
我的Keras使用总结(5)——Keras指定显卡且限制显存用量,常见函数的用法及其习题练习
完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
Keras 是一个高层神经网络API,Keras是由纯Python编写而成并基于TensorFlow,Theano以及CNTK后端。Keras为支持快速实验而生,能够将我们的idea迅速转换为结果。好了不吹了,下面继续学习Keras的一些用法,其中这篇博客包括了Keras如何指定显卡且限制显存用量,还有一些常见函数的用法及其问题,最后是使用Keras进行的练习。
Keras如何指定显卡且限制显存用量
Keras在使用GPU的时候有个特点,就是默认全部占满显存。若单核GPU也无所谓,若是服务器GPU较多,性能较好,全部沾满就太浪费了。
于是有以下五种情况:
- 1,指定GPU
- 2,使用固定显存的GPU
- 3,指定GPU+固定显存
- 4,GPU动态增长
- 5,CPU充分占用
- 6,tf.keras 使用多 GPU
1,固定 GPU 的显存
本节来自:深度学习 tehano/tensorflow 多显卡多人使用问题集(参见:Limit the resource usage for tensorflow backend · Issue #1538 · fchollet/keras · GitHub)
在使用keras时候会出现总是占满 GPU 显存的情况,可以通过重设 backend 的GPU占用情况来进行调节
import tensorflow as tf from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 set_session(tf.Session(config=config))
需要注意的是,虽然代码或配置层面设置了对显存占用百分比阈值,但在实际运行中如果达到了这个阈值,程序有需要的话还是会突破这个阈值。换而言之如果跑在一个大数据集上还是会用到更多的显存。以上的显存限制仅仅为了在跑小数据集时避免对显存的浪费而已。
2,使用指定的GPU
比如下面代码:
import os os.environ["CUDA_VISIBLE_DEVICES"] = "2"
此时的代码为选择了编号为2的GPU。
下面代码我们设置了8个GPU,(当然这是假的哈)
# python设置系统变量的方法 os.environ["CUDA_VISIBLE_DEVICES"] = "8,9,10,11,12,13,14,15"
注意,在代码中指定设备时,重新从 0 开始计,而不是从8开始。
3,指定GPU+固定显存
上面两个连在一起用就OK:
import os import tensorflow as tf os.environ["CUDA_VISIBLE_DEVICES"] = "2" from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 set_session(tf.Session(config=config))
那么在命令行,可以使用:https://github.com/tensorflow/nmt/issues/60
CUDA_VISIBLE_DEVICES=0 python -m nmt.nmt
4,GPU动态增长
import keras.backend.tensorflow_backend as KTF import tensorflow as tf import os os.environ["CUDA_VISIBLE_DEVICES"] = "1" config = tf.ConfigProto() config.gpu_options.allow_growth=True #不全部占满显存, 按需分配 sess = tf.Session(config=config) KTF.set_session(sess)
os.environ 指的时占用的 GPU编号;allow_growth 为动态申请显存占用。
5,CPU充分占用
num_cores = 4
config = tf.ConfigProto(intra_op_parallelism_threads=num_cores, inter_op_parallelism_threads=num_cores,
allow_soft_placement=True, device_count={'CPU': 4})
session = tf.Session(config=config)
K.set_session(session)
其中:
- device_count, 告诉tf Session使用CPU数量上限,如果你的CPU数量较多,可以适当加大这个值
- inter_op_parallelism_threads和intra_op_parallelism_threads告诉session操作的线程并行程度,如果值越小,线程的复用就越少,越可能使用较多的CPU核数。如果值为0,TF会自动选择一个合适的值。
- allow_soft_placement=True, 有时候,不同的设备,它的cpu和gpu是不同的,如果将这个选项设置成True,那么当运行设备不满足要求时,会自动分配GPU或者CPU。
6,tf.keras 使用多 GPU
DistributionStrategy API是构建多设备/机器训练的简单方式,开发者只需要在现有模型上做少量的修改,就可以用它们进行分布式训练。另外,DistributionStrategy在设计时考虑了同时兼容动态图(eager)和静态图。
参考:TensorFlow 1.11.0发布,一键多GPU(训练、预测和评价tf.keras模型)
目前TensorFlow支持三种DistributionStrategy:
- MirroredStrategy
- CollectiveAllReduceStrategy
- ParameterServerStrategy
在tf.keras中直接使用DistributionStrategy
最新的TensorFlow Github中给出了在tf.keras中直接使用DistributionStrategy的例子。
用tf.keras构建一个单层网络:
inputs = tf.keras.layers.Input(shape=(1,)) predictions = tf.keras.layers.Dense(1)(inputs) model = tf.keras.models.Model(inputs=inputs, outputs=predictions)
目前,使用DistributionStrategy需要使用tf.data.Dataset来作为数据输入:
features = tf.data.Dataset.from_tensors([1.]).repeat(10000).batch(10) labels = tf.data.Dataset.from_tensors([1.]).repeat(10000).batch(10) train_dataset = tf.data.Dataset.zip((features, labels))
这里我们为模型指定使用MirroredStrategy进行多GPU训练,代码非常简单:
distribution = tf.contrib.distribute.MirroredStrategy()
model.compile(loss='mean_squared_error',
optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.2),
distribute=distribution)
使用常规的训练、评价和预测方法会自动在多GPU上进行:
model.fit(train_dataset, epochs=5, steps_per_epoch=10) model.evaluate(eval_dataset) model.predict(predict_dataset)
将tf.keras模型迁移到多GPU上运行只需要上面这些代码,它会自动切分输入、在每个设备(GPU)上复制层和变量、合并和更新梯度。
7,OpenBLASblas_thread_initpthread_creatResourcetemporarilyunavailable问题分析与解决
7.1 报错情况
我直接运行我的代码会报错如下:

问题太多了,但是解决方法好像很简单
7.2 解决方法
参考文献:https://zhuanlan.zhihu.com/p/23250782
TensorFlow 如果单纯使用 TensorFlow的话,可以用代码控制:
config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.4 session = tf.Session(config=config, ...)
如果使用Keras作为前端,也可以用代码控制:
import tensorflow as tf from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 set_session(tf.Session(config=config))
这样一来,就可以让同一块显卡同时执行多程序了,cuda流处理器也可以和多核CPU一样满足多程序运行。
需要注意的是,虽然代码或配置层面设置了对显存占用百分比阈值,但在实际运行中如果达到了这个阈值,程序有需要的话还是会突破这个阈值(用theano后端会如此,tensorflow可能会报资源耗尽错,2020年7月20日补充)。换而言之如果跑在一个大数据集上还是会用到更多的显存。以上的显存限制仅仅为了在跑小数据集时避免对显存的浪费而已。
常见函数的用法
1,fit() 和 fit_generator() 区别以及参数的坑
参考地址:https://blog.csdn.net/mlp750303040/article/details/89207658 https://blog.csdn.net/learning_tortosie/article/details/85243310
首先Keras中的 fit() 函数传入的 x_train 和 y_train 是被完整的加载进内存的,当然用起来很方便,但是如果我们数据量很大,那么是不可能将所有数据载入内存的,必将导致内存泄露,这时候我们可以用 fit_generator 函数来进行训练。
1.1 fit() 函数
下面是 fit 传参的例子:
history = model.fit(x_train, y_train, epochs=10,batch_size=32,
validation_split=0.2)
在这里我们看到提供的训练数据(trainX)和训练标签(trainY),然后这里需要给出 epochs 和 batch_size,epoch是这个数据集要被训练多少次,batch_size 是这个数据集被分成多少个 batch 进行处理。最后给出交叉验证集的大小,这里的 0.2 是指在训练集上占比 20%。
使用 .fit() 函数,这里需要做两个假设:
- 1,我们的整个训练集可以放在 RAM
- 2,没有数据增强(即不需要Keras生成器)
相反,我们的网络将在原始数据上训练,原始数据本身将适合内存,我们无需将旧批量数据从 RAM 中移出并将新批量数据移入RAM。此外,我们不会使用数据增强动态操纵训练数据。
1.2 fit_generator() 函数
对于小型,简单化的数据集,使用Keras的 .fit 函数是完全可以接受的。这些小型数据集通常不是很具有挑战性,不需要任何数据增强。
但是,真实世界的数据集很少这么简单:
- 真实世界的数据结构通常太大而无法放入内存中
- 他们也往往具有挑战性,要求我们执行数据增强以避免过拟合并增加我们模型的泛化能力
在这些情况下,我们需要利用 Keras的 .fit_generator() 函数。
fit_generator() 函数必须传入一个生成器,我们的训练数据也是通过生成器产生的,下面给出一个简单的生成器例子:
# initialize the number of epochs and batch size
EPOCHS = 100
BS = 32
# construct the training image generator for data augmentation
aug = ImageDataGenerator(rotation_range=20, zoom_range=0.15,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
horizontal_flip=True, fill_mode="nearest")
这里的生成器函数我生成的是一个 batch_size 为 32大小的数据,这里只是一个demo,如果在生成器里没有规定 batch_size 的大小,就是每次产生一个数据,那么在用 fit_generator 的时候里面的参数 steps_per_epoch 是不一样的(这个问题后面讲,这里不再赘述)
下面是 fit_generator() 函数的传参:
# train the network
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
我们首先会初始化将要训练的网络的 epoch和batch size,然后我们初始化 aug,这是一个 Keras ImageDataGenerator 对象,用于图像的数据增强,随机平移,旋转,调整大小等。
执行数据增强是正则化的一种形式,使我们的模型能够更好的被泛化。但是应用数据增强意味着我们的训练数据不再是“静态的”,而数据不断在变换。根据提供给ImageDataGenerator的参数随机调整每批新数据,因此我们需要利用Keras的 .fit_generator 函数来训练我们的模型。顾名思义, .fit_generator() 函数假定存在一个为其生成数据的基础函数。该函数本身是一个 Python生成器。
所以Keras在使用 .fit_generator() 训练模型的过程中:
- Keras调用提供给 .fit_generator 的生成器函数(在本例为 aug.flow)
- 生成器函数为 .fit_generator() 函数生成一大批为 batch size 的数据
- .fit_generator() 函数接受批量数据,执行反向传播,并更新模型中的权重
- 重复该过程直到达到期望的 epoch 数量
下面说一下为什么我们需要 steps_per_epoch?
请记住,Keras数据生成器意味着无限循环,它永远不会返回或退出。
而steps_per_epoch:是在声明一个epoch完成并开始下一个epoch之前从发生器产生的步骤(样本批次)的总数,它通常应该等于数据集的唯一样本数除以批量大小。
由于该函数旨在无限循环,因此 Keras无法确定一个 epoch何时开始,并且新的 epoch何时开始。因此我们将训练数据的总数除以批量大小的结果作为 steps_per_epoch 的值,一旦Keras到达这一步,它就会知道这是一个新的 epoch。所以当使用 fit_generator 增加 batch_size时,如果希望训练时间保持不变或者更低,则应将 steps_per_epochs 减少相同的因子。
所以我们使用fit_generator() 函数的时候,一般需要将 steps_per_epoch 和 validation_steps写成活参,如下:
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size
)
注意这里的 nb_train_samples 和 nb_validation_samples 需要我们自己找一下,看看自己的训练集和验证集的数据总共有多少个。
2,回调函数callback
官方文档:https://keras.io/zh/callbacks/
回调函数是一组在训练的特定阶段被调用的函数集,你可以使用回调函数来观察训练过程中网络内部的状态和统计信息。通过传递回调函数列表到模型的 .fit() 中,即可在给定的训练阶段调用该函数集中的函数。
Tips:虽然我们称之为“回调函数”,事实上Keras的回调函数是一个类,回调函数只是习惯性称呼。
callback模块中常用的类和函数有12个,但是下面只学习几个常用的类。

2.1,Callback
keras.callbacks.Callback()
这是回调函数的抽象类,定义新的回调函数必须继承该类。
类属性:
- params:字典,训练参数集(如信息显示方法 verbosity,batch大小,epoch数)
- model:keras.models.Model对象,为正在训练的模型的引用
回调函数以字典 logs 为参数,该字典包含了一系列与当前 batch 或 epoch相关的信息。
目前,模型的 .fit() 中有下列参数会被记录到logs中:
- 在每个epoch的结尾处(on_epoch_end),logs将包含训练的正确率和误差,acc和loss,如果指定了验证集,还会包含验证集正确率和误差 val_acc 和 val_loss,val_acc 还额外需要在 .compile中启用 metrics=['accuracy']。
- 在每个 batch 的开始处(on_batch_begin):logs包含size,即当前batch的样本数
- 在每个batch的结尾处(on_batch_end):logs包含loss,若启用 accuracy则还包含acc
on_epoch_begin #在每轮开始时被调用 on_epoch_end #在每轮结束时被调用 on_batch_begin #在处理每个批量之前被调用 on_batch_end #在处理每个批量之后被调用 on_train_begin #在训练开始时被调用 on_train_end #在训练结束时被调用
2.2 EarlyStopping
earlystopping 是Callbacks 的一种,callbacks 用于指定在每个 epoch 开始和结束的时候进行哪种特定的操作。Callbacks中有一些设置好的接口,可以直接使用,如'acc','val_acc', 'loss','val_loss'等等。EarlyStopping则是用于提前停止训练的 callbacks。具体的,可以达到当训练集上的 loss 不再减少(即减小的程度小于某个阈值)的时候停止训练。
为什么要使用 earlystopping?
当我们训练深度学习神经网络的时候通常希望能够获得最好的泛化性能(generalization performance,即可以很好的拟合数据),但是所有的标准深度网络结构如全连接多层感知机都很容易过拟合。常用的防止过拟合的方法是对模型加正则项,如L1,L2,dropout,但深度神经网络希望通过加深网络层次减少优化的参数,同时可以得到更好的优化结果,Early stopping 的使用可以在模型训练整个过程中截取保存结构最优的参数模型,防止过拟合。
earlystopping 旨在解决 epoch 数量需要手动设置的问题。它也可以被视为一种能够避免网络发生过拟合的正则化方法(与L1,L2权重衰减和丢弃法类似)。根本原因就是因为继续训练会导致测试集上的准确率下降。那么继续训练导致测试准确率下降的原因猜测可能是:1,过拟合;2,学习率过大导致不收敛;3,使用正则项的时候,loss的减少可能不是因为准确率增加导致的,而是因为权重大小的降低。
earlystopping 的原理
1,将数据分为训练集和验证集
2,每个 epoch结束后(或者每N个epoch后):在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练
3,将停止之后的权重作为网络的最终参数
这种做法很符合直观感受,因为精度都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为验证集精度不再提高了,因为可能经过这个Epoch后,精度降低了,但是随后的Epoch又让精度又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的验证集精度,当连续10次Epoch(或者更多次)没达到最佳精度时,则可以认为精度不再提高了。
keras.callbacks.EarlyStopping(monitor='val_loss', patience=0, verbose=0, mode='auto')
当监测值不再改善时,该回调函数将终止训练。
参数:
- monitor:需要监视的量,有’acc’,’val_acc’,’loss’,’val_loss’等等。正常情况下如果有验证集,就用’val_acc’或者’val_loss’。但是如果没有单设验证集,就只能用’acc’了
- patience:能够容忍多少个 epoch 内都没有improvement,这个设置其实是在抖动和真正的准确率下降之间做 trade off。如果 patience设置的大,那么最终得到的准确率要略低于模型可以达到的最高准确率;如果patience设置的小,那么模型很可能在前期抖动,还在全图搜索的阶段就停止了,准确率一般很差。patience的大小和 learning rate 直接相关。当 early stop被激活(如果发现loss相比上一个epoch训练没有下降),则经过patience个epoch后停止训练
- verbose:信息展示模型
- model:‘auto’,‘min’,‘max’之一,在 min模式下,如果检测值停止下降则终止训练。在 max模式下,当检测值不再上升则停止训练。例如,当监测值为 val_acc 时,模式应该为 max,当监测值为 val_loss 时,模式应为 min。在auto模式下,评价准则由被监测值的名字自动推断
2.3 LearningRateScheduler
keras.callbacks.LearningRateScheduler(schedule)
该回调函数是学习率调度器
参数:
- schedule:函数,该函数以 epoch号为参数(从0算起的整数),返回一个新的学习率(浮点数)
2.4 ModelCheckpoint
Keras中的模型主要包括model和weight两个部分,保存Keras的model文件和载入Keras文件的方法有很多,这里分别学习一下。
保存model部分的主要方法:
1,通过 json 文件:
# serialize model to JSON
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
2,通过Yaml文件:
# save as YAML yaml_string = model.to_yaml()
3,通过 hdf5文件:
# 保存权重系数
# serialize weights to HDF5
model.save_weights("model.h5")
print("Saved model to disk")
# 同时保存 model 和权重的方法
model.save('model_weight.h5') # creates a HDF5 file 'my_model.h5'
# 载入权重和载入模型
from keras.models import load_model
model = load_model('model.h5')
loaded_model.load_weights("model.h5")
但是这里主要学习一下ModelCheckpoint方法:
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
在每个训练器之后保存模型。
参数说明:
- filepath:字符串,保存模型的路径
- monitor:需要监视的值,val_acc 或者 val_loss
- verbose:信息展示模式,0或者1(checkpoint 的保存信息,类似于Epoch 000001:saving model to...)
- save_best_only:当设置为True时,监测值有改进时才会保存当前的模型(the lastest best model according to the quantity monitored will not be overweitten)
- model:'auto', ‘min’,‘max’之一,在 save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为 val_acc 时,模式应该为 max,当监测值为 val_loss 时,模式应为 min。在auto模式下,评价准则由被监测值的名字自动推断
- save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
- period:checkpoint之间的间隔的 epoch数
注意1:filepath 可以包括命名格式选项,可以由 epoch的值和 logs的键(由on_epoch_end 参数传递)来填充。
例如:如果 filepath 是 weights.{epoch:02d}-{val_loss:.2f}.hdf5,那么模型被保存的文件名就会有训练轮数和验证损失。
注意2:我们需要在 model.fit 添加 callbacks = [checkpoint] 实现回调。
举一个我实际的例子:
# 训练参数设置
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=6, verbose=1)
BATCH_SIZE = 32
gen = Generator(bbox_util, BATCH_SIZE, lines[:num_train], lines[num_train:],
(input_shape[0], input_shape[1]),NUM_CLASSES, do_crop=True)
model.compile(optimizer=Adam(lr=1e-4),loss=MultiboxLoss(NUM_CLASSES, neg_pos_ratio=5.0).compute_loss)
model.fit_generator(gen.generate(True),
steps_per_epoch=num_train//BATCH_SIZE,
validation_data=gen.generate(False),
validation_steps=num_val//BATCH_SIZE,
epochs=100,
initial_epoch=0,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
2.5 ReduceLROnPlateau
定义学习率之后,经过一定epoch迭代之后,在训练过程中如果出现了损失稳定(loss plateau),即损失率不怎么变化时,需要在训练过程中缩小学习率,进而提升模型。如何在训练过程中缩小学习率呢?我们可以使用Keras中的回调函数ReduceLrOnPlateau,与EarlyStopping 配合使用,会非常方便。
为什么初始化一个非常小的学习率呢?因为初始的学习率过小,会需要非常多次的迭代才能使模型达到最优状态,训练缓慢。如果训练过程中不断缩小学习率,可以快速又精确的获得最优模型。
from keras.callbacks import ReduceLROnPlateau
'''
monitor:监测的值,可以是accuracy,val_loss,val_accuracy
factor:缩放学习率的值,学习率将以lr = lr*factor的形式被减少
patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
mode:‘auto’,‘min’,‘max’之一 默认‘auto’就行
epsilon:阈值,用来确定是否进入检测值的“平原区”
cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
min_lr:学习率最小值,能缩小到的下限
'''
Reduce=ReduceLROnPlateau(monitor='val_accuracy',
factor=0.1,
patience=2,
verbose=1,
mode='auto',
epsilon=0.0001,
cooldown=0,
min_lr=0)
callbacks_list = [
keras.callbacks.ReduceLROnPlateau(
monitor='val_loss' ←------ 监控模型的验证损失
factor=0.1, ←------ 触发时将学习率除以10
patience=10, ←------ 如果验证损失在10轮内都没有改善,那么就触发这个回调函数
)
]
2.6 回调函数 CSVLogger
定义在:tensorflow/python/keras/callbacks.py。
将epoch(迭代次数)结果流式传入到cvs文件的回调。支持所有可以表示为字符串的值,包括一维迭代,如 np.ndarray。
示例:
csv_logger = CSVLogger('training.log')
model.fit(X_train, Y_train, callbacks=[csv_logger])
参数:
- filename:cvs文件的文件名
- separator:用于分割csv文件中的元素的字符串
- append:True(如果文件存在则追加,对继续训练很有用),False(覆盖现有文件)
2.7 官网例子:记录损失历史
代码如下:
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
def on_batch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
model = Sequential()
model.add(Dense(10, input_dim=784, kernel_initializer='uniform'))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
history = LossHistory()
model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=0, callbacks=[history])
print(history.losses)
# 输出
'''
[0.66047596406559383, 0.3547245744908703, ..., 0.25953155204159617, 0.25901699725311789]
'''
2.8 官网例子:模型检查点
代码如下:
from keras.callbacks import ModelCheckpoint
model = Sequential()
model.add(Dense(10, input_dim=784, kernel_initializer='uniform'))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
'''
如果验证损失下降, 那么在每个训练轮之后保存模型。
'''
checkpointer = ModelCheckpoint(filepath='/tmp/weights.hdf5', verbose=1, save_best_only=True)
model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=0,
validation_data=(X_test, Y_test), callbacks=[checkpointer])
2.9 例子:提前终止训练
代码如下:
train_generator, validation_generator, count1, count2 = generate(batch, size)
model = MobileNetv2((size, size, 3), num_classes)
opt = Adam()
earlystop = EarlyStopping(monitor='val_acc', patience=30, verbose=0, mode='auto')
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
history = model.fit_generator(
train_generator,
validation_data=validation_generator,
steps_per_epoch=count1 // batch,
validation_steps=count2 // batch,
epochs=epochs,
callbacks=[earlystop]
)
model.save('model/model.h5')
2.10 例子:编写自己的回调函数
(参考文献:https://www.kancloud.cn/mikl_maple/python/1726322)
调函数中,那么可以编写你自己的回调函数,回调函数的实现方法是创建 Keras.callbacks.Callback 类的子类。然后你可以实现下面这些方法(从名称中即可看出这些方法的作用),他们分别在训练过程中的不同时间段被调用。
n_epoch_begin ←------ 在每轮开始时被调用 on_epoch_end ←------ 在每轮结束时被调用 on_batch_begin ←------ 在处理每个批量之前被调用 on_batch_end ←------ 在处理每个批量之后被调用 on_train_begin ←------ 在训练开始时被调用 on_train_end ←------ 在训练结束时被调用
这些方法被调用时都有一个 logs 参数,这个参数是一个字典,里面包含前一个批量,前一个轮次或者前一次训练的信息,即训练指标和验证指标等。此外,回调函数还可以访问下列属性。
self.model:调用回调函数的模型实例。self.validation_data:传入fit作为验证数据的值。
下面是一个自定义回调函数的简单示例,它可以在每轮结束后将模型每层的激活保存到硬盘(格式为 Numpy 数组),这个激活是对验证集的第一个样本计算得到的。
import keras
import numpy as np
class ActivationLogger(keras.callbacks.Callback):
def set_model(self, model):
self.model = model #在训练之前由父模型调用,告诉回调函数是哪个模型在调用它
layer_outputs = [layer.output for layer in model.layers]
self.activations_model = keras.models.Model(model.input,
layer_outputs) #模型实例,返回每层的激活
def on_epoch_end(self, epoch, logs=None):
if self.validation_data is None:
raise RuntimeError('Requires validation_data.')
validation_sample = self.validation_data[0][0:1] #获取验证数据的第一个输入样本
activations = self.activations_model.predict(validation_sample)
f = open('activations_at_epoch_' + str(epoch) + '.npz', 'w') #(以下3行)将数组保存到硬盘
np.savez(f, activations)
f.close()
我的回调代码如下:
class myCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
if (logs.get('acc') > 0.95):
print("\nReached 95% accuracy so cancelling training !")
self.model.stop_training = True
习题练习
(参考地址:https://zhuanlan.zhihu.com/p/103049619)
1,导入
1.1,导入Keras库,并打印版本信息
import keras print(keras.__version__) # 2.2.4
2,一个简单的例子
使用MLP模型实现手写数字图像MNIST的分类

2.1 选择模型
Keras中的模型分为序贯模型和函数式模型,我们这里初始化一个顺序模型(Sequential)
model = Sequential()
2.2 构建网络层
网络层分为输入层,隐藏层,输出层。我们为模型model加入一个784输入,784输出的隐藏层,激活函数使用relu。
model.add(Dense(units=784, activation='relu', input_dim=784))
在上面的基础上,我们为model加入10个输出的输出层,激活函数使用softmax。
model.add(Dense(units=10, activation='softmax'))
最后可以通过 .summary() 查看模型参数情况
model.summary()
2.3 编译模型
编译模型的过程主要分为三个,分别是优化函数的选择,损失函数的选择,性能评估指标的选择。
我们使用.compile() 来配置学习过程,代价函数 loss 使用 categorical_crossentropy,优化算法 optimizer使用 sgd,性能的指标使用 accuracy。
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
2.4 训练模型
首先读入数据
from keras.datasets import mnist (X_train, y_train), (X_test, y_test) = mnist.load_data()
然后将y值进行one-hot编码
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
将数据送入模型训练
model.fit(X_train, y_train, epochs=5, batch_size=32)
评估模型性能
score = model.evaluate(X_test, y_test, batch_size=128)
print('loss:', score[0])
print('accu:', score[1])
2.5 模型预测
使用模型进行预测
model.predict_classes(X_test, batch_size=128)
2.6 完整代码
我们这里完整代码有数据预处理,我们可以很清楚的看到我们特意将数据reshape成一维数据,从最简单的开始,我们是将28*28的灰度图转化为 784的一维数据。
完整的代码如下:
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.datasets import mnist
from keras.utils import to_categorical
import numpy as np
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# print(X_train.shape[0])
X_train, X_test = X_train.reshape(X_train.shape[0], 784), X_test.reshape(X_test.shape[0], 784)
X_train, X_test = X_train.astype('float32'), X_test.astype('float32')
X_train /= 255
X_test /= 255
y_train, y_test = to_categorical(y_train, num_classes=10), to_categorical(y_test, num_classes=10)
model = Sequential()
model.add(Dense(units=784, activation='relu', input_dim=784))
model.add(Dense(units=10, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5, batch_size=32)
score = model.evaluate(X_test, y_test, batch_size=128)
print('loss:', score[0])
print('accu:', score[1])
model.predict_classes(X_test, batch_size=128)
结果如下:
128/10000 [..............................] - ETA: 3s 2176/10000 [=====>........................] - ETA: 0s 4224/10000 [===========>..................] - ETA: 0s 6528/10000 [==================>...........] - ETA: 0s 8704/10000 [=========================>....] - ETA: 0s 10000/10000 [==============================] - 0s 28us/step loss: 0.20326514495611192 accu: 0.9421
3,一个稍微复杂的例子
使用LeNet5 实现CIFAR10数据集的分类

3.1 选择模型
我们这里仍然初始化一个顺序模型(Sequential)
model = Sequential()
3.2 构建网络层
完成input_c1:添加一个二维卷积层,输入为32*32*3,卷积核大小为5*5,核种类6个,并且假设我们漏了relu
model.add(Conv2D(6, (5, 5), input_shape=(32, 32, 3)))
刚刚漏了relu,现在可以另外加上
model.add(Activation('relu'))
完成C1-S1:2*2 下采样层
model.add(MaxPooling2D(pool_size=(2, 2)))
完成S2-C3:二维卷积,16个内核,5*5的大小,别忘记relu
model.add(Conv2D(16, (5, 5), activation='relu'))
完成C3-S4:2*2下采样层
model.add(MaxPooling2D(pool_size=(2, 2)))
完成S4-C5:先添加平坦层,(也就是碾平数据),再添加全连接层,输入120维,激活函数relu
model.add(Flatten()) model.add(Dense(120, activation='relu'))
完成C5-F6:添加全连接层,84个输出,激活函数relu
model.add(Dense(84, activation='relu'))
完成F6-OUTPUT:添加全连接层,10个输出,激活函数 softmax
model.add(Dense(10, activation='softmax'))
最后可以通过 .summary() 查看模型参数情况
model.summary()
3.3 编译模型
编译模型的过程主要分为三个,分别是优化函数的选择,损失函数的选择,性能评估指标的选择。
首先我们设置随机梯度下降SGD优化算法的参数。我们learning_rate=0.01, epoch=25, decay=learning_rate/epoch, momentum=0.9, nesterov=False
from keras.optimizers import SGD learning_rate = 0.01 epoch = 10 decay = learning_rate / epoch sgd = SGD(lr=learning_rate, momentum=0.9, decay=decay, nesterov=False)
编译模型,代价函数loss使用categorical_crossentropy,优化算法前面已经定义了,性能指标使用accuracy。
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
3.4 训练模型
首先读入数据
from keras.datasets import cifar (X_train, y_train), (X_test, y_test) = cifar.load_data()
然后将y值进行one-hot编码(预处理)
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
将数据送入模型训练,并且设置20%为验证集
history = model.fit(X_train, y_train, validation_split=0.2, epochs=10, batch_size=32, verbose=1)
然后可以可视化历史训练的训练集及验证集的准确率值,以及可视化历史训练的训练集及验证集的损失值。
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend(['Train', 'val'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.legend(['Train', 'val'], loc='upper left')
plt.show()
模型评估
score = model.evaluate(X_test, y_test, verbose=0)
print(model.metrics_names)
print('loss:', score[0])
print('accu:', score[1])
3.5 模型预测
使用模型进行预测
prediction = model.predict_classes(X_test) print(prediction[:10])
显示混淆矩阵
# 显示混淆矩阵 import pandas as pd print(classes) pd.crosstab(y_gt.reshape(-1),prediction,rownames=['label'],colnames=['predict'])
3.6 完整代码
代码如下:
from keras.models import Sequential
from keras.layers import Conv2D, Activation, MaxPooling2D, Flatten, Dense
from keras.datasets import cifar10
from keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
from keras.optimizers import SGD
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train, X_test = X_train.astype('float32'), X_test.astype('float32')
X_train /= 255.0
X_test /= 255.0
y_train, y_test = to_categorical(y_train, num_classes=10), to_categorical(y_test, num_classes=10)
learning_rate = 0.001
epoch = 10
decay = learning_rate / epoch
sgd = SGD(lr=learning_rate, momentum=0.9, decay=decay, nesterov=False)
model = Sequential()
model.add(Conv2D(6, (5, 5), input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(16, (5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(120, activation='relu'))
model.add(Dense(84, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
history = model.fit(X_train, y_train,
validation_split=0.2,
epochs=20, batch_size=32, verbose=1)
plt.figure(12)
plt.subplot(121)
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend(['Train', 'val'], loc='upper left')
plt.subplot(122)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.legend(['Train', 'val'], loc='upper left')
plt.show()
score = model.evaluate(X_test, y_test, verbose=1)
print(model.metrics_names)
print('loss:', score[0])
print('accu:', score[1])
prediction = model.predict_classes(X_test)
print(prediction[:10])
结果如下:
['loss', 'acc'] loss: 1.262941250228882 accu: 0.5561 [3 1 8 0 4 6 1 2 4 1]
可视化预测结果如下:

我们可以看到准确率才达到55%左右,当我们增加epochs的时候,这里准确率就上去了,这里不多做尝试。
4,Model式模型
这部分会实现一个多输入多输出的模型
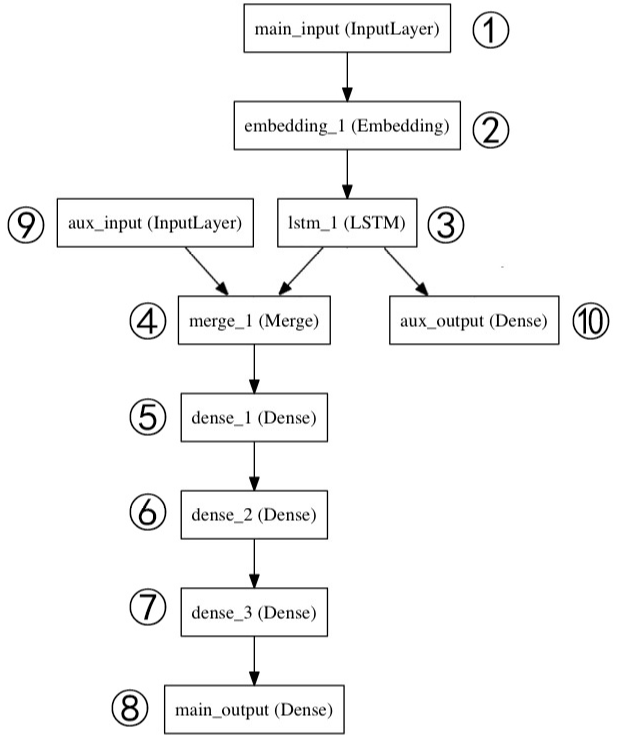
4.1 构建网络
这里我们选择函数式模型(model),所以不需要提前实例化,先将网络结构实现。
定义1,主要输入层,接受新闻标题本身,即一个整数序列(每个整数编码一个词)。这些整数在1到10000之间(10000个词的词汇表),且序列长度为100个词,命名 main_input
main_input = Input(shape=(100,), dtype='int32', name='main_input')
定义2,将输入序列编码为一个稠密向量的序列,输出每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
定义3,LSTM层把向量序列转换成单个向量,它包含整个序列的上下文信息,输出维度为32
lstm_out = LSTM(32)(x)
定义10,其作为辅助损失,使得即使在模型主损失很高的情况下,LSTM层和 Embedding层都能被平稳地训练。输出维度1,激活函数Sigmoid,命名为aux_output
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
定义9,输入辅助数据,五维向量,命名为 aux_input
auxiliary_input = Input(shape=(5,), name='aux_input')
定义4,将辅助输入数据与LSTM层的输出连接起来,输入到模型中
x = keras.layers.concatenate([lstm_out, auxiliary_input])
定义5,6,7, 堆叠多个全连接网络层,输出均为 64维
x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x)
定义8,输出层,激活函数Sigmoid,命名 main_output
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
4.2 定义模型
定义一个具有两个输入和输出的模型
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
4.3 编译模型
编译模型,给辅助损失分配 0.2 的权重
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
4.4 训练模型
读取数据
把数据送入模型训练
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': headline_labels, 'aux_output': additional_labels},
epochs=50, batch_size=32,verbose=0)
4.5 预测
model.predict({'main_input': headline_data, 'aux_input': additional_data})
4.6 完整代码
代码如下(这个差点东西):
from keras.models import Sequential, Input, Model
from keras.layers import Conv2D, Activation, MaxPooling2D, Flatten, Dense
from keras.datasets import imdb
from keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
from keras.optimizers import SGD
import keras
from keras.layers import Embedding, LSTM
max_features = 10000
# 该数据库含有IMDB的25000条影评,被标记为正面/负面两种评价,影评已被预处理为词下标构成的序列
# y_train和y_test 序列的标签,是一个二值 list
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=max_features)
print(X_train.shape, y_train.shape) # (25000,) (25000,)
main_input = Input(shape=(100,), dtype='int32', name='main_input')
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
lstm_out = LSTM(32)(x)
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
model = Model(inputs=[main_input, auxiliary_input],
outputs=[main_output, auxiliary_output])
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy',
'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1, 'aux_output': 0.2})
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': headline_labels, 'aux_input': additional_label},
epochs=50, batch_size=32, verbose=0)
model.predict({'main_input': headline_data, 'aux_input': additional_data})
5,LSTM官网例子
代码:
from __future__ import print_function
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
max_features = 20000
maxlen = 80
batch_size = 32
print('loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences') # 25000 train sequences
print(len(x_test), 'test sequences') # 25000 test sequences
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape) # x_train shape: (25000, 80)
print('x_test shape:', x_test.shape) # x_test shape: (25000, 80)
print('Build model...')
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print("Train...")
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=15,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test,
batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)
结果:
672/25000 [..............................] - ETA: 2:12 - loss: 0.0880 - acc: 0.9702 704/25000 [..............................] - ETA: 2:12 - loss: 0.0866 - acc: 0.9702 736/25000 [..............................] - ETA: 2:11 - loss: 0.0846 - acc: 0.9715 768/25000 [..............................] - ETA: 2:11 - loss: 0.0825 - acc: 0.9727 800/25000 [..............................] - ETA: 2:12 - loss: 0.0823 - acc: 0.9725 832/25000 [..............................] - ETA: 2:12 - loss: 0.0796 - acc: 0.9736 864/25000 [>.............................] - ETA: 2:11 - loss: 0.0798 - acc: 0.9722
参考文献:https://blog.csdn.net/sinat_26917383/article/details/75633754

 浙公网安备 33010602011771号
浙公网安备 33010602011771号