
卷积神经网络学习笔记——ResNet(Tensorflow实现)
完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
论文地址:Deep Residual Learning for Image Recognition
自2012年AlexNet提出以来,图像分类、目标检测等一系列领域都被卷积神经网络CNN统治着。接下来的时间里,人们不断设计新的深度学习网络模型来获得更好的训练效果。一般而言,许多网络结构的改进(例如从VGG到ResNet可以给很多不同的计算机视觉领域带来进一步性能的提高,所以我们很容易就想到:深的网络一般会比浅的网络效果好,如果要进一步地提升模型的准确率,最直接的方法就是把网络设计的越来越深,这样的准确率也就会越来越准确。
可现实是这样吗?
先看几个经典的图像识别深度学习模型:
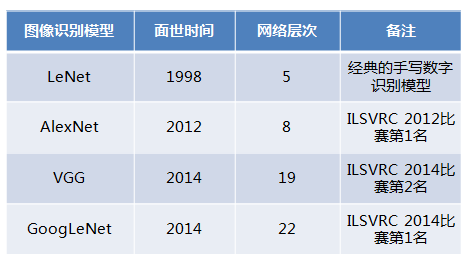
这几个模型都是在世界顶级比赛中获奖的著名模型,然而,一看这些模型的网络层次数量,似乎让人很失望,少则5层,多的也就22层而已,这些世界级模型的网络层次也没有那么深啊。而下面学习的网络则成功的拓宽了深度。
ResNet(Residual Neural Network)由微软研究员的 Kaiming He 等四位华人提出,通过使用 Residual Uint 成功训练152层深的神经网络,在 ILSVRC 2015比赛中获得了冠军,取得了 3.57%的top-5 的错误率,同时参数量却比 VGGNet低,效果非常突出,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet,Alpha zero 也使用了ResNet,所以可见ResNet确实很好用。ResNet的结构可以极快的加速超深神经网络的训练,模型的准确率也有非常大的提升。之前我们学习了Inception V3,而Inception V4则是将 Inception Module和ResNet相结合。可以看到ResNet是一个推广性非常好的网络结构,甚至可以直接应用到 Inception Net。
1,模型加深存在的问题
ResNet 和 HighWay Network非常类似,也就是允许原始输入信息直接传输到后面的层中。ResNet最初的灵感来自这个问题:在不断加神经网络的深度时,会出现一个 Degradation 的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是一个过拟合的问题,因为不光在测试机上误差增大,训练集本身误差也会增大。假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个 y=x 的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是 ResNet的灵感来源。假定某段神经网络的输入是 x,期望输出是 H(x),如果我们直接把输入 x 传到输出作为初始结果,那么此时我们需要学习的目标就是 F(x) = H(x) - x。如下图所示,这就是一个ResNet的残差学习单元(Residual Unit),ResNet相当于将学习目标改变了,不再是学习一个完整的输出 H(x),只是输出和输入的差别 H(x) - x,即残差。
所以ResNet最根本的动机就是解决所谓的“退化”问题,即解决当模型的层次加深时,错误率却高了的问题。
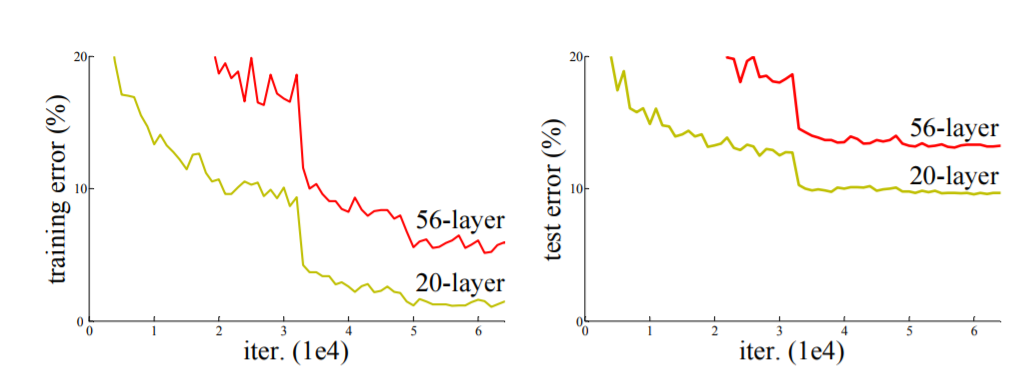
如下图所示,CIFIR10 数据的一个实验,每个图有两个网络层,分别是20层和56层,并且左侧为训练误差,右侧是测试误差,不光在测试集上误差比较大,训练集本身的误差也非常大。(为什么要用20层呢?有人做实验发现简单的叠加,20层就是叠加的极限了。)
随着网络越深,精准度的变化如下图(这是一般的深层卷积神经网络):
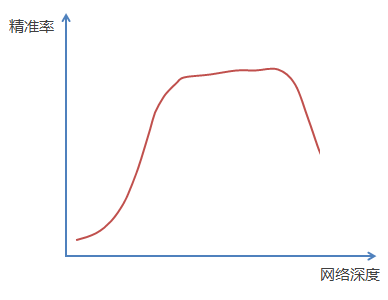
通过实验可以发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络变得更加难以训练了。
2,为什么深度模型难以训练
为什么随着网络层级越深,模型效果却变差了呢?
2.1 链式法则与梯度弥散
下图是一个简单的神经网络图,由输入层,隐含层,输出层构成:
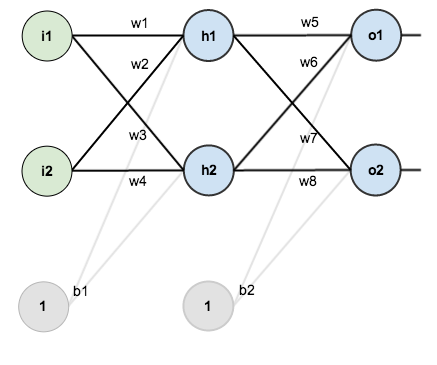
回想一下神经网络反向传播的原理,先通过正向传播计算出结果 output,然后通过与样本比较得出误差值 Etotal:
![]()
根据误差结果,利用著名的“链式法则”求偏导,使结果误差反向传播从而得出权重w调整的梯度。下图是输出结果到隐含层的反向传播过程(隐含层到输入层的反向传播过程也是类似):

通过不断迭代,对参数矩阵进行不断调整后,使得输出结果的误差值更小,使输出结果与事实更加接近。
从上面的过程来看,神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的 0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
2.2 1.01 365 = 37.783 与 0.99 365 = 0.0255
3,Highway Network简介
在ResNet之前,瑞士教授 Schmidhuber 提出了 Highway Network,原理与ResNet很相似。这位Schmidhuber 教授同时也是 LSTM网络的发明者,而且是早在1997年发明的,可谓是神经网络领域元老级的学者。通常认为神经网络的深度对其性能非常重要,但是网络越深其训练难度越大,Highway Network的目标就是解决极深的神经网络难以训练的问题。Highway Network相当于修改了每一层的激活函数,此前的激活函数只是对输入做一个非线性变换 y = H(x, WH) ,Highway Network 则允许保留一定比例的原始输入 x,即 y = H(x, WH) .T(x, WT) + x . C(x, WC) ,其中 T是变换系数,C为保留系数。论文中令 C= 1 - T。这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因而得名 Highway Network。Highway Network主要通过 gating units 学习如何控制网络中的信息流,即学习原理信息应保留的比例。这个可学习的 gating机制,正是借鉴自Schmidhuber 教授早年的 LSTM 训练神经网络中的gating。几百乃至上千层深的 Highway Network可以直接使用梯度下降算法训练,并可以配合多种非线性激活函数,学习极深的神经网络现在变得可行了。事实上,Highway Network 的设计在理论上允许其训练任意深的网络,其优化方法基本上与网络的深度独立,而传统的神经网络结构则对深度非常敏感,训练复杂度随着深度增加而急剧增加。
4,ResNet的特点
针对“退化”问题,作者提出了一个Residual的结构。
假设:假如有一个比较浅网络(Shallow Net)的准确率达到了饱和,那么后面再加上几个 y = x 的恒等映射(Identity Mappings),按理说,即使准确率不能再提速了,起码误差不会增加(也即更深的网络不应该带来训练集上误差的上升),但是实验证明准确率下降了,这说明网络越深,训练难度越大。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
对于shortcut的方式,作者提出了三个选项:
- A:使用恒等映射,如果 residual block 的输入输出维度不一致,对增加的维度用 0 来填充
- B:在 block 输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致
- C:对于所有的 block 均使用线性投影
对于这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而是使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
进一步实验,作者又提出了deeper的residual block,ResNet引入了残差网络结构(residual Network),通过这种残差网络结构,可以把网络层弄得很深,作者提出了50, 101, 152层的ResNet(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图示带有跳跃结构的:
(这里插句嘴:其实那个时候ResNet的错误率已经把其他网络甩了几条街,但是似乎作者还不满足,又搭建了更加变态的 1202层网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个 1202层的模型进行进一步的优化。。。)

F(x) 是一个残差映射 w, r, t 恒等,如果说恒等是理想,很容易将权重值设定为0,如果理想化映射更接近于恒等映射,便更容易发现微小波动。
我的白话理解:这里我们做了两个步骤:1是给网络加两层卷积,2是恒等映射;然后做完后,我们对比方法1和方法2那个效果更好,所以这么做的目的就是保证每个小模块卷积的效果至少不比原来差,虽然好不好不确定,这样起码不会造成精度下降。上面的恒等映射,是把一个输入 x 和其堆叠了2次后的输出 F(x) 的进行元素级和作为总的输出。因此它没有增加网络的运算复杂度,而且这个操作很容易被现在的一些常用库执行(比如:Caffe,TensorFlow)。
残差网络借鉴了高速网络(Highway Network)的跨层链接思想,但对其进行修改(残差项原本是带权值的,但是ResNet用恒等映射代替之)
- 假定某段神经网络的输入是x,期望输出是H(x),即H(x)是期望的复杂潜在映射,如果是要学习这样的模型,则训练难度会比较大;
- 回想前面的假设,如果已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。
- 在上图的残差网络结构图中,通过“shortcut connections(捷径连接)”的方式,直接把输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,那么H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) = H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。
- 这种残差跳跃式的结构,打破了传统的神经网络n-1层的输出只能给n层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
- 至此,神经网络的层数可以超越之前的约束,达到几十层、上百层甚至千层,为高级语义特征提取和分类提供了可行性。
下面感受一下34层的深度残差网络的结构图:

从图中可以看出,怎么有一些“shortcut connections(捷径连接)”是实线,有一些是虚线,有什么区别呢?
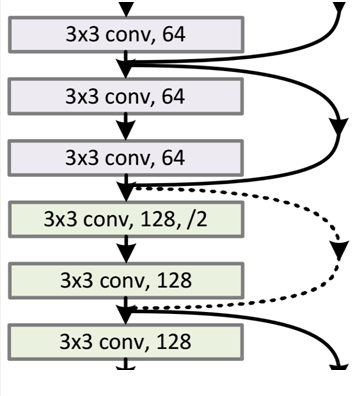
因为经过“shortcut-connections(捷径连接)”后,H(x) = F(x) + x,如果 F(x) 和 x 通道相同,则可直接相加,那么通道不同怎么相加呢。上图的实线,虚线就是为了区分这两种情况的:
- 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是 3*3*64 的特征图,由于通道相同,所以采用计算方式为H(x) = F(x) + x;
- 虚线的 Connection 部分,表示通道不同,如上图的第一个绿色矩形和第三个粉色矩形,分别为 3*3*64 和 3*3*128 的特征图,通道不同,采用的计算方式为 H(x) = F(x) + Wx,其中 W 为卷积操作,用来调整x维度的。虚线这里做了1*1的卷积
4.1 1*1 卷积的目的
先不针对此问题,我们来说说1*1 卷积的主要作用:
- 1,降维(dimension reductionality)/升维。比如,一张 500*500 且厚度 depth 为 100 的图片在 20个 filter 上做 1*1 的卷积,那么结果的大小为 500 * 500 *20。
- 2,加入非线性。卷积层之后经过激励层,1*1 的卷积在前一层的学习表达上添加了非线性激励(non-linear activation),提升网络的表达能力。
- 3,数据融合。在ResNet中,数据要进行相加,但有时并不能保证通道大小匹配,这个时候就需要使用 1*1 卷积操作,是数据在各个维度上进行匹配,从而对两个数据进行计算。
- 4,减少计算量。在GoogLeNet中,Inception中的卷积多数先进行 1*1 卷积操作,再进行其他卷积操作,这样其实可以减少计算量。某些程度避免了过拟合。
下面来说ResNet中的残差模块。
下图是两层及三层的ResNet残差学习模块:
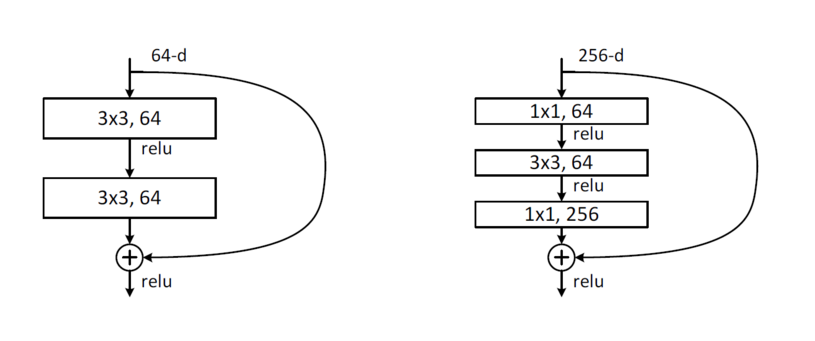
两种结构分别针对 ResNet34(左图)和 ResNet50/101/152(右图),其目的主要就是为了降低参数的数目,左图是两个 3*3*64 的卷积,参数数目:3*3*64*64*2 = 73728,右图是第一个1*1的卷积把256维通道降到64维,然后在最后通过1*1卷积恢复,整体上用的参数数目为:1*1*256*64 + 3*3*64*64 + 1*1*64*256 = 69632,右图的参数数量和左图无法对比(因为这里是图错了),应该是说,当左图为 两个3*3*256 的卷积,则参数数目为:3*3*256*256*2=1179648, 此时左右对比,则1179648/69632=16.94,右图参数数量降低了 16.94,因此,右图的主要目的就是为了减少参数量,从而减少计算量。
对于常规的ResNet,可以用于34层或者更少的网络中(左图);对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
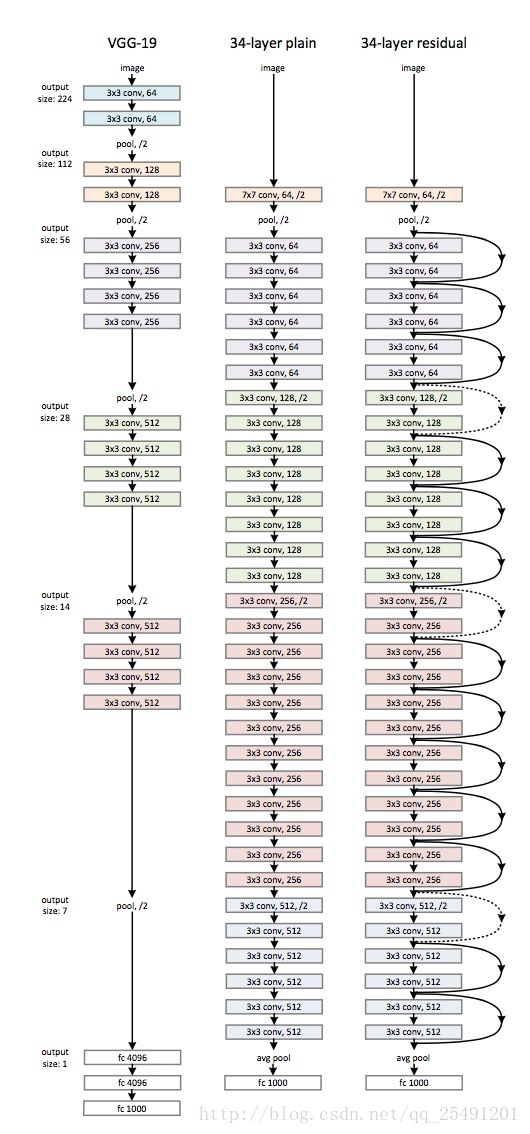
5,VGGNet-19 VS ResNet-34(ResNet的创新点)
在提出残差学习的思想,传统的卷积网络或者全连接网络在信息传递的时候或多或少会存在信息丢失,损耗等问题,同时还有导致梯度消失或梯度爆炸,导致很深的网络无法训练。ResNet在一定程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入,输出差别的那一部分,简化学习目标和难度。
接下来,作者就设计实验来证明自己的观点。首先构建了一个 18层和一个34层的plain网络,即将所有层进行监督的铺叠,然后构建一个 18层和一个34层的 residual网络,仅仅是在 plain 上插入了 shortcut,而且这两个网络的参数量,计算量相同,并且和之前有很好效果的 VGG-19对比,计算量要小很多(36亿FLOPs VS 196亿FLOPs,FLOPs 即每秒浮点运算次数)这也是作者反复强调的地方,也是这个模型最大的优势所在。
下图所示为 VGGNet-19,以及一个34层深的普通卷积网络,和34层深的ResNet网络的对比图。可以看到普通直连的卷积神经网络和ResNet的最大区别在于,ResNet有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这种结构也被称为 shortcut或 skip connections。
传统的卷积层或全连接层在信息传递时,或多或少的会存在信息丢失,损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则需要学习输入,输出差别的那一部分,简化学习目标和难度。
在ResNet的论文中,处理下图中的两层残差学习单元,还有三层的残差学习单元。两层的残差学习单元中包含两个相同输出通道数(因为残差等于目标输出减去输入,即 H(x) - x,因此输入,输出维度需保持一致)的 3*3 卷积;而3层的残差网络则使用了 Network In Network 和 Inception Net中的 1*1 卷积,并且是在中间 3*3 的卷积前后都使用了 1*1 卷积,有先降维再升维的操作。另外,如果有输入,输出维度不同的情况,我们可以对 x 做一个线性映射变换维度,再连接到后面的层。
下图为 VGG-19 ,直连的 34层网络(即plain,没有加入恒等映射的图),和ResNet的34层网络的结构(有 shortcut)对比:
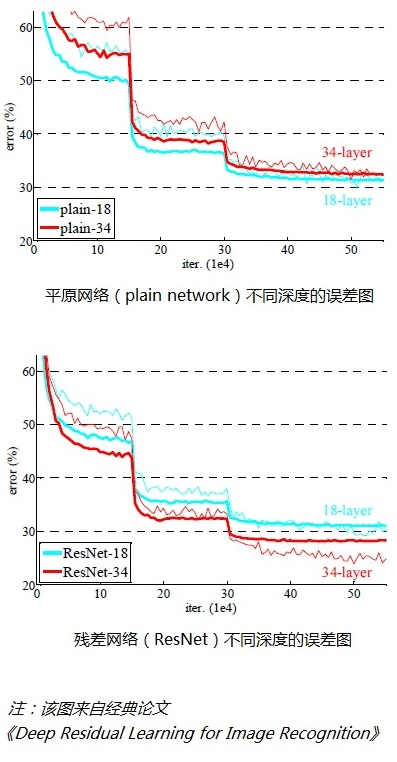
经检验,深度残差网络的确解决了退化问题,如下图所示,上图为平原网络(plain network)网络层次越深(34层)比网络层次浅的(18层)的误差率更高;右图为残差网络ResNet的网络层次越深(34层)比网络层次浅(18层)的误差率更低。不仅如此,ResNet的收敛速度比plain的要快得多。
6,ResNet不同层数的网络配置
下图是ResNet 不同层数时的网络配置(这里我们特别提出ResNet50和ResNet101,主要是因为他们的出镜率很高,所以需要做特别的说明):
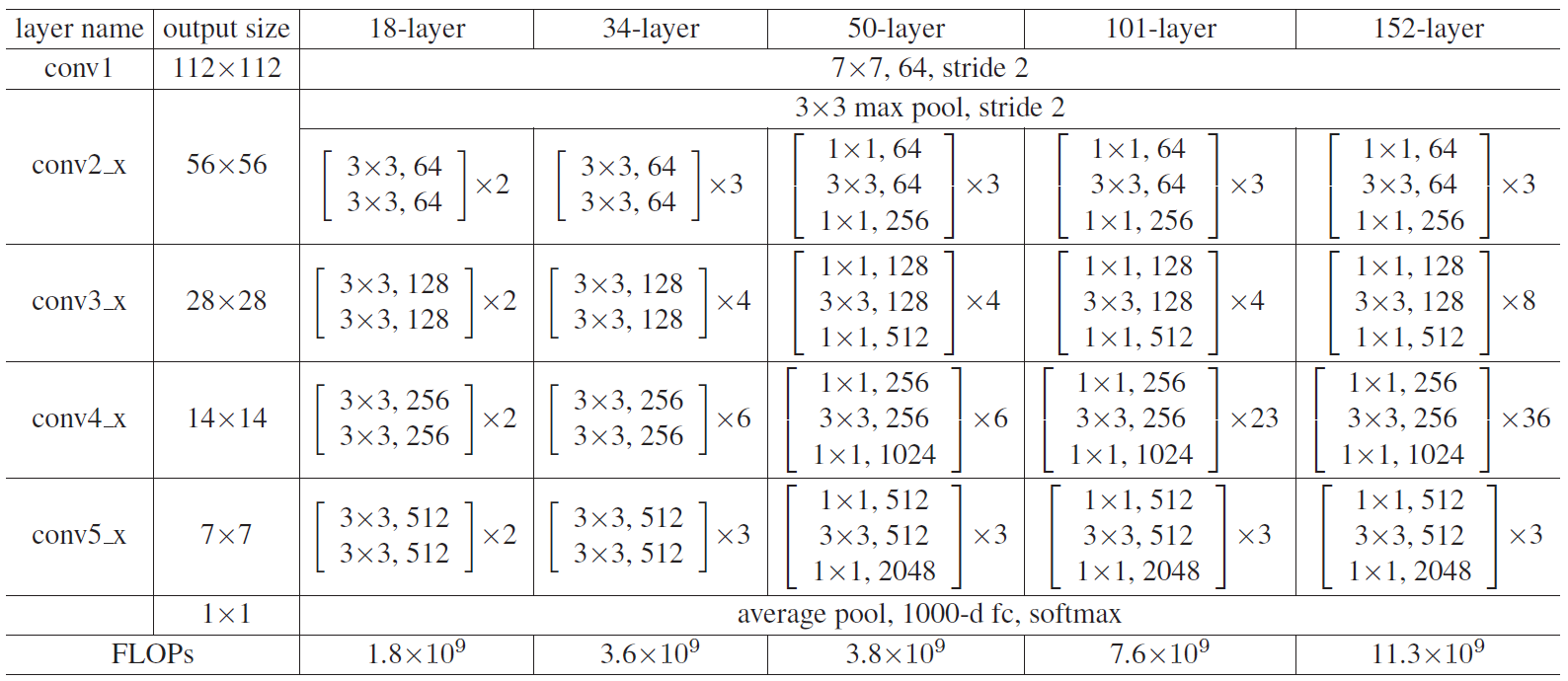
上表中,我们一共提出了五种深度的ResNet,分别是18, 34, 50, 101和152,首先看图2最左侧,我们发现所有的网络都分为五部分,分别是 conv1, conv2_x, conv3_x, conv4_x , conv5_x,之后的其他论文也会专门用这个称呼指代 ResNet 50 或者 101 的每部分。
拿 101-layer 那列,我们先看看 101-layer 是不是真的是 101 层网络,首先有个 输入 7*7*64的卷积,然后经过 3 + 4 + 23+ 3 = 33 个 building block ,每个 block 为3层,所以有 33*3 = 99 层,最后有个 fc 层(用于分类),所有有 1+99+1=101层,确实有101层网络;
注意1:101 层网络仅仅指卷积或者全连接层,而激活层或者 Pooling 层并没有计算在内;
注意2:这里我们关注50-layer 和 101-layer 这两列,可以发现,他们唯一的不同在于 conv4_x, ResNet50有6个block,而 ResNet101有 23 个 block,插了17个block,也就是 17*3=51层。
在使用了ResNet的结构后,可以发现层数不断加深导致的训练集上误差增大的现象被消除了,ResNet 网络的训练误差会随着层数增大而逐渐减小,并且在测试机上的表现也会变好。在ResNet推出后不久,Google就借鉴了ResNet的精髓,提出了 Inception V4和 Inception-ResNet-V2,并通过融合这两个模型,在 ILSVRC数据集上取得了惊人的 3.08%的错误率。可见,ResNet及其思想对卷积神经网络研究的贡献确实非常显著,具有很强的推广性。在ResNet的作者的第二篇相关论文 Identity Mappings in Deep Rsidual Networks中,ResNet V2被提出。ResNet V2和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信息可以直接传输,因此 skip connection 的非线性激活函数(如ReLU)替换为 Identity Mappings(y = x)。同时,ResNet V2在每一层中都使用了Batch Normalization。这样处理之后,新的残差学习单元将比以前更容易训练且泛化性更强。
根据 Schmidhuber 教授的观点,ResNet 类似于一个没有Gates 的LSTM 网络,即将输入 x 传递到后面层的过程是一直发生的,而不是学习出来的。同时,最近也有两篇论文表示,ResNet 基本等价于 RNN且ResNet的效果类似于在多层网络间的集成方法(ensemble)。ResNet在加深网络层数上做出来重大贡献,而另一篇论文 The Power of Depth for Feedforward Neural Networks 则从理论上证明了加深网络比加宽网络更有效,算是给ResNet 提供了声援,也是给深度学习为什么要深才有效提供合理的解释。
7,TensorFlow 实现ResNet V2网络
在ResNet的作者的第二篇相关论文《Identity Mappings in Deep Residual Networks》中,提出了ResNet V2。ResNet V2 和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此“shortcut connection”(捷径连接)的非线性激活函数(如ReLU)替换为 Identity Mappings。同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理后,新的残差学习单元比以前更容易训练且泛化性更强。
下面我们使用TensorFlow实现一个ResNet V2 网络。我们依然使用方便的 contrib.slim 库来辅助创建 ResNet,其余载入的库还有原生的 collections。本文代码主要来自于TensorFlow的开源实现。
我们使用 collections.namedtuple 设计ResNet 基本Block 模块组的 named tuple,并用它创建 Block 的类,但只包含数据结构,不包含具体方法。我们要定义一个典型的 Block,需要输入三个参数,分别是 scope,unit_fn 和 args。以Block('block1', bottleneck, [(256, 64, 1]) x 2 + [(256, 64, 2 )]) 这一行代码为例,它可以定义一个典型的Block,其中 block1 就是我们这个Block 的名称(或 scope);bottleneck 是ResNet V2中的残差学习单元;而最后一个参数 [(256, 64, 1]) x 2 + [(256, 64, 2 )] 则是这个Block 的 args,args 是一个列表,其中每个元素都对应一个 bottleneck残差学习单元,前面两个元素都是 (256,64,1),最后一个是(256,64,2)。每一个元素都是一个三元 tuple,即 (depth,depth_bottleneck, stride)。比如(256, 64, 3)代表构建的 bottleneck 残差学习单元(每个残差学习单元包含三个卷积层)中,第三层输出通道数 depth 为 256,前两层输出通道数 depth_bottleneck 为64,且中间那层的步长 stride 为3。这个残差学习单元结构即为 [(1x1/s1, 64), (3x3/s2, 64), (1x1/s1, 256)]。而在这个Block中,一共有3个bottleneck残差学习单元,除了最后一个的步长由3变为2,其余都一致。
#_*_coding:utf-8_*_
import collections
import tensorflow as tf
slim = tf.contrib.slim
class Block(collections.namedtuple('Block', ['scope', 'uint_fn', 'args'])):
'A named tuple describing a ResNet block'
下面定义一个降采样 subsample的方法,参数包括 inputs(输入),factor(采样因子)和scope。这个函数也非常简单,如果factor为1,则不做修改直接返回 inputs;如果不为1,则使用 slim.max_pool2d 最大池化来实现,通过1x1的池化尺寸,stride作步长,即可实现降采样。
def subsample(inputs, factor, scope=None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
再定义一个 conv2d_same函数创建卷积层。先判断 stride 是否为1,如果为1,则直接使用 slim.conv2d 并令 padding 模式为SAME。如果 stride 不为1,则显式地 pad zero,要pad zero 的总数为 Kernel_size -1 ,pad_beg 为 pad/2,pad_end 为余下的部分。接下来使用 tf.pad 对输入变量进行补零操作。最后,因为已经进行了 zero padding ,所以只需要使用一个 padding 模式为VALID 的 slim.conv2d 创建这个卷积层。
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride=1,
padding='SAME', scope=scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride,
padding='VALID', scope=scope)
接下来定义堆叠Blocks的函数,参数中的 net 即为输入,blocks是之前定义的Block 的class 的列表,而 outputs_collections 则是用来收集各个 end_points 的 collections。下面使用两层循环,逐个Block,逐个Residual Uint 地堆叠,先使用两个 tf.variable_scope 将残差学习单元命名为 block1 / uint_1 的形式。在第二层循环中,我们拿到每个Block中每个Residual Unit的args,并展开为 depth,depth_bottleneck 和 stide,其含义在前面定义Blocks类时已经学习过。然后使用 unit_fn 函数(即残差学习单元的生成函数)顺序地创建并连接所有的残差学习单元。最后,我们使用 slim.utils.collect_named_outpouts 函数将输出 net 添加到 collection 中 。最后,当所有 Block 中的所有Residual Unit 都堆叠完之后,我们再返回最后的 net 作为 stack_blocks_dense 函数的结果。
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections=None):
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' % (i+1), values=[net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net,
depth=unit_depth,
unit_depth_bottleneck=unit_depth_bottleneck,
steide=unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
return net
这里创建 ResNet通用的 arg_scope,关于 arg_scope,我们已经知道其功能——用来定义某些函数的参数默认值。这里定义训练标记 is_training 默认为TRUE,权重衰减速率 weight_decay 默认为 0.0001,BN的衰减速率默认为 0.997,BN的 epsilon默认为 1e-5,BN的 scale默认为 TRUE,和Inception V3定义 arg_scope一样,先设置好BN的各项参数,然后通过slim.arg_scope将 slim.conv2d的几个默认参数设置好:权重正则器设置为 L2正则,权重初始化器设为 slim.variance_scaling_initializer(),激活函数设为 ReLU,标准化器设为 BN。并将最大池化 的padding模式默认设为 SAME(注意,ResNet原论文中使用的 VALID模式,设为SAME可让特征对其更简单,大家可以尝试改为 VALID)。最后将几层嵌套的 arg_scope 作为结果返回。
def resnet_arg_scope(is_training=True,
weight_decay=0.0001,
batch_norm_decay=0.997,
batch_norm_epsilon=1e-5,
batch_norm_scale=True):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params
):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
return arg_sc
接下来定义核心的 bottleneck 残差学习单元,它是ResNet V2 的论文中提到的 Full Preactivation Residual Unit 的一个变种。它和ResNet V1 中的残差学习单元的主要区别有两点,一是在每层前都用了Batch Bormalization,而是对输入进行 practivation,而不是在卷积进行激活函数处理。我们来看一下bottleneck 函数的参数,inputs是输入,depth,depth_bottleneck和stride这三个参数前面的 Batch Normalization,并使用 ReLU函数进行预激活Preactivate。然后定义 shortcut(即直连的 x):如果残差单元的输入通道数 depth_in和输出通道数 depth一致,那么使用 subsample按步长为 stride 对 Inputs 进行空间上的降采样(确保空间尺寸和残差一致,因为残差中间那层的卷积步长为 stride);如果输入,输出通道数不一样,我们用步长为 stride 的1*1 卷积改变其通道数,使得与输出通道数一致。然后定义 Residual(残差),residual这里有3层,先是一个1*1尺寸,步长为1,输出通道数为depth_bottleneck的卷积,然后是一个3*3尺寸,步长为 stride,输出通道数为 depth_bottleneck的卷积,最后是一个1*1的卷积,步长为1,输出通道数为depth的卷积,得到最终的 residual,这里注意最后一层没有正则项也没有激活函数。然后将residual 和 shortcut 相加,得到最后结果 output,再使用 slim.utils.collect_named_outpouts 将结果添加进 collection并返回 output 作为函数结果。
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride,
outputs_collections=None, scope=None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None,
scope='shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
scope='conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride,
scope='conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalozer_fn=None, activation_fn=None,
scope='conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output)
下面定义生成ResNet V2 的主函数,我们只需要预先定义好网络的残差学习模块组blocks,它就可以生成对应的完整的ResNet。先看看这个函数的参数,Inputs 即输入,blocks为定义好的Block类的列表,num_classes是最后输出的类数。global_pool 标志是否加上最后的一层全局平均池化,include_root_block 标志是否加上ResNet网络最前面通常使用的7*7卷积和最大池化,reuse标志是否重用,scope是整个网络的名称。在函数体内,我们先定义好variable_scope及 end_points_collection,再通过 slim.arg_scope 将(slim.con2d,bottleneck, stack_block_dense)这三个函数的参数 outputs_collections默认设为 end_points_collection。然后根据 include_root_block标记,创建ResNet最前面的 64输出通道的步长为2的7*7卷积,然后再接一个步长为2的3*3的最大池化。经历两个步长为2的层,图片尺寸已经被缩小为1/4。然后,使用前面定义好的 stack_blocks_dense 将残差学习模块组生成好,再根据标记添加全局池化层,这里用 tf.reduce_mean 实现全局平均池化,效率比直接用 avg_pool高。下面根据是否有分类数,添加一个输出通道数为 Num_classes的1*1卷积(该卷积层无激活函数和正则项),再添加一个 Softmax层输出网络结果。同时使用 slim.utils.convert_collection_to_dict 将 collection 转化为Python的 dict,最后返回 net 和 end_points。
def resnet_v2(inputs,
blocks,
num_classes=None,
global_pool=True,
include_root_block=True,
reuse=None,
scope=None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck,
stack_blocks_dense],
outputs_collections=end_points_collection):
net = inputs
if include_root_block:
with slim.arg_scope([slim.conv2d],
activation_fn=None, normalizer_fn=None):
net = conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = stack_blocks_dense(net, blocks)
net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
if global_pool:
net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='logits')
end_points = slim.utils.convert_collection_to_dict(
end_points_collection
)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope='predictions')
return net, end_points
至此,我们就将 ResNet 的生成函数定义好了。下面根据ResNet不同层数时的网络配置图中推荐的几个不同深度的ResNet网络配置,来设计层数分别为 50, 101, 152 和 200 的ResNet。我们先来看 50层的ResNet,其严格遵守了图中的设置,4个残差学习Blocks 的 units数量分别为3, 4, 6和3,总层数即为 (3+4+6+3)x3+2=50。需要注意的时,残差学习模块之前的卷积,池化已经将尺寸缩小为4倍,我们前3个Blocks又都包含步长为2的层,因此总尺寸缩小了 4*8=32倍,输入图片尺寸最后变为 224/32=7 。和 Inception V3很像,ResNet 不断使用步长为2的层来缩减尺寸,但同时输出通道数也在持续增加,最后达到了 2048。
def resnet_v2_50(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_50'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)
]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
101 层的ResNet 和50层相比,主要变化就是把4个Blocks的units 数量从3, 4, 6,3提升到了3, 4, 23, 3 。即将第三个残差学习Block 的units 数增加到接近4倍。
def resnet_v2_101(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_101'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 22 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)
]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
然后152层的ResNet,则是将第二个Block 的units数提高到8,将第三个 Block的 units 数提高到36。Units数量提升的主要场所依然是第三个Block。
def resnet_v2_152(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_152'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)
]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
最后,200层的Resnet 相比152层的ResNet ,没有继续提升第三个Block的units数,而是将第二个Block的 units 数一下子提升到了23。
def resnet_v2_200(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_200'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 23 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)
]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
最后我们使用一直以来的测评函数 timne_tensorflow_run,来测试 152层深的 ResNet(即获得 ILSVRC 2015 冠军的版本)的forward 性能。图片尺寸回归到AlexNet ,VGGNet的 224*224,batch_size 为32。我们将 is_training 这个 FLAG置为FALSE。然后使用 resnet_v2_152 创建网络,再由 time_tensorflow_run 函数测评其 forward 性能。这里不再对训练时的性能进行测试了,大家可以自行测试求解ResNet全部参数的梯度所需要的时间。
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration=%.3f'%(datetime.now(),
i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch'% (datetime.now(),
info_string, num_batches, mn, sd))
if __name__ == '__main__':
batch_size = 32
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(resnet_arg_scope(is_training=False)):
net, endpoints = resnet_v2_152(inputs, 1000)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, net, 'Forward')
这里可以看到,虽然这个ResNet有152层深,但其forward计算耗时并没有特别夸张,相比 VGGNet 和 Inception_v3,大概只增加了 50%,每batch为 0.122 秒。这说明 ResNet也是一个实用的卷积神经网络结构,不仅支持超深网络的训练,同时在实际工业应用时也有不差的forward 性能。
2019-09-17 13:40:28.111221: step 0, duration=0.124 2019-09-17 13:40:29.336873: step 10, duration=0.122 2019-09-17 13:40:30.555401: step 20, duration=0.122 2019-09-17 13:40:31.774261: step 30, duration=0.122 2019-09-17 13:40:32.993206: step 40, duration=0.122 2019-09-17 13:40:34.210301: step 50, duration=0.122 2019-09-17 13:40:35.426938: step 60, duration=0.122 2019-09-17 13:40:36.644774: step 70, duration=0.122 2019-09-17 13:40:37.861877: step 80, duration=0.122 2019-09-17 13:40:39.078488: step 90, duration=0.122 2019-09-17 13:40:40.173907: Forward across 100 steps, 0.012 +/- 0.037 sec / batch
本文我们完整的学习了ResNet的基本原理及Tensorflow实现,也设计了一系列不同深度的 ResNet。如果大家感兴趣可以自行探索不同深度,乃至不同残差单元结构的ResNet的分类性能。例如,ResNet 原论文中主要增加的时第二个和第三个Block的 units数,大家可以尝试增加其余两个Block的 units数,或者修改bottleneck单元中的 depth,depth_bottleneck等参数,可对其参数设置的意义加深理解。ResNet 可以算是深度学习中的一个里程碑式的图片,真正意义上支持极深神经网络的训练。其网络结构值得反复思索,如Google等已将其融合到自家的 Inception Net中,并取得了非常好的效果。相信ResNet的成功也会启发其他在深度学习领域研究的灵感。
完整代码如下:
import collections
import tensorflow as tf
slim = tf.contrib.slim
class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
"""A named tuple describing a ResNet block.
Its parts are:
scope: The scope of the `Block`.
unit_fn: The ResNet unit function which takes as input a `Tensor` and
returns another `Tensor` with the output of the ResNet unit.
args: A list of length equal to the number of units in the `Block`. The list
contains one (depth, depth_bottleneck, stride) tuple for each unit in the
block to serve as argument to unit_fn.
"""
def subsample(inputs, factor, scope=None):
"""Subsamples the input along the spatial dimensions.
Args:
inputs: A `Tensor` of size [batch, height_in, width_in, channels].
factor: The subsampling factor.
scope: Optional variable_scope.
Returns:
output: A `Tensor` of size [batch, height_out, width_out, channels] with the
input, either intact (if factor == 1) or subsampled (if factor > 1).
"""
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None):
"""Strided 2-D convolution with 'SAME' padding.
When stride > 1, then we do explicit zero-padding, followed by conv2d with
'VALID' padding.
Note that
net = conv2d_same(inputs, num_outputs, 3, stride=stride)
is equivalent to
net = slim.conv2d(inputs, num_outputs, 3, stride=1, padding='SAME')
net = subsample(net, factor=stride)
whereas
net = slim.conv2d(inputs, num_outputs, 3, stride=stride, padding='SAME')
is different when the input's height or width is even, which is why we add the
current function. For more details, see ResnetUtilsTest.testConv2DSameEven().
Args:
inputs: A 4-D tensor of size [batch, height_in, width_in, channels].
num_outputs: An integer, the number of output filters.
kernel_size: An int with the kernel_size of the filters.
stride: An integer, the output stride.
rate: An integer, rate for atrous convolution.
scope: Scope.
Returns:
output: A 4-D tensor of size [batch, height_out, width_out, channels] with
the convolution output.
"""
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride=1,
padding='SAME', scope=scope)
else:
# kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1)
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs,
[[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride,
padding='VALID', scope=scope)
@slim.add_arg_scope
def stack_blocks_dense(net, blocks,
outputs_collections=None):
"""Stacks ResNet `Blocks` and controls output feature density.
First, this function creates scopes for the ResNet in the form of
'block_name/unit_1', 'block_name/unit_2', etc.
Args:
net: A `Tensor` of size [batch, height, width, channels].
blocks: A list of length equal to the number of ResNet `Blocks`. Each
element is a ResNet `Block` object describing the units in the `Block`.
outputs_collections: Collection to add the ResNet block outputs.
Returns:
net: Output tensor
"""
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net,
depth=unit_depth,
depth_bottleneck=unit_depth_bottleneck,
stride=unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
return net
def resnet_arg_scope(is_training=True,
weight_decay=0.0001,
batch_norm_decay=0.997,
batch_norm_epsilon=1e-5,
batch_norm_scale=True):
"""Defines the default ResNet arg scope.
TODO(gpapan): The batch-normalization related default values above are
appropriate for use in conjunction with the reference ResNet models
released at https://github.com/KaimingHe/deep-residual-networks. When
training ResNets from scratch, they might need to be tuned.
Args:
is_training: Whether or not we are training the parameters in the batch
normalization layers of the model.
weight_decay: The weight decay to use for regularizing the model.
batch_norm_decay: The moving average decay when estimating layer activation
statistics in batch normalization.
batch_norm_epsilon: Small constant to prevent division by zero when
normalizing activations by their variance in batch normalization.
batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the
activations in the batch normalization layer.
Returns:
An `arg_scope` to use for the resnet models.
"""
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
# The following implies padding='SAME' for pool1, which makes feature
# alignment easier for dense prediction tasks. This is also used in
# https://github.com/facebook/fb.resnet.torch. However the accompanying
# code of 'Deep Residual Learning for Image Recognition' uses
# padding='VALID' for pool1. You can switch to that choice by setting
# slim.arg_scope([slim.max_pool2d], padding='VALID').
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
return arg_sc
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride,
outputs_collections=None, scope=None):
"""Bottleneck residual unit variant with BN before convolutions.
This is the full preactivation residual unit variant proposed in [2]. See
Fig. 1(b) of [2] for its definition. Note that we use here the bottleneck
variant which has an extra bottleneck layer.
When putting together two consecutive ResNet blocks that use this unit, one
should use stride = 2 in the last unit of the first block.
Args:
inputs: A tensor of size [batch, height, width, channels].
depth: The depth of the ResNet unit output.
depth_bottleneck: The depth of the bottleneck layers.
stride: The ResNet unit's stride. Determines the amount of downsampling of
the units output compared to its input.
rate: An integer, rate for atrous convolution.
outputs_collections: Collection to add the ResNet unit output.
scope: Optional variable_scope.
Returns:
The ResNet unit's output.
"""
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None,
scope='shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
scope='conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride,
scope='conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalizer_fn=None, activation_fn=None,
scope='conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections,
sc.name,
output)
def resnet_v2(inputs,
blocks,
num_classes=None,
global_pool=True,
include_root_block=True,
reuse=None,
scope=None):
"""Generator for v2 (preactivation) ResNet models.
This function generates a family of ResNet v2 models. See the resnet_v2_*()
methods for specific model instantiations, obtained by selecting different
block instantiations that produce ResNets of various depths.
Args:
inputs: A tensor of size [batch, height_in, width_in, channels].
blocks: A list of length equal to the number of ResNet blocks. Each element
is a resnet_utils.Block object describing the units in the block.
num_classes: Number of predicted classes for classification tasks. If None
we return the features before the logit layer.
include_root_block: If True, include the initial convolution followed by
max-pooling, if False excludes it. If excluded, `inputs` should be the
results of an activation-less convolution.
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
Returns:
net: A rank-4 tensor of size [batch, height_out, width_out, channels_out].
If global_pool is False, then height_out and width_out are reduced by a
factor of output_stride compared to the respective height_in and width_in,
else both height_out and width_out equal one. If num_classes is None, then
net is the output of the last ResNet block, potentially after global
average pooling. If num_classes is not None, net contains the pre-softmax
activations.
end_points: A dictionary from components of the network to the corresponding
activation.
Raises:
ValueError: If the target output_stride is not valid.
"""
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck,
stack_blocks_dense],
outputs_collections=end_points_collection):
net = inputs
if include_root_block:
# We do not include batch normalization or activation functions in conv1
# because the first ResNet unit will perform these. Cf. Appendix of [2].
with slim.arg_scope([slim.conv2d],
activation_fn=None, normalizer_fn=None):
net = conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = stack_blocks_dense(net, blocks)
# This is needed because the pre-activation variant does not have batch
# normalization or activation functions in the residual unit output. See
# Appendix of [2].
net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
if global_pool:
# Global average pooling.
net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='logits')
# Convert end_points_collection into a dictionary of end_points.
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope='predictions')
return net, end_points
def resnet_v2_50(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_50'):
"""ResNet-50 model of [1]. See resnet_v2() for arg and return description."""
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block(
'block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block(
'block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]),
Block(
'block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
def resnet_v2_101(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_101'):
"""ResNet-101 model of [1]. See resnet_v2() for arg and return description."""
blocks = [
Block(
'block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block(
'block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block(
'block3', bottleneck, [(1024, 256, 1)] * 22 + [(1024, 256, 2)]),
Block(
'block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
def resnet_v2_152(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_152'):
"""ResNet-152 model of [1]. See resnet_v2() for arg and return description."""
blocks = [
Block(
'block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block(
'block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block(
'block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block(
'block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
def resnet_v2_200(inputs,
num_classes=None,
global_pool=True,
reuse=None,
scope='resnet_v2_200'):
"""ResNet-200 model of [2]. See resnet_v2() for arg and return description."""
blocks = [
Block(
'block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block(
'block2', bottleneck, [(512, 128, 1)] * 23 + [(512, 128, 2)]),
Block(
'block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block(
'block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool,
include_root_block=True, reuse=reuse, scope=scope)
from datetime import datetime
import math
import time
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
if __name__ == '__main__':
batch_size = 32
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(resnet_arg_scope(is_training=False)):
net, end_points = resnet_v2_152(inputs, 1000)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, net, "Forward")
本文是学习ResNet网络的笔记,参考了《tensorflow实战》这本书中关于ResNet的章节,写的非常好,所以在此做了笔记,侵删。
而且本文在学习中,摘抄了下面博客的ResNet笔记,也写的通俗易通:
https://my.oschina.net/u/876354/blog/1634322
https://www.zybuluo.com/rianusr/note/1419006
https://my.oschina.net/u/876354/blog/1622896
参考文献:https://blog.csdn.net/u013181595/article/details/80990930
https://blog.csdn.net/lanran2/article/details/79057994
ResNet的论文文献: https://arxiv.org/abs/1512.03385
强烈建议学习何凯文关于深度残差网络的两篇经典论文,深度残差网络的主要思想,便是来自下面两篇论文:
- 《Deep Residual Learning for Image Recognition》(基于深度残差学习的图像识别)
- 《Identity Mappings in Deep Residual Networks》(深度残差网络中的特征映射)
在学习后,确实对ResNet 理解了不少,在此很感谢。
https://blog.csdn.net/qq_25491201/article/details/78405549
keras实现:https://blog.csdn.net/Solo95/article/details/85177557

 浙公网安备 33010602011771号
浙公网安备 33010602011771号