
OpenCV计算机视觉学习(1)——图像基本操作(图像视频读取,ROI区域截取,常用cv函数解释)
如果需要处理的原图及代码,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice
1,计算机眼中的图像
我们打开经典的 Lena图片,看看计算机是如何看待图片的:

我们点击图中的一个小格子,发现计算机会将其分为R,G,B三种通道。每个通道分别由一堆0~256之间的数字组成,那OpenCV如何读取,处理图片呢,我们下面详细学习。
2,图像的加载,显示和保存
我们看看在OpenCV中如何操作:
import cv2
# 生成图片
img = cv2.imread("lena.jpg")
# 生成灰色图片
imgGrey = cv2.imread("lena.jpg", 0)
# 展示原图
cv2.imshow("img", img)
# 展示灰色图片
cv2.imshow("imgGrey", imgGrey)
# 等待图片的关闭
cv2.waitKey()
# 保存灰色图片
cv2.imwrite("Copy.jpg", imgGrey)
图像的显示,也可以创建多个窗口。
2.1 图像的加载函数 cv2.imread()
cv2.imread() 函数原型如下:
imread(filename, flags=None)
使用函数cv2.imread() 读入图像。
filename表示要读取的图像的文件路径和文件名,需要你给函数提供完整路径。
第二个参数flags是图像读取的标识,用于读取图像的行为和格式,是要告诉函数应该如何读取这幅图片。
常见的标识包括”
- cv2.IMREAD_COLOR:读入一副彩色图像。图像的透明度会被忽略,这是默认参数
- cv2.IMREAD_GRAYSCALE:以灰度模式读入图像
- cv2.IMREAD_UNCHANGED:保留读取图片原有的颜色通道
- +1 :等同于cv2.IMREAD_COLOR
- 0 :等同于cv2.IMREAD_GRAYSCALE
- -1 :等同于cv2.IMREAD_UNCHANGED
除了这些常用的标志之外,还可以用其他的标志进行更高级的图像处理和读取,完整的标志列表可以在OpenCV的文档找到。
PS:调用opencv,就算图像的路径是错的,OpenCV 也不会提醒你的,但是当你使用命令 print(img) 时得到的结果是None。因为cv::imread 函数返回一个 cv::Mat 对象,即图像的数据矩阵。如果无法读取图像或文件不存在,则返回一个空的 cv::Mat 对象。所以这是要注意的。
2.2 图像的显示函数 cv2.imshow()
cv2.imshow() 函数作用是在窗口中显示图像,窗口自动适合于图像大小,我们也可以通过imutils模块调整显示图像的窗口大小。
函数官方定义如下:
imshow(winname, mat)
参数解释如下:
- 参数一: 窗口名称(字符串)
- 参数二: 图像对象,类型是numpy中的ndarray类型,注:这里可以通过imutils模块改变图像显示大小
2.3 图像的保存函数 cv2.imwrite()
cv2.imwrite() 函数检查图像保存到本地,官方定义如下:
cv2.imwrite(image_filename, image)
参数解释如下:
- 参数一: 保存的图像名称(字符串)
- 参数二: 图像对象,类型是numpy中的ndarray类型
3,图像显示窗口创建与销毁
当我们使用imshow函数展示图像时,最后需要在程序中对图像展示窗口进行销毁,否则程序将无法正常终止,常用的销毁窗口的函数有下面两个:
(1)、cv2.destroyWindow(windows_name) #销毁单个特定窗口 参数: 将要销毁的窗口的名字 (2)、cv2.destroyAllWindows() #销毁全部窗口,无参数
那我们合适销毁窗口,肯定不能图片窗口一出现我们就将窗口销毁,这样便没法观看窗口,试想有两种方式:
- (1) 让窗口停留一段时间然后自动销毁;
- (2) 接收指定的命令,如接收指定的键盘敲击然后结束我们想要结束的窗口
以上两种情况都将使用cv2.waitKey函数, 首先产看函数定义:
cv2.waitKey(time_of_milliseconds)
唯一参数delay是整数,可正可负也可是零,含义和操作也不同,分别对应上面说的两种情况。
(1) time_of_milliseconds > 0 :
此时time_of_milliseconds表示时间,单位是毫秒,
含义表示等待 time_of_milliseconds毫秒后图像将自动销毁,看以下示例
#表示等待10秒后,将销毁所有图像
if cv2.waitKey(10000):
cv2.destroyAllWindows()
#表示等待10秒,将销毁窗口名称为'origin image'的图像窗口
if cv2.waitKey(10000):
cv2.destroyWindow('origin image')
(2) time_of_milliseconds <= 0 :
此时图像窗口将等待一个键盘敲击,接收到指定的键盘敲击便会进行窗口销毁。
我们可以自定义等待敲击的键盘,通过下面的例子进行更好的解释
#当指定waitKey(0) == 27时当敲击键盘 Esc 时便销毁所有窗口
if cv2.waitKey(0) == 27:
cv2.destroyAllWindows()
#当接收到键盘敲击A时,便销毁名称为'origin image'的图像窗口
if cv2.waitKey(-1) == ord('A'):
cv2.destroyWindow('origin image')
waitKey()函数原型:
C++: int waitKey(int delay=0) Python: cv2.waitKey([delay]) → retval C: int cvWaitKey(int delay=0 ) Python: cv.WaitKey(delay=0) → int
waitKey()函数功能:
waitKey() 函数的功能是不断地刷新图像,频率时间为delay,单位为ms。返回值为当前键盘按键值。
waitKey()函数作用:
1,waitKey() 这个函数是在一个给定的时间内(单位ms)等待用户按键触发;如果用户没有按下键,则继续等待(循环)。
2,如果设置waitKey(0),则表示程序会无限制的等待用户的按键事件。
3,用OpenCV来显示图像或者视频时,如果后面不加cvWaitKey这个函数,基本上是显示不出来的。
4,显示图像,一般要在cvShowImage()函数后面加一句cvWaitKey(0);否则图像无法正常显示。
waitKey()源代码:
def waitKey(delay=None): # real signature unknown; restored from __doc__
"""
waitKey([, delay]) -> retval
. @brief Waits for a pressed key.
.
. The function waitKey waits for a key event infinitely (when \f$\texttt{delay}\leq 0\f$ ) or for delay
. milliseconds, when it is positive. Since the OS has a minimum time between switching threads, the
. function will not wait exactly delay ms, it will wait at least delay ms, depending on what else is
. running on your computer at that time. It returns the code of the pressed key or -1 if no key was
. pressed before the specified time had elapsed.
.
. @note
.
. This function is the only method in HighGUI that can fetch and handle events, so it needs to be
. called periodically for normal event processing unless HighGUI is used within an environment that
. takes care of event processing.
.
. @note
.
. The function only works if there is at least one HighGUI window created and the window is active.
. If there are several HighGUI windows, any of them can be active.
.
. @param delay Delay in milliseconds. 0 is the special value that means "forever".
"""
pass
指定窗口大小模式的属性:
- cv2.WINDOW_AUTOSIZE:根据图像大小自动创建大小
- cv2.WINDOW_NORMAL:窗口大小可调整
# 设置为WINDOW_NORMAL可以任意缩放
# cv.namedWindow('input_image', cv.WINDOW_NORMAL)
代码如下:
import cv2
img = cv2.imread("lena.jpg")
cv2.namedWindow("img", cv2.WINDOW_NORMAL)
cv2.imshow("img", img)
cv2.waitKey()
cv2.destroyAllWindows()
4,视频的读取,处理与保存
(视频读取流程的话:可以达到30fps,即一秒30帧,不过基本都是25~30左右)
cv2.VideoCapture(): 可以捕获摄像头,用数字来控制不同的设备,例如0,1。如果是视频文件,直接指定好路径即可。设备索引只是指定哪台摄像机的号码,0代表第一台摄像机,1代表第二台摄像机。之后就可以逐帧捕获视频,但最后,不要忘记释放捕获。
cap.read():返回一个布尔值(True / False)。如果帧被正确读取,则返回true,否则返回false。可以通过检查这个返回值来判断视频是否结束。
cap.isOpened():检查cap是否被初始化。若没有初始化,则使用cap.open()打开它。当cap没有初始化时,上面的代码会报错。
retval,image= cv2.VideoCapture.read([,image]) 抓取,解码并返回下一个视频帧。返回值为true表明抓取成功。该函数是组合了grab()和retrieve(),这是最方便的方法。如果没有帧,该函数返回false,并输出空图像。
retval, image = cv2.VideoCapture.retrieve([, image[, flag]]) 解码并返回抓取的视频帧
retval = cv2.VideoCapture.grab() 从视频文件或相机中抓取下一帧。true为抓取成功。该函数主要用于多摄像头时。
cv2.VideoCapture.release() 关闭视频文件或相机设备。
cap.get(propId):访问视频的某些功能,其中propId是一个从0到18的数字,每个数字表示视频的属性(Property Identifier)。其中一些值可以使用cap.set(propId,value)进行修改,value是修改后的值。
举个例子:我通过cap.get(3)和cap.get(4)来检查帧的宽度和高度,默认的值是640x480。但我想修改为320x240,可以使用ret = cap.set(3, 320)和ret = cap.set(4, 240)。
propId 常见取值如下:
- cv2.CAP_PROP_POS_MSEC: 视频文件的当前位置(ms)
- cv2.CAP_PROP_POS_FRAMES: 从0开始索引帧,帧位置。
- cv2.CAP_PROP_POS_AVI_RATIO:视频文件的相对位置(0表示开始,1表示结束)
- cv2.CAP_PROP_FRAME_WIDTH: 视频流的帧宽度。
- cv2.CAP_PROP_FRAME_HEIGHT: 视频流的帧高度。
- cv2.CAP_PROP_FPS: 帧率
- cv2.CAP_PROP_FOURCC: 编解码器四字符代码
- cv2.CAP_PROP_FRAME_COUNT: 视频文件的帧数
- cv2.CAP_PROP_FORMAT: retrieve()返回的Mat对象的格式。
- cv2.CAP_PROP_MODE: 后端专用的值,指示当前捕获模式
- cv2.CAP_PROP_BRIGHTNESS:图像的亮度,仅适用于支持的相机
- cv2.CAP_PROP_CONTRAST: 图像对比度,仅适用于相机
- cv2.CAP_PROP_SATURATION:图像饱和度,仅适用于相机
- cv2.CAP_PROP_HUE: 图像色调,仅适用于相机
- cv2.CAP_PROP_GAIN: 图像增益,仅适用于支持的相机
- cv2.CAP_PROP_EXPOSURE: 曝光,仅适用于支持的相机
- cv2.CAP_PROP_CONVERT_RGB:布尔标志,指示是否应将图像转换为RGB。
视频读取与处理代码:
import cv2
# 参数为视频文件目录
videoc = cv2.VideoCapture('test.mp4')
# VideoCapture对象,参数可以是设备索引或视频文件名称,设备索引只是指定哪台摄像机的号码
# 0代表第一台摄像机,1代表第二台摄像机,之后可以逐帧捕获视频,但是最后需要释放捕获
# 调用内置摄像头
# cap = cv2.VideoCapture(0)
# 调用USB摄像头
# cap = cv2.VideoCapture(1)
# 检查是否打开正确
if videoc.isOpened():
open, frame = videoc.read()
else:
open = False
# 逐帧显示实现视频播放
while open:
ret, frame = videoc.read() # 读取
if frame is None:
break
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('result', gray)
if cv2.waitKey(10) & 0xFF == 27: # 读取完自动退出
# if cv2.waitKey(1) & 0xFF == ord('q'): # 读完按 q 退出
break
# 释放摄像头对象和窗口
videoc.release()
cv2.destroyAllWindows()
解释一下从文件中播放视频: 和从相机捕获视频相同,只需要更改相机索引和视频文件名。在显示帧时,选择适当地 cv2.waitKey() 时间,如果该值太小,视频会非常快,如果他太大,则视频会非常慢(这可以用慢动作显示视频)。正常情况下 25毫秒即可。
保存视频:我们需要创建一个 VideoWriter对象,指定输出文件名(例如:output.avi)。之后指定 FourCC代码(FourCC是用于指定视频编码解码器的四字节代码,可用的代码列标:http://www.fourcc.org/codecs.php)。接下来传递每秒帧数(FPS)和帧大小,最后一个是 isColor标注,如果他为TRUE,编码器编码成彩色帧,否则编码成灰度框帧。
视频保存代码:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi',fourcc, 20.0, (640,480))
while(cap.isOpened()):
ret, frame = cap.read()
if ret==True:
frame = cv2.flip(frame,0)
# write the flipped frame
out.write(frame)
cv2.imshow('frame',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
# Release everything if job is finished
cap.release()
out.release()
cv2.destroyAllWindows()
OpenCV提供了接口VideoWriter 用于视频的保存:
<VideoWriter object> = cv.VideoWriter( filename, fourcc, fps, frameSize[, isColor] )
函数参数:
- filename:给要保存的视频起个名字
- fourcc:指定视频编解码器的4字节代码
- 【(‘P’,‘I’,‘M’,‘1’)是MPEG-1编解码器】
- 【(‘M’,‘J’,‘P’,'G ')是一个运动jpeg编解码器】
- fps:帧率
- frameSize:帧大小
- retval = cv2.VideoWriter_fourcc( c1, c2, c3, c4 ) 将4字符串接为fourcc代码。
- cv.VideoWriter.write( image ) 将帧图像保存为视频文件。
- isColor:如果为true,则视频为彩色,否则为灰度视频,默认为true
5,图像ROI
ROI(Region of Interest)表示感兴趣区域。感兴趣区域,就是我们从图像中选择一个图像区域,这个区域就是图像分析所关注的焦点。我们圈定这个区域,那么我们要处理的图像就是要从一个大图像变为小图像区域了,这样以便进行进一步处理,可以大大减少处理时间。
ROI 也是使用Numpy 索引来获得的,其本质上是多维数组(矩阵)的切片,如下图所示:

其实,原理很简单,就是利用数组切片和索引操作来选择指定区域的内容,通过像素矩阵可以直接获取ROI区域,如 img[200:400, 200: 400]。Rect 四个形参分别是:x坐标,y坐标,长,高,注意(x, y)指的是矩形的左上角点。
比如我要获取欧文的头,图如下:

简易的矩形ROI区域获取代码如下
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取原始图像
img = cv2.imread('irving.jpg')
# print(img.shape) # (458, 558, 3)
# 我们自己计算要获取的头部的大小,以及左上角的坐标
# 这里左上角的坐标为:w:h=250 7 区域为100*100
roi_zero = img[7:107, 250:350]
# 显示图像
cv2.imshow("Image", roi_zero)
# 等待显示
cv2.waitKey(0)
cv2.destroyAllWindows()
结果如下:

6,图像宽,高,通道数获取

img.shape 返回图像高(图像矩阵的行数),宽(图像矩阵的列数)和通道数3个属性组成的元组,若图像是非彩色图(即灰度图,二值图等),则只返回高和宽组成的元组。
import cv2
img = cv2.imread("1.jpg")
imgGrey = cv2.imread("1.jpg", 0)
sp1 = img.shape
sp2 = imgGrey.shape
print(sp1)
print(sp2)# ======输出=======#(1200, 1920, 3)#(1200, 1920)
7,图像像素数目和图像数据类型的获取
图像矩阵img 的 size属性和 dtype 分别对应图像的像素总数目和图像数据类型。一般情况下,图像的数据类型是 uint8。
通过size关键字获取图像的像素数目,其中灰度图像返回行数*列数,彩色图像返回行数*列数*通道数。
通过dtype关键字获取图像的数据类型,通常返回 uint8
代码如下:
# -*- coding:utf-8 -*-
import cv2
import numpy
#读取图片
img = cv2.imread("test.jpg", cv2.IMREAD_UNCHANGED)
#获取图像形状
print(img.shape)
#获取像素数目
print(img.size)
#获取图像类型
print(img.dtype)
结果如下:
(615, 327, 3) 603315 # 603315=615*327*3 uint8
注意1:如果图像是灰度图,返回值仅有行数和列数,所以通过检查这个返回值就可以知道加载的是灰度图还是彩色图。img.size可以返回图像的像素数目。
注意2:在debug时, img.dtype 非常重要,因为在OpenCV Python代码中经常出现数据类型的不一致。
8,生成指定大小的空图像
生成指定大小的空图形,方便我们后续填充,空图形是黑色的图(因为指定的是0)。
import cv2
import numpy as np
img = cv2.imread("1.jpg")
imgZero = np.zeros(img.shape, np.uint8)
imgFix = np.zeros((300, 500, 3), np.uint8)
# imgFix = np.zeros((300,500),np.uint8)
cv2.imshow("img", img)
cv2.imshow("imgZero", imgZero)
cv2.imshow("imgFix", imgFix)
cv2.waitKey()
9,访问和操作图像像素
OpenCV中图像矩阵的顺序是 B,G,R。可以直接通过坐标位置访问和操作图像像素。
import cv2
img = cv2.imread("01.jpg")
numb = img[50,100]
print(numb)
img[50,100] = (0,0,255)
cv2.imshow("img",img)
cv2.waitKey()
分开访问图像某一通道像素值也非常方便(下面代码将图像变为白色,即255):
import cv2
img = cv2.imread("01.jpg")
img[0:100,100:200,0] = 255
img[100:200,200:300,1] = 255
img[200:300,300:400,2] = 255
cv2.imshow("img",img)
cv2.waitKey()
Python中,更改图像某一矩形区域的像素值也很方便。
import cv2
img = cv2.imread("01.jpg")
img[0:50,1:100] = (0,0,255)
cv2.imshow("img",img)
cv2.waitKey()
注意:优化
首先我们需要读入一幅图像,然后根据像素的行和列的坐标获取它的像素值。对BGR图像而言,返回值为B,G,R的值,对灰度图像而言,会返回它的灰度值(亮度? intensity)
import cv2
import numpy as np
img=cv2.imread('test.jpg')
px=img[100,100]
print(px)
blue=img[100,100,0]
print(blue)
# 我们可以使用类似的方式修改像素值
img[100,100]=[255,255,255]
print(img[100,100])
## [255 255 255]
注意1:Numpy 是经过优化了的进行快速矩阵运算的软件包,所以我们不推荐逐个获取像素值并修改,这样会很慢,能有矩阵运算就不要循环。
注意2:上面提到的方法被用来选取矩阵的一个区域,比如说 前 5行的后3列。对于获取每一个像素值,也许使用Numpy 的 array.item() 和 array.itemset() 会更好,但是返回是标量。如果你想获得所有 B,G,R的值,你需要使用 array.item() 分割他们。
获取像素值及其修改的更好的方法
import cv2
import numpy as np
img=cv2.imread('test.jpg')
print(img.item(10,10,2))
img.itemset((10,10,2),100)
print(img.item(10,10,2))
# 59
# 100
10,图像颜色通道分离与合并
分离图像通道可以使用 cv2中 split函数,合并则可以使用 merge函数。
import cv2
img = cv2.imread("01.jpg")
b , g , r = cv2.split(img)
# b = cv2.split(img)[0]
# g = cv2.split(img)[1]
# r = cv2.split(img)[2]
merged = cv2.merge([b,g,r])
cv2.imshow("Blue",b)
cv2.imshow("Green",g)
cv2.imshow("Red",r)
cv2.imshow("Merged",merged)
cv2.waitKey()
有时候,我们需要对 BGR 三个通道分别进行操作,这时你就需要把BGR拆分成单个通道,有时你需要把独立通道的图片合成一个BGR图像。下面学习一下拆分及其合并图像通道的cv函数
代码如下:
# _*_coding:utf-8_*_
import cv2
import numpy as np
def split_image(img_path):
img = cv2.imread(img_path)
print(img.shape) # (800, 800, 3)
# b, g, r = cv2.split(img)
b = img[:, :, 0]
g = img[:, :, 1]
r = img[:, :, 2]
cv2.imshow('b', b)
# cv2.imshow('g', g)
# cv2.imshow('r', r)
cv2.waitKey(0)
cv2.destroyAllWindows()
def merge_image(img_path):
img = cv2.imread(img_path)
b, g, r = cv2.split(img)
img = cv2.merge([b, g, r])
cv2.imshow('merge', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
img_path = 'durant.jpg'
split_image(img_path)
# merge_image(img_path)
注意:这里拆分写了两个方法,为什么呢?就是因为 cv2.split()是一个比较耗时的操作,只有真正需要时才用它,能用Numpy索引就尽量使用索引。
原图:

B,G,R 三种通道的图片:
合并后的图片

假设,我们想是所有像素的红色通道值都为0,我们不必先拆分再赋值,我们可以直接使用 Numpy 索引,这样会更快:
def assign_image(img_path):
img = cv2.imread(img_path)
img[:, :, 1] = 0
cv2.imshow('assign', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
img_path = 'durant.jpg'
assign_image(img_path)
结果如下:

11,在图像上输出文字
使用putText函数在图片上输出文字,函数原型:
putText(img, text, org, fontFace, fontScale, color, thickness=None, lineType=None, bottomLeftOrigin=None)
参数意思:
- img: 图像
- text:要输出的文本
- org: 文字的起点坐标
- fontFace: 字体
- fontScale: 字体大小
- color: 字体颜色
- thickness: 字图加粗
代码如下:
import cv2
img = cv2.imread("durant.jpg")
cv2.putText(img, "durant is my favorite super star", (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255))
cv2.imshow("img", img)
cv2.waitKey()
图如下:

12 cv2.cvtColor()函数用法介绍
在日常生活中,我们看到的大多数彩色图像都是RGB类型,但是在图像处理过程中,常常需要用到灰度图像、二值图像、HSV、HSI等颜色,OpenCV提供了cvtColor()函数实现这些功能。其函数原型如下所示:
cvtColor(src, code, dst=None, dstCn=None)
变量含义:
- src表示输入图像,需要进行颜色空间变换的原图像
- dst表示输出图像,其大小和深度与src一致
- code表示转换的代码或标识
- dstCn表示目标图像通道数,其值为0时,则有src和code决定
该函数的作用是将一个图像从一个颜色空间转换到另一个颜色空间,其中,RGB是指Red、Green和Blue,一副图像由这三个通道(channel)构成;Gray表示只有灰度值一个通道;HSV包含Hue(色调)、Saturation(饱和度)和Value(亮度)三个通道。在OpenCV中,常见的颜色空间转换标识包括CV_BGR2BGRA、CV_RGB2GRAY、CV_GRAY2RGB、CV_BGR2HSV、CV_BGR2XYZ、CV_BGR2HLS等。
下面代码对比了九种常见的颜色空间,包括BGR、RGB、GRAY、HSV、YCrCb、HLS、XYZ、LAB和YUV,并循环显示处理后的图像。
#encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像
img_BGR = cv2.imread('durant.jpg')
#BGR转换为RGB
img_RGB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)
#灰度化处理
img_GRAY = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2GRAY)
#BGR转HSV
img_HSV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HSV)
#BGR转YCrCb
img_YCrCb = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YCrCb)
#BGR转HLS
img_HLS = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HLS)
#BGR转XYZ
img_XYZ = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2XYZ)
#BGR转LAB
img_LAB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2LAB)
#BGR转YUV
img_YUV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YUV)
#调用matplotlib显示处理结果
titles = ['BGR', 'RGB', 'GRAY', 'HSV', 'YCrCb', 'HLS', 'XYZ', 'LAB', 'YUV']
images = [img_BGR, img_RGB, img_GRAY, img_HSV, img_YCrCb,
img_HLS, img_XYZ, img_LAB, img_YUV]
for i in xrange(9):
plt.subplot(3, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
效果图如下:

如果想查看参数的全部类型,请执行以下程序便可查阅,总共有274种空间转换类型:
import cv2
flags = [i for i in dir(cv2) if i.startswith('COLOR_')]
print(flags)
12.1, BGR2YUV
(参考地址:https://zhuanlan.zhihu.com/p/98622289)
OpenCV BGR 图转 YUV图的的C++源码如下:
// file name: convert.cpp
#include <opencv2/opencv.hpp>
// BGR 转 YUV
void BGR2YUV(const cv::Mat bgrImg, cv::Mat &y, cv::Mat &u, cv::Mat &v) {
cv::Mat out;
cv::cvtColor(bgrImg, out, cv::COLOR_BGR2YUV);
bgr
cv::bgr channel[3];
cv::split(out, channel);
y = channel[0];
u = channel[1];
v = channel[2];
}
// YUV 转 BGR
void YUV2BGR(const cv::Mat y, const cv::Mat u, const cv::Mat v, cv::Mat& bgrImg) {
std::vector<cv::Mat> inChannels;
inChannels.push_back(y);
inChannels.push_back(u);
inChannels.push_back(v);
// 合并3个单独的 channel 进一个矩阵
cv::Mat yuvImg;
cv::merge(inChannels, yuvImg);
cv::cvtColor(yuvImg, bgrImg, cv::COLOR_YUV2BGR);
}
// 使用例子
int main() {
cv::Mat origImg = cv::imread("test.png");
cv::Mat y, u, v;
BGR2YUV(origImg, y, u, v);
cv::Mat bgrImg;
YUV2BGR(y, u, v, bgrImg);
cv::imshow("origImg", origImg);
cv::imshow("Y channel", y);
cv::imshow("U channel", u);
cv::imshow("V channel", v);
cv::imshow("converted bgrImg", bgrImg);
cv::waitKey(0);
return 0;
}
在python中测试如下:
import cv2
import matplotlib.pyplot as plt
def bgr2yuv(img):
yuv_img = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)
y, u, v = cv2.split(yuv_img)
return y, u, v
def yuv2bgr(y, u, v):
yuv_img = cv2.merge([y, u, v])
bgr_img = cv2.cvtColor(yuv_img, cv2.COLOR_YUV2BGR)
return bgr_img
def main():
orig_img = cv2.imread('durant.jpg')
gray = cv2.cvtColor(orig_img, cv2.COLOR_BGR2GRAY)
y, u, v = bgr2yuv(orig_img)
bgr_img = yuv2bgr(y, u, v)
titles = ['orig_img', 'gray', 'Y channel','U channel','V channel','bgr_img']
images = [orig_img, gray, y, u, v, bgr_img]
for i in range(len(titles)):
plt.subplot(2, 3, i+1)
plt.imshow(images[i])
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
if __name__ == '__main__':
main()
图如下:
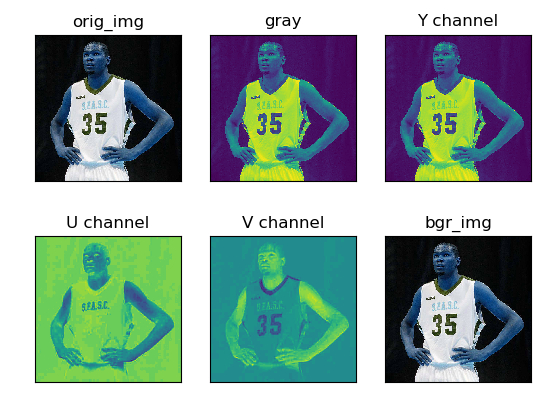
下面区分一下YUV和YCbCr,YUV色彩模型来源于RGB模型,该模型的特点是将亮度和色度分离开,从而适合于图像处理领域。
应用:模拟领域
Y'= 0.299*R' + 0.587*G' + 0.114*B'
U'= -0.147*R' - 0.289*G' + 0.436*B' = 0.492*(B'- Y')
V'= 0.615*R' - 0.515*G' - 0.100*B' = 0.877*(R'- Y')
R' = Y' + 1.140*V'
G' = Y' - 0.394*U' - 0.581*V'
B' = Y' + 2.032*U'
YCbCr模型来源于YUV模型。YCbCr是 YUV 颜色空间的偏移版本,应用:数字视频,ITU-R BT.601建议
Y’ = 0.257*R' + 0.504*G' + 0.098*B' + 16
Cb' = -0.148*R' - 0.291*G' + 0.439*B' + 128
Cr' = 0.439*R' - 0.368*G' - 0.071*B' + 128
R' = 1.164*(Y’-16) + 1.596*(Cr'-128)
G' = 1.164*(Y’-16) - 0.813*(Cr'-128) - 0.392*(Cb'-128)
B' = 1.164*(Y’-16) + 2.017*(Cb'-128)
参考文献:https://blog.csdn.net/woainishifu/article/details/53260546
https://blog.csdn.net/eastmount/article/details/82177300
https://www.cnblogs.com/Undo-self-blog/p/8434906.html
https://www.cnblogs.com/zlel/p/9267629.html
视频读取:https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_gui/py_video_display/py_video_display.html
https://blog.csdn.net/qq_25436597/article/details/79621833
https://zhuanlan.zhihu.com/p/44255577
OpenCV中的rgb2Yuv转换公式问题:https://bbs.csdn.net/topics/390713769

