
深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition
论文作者: Gregory Koch Richard Zemel Ruslan Salakhutdinov
论文地址:https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
几乎所有分类模型使用的都是标准分类。输入被馈送到一系列层,最后输出类概率。如果想通过猫来预测出狗,你可以在你所期望的预测时间内训练相似的(但不相同的)狗/猫图片模型。当然,这要求你有一个数据集,与你使用模型进行预测时所期望的数据集类似。而孪生网络是一种特殊类型的神经网络架构。与一个学习对其输入进行分类的模型不同,该神经网络是学习在两个输入中进行区分。它学习了两个输入之间的相似之处。

摘要
为机器学习应用程序学习一个好的特征的过程可能在计算上非常昂贵,并且在数据很少的情况下可能会变得困难。一个典型的例子就是一次学习设置,在这种情况下,我们必须仅给出每个新类的一个示例,就可以正确的做出预测。在本文中,我们探索了一种学习孪生神经网络的方法,该方法采用独特的结构自然对输入之间的相似性进行排名。一旦网络被调整好,我们就可以利用强大的判别功能,将网络的预测能力不仅用于新数据,而且适用于未知分布中的全新类别。使用卷积架构,我们可以在单次分类任务上获得近乎最先进的性能,从而超过其他深度学习模型的强大结果。

人类展现出强大的获取和识别新模式的能力。特别是,我们观察到,当受到刺激时,人们似乎能够快速理解新概念,然后在将来的感知中认识到这些概念的变化(Lake等,2011)。机器学习已成功用于各种应用程序中的最先进性能,例如Web搜索,垃圾邮件检测,字幕生成以及语音和图像识别。但是,当被迫对几乎没有监督信息的数据进行预测时,这些算法通常会崩溃。我们希望归纳这些不熟悉的类别,而无需进行大量的重新培训,由于数据有限或在在线预测设置(例如网络检索)中,重新培训可能即昂贵又不可能。

图1:使用Omniglot 数据集进行20次单发分类任务的示例。单独的测试图像显示在29张图像的网格上方,代表我们可以为测试图像选择的可能看不见的类型。这20张图片是我们每个类别中唯一已知的示例。


一个特别有趣的任务是在这样的限制下进行分类:我们可能只观察每个可能类的单一示例。这杯称为单次学习,这是我们在该工作中提出的模型的主要重点(Fei-Feiet等,2006;Lake等,2011)。这应该与零散学习区分开来,在零散学习中,模型无法查看目标类别中的任何示例(Palatucci等,2009)。
通过开发特定领域的功能或推理程序可以一直解决一次性学习的问题,这些功能或推理程序具有针对目标任务的高度区分性。结果,结合了这些方法的系统在类似情况下往往会表现出色,但无法提供可应用于其他类似问题的可靠解决方案。在本文中,我们提出了一种新颖的方法,该方法可以限制输入结构的假设,同时自动获取使模型能够成功地从几个示例中成功推广的特征。我们建立在深度学习框架的基础上,该框架使用多层非线性来捕获不变性以在输入空间中进行变换,通常是通过利用具有许多参数的模型,然后使用大量数据来防止过度拟合(Bengio,2009;Hinton等,2006)。这些功能非常强大,因为我们可以在不强加先验的情况下学习他们,尽管学习算法本身的成本可能很高。
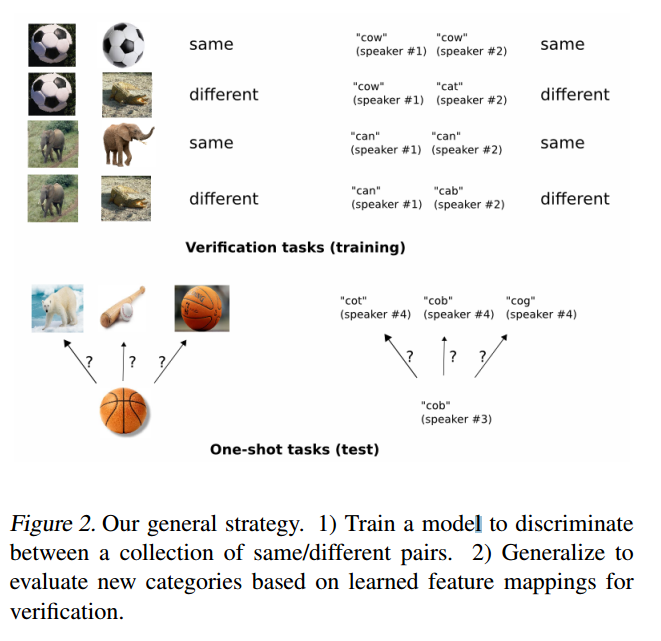
图2,我们的总体策略。1)训练模型以区分相同/不同对的集合。2)根据学习到的特征映射进行概括以评估新类别,以进行验证。


通常,我们通过具有监督性的基于度量的方法使用孪生神经网络来学习图像表示,然后将该网络的功能重新用于一次学习,而无需进行任何重新训练。
在我们的实验中,我们将注意力集中在字符识别上,尽管基本方法几乎可以用于任何形式(图二)。对于这个领域,我们使用大量的孪生卷积神经网络,其中a)能够学习通用图像特征,这些特征对于做出关于未知类分布的预测非常有用,即使这些新分布中的例子很少。 b)使用标准优化技术对从元数据采用的对进行轻松训练;c)通过利用深度学习技术,提供了一种不依赖于特定领域知识的竞争性方法。
要开发用于单次图像分类的模型,我们的目标是首先学习一个可以区分图像对的类身份的神经网络,这是图像识别的标准验证任务。我们假设,在验证方面表现出色的网络应该推广到一键式分布。验证模型学习根据输入对属于相同类别或不同类别的可能性来识别输入对。然后可以使用该模型以成对的方式针对测试图像评估新图像,每个新颖类恰好一个。然后根据验证网络将得分最高的配对授予一次任务的最高概率。如果验证模型学习到的特征足以确认或拒绝一组字母中的字符的身份,那么对于其他字母来说,他们应该就足够了,只要该模型已暴露于各种字母中以鼓励之间的差异学习的功能。



总体而言,对一次性学习算法的研究还很不成熟,并且机器学习社区对此的关注还很有限。但是,本文之前还有一些关键的工作领域。
一键式学习的开创性工作可以追溯到2000年初的李飞飞等人。作者开发了一个变种的贝叶斯框架,用于 oneshot 图像分类,前提是在给定类别中只有很少的示例可用时,可以利用先前学习的类别来帮助预测未来的类别(Fe-Fei等,2003;Fei-Fei 等)等(2006)。最近,Lake等人。从认知科学的角度解决了一次性学习的问题,通过一种被称为“层次贝叶斯程序学习”(HBPL)的方法解决了用于字符识别的一次性学习(2013)。在一系列的几篇论文中,作者模拟了生成字符的过程,以将图像分解成小块(Lake等,2011;2012)。HBPL的目标是确定所观察像素的结构说明。但是,由于联合参数空间很大,因此在HBPL下进行推理很困难,从而导致难以解决的集成问题。
一些研究人员考虑了其他方法或转移学习方法。湖等。最近有一些工作,该工作针对语言原语来识别未知说话者的新单词(2014年)。Maas和Kemp在使用贝叶斯网络预测 Ellis Island 乘客数据的属性(2009年)的著作中只有少数发表,Wu和Dennis在机器人制动的路径规划算法的背景下解决了一次性学习(2012)。Lim着重研究如何通过调整衡量损失函数中的每个训练样本应加权每个类别多少的度量,来“借用” 训练集中其他类别的示例。对于某些类别几乎没有示例的数据集,此想法可能很有用,它提供了一种灵活且连续的方式,将类别间信息纳入模型。

图三,用于逻辑分类P的二进制分类的简单两层孪生网络。网络的结构在顶部和底部进行复制,以形成双胞胎网络,每一层都有共享的权重矩阵。

3,用于图像验证的深度孪生网络
孪生网络是由两个完全相同的神经网络组成,每个都采用两个输入图像中的一个。然后将两个网络的最后一层馈送到对比损失函数,用来计算两个图像之间的相似度。它具有两个兄弟网络,他们是具有完全相同权重的相同神经网络。图像对中的每个图像将被馈送到这些网络中的一个。使用对比损失函数优化网络,我们将获得确切的函数。
孪生网络由Bromley 和 LeCun 于 1990年代首次引入,以解决作为图像匹配问题的签名验证(Bromley等, 1993)。孪生神经网络由双胞胎网络组成,该双胞胎网络接受不同的输入,但是在顶部由能量函数连接。此函数在每侧的最高层特征表示之间计算一些度量(图3)。双网之间的参数是绑定的,加权绑定保证了两个及其相似的图像可能无法通过各自的网络映射到特征空间中非常不同的位置,因为每个网络都计算相同的功能。而且,网络是对称的,因此每当我们向双胞胎网络呈现两个不同的图像时,最上层的连接层将计算相同的度量,就像我们要呈现相同的两个图像但像相对的双胞胎一样。


在LeCun等人中,作者使用了包含两个项的对比能力函数,以减少相似对的能力并不相似对的能量(2005年)。但是,在本文中,我们使用双特征向量h1和h2之间的加权L1距离结合S型激活,将其映射到区间 [0, 1]。因此,交叉熵目标是训练网络的自然选择。请注意,在LeCun等人中,他们直接学习了相似性指标,该相似性指标由能量损失隐式定义,而我们按照 Facebook DeepFace论文中的方法(Taigman等人,2014)固定了上述指标。我们性能最佳的模型在完全连接的层和顶级能量函数之前使用多个卷积层。在许多大型计算机视觉应用中,特别是在图像识别任务中,卷积神经网络已经取得了优异的成绩(Bengio,2009; Krizhevsky等,2012; Simonyan&Zisserman,2014; Srivastava,2013)。

有几个因素使卷积网络特别有吸引力。局部连通性可以大大减少模型中的参数数量,从而固有的提供某种形式的内置正则化,尽管卷积层在计算上比标准非线性要贵。同样,在这些网络中使用的卷积运算具有直接过滤的解释,其中每个特征图都与输入特征进行卷积,以将模式识别为像素分组。因此,每个卷积层的输出对应于原始输入控件中的重要控件特征,并为简单变换提供了一定的鲁棒性。最后,现在可以使用非常快的CUDA库来构建大型卷积网络,而无需花费大量的训练时间(Mnih,2009年; Krizhevsky等人,2012年; Simonyan&Zisserman,2014年)。
现在,我们详细介绍了孪生网络的结构以及实验中使用的学习算法的细节。


我们的标准模型时一个孪生卷积神经网络,每个L层都具有 N1 个单位,其中h1,l 代表第一个双胞胎在 l 层中的隐藏矢量, h2,l 代表第二队双胞胎的相同。我们在前 L-2 层中仅使用整流线性(ReLU)单元,而在其余层中使用 S型单元。
该模型由一系列卷积层组成,每个卷积层使用单个通道,并具有大小可变且固定步长为1的滤波器。将卷积滤波器的数量指定为16的倍数以优化性能。网络将ReLU激活功能应用于输出特征图,还可以选择在最大池化之后使用过滤器大小和跨度为2。因此,没层中的第K个过滤器采用如下形式:

其中Wl-1 , l是第 l 层特征图的三维张量,我们采用 * 是有效的卷积运算,对应于仅返回哪些在每个卷积滤波器和输入特征图之间完全重叠的结果的输出单元。
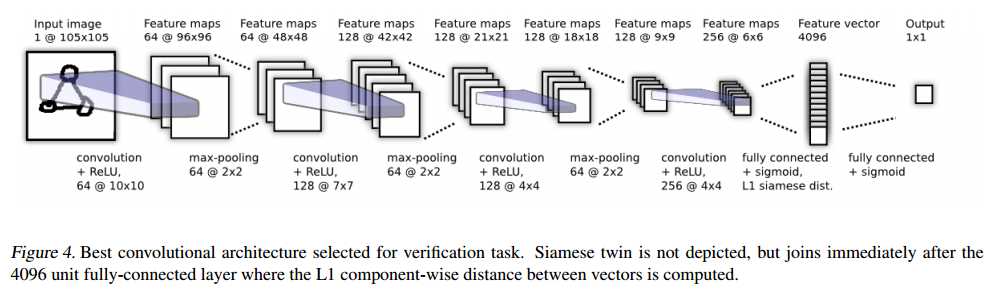
图四,选择用于验证任务的最佳的卷积架构。没有显示连体双胞胎,但在4096个单位的完全连接层之后立即加入连体,其中计算了向量之间的L1分量方向距离。

最终卷积层中的单位被展平为单个向量。该卷积层之后是一个完全连接的层,然后再一层计算每个孪生双胞胎之间的感应距离度量,该距离度量被提供给单个S型输出单元。更准确的说,预测矢量为 P=![]() ),其中 其中σ是S型激活函数。 最后一层在第 (L-1)隐藏层的学习特征空间上引入度量,并对两个特征之间的相似性进行评分。αj是模型在训练过程中学习的其他参数,加权了分量方向距离的重要性。这为网络定义了最后的 Lth全连接层,该层将两个孪生双胞胎相连。
),其中 其中σ是S型激活函数。 最后一层在第 (L-1)隐藏层的学习特征空间上引入度量,并对两个特征之间的相似性进行评分。αj是模型在训练过程中学习的其他参数,加权了分量方向距离的重要性。这为网络定义了最后的 Lth全连接层,该层将两个孪生双胞胎相连。
我们在上面描述了一个示例(图4),该示例显示了我们考虑的模型的最大版本。该网络还为验证任务中的任何网络提供了最佳结果。

3.2 Learning
损失函数:令M代表小批量的大小,其中 i 索引第 i 个小批量。现在让 y(x1, x2) 是一个长度为M的向量,其中包括小批量的标签,其中,当 x1 和 x2 来自同一字符类时,我们假设 y(x1, x2) =1 ,否则,我们在以下形式中的二进制分类器上强加一个正规化的交叉熵目标:
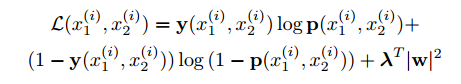


优化器:这个目标与标准的反向传播算法结合在一起,在该算法中,由于权重的关系,整个双子网络的梯度是相加的。我们将学习速率 ηj,动量 µj 和 L2 正则化权重 λj 分层定义,从而将小批量大小固定为128,因此在时间点T的更新规则如下:
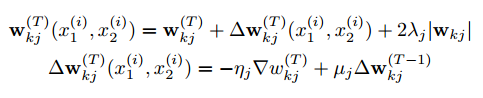
其中 ∇wkj 是相对于某层第 j 个神经元和连续层第 k 个神经元之间权重的偏导数。

权重初始化。我们从零均值和 10-2的标准差的正态分布初始化卷积层中的所有网络权重。偏差也从正态分布初始化卷积层中的所有网络权重。偏差也从正态分布初始化,但平均值为 0.5,标准差为10-2。在完全连接的层中,以与卷积层相同的方式来初始化偏差,但是权重时从更宽的正态分布中得出的,均值为零,标准差为 2*10-1。

学习时间表。尽管我们为每一层设置了不同的不学了,但是每个epoch的学习率在网络上均匀下降了 1%,因此 η(T)j =0.99η(T -1)j。 我们发现,通过对学习速率进行退火,网络能够更轻松地收敛到局部最小值,而不会陷入错误表明。我们将动量固定为每层从 0.5 开始,每个时代线性增加,直达达到值 j,即第 j 层的各个动量项。
我们对每个网络进行了最多200个epochs的训练。但是监视了从验证集中的字母和抽屉随机生成的320个 oneshot 学习任务集中的一次验证错误。当验证错误在20个epochs内未减少时,我们根据一次验证错误停止并在最佳时期使用模型的参数。如果在整个学习计划中验证错误继续减少,我们将保存此过程生成的模型的最终状态。


超参数优化。我们仨还有贝叶斯优化框架Whetlab的Beta版来执行超参数选择。对于学习计划和正则化超参数,我们设置分层学习率ηj∈[10-4,10-1],分层动量µj∈[0,1]和分层L2正则化惩罚λj∈[0,0.1]。对于网络超参数,我们让卷积滤波器的大小在3x3到20x20之间变化,而每层中的卷积滤波器的数量在16到256之间(使用16的倍数)变化。全连接层的范围从128打破4096单位不等,也是16的倍数。我们将优化器设置为最大化一次验证设置的准确性。分配给单个Whetlab迭代的分数是在任何时期发现的该指标的最高值。

仿射失真。此外,我们在训练集上增加一些仿射失真(图五)。对于每个图像对x1,x2,我们生成了一对仿射变换T1,T2,以产生x1 = T1(x1),x2 = T2(x2),其中T1,T2由多维均匀分布随机确定。 因此,对于任意变换T,我们有T =(θ,ρx,ρy,sx,sy,tx,tx),其中θ∈[−10.0,10.0],ρx,ρy∈[−0.3,0.3],sx, sy∈[0.8,1.2]和tx,ty∈[−2,2]。 转换的每个这些分量都以0.5的概率包括在内。

图5,Omniglot数据集中为单个字符串生成的随机放射失真的样子


4,实验
我们在首先描述的Omniglot数据集的子集上训练了模型。然后我们提供有关验证和单发性能的详细信息。
4.1 Omniglot 数据集
Omniglot数据集是由Brenden Lake及其同事在麻省理工学院通过亚马逊的Mechanical Turk收集的,以产生一个标准的基准,可以从手写字符识别领域的一些示例中学习(Lake等,2011)。1Omniglot包含了来自50个字母的示例从诸如拉丁语和韩语等公认的国际语言到鲜为人知的当地方言。它还包括一些虚构的字符集,例如Aurek-Besh和Klingon(图6)。
每个字母中的字母数量从大约15个字符到最多40个字符不等。这些字母中的所有字符都是由20个抽屉中的每个抽屉一次生成的,Lake将数据分为40个字母背景集和10个字母评估集。我们保留这两个术语是为了与可以从背景集生成的正常训练,验证和测试集区分开,以调整模型以进行验证。背景集用于通过学习超参数和特征映射来开发模型。相反,评估集仅用于测量单次分类性能。

图6. Omniglot数据集包含来自世界各地字母的各种不同图像。


4.2 验证
为了训练我们的验证网络,我们通过对随机相同和不同的样本对进行采样,将三个不同的数据集大小与30000,90000和120000 个训练示例放在一起。我们预留了总培训数据的 60%:50个字母中的30个字母和20个抽屉的12个抽屉。
我们固定了每个字母的训练样本数量,以使每个字母在优化过程中都能得到相同的表示,尽管这不能保证每个字母中的各个字符类。通过添加仿射失真,我们还生成了与这些大小中的每个大小的增强版本相对应的数据集的附加副本。我们为每个训练示例添加了八个变换,因此相应的数据集包含 270000,810000和1350000有效示例。

为了监控培训期间的表现,我们使用了两种策略。首先,我们创建了一个验证集,用于从10个字母和4个其他抽屉中提取的10,000个示例对进行验证。我们保留了最后10个字母和4个抽屉用于测试,在这里我们将它们限制为与Lake等人使用的相同。 (Lake et al。,2013)。我们的其他策略是利用相同的字母和抽屉为验证集生成一组320次单次识别试验,以模拟评估集中的目标任务。实际上,确定停止时间的第二种方法至少与验证任务的验证错误一样有效,因此我们将其用作终止标准。
在下表(表1)中,我们列出了六种可能的训练集的最终验证结果,其中列出的测试准确性在最佳验证检查点和阈值处报告。我们报告了六个不同训练运行的结果,这些结果改变了训练集的大小和切换的失真。
在图7中,我们从验证任务的前两个性能最高的网络中提取了前32个滤波器,这些滤波器在具有仿射失真和图3所示架构的90k和150k数据集上进行了训练。过滤器之间的适应性,很容易看出某些过滤器相对于原始输入空间承担了不同的角色。
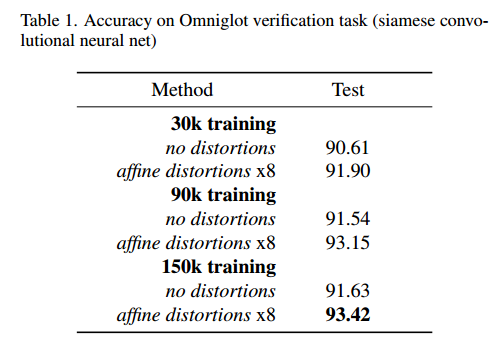
表一,Omniglot验证任务的准确性(孪生卷积神经网络)

图7,孪生网络学习到的第一层卷积滤波器的示例。通过过滤器具有不同的作用:一些过滤器寻找非常小的逐点特征,而另一些过滤器则发挥更大的边缘检测器的作用。


4.3 单样本学习
一旦我们优化了孪生网络以完成验证任务,就可以在一次学习中展示我们所学功能的区分潜力。假设给定一个测试图像 X,我们希望将其分类为C类之一。我们还得到了其他一些图像{xc} C c = 1,这是代表这些C类中每个类别的列向量的集合。现在,我们可以使用 x, xc作为输入查询网络,范围为C=1 ....... c2 然后预测与最大相似度相对应的类别。


为了凭经验估计一次性学习成绩,Lake开发了20种字母内部分类任务,其中首先从为评估集保留的字母中选择一个字母,然后随机抽取20个字符。还从评估抽屉池中选择了二十个抽屉中的两个。然后,这两个抽屉将产生二十个字符的样本。第一个抽屉产生的每个字符都表示为测试图像,并分别与第二个抽屉中的所有二十个字符进行比较,目的是从第二个抽屉的所有字符中预测与测试图像相对应的类别。图7显示了一次学习实验的一个单独示例。此过程对所有字母重复两次,因此,十个评估字母表中的每一个都有40个一次学习试验。这总共构成了400次单次学习试验,由此计算出分类准确性。
表2给出了一次性结果。我们借鉴(Lake等人,2013)的基线结果与我们的方法进行比较。我们还包括来自具有两个完全连接层的非卷积孪生网络的结果。
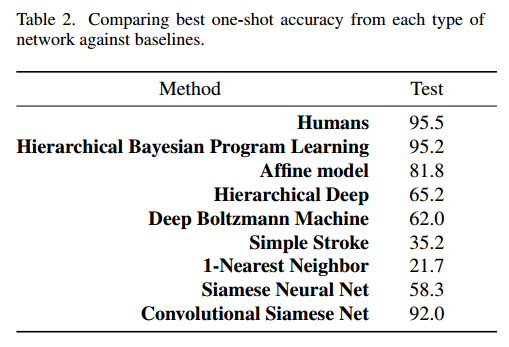
表2. 将每种类型的网络与基准的最佳单次准确度进行比较。


我们的卷积方法达到了92%,比HBPL本身以外的任何模型都强。 这仅略低于人为错误率。 虽然HBPL总体上显示出更好的结果,但我们表现最好的卷积网络并未包含有关字符或笔触的任何其他先验知识,例如有关绘图过程的生成信息。 这是我们模型的主要优势。

表3,MNIST 10 对1 单分类任务的结果

4.4 MNIST单分类训练
Omniglot数据集包含少量样本,用于每种可能的字母类别。因此,原始作者将其称为“ MNIST转置”,其类数远远超过训练实例的数量(Lake等,2013)。我们认为监视在Omniglot上训练的模型可以很好地推广到MNIST会很有意思,在MNIST中,我们将MNIST中的10位数字视为字母,然后评估10向单发分类任务。我们遵循与Omniglot类似的程序,在MNIST测试集上进行了400次单次试验,但不包括对训练集的任何微调。所有28x28图像均被上采样至35x35,然后提供给我们的模型的简化版本,该模型在Omniglot的35x35图像上进行了训练,这些图像被下采样了3倍。我们还评估了此任务的最近邻基线。
表3显示了该实验的结果。最近的邻居基准提供与Omniglot相似的性能,而卷积网络的性能下降幅度更大。但是,我们仍然可以从Ominglot上学到的功能中获得合理的概括,而无需对MNIST进行任何培训。


5,总结
我们提出了一种通过首先学习深度卷积孪生神经网络进行验证来执行单发分类的策略。我们概述了将网络性能与为Omniglot数据集开发的现有最新分类器进行比较的新结果。我们的网络大大超越了所有可用的基准,并且接近先前作者所获得的最佳数字。我们认为,这些网络在此任务上的强大性能不仅表明我们的度量学习方法可以实现人类水平的准确性,而且该方法应扩展到其他领域的单次学习任务,尤其是图像分类。
在本文中,我们仅考虑通过使用全局仿射变换处理图像对及其失真来训练验证任务。我们一直在尝试一种扩展算法,该算法利用有关单个笔划轨迹的数据来产生最终的计算失真(图8)。希望通过在笔划上施加局部仿射变换并将其覆盖到合成图像中,我们希望我们可以学习更好地适应新示例中常见变化的特征。

图8.针对Omniglot中不同字符的两组笔画变形。 列描绘了从不同抽屉中抽取的字符。 第1行:原始图片。 第2行:全局仿射变换。 第3行:笔画仿射变换。 第4行:在笔划变换之上分层的全局仿射变换。 请注意,笔画变形如何会增加噪音并影响各个笔画之间的空间关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号