2, X3....Xn, p(X1),p(X2), p(X3)....P(Xn)为X对应取值的概率,可以理解为数据 X1, X2, X3.....Xn出现的频率 f(Xi),则:
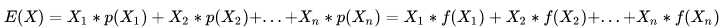
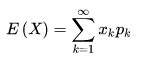
例子:
某城市有10万个家庭,没有孩子的家庭有 1000 个,有一个孩子的家庭有 9 万个,有两个孩子的家庭有 6000个,有 3个孩子的家庭有 3000个。
则此城市中任一个家庭中孩子的数目是一个随机变量,记为X。它可取值 0, 1, 2, 3 。
其中,X取 0 的概率为 0.01 ,取 1的概率为 0.9,取 2的概率为0.06,取 3的概率为0.03
则它的数学期望为:
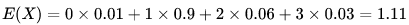
即此城市一个家庭平均有小孩 1.11 个,当然人不可能用1.11来算,约等于2个。
设 Y 是随机变量X的函数:
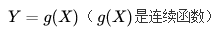
它的分布律为:
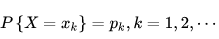

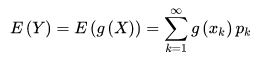
连续型:
设连续型随机变量 X 的概率密度函数为 f(x),若积分绝对收敛,则称积分的值为随机变量的数学期望,记为 E(x),即:
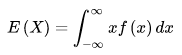
若随机变量 X的分布函数 F(x) 可表示成一个非负可积函数 f(x)的积分,则称 X为连续型随机变量,f(x)称为 X 的概率密度函数(分布密度函数)。
数学期望 E(X) 完全由随机变量 X 的概率分布所确定。若X服从某一分布,也称 E(X) 是这一分布的数学期望。
定理:
若随机变量 Y 符合函数 Y = g(x),且下面函数绝对收敛,则有下下面的期望

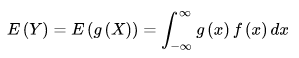
该定理的意义在于:我们求 E(Y) 时不需要计算出 Y的分布律或概率分布,只要利用X的分布律或者概率密度即可。
上述定理还可以推广到两个或以上随机变量的函数情况。
设 Z 是随机变量 X, Y 的函数 Z = g(X, Y)(g是连续函数),Z是一个一维随机变量,二维随机变量(X, Y)的概率密度为 f(x, y),则有:
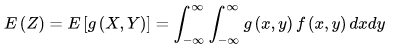
离散型随机变量与连续型随机变量的区别
离散型随机变量与连续型随机变量都是由随机变量取值范围确定。
变量取值只能取离散型的自然数,就是离散型随机变量。例如,一次掷20个硬币,k额硬币正面朝上,k是随机变量。k的取值只能是自然数0, 1, 2 ,3, 4, 。。。。20。而不能取小数 3.5 ,无理数 √ 20 ,因此k是离散型随机变量。
如果变量可以在某个区间内取任一实数,即变量的取值可以是连续的,这随机变量就称为连续型变量。例如公共汽车每 15 分钟一班,某人在站台等车时间 x 是个随机变量,x的取值范围是 [0, 15),它是一个区间,从理论上说在这个区间内可取任一实数 3.5 ,无理数 ,√ 20 等,因而称这随机变量是连续型随机变量。
3.5 Jensen不等式

如果用图表示会很清晰:


4,EM算法的推导
从上面的总结,我们知道EM算法就是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
这时候你就不服了,说你老迭代迭代的,你咋知道新的参数的估计就比原来的好啊?为什么这种方法行得通呢?有没有失效的时候呢?什么时候失效呢?用到这个方法需要注意什么问题呢?
为了说明这一串问题,我们下面学习EM算法的整个推导过程。
首先,我们接着上面的问题聊,就是100名学生的身高问题,总结一下问题,如下:
样本集 {x(1), x(2) , .... x(m)},包含 m 个独立的样本,其中每个样本 i 对应的类别 z(i) 是未知的,所以很难用极大似然求解。而我们的目的就是想找到每个样例隐含的类别z,能使得p(x, z) 最大。
p(x, z) 的最大似然估计如下:
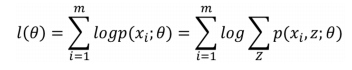
上式中,我们要考虑每个样本在各个分布中的情况。本来正常求偏导就可以了,但是因为有隐含数据的存在,也就是log后面还有求和,这个就没有办法直接求出 theta了。
对于每一个样例 i,让Qi 表示该样例隐含变量 z 的某种分布,Qi 满足的条件是:

如果 z 是连续性的,那么Qi是概率密度函数,需要将求和符号换做积分符号。继续上面的例子,假设隐藏变量 z是身高,那就是连续的高斯分布;假设隐藏变量是男女,那就是伯努利分布 。
所以说如果我们确定了隐藏变量z,那求解就容易了,可是怎么求解呢?这就需要一些特殊的技巧了。
技巧:Jensen不等式应用于凹函数时,不等号方向反向。
我们知道:

所以对右式分子分母同时乘以 Q(z):
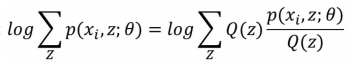
为什么要这么做呢?说白了就是要凑Jensen不等式(Q(z) 是Z的分布函数),下面继续
这里假设:
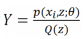
则上式可以写为:
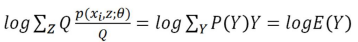
我们由Jensen不等式可以知道(由于对数函数是凹函数):
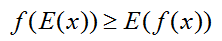
则代入 上式:
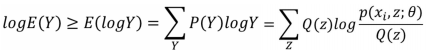
所以:
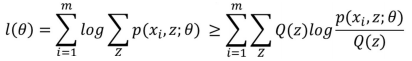
上面这个过程可以看做是对 l(Θ) 求了下界。对于Qi 的选择,有多种可能,那种更好呢?假设 Θ 已经给定,那么 l(Θ) 的值就取决于 Q(z)和P(x, z)了。
4.1 如何优化下界?
因为下界比较好求,所以我们要优化这个下界来使得似然函数最大。那么如何优化下界呢?
随着我们的参数变换,我们的下界是不断增大的趋势。我们红色的线是恒大于零的。简单来说,就是EM算法可以看做是J 的坐标上升法,E步固定 theta,优化 Q,M步固定Q,优化 theta。
迭代到收敛

可能用这个图更明显(参考:https://blog.csdn.net/u010834867/article/details/90762296)
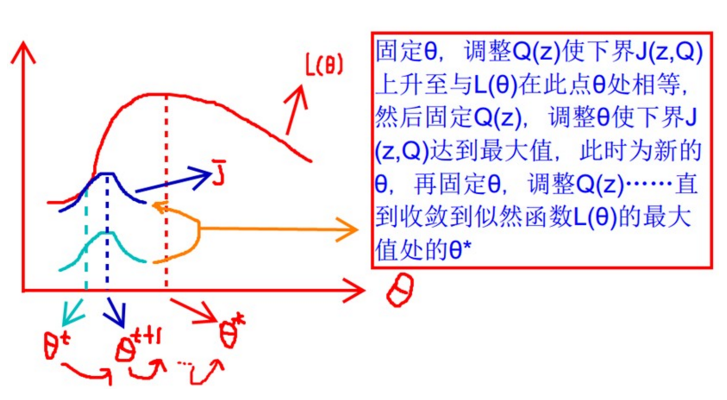
我们需要调整上式中Q(z)和P(x, z) 这两个概率,使下界不断上升,以逼近 l(Θ) 的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于 l(Θ) 了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,就需要什么呢?下面继续说。
4.2 如何能使Jensen不等式等号成立呢?
什么时候,使得我们的似然函数最大呢?当然是取等号的时候。什么时候等号成立呢?
由上面Jensen不等式中所说,我们要满足Jensen不等式的等号,则当且仅当 P(x=E(x)) = 1的时候,也就是说随机变量X是常量。在这里,我们则有:
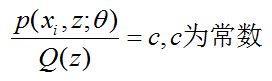
c为常数,不依赖于 z。对此式子做进一步推导,由于Q(z) 是z的分布函数,所以满足:

所有的分子和等于常数C(分母相同),即:

多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是 c,那么就可以求解 Q(z)了。
4.3 Q(z)的求解
我们知道Q(z) 是z的分布函数,而且:
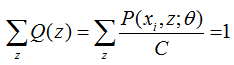
由上式就可得C就是 P(xi, z)对Z求和,我们上面有公式。
从上面两式,我们可以得到:
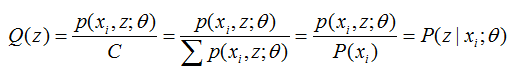
Q(z) 代表第 i 个数据是来自 zi 的概率。
至此,我们推出了在固定其他参数 Θ 后,Q(z)的计算公式就是后验概率,解决了Q(z)如何选择的问题。这一步就是E步,建立 l(Θ) 的下界。
所以去掉 l(Θ) 式中为常数的部分,则我们需要极大化的对数似然下界为:
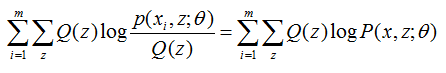
注意上式也就是我们EM算法的M步,就是在给定 Q(z)后,调整Θ,去极大化 l(Θ)的下界(在固定Q(z)后,下界还可以调整的更大)。
E步我们再强调一次,注意到上式Q(z)是一个分布,因此 下式可以理解为 logP(x, z; Θ) 基于条件概率分布 Q(z)的期望。

至此,我们学习了EM算法那中E步和M步的具体数学含义。
5,EM算法的一般流程
下面我们总结一下EM算法的流程。
输入:观察数据 x = {x1, x2, ... xm},联合分布 p(x, z; θ),条件分布 p(z|x; θ),最大迭代次数 J 。
1)随机初始化模型参数 θ 的初值 θ0。
2)循环重复,即for j from 1 to J 开始EM算法迭代。
E步:计算联合分布的条件概率期望
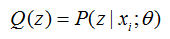
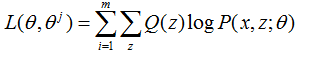
M步:极大化L(θ, θj),得到 θj+1:
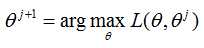
3)如果 θj+1 已经收敛,则算法结束,否则继续回到步骤E步迭代。
输出:模型参数 θ。
用PPT总结如下:

6,EM算法的收敛性思考
(这里直接粘贴刘建平老师的博客了。方便。。)
EM算法的流程并不复杂,但是还有两个问题需要我们思考:
- 1) EM算法能保证收敛吗?
- 2)EM算法如果收敛,那么能保证收敛到全局最大值吗?
首先,我们先看第一个问题,EM算法的收敛性。要证明EM算法收敛,则我们需要证明我们的对数似然函数的值在迭代的过程中一直在增大。即:
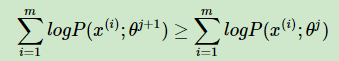
由于:
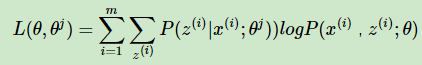
令:
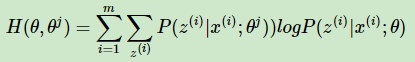
上面两个式子相减得到:

在上式中分别取 Θ 为 Θj 和 Θj+1 ,并且相减得到:
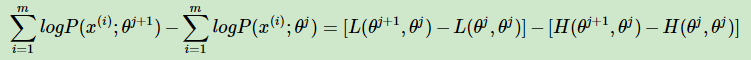
要证明EM算法的收敛性,我们只需要证明上式的右边是非负的即可。
由于 Θj+1 使得L(Θ,Θj )极大,因此有:
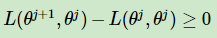
上式的意思是说极大似然估计单调递增,那么我们会达到最大似然估计的最大值。
而对于第二部分,我们有:
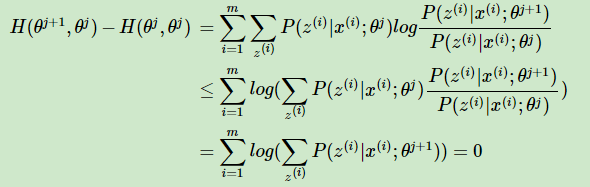
上式中,第二个不等式使用了Jensen不等式,只不过和前面的使用相反而已,最后一个等式使用了概率分布累积为1的性质。
至此,我们得到了:
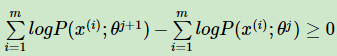
从上面的推导可以看出,EM算法可以保证收敛到一个稳定点,但是却不能保证收敛到全局的极大值点,因此它是局部最优的算法,当然,如果我们的优化目标 L(Θ,Θj )是凸的,则EM算法可以保证收敛到全局最大值,这点和梯度下降法这样的迭代算法相同。至此我们也回答了上面的第二个问题。
如果我们从算法思想的角度来思考 EM 算法,我们可以发现我们的算法里已知的是观察数据,未知的隐含数据和模型参数。在E步,我们所做的事情是固定模型参数的值,优化隐含数据的分布,而在M步,我们所做的事情是固定隐含数据分布,优化模型参数的值。比较下其他的机器学习算法,其实很多算法都有类似的思想。比如SMO算法,坐标轴下降法都是由了类似的思想来求解问题。
7,GMM(高斯混合模型)
我们上面已经推导了EM算法,下面再来说一下高斯混合模型。高斯混合模型是什么呢?顾名思义就是用多个高斯模型来描述数据的分布,就是说我们的数据可以看做是从多个Gaussian Distribution 中生成出来的。那GMM是由K个Gaussian分布组成,所以每个Gaussian称为一个“Component”。
首先说一句,为什么是高斯混合模型呢?而不是其他模型呢?
因为从中心极限定理知:只要k足够大,模型足够复杂,样本量足够多,每一块小区域就可以用高斯分布描述(简单说:只要样本量足够大时,样本均值的分布慢慢变为正态分布)。而且高斯函数具有良好的计算性能,所以GMM被广泛的应用。
有时候单一的高斯分布不能很好的描述分布,如下图,二维高斯密度函数的等概率先为椭圆(当然后面会做练习)

从上图我们看到,左图用单一高斯分布去描述,显然没有右图用两个高斯分布去描述的效果好。
所以我们引入混合高斯模型。
如下图所示,我们用三个高斯分布去描述一个二维的数据:

现在我们定义 K 个高斯密度叠加:
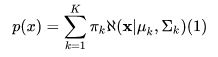
对于每个高斯密度函数有自己的均值 μk 和方差 ∑k , πk作为混合的比例系数有:
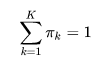
下图中(a)为不同混合比例下的高斯概率密度分布;(b)为混合状态下的概率密度分布;(c)为概率密度分布的表面图:

所以 p(x) 可以改写为:
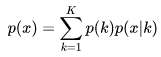
并与公式(1)对比,有:

则后验概率 p(k|x),根据贝叶斯理论,可表示为:
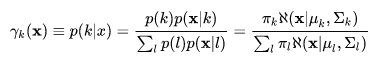
因此GMM由 μ, ∑ , π 确定,并在有参数 K的存在。
而GMM模型的求解方式和EM算法是一样的,就是不断的迭代更新下去。一个最直观的了解算法的思路就是参考K-Means算法。博客地址:
Python机器学习笔记:K-Means算法,DBSCAN算法
这里再简单的说一下,在K-Means聚类时,每个聚类簇的质心是隐含数据。我们会假设K个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并且把样本聚类到最近的这个质心,即EM算法的M步,重复这个E步和M步,知道质心不再变化为止,这样就完成了K-Means聚类。当然K-Means算法是比较简单的,实际问题并没有这么简单,但是大概可以说明EM算法的思想了。
上面遗留了一个问题,就是单一的高斯分布不能很好的描述分布,而两个高斯分布描述的好。为了将这个说的透彻,我们这样做:我们生成四簇数据,其中两簇数据离的特别近,然后我们看看K-Means算法是否能将这两簇离的特别近的数据按照我们的想法区分开,再看看GMM算法呢,如果可以区分,那么我们将数据拉伸呢?
所以下面我们会做两个实验,对于随机生成的数据,我们会做K-Means算法和GMM算法的效果比对,然后再对数据进行处理,再做K-Means算法和GMM算法的效果比对。
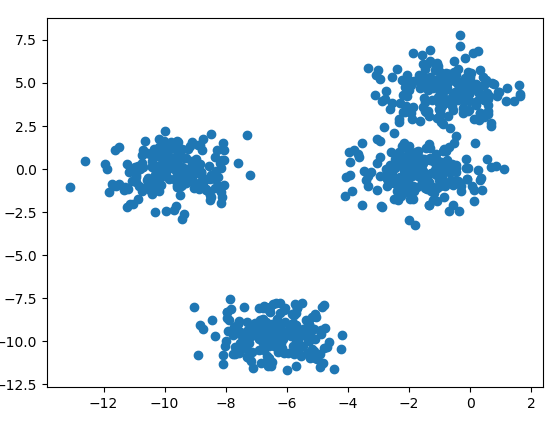
首先生成四簇数据,效果如下:
from sklearn.datasets.samples_generator import make_blobs from matplotlib import pyplot as plt from sklearn.cluster import KMeans from sklearn.mixture import GaussianMixture # 生成新的数据 X, y_true = make_blobs(n_samples=800, centers=4, random_state=11) plt.scatter(X[:, 0], X[:, 1])
图如下:
我们看看K-Means分类效果:

我们再看看GMM算法的效果:

都能分出来,这样很好,下面我们对数据进行处理:拉伸
rng = np.random.RandomState(13) X_stretched = np.dot(X, rng.randn(2, 2))
我们拉伸后,看看原图效果:
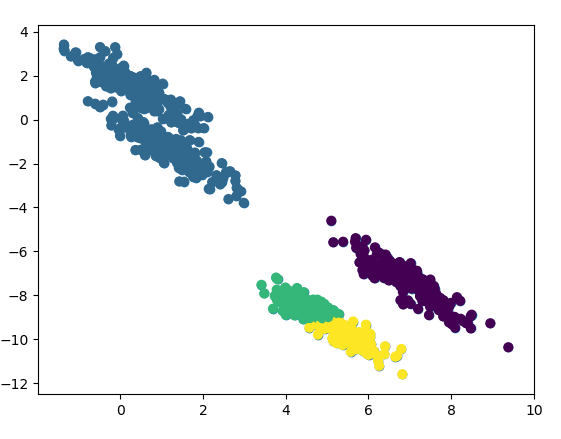
下面分别使用K-Means算法和GMM算法看效果:
首先是K-Means算法
kmeans = KMeans(n_clusters=4) kmeans.fit(X) y_kmeans = kmeans.predict(X) plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
效果如下

K-Means算法没有把拉伸的数据分开,而是按照聚类的思想,将上面的数据聚在一起,将下面的数据聚在一起。
我们再看看GMM算法的效果:
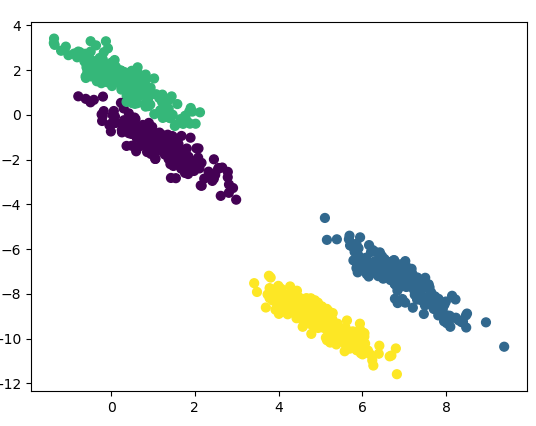
是不是GMM算法区分出来我们想要的效果了。所以在这个问题上GMM算法的优势就体现出来了。
完整代码去我的GitHub上拿(地址:https://github.com/LeBron-Jian/MachineLearningNote)。
8,Sklearn实现GMM(高斯混合模型)
Sklearn库GaussianMixture类是EM算法在混合高斯分布的实现,现在简单记录下其参数说明。
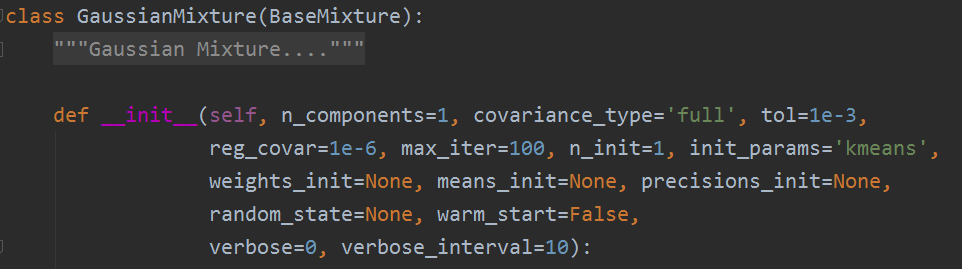
对此源码中的参数,我们了解其意义:
- 1. n_components:混合高斯模型个数,默认为1
- 2. covariance_type:协方差类型,包括{‘full’,‘tied’, ‘diag’, ‘spherical’}四种,分别对应完全协方差矩阵(元素都不为零),相同的完全协方差矩阵(HMM会用到),对角协方差矩阵(非对角为零,对角不为零),球面协方差矩阵(非对角为零,对角完全相同,球面特性),默认‘full’ 完全协方差矩阵
- 3. tol:EM迭代停止阈值,默认为1e-3.
- 4. reg_covar:协方差对角非负正则化,保证协方差矩阵均为正,默认为0
- 5. max_iter:最大迭代次数,默认100
- 6. n_init:初始化次数,用于产生最佳初始参数,默认为1
- 7. init_params: {‘kmeans’, ‘random’}, defaults to ‘kmeans’.初始化参数实现方式,默认用kmeans实现,也可以选择随机产生
- 8. weights_init:各组成模型的先验权重,可以自己设,默认按照7产生
- 9. means_init:初始化均值,同8
- 10. precisions_init:初始化精确度(模型个数,特征个数),默认按照7实现
- 11. random_state :随机数发生器
- 12. warm_start :若为True,则fit()调用会以上一次fit()的结果作为初始化参数,适合相同问题多次fit的情况,能加速收敛,默认为False。
- 13. verbose :使能迭代信息显示,默认为0,可以为1或者大于1(显示的信息不同)
- 14. verbose_interval :与13挂钩,若使能迭代信息显示,设置多少次迭代后显示信息,默认10次。
下面看看网友对源码的分析:
(1)首先将模型完全转换成对数计算,根据高斯密度函数公式分别计算k个组成高斯模型的log值,即logP(x|z)的值
def _estimate_log_gaussian_prob(X, means, precisions_chol, covariance_type):
# 计算精度矩阵的1/2次方log_det(代码精度矩阵是通过cholesky获取)
log_det = _compute_log_det_cholesky(
precisions_chol, covariance_type, n_features)
# 对应上面四种协方差类型,分别计算精度矩阵与(x-u)相乘那部分log_prob
if covariance_type == 'full':
log_prob = np.empty((n_samples, n_components))
for k, (mu, prec_chol) in enumerate(zip(means, precisions_chol)):
y = np.dot(X, prec_chol) - np.dot(mu, prec_chol)
log_prob[:, k] = np.sum(np.square(y), axis=1)
elif covariance_type == 'tied':
log_prob = np.empty((n_samples, n_components))
for k, mu in enumerate(means):
y = np.dot(X, precisions_chol) - np.dot(mu, precisions_chol)
log_prob[:, k] = np.sum(np.square(y), axis=1)
elif covariance_type == 'diag':
precisions = precisions_chol ** 2
log_prob = (np.sum((means ** 2 * precisions), 1) -
2. * np.dot(X, (means * precisions).T) +
np.dot(X ** 2, precisions.T))
elif covariance_type == 'spherical':
precisions = precisions_chol ** 2
log_prob = (np.sum(means ** 2, 1) * precisions -
2 * np.dot(X, means.T * precisions) +
np.outer(row_norms(X, squared=True), precisions))
# 最后计算出logP(x|z)的值
return -.5 * (n_features * np.log(2 * np.pi) + log_prob) + log_det
(2)P(x|z)*P(z)计算每个模型的概率分布P(x,z),求对数则就是相加了
def _estimate_weighted_log_prob(self, X):
return self._estimate_log_prob(X) + self._estimate_log_weights()
(3)最后开始计算每个模型的后验概率logP(z|x),即Q函数
def _estimate_log_prob_resp(self, X):
weighted_log_prob = self._estimate_weighted_log_prob(X)
#计算P(X)
log_prob_norm = logsumexp(weighted_log_prob, axis=1)
with np.errstate(under='ignore'):
# 忽略下溢,计算每个高斯模型的后验概率,即占比,对数则相减
log_resp = weighted_log_prob - log_prob_norm[:, np.newaxis]
return log_prob_norm, log_resp
(4)调用以上函数
#返回所有样本的概率均值,及每个高斯分布的Q值
def _e_step(self, X):
log_prob_norm, log_resp = self._estimate_log_prob_resp(X)
return np.mean(log_prob_norm), log_resp
2.对应M step
def _m_step(self, X, log_resp):
#根据上面获得的每个高斯模型的Q值(log_resp)。重新估算均值self.means_,协方差self.covariances_,当前符合各高斯模型的样本数目self.weights_(函数名起的像权重,实际指的是数目)
n_samples, _ = X.shape
self.weights_, self.means_, self.covariances_ = (
_estimate_gaussian_parameters(X, np.exp(log_resp), self.reg_covar,
self.covariance_type))
#更新当前各高斯模型的先验概率,即P(Z)
self.weights_ /= n_samples
#根据cholesky分解计算精度矩阵
self.precisions_cholesky_ = _compute_precision_cholesky(
self.covariances_, self.covariance_type)
然后重复以上过程,就完成了EM算法的实现啦。
下面进入我们的实战环节。。。
数据(可以去我的GitHub上拿,地址:https://github.com/LeBron-Jian/MachineLearningNote)
数据的背景是这样的,这里简单介绍一下:在某个地区有一个桥,桥东面有一个区域,桥西边有一个区域。假设我们这两个地方是存放共享单车的,那给出的数据是每天某个时间点,共享单车被骑走的数据。(此数据是关于时间序列的数据),数据有 42312条,每条数据有两个特征(也就是前面提到的两个地区)。
首先我们展示一下数据,代码如下:
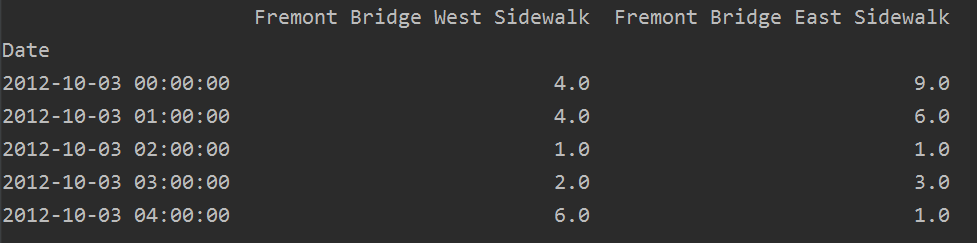
import pandas as pd filename = 'Fremont.csv' data = pd.read_csv(filename, index_col='Date', parse_dates=True) res = data.head() print(res)
数据如下:
为了直观,我们画图,看看原数据长什么样子:

这样是很难看出特征的吧,原数据是按照小时来统计两个区域的数据,下面我们对数据进行重采样,按周进行计算,我们再看看效果:
# 展示原数据
# data.plot()
data.resample('w').sum().plot()
注意这个resample 的意思,是按照时间索引进行合并后求和计算的。就是在给定的时间单位内重取样,常见的时间频率为:
- A year
- M month
- W week
- D day
- H hour
- T minute
- S second
说明白了意思,下面我们看看按周进行计算的图:
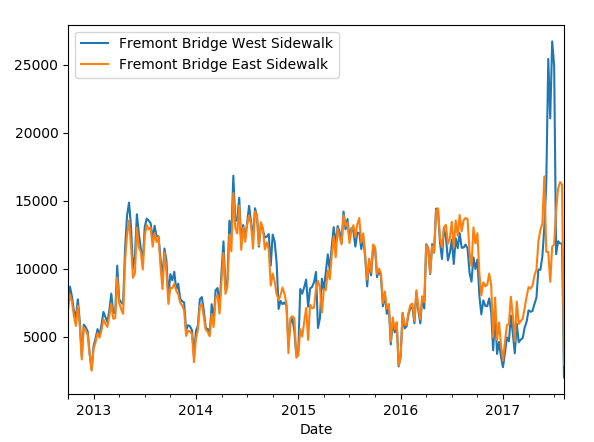
现在数据直观上看起来清晰多了吧,当然我们对于时间序列问题,不止可以采取重取样查看数据,也可以采用滑动窗口,下面尝试一下采用365天做一个滑动窗口,这里是窗口的总和,代码和图如下:
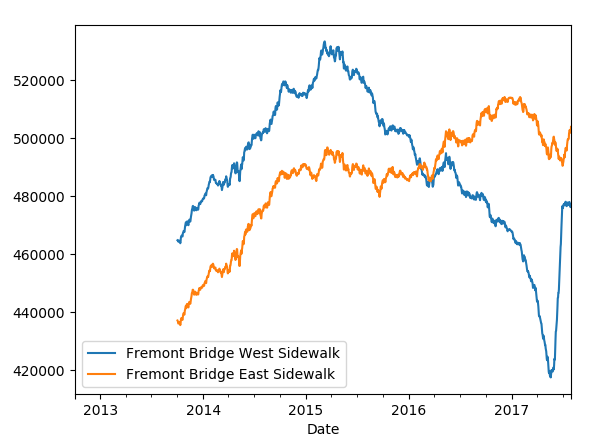
# 对数据采用滑动窗口,这里窗口是365天一个
data.resample('D').sum().rolling(365).plot()
图如下:
下面我们不按照时间来算了,不对这五年的数据进行分析了,我们想看看某一天的数据分布,如何做呢?
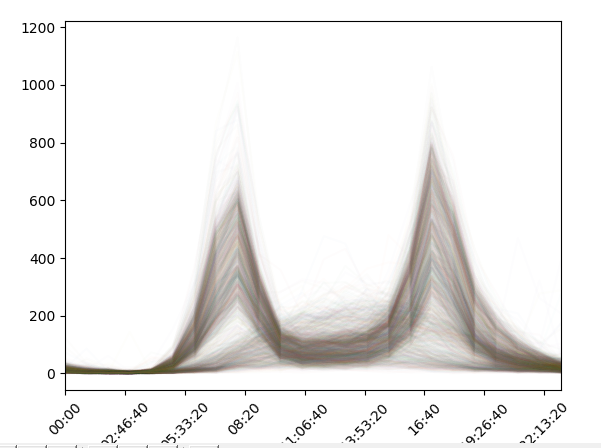
# 查看某一天的数据分布 data.groupby(data.index.time).mean().plot() plt.xticks(rotation=45)
图如下:

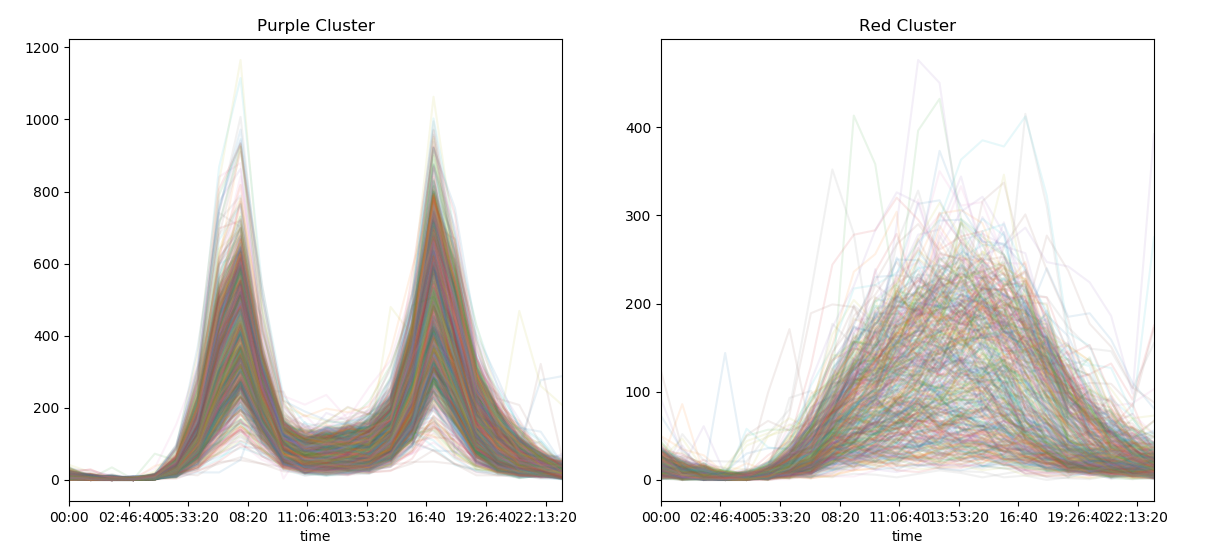
我们可以看到在早上七点到九点,West地区骑走的共享单车比较多,而在下午的四点到六点,East骑走的共享单车比较多。
下面我们将这两个特征分别命名为East和West,再看看前五个小时时间变换图。
# 查看前五个小时时间变换
# pivot table
data.columns = ['West', 'East']
data['Total'] = data['West'] + data['East']
pivoted = data.pivot_table('Total', index=data.index.time, columns=data.index.date)
res = pivoted.iloc[:5, :5]
print(res)
结果如下:

我们展示一下 24个小时的两地数据图:
# 画图展示一下 pivoted.plot(legend=False, alpha=0.01) plt.xticks(rotation=45)
图如下(数据比较多,画图比较慢,等等就OK):
对数据分析完后,我们开始使用模型训练,这里为了能将数据展示在二维图上,我们做这样一个处理,首先我们将数据转置,毕竟将数据分为很多特征,而且只有24个数据不好。所以将样本数分为1763,特征为24个,则效果就比较好了。。。。
而这样是可以做的,但是方便演示,我们希望将数据转换为二维的,那我们需要对数据进行降维,我们把二十四个特征降维到二维空间,降维代码如下:
X = pivoted.fillna(0).T.values print(X.shape) X2 = PCA(2).fit_transform(X) print(X2.shape) plt.scatter(X2[:, 0], X2[:, 1])
转换为二维,数据如图所示:
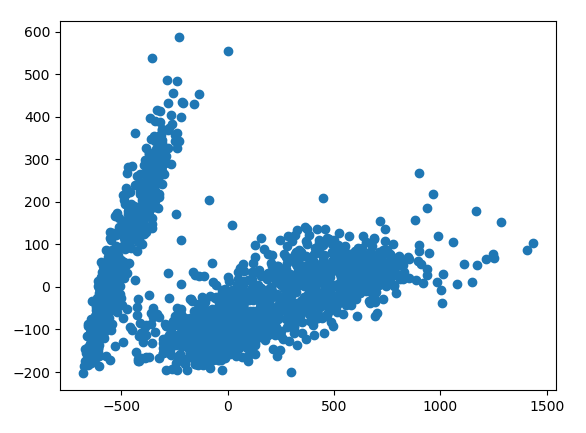
数据经过PCA降维后,其物理意义很难解释,我们可以看到图中都有负值了,所以不要纠结这个问题。
下面看GMM算法的代码:
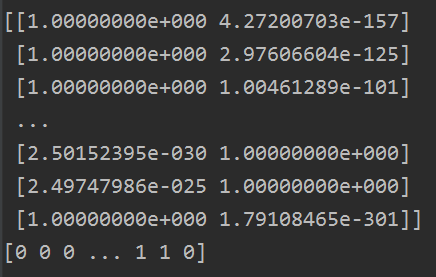
gmm = GaussianMixture(2) gmm.fit(X) labels_prob = gmm.predict_proba(X) print(labels_prob) labels = gmm.predict(X) print(labels) plt.scatter(X2[:, 0], X2[:, 1], c=labels, cmap='rainbow')
我们看看预测出来的label概率和label值(GMM算法比较特别,我们可以知道某个类别的概率值):
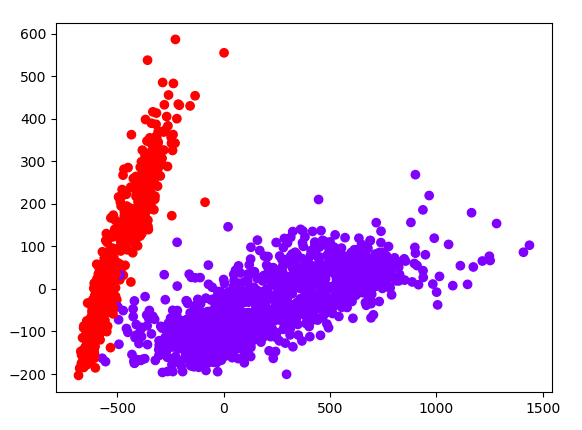
使用GMM算法,分类的图如下:
下面我们将二维数据还原回去,看效果,代码如下:
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
pivoted.T[labels == 0].T.plot(legend=False, alpha=0.1, ax=ax[0])
pivoted.T[labels == 1].T.plot(legend=False, alpha=0.1, ax=ax[0])
ax[0].set_title('Purple Cluster')
ax[1].set_title('Red Cluster')
图如下:
PS:这篇文章是我整理自己学习EM算法的笔记,结合老师的PPT,然后找到网友优秀的博客,将自己的理解写到这里。
参考文献:https://www.cnblogs.com/pinard/p/6912636.html
https://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
https://blog.csdn.net/fuqiuai/article/details/79484421
https://blog.csdn.net/u010834867/article/details/90762296
https://zhuanlan.zhihu.com/p/28108751
https://blog.csdn.net/lihou1987/article/details/70833229
https://blog.csdn.net/v_july_v/article/details/81708386

