
卷积神经网络学习笔记——GoogLeNet(Tensorflow实现)
完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet”,所以我们这里题目就叫GoogLeNet。后面我们为了方便就叫inception Net。
Google Inception Net 首次出现在 ILSVRC 2014的比赛中(和VGGNet 同年),就以较大优势取得了第一名。那一届比赛中的 Inception Net 通常被称为inception V1,它最大的特点就是控制了计算量和参数量的同时,获得了非常好的分类性能——top-5 错误率 6.67%,只有 AlexNet的一半不到。Inception V1 有22 层深,比 AlexNet的8层或者 VGGNet的19层还要更深。但其大小却比AlexNet和VGG小很多,计算量只有 15亿次浮点运算,同时只有500万的参数量,仅为 AlexNet 参数量(6000万)的 1/12,却可以达到远胜于 AlexNet的准确率,可以说是非常优秀且非常实用的模型。因此在内存或计算资源有限时,GoogLeNet是比较好的选择;从模型结果来看,GoogLeNet的性能更加优越。
1,GoogLeNet 是如何进一步提升性能?
GoogLeNet 带来的性能提升很大程度上要归功于“降维”,也就是卷积分解的一种。考虑到网络邻近的激活单元高度相关,因此聚合之前进行降维可以得到类似于局部特征的东西。接下来主要讨论其他的卷积分解方法。既然Inception网络是全卷积,卷积计算变少也就意味着计算量变小,这些多出来的计算资源可以来增加 filter-bank 的尺寸大小。
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题:
- (1)参数太多,如果训练数据集有限,很容易产生过拟合;
- (2)网络越大、参数越多,计算复杂度越大,难以应用;
- (3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
如何减少参数?
- 第一步通过2个3*3的卷积核来代替一个5*5的卷积核,感受野相同的情况下,两个3*3的卷积核的参数为2*3*3=18,而5*5卷积核的参数为25个;
- 在卷积之前通过1*1的卷积核来降低feature map维度,之后再卷积;
- 将n*n的卷积核替换为1*n和n*1两个卷积核。
2,GoogLeNet 的特点
2.1,参数更少
GoogLeNet 参数为500万个,AlexNet参数个数为 GoogLeNet 的12倍,VGGNet参数又是 AlexNet的3倍。
2.2,性能更好
占用更少的内存和计算资源,且模型结果的性能却更加优越。
Inception 历经了 V1,V2,V3,V4等多个版本的发展,不断趋于完善,下面一一进行介绍。
3,稀疏结构和Hebbian原理的学习
人脑神经元的连接是稀疏的,因此研究者认为大型神经网络的合理连接方式应该也是稀疏的。稀疏结构是非常适合神经网络的一种结构,尤其是对非常大型,非常深的神经网络,可以减轻过拟合并降低计算量,例如卷积神经网络就是稀疏的连接。Inception Net的主要目标就是找到最优的稀疏结构单元(即Inception Module),论文中提到其稀疏结构基于 Hebbian原理,这里简单解释一下Hebbian原理:神经反射活动的持续与重复会导致神经元连接稳定性的持久提升,当两个神经元细胞 A 和B 距离很近,并且A 参与了对B重复,持续的兴奋,那么某些代谢会导致A将作为能使B兴奋的细胞。总结一下即“一起发射的神经元会连接一起”(Cells that fire together, were together),学习过程中的刺激会使神经元间的突触强度增加。受 Hebbian原理启发,另一篇文章 Provable Bounds for learning Some Deep Representations 提出,如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方法时逐层构筑网络:将上一层高度相关(correlated)的节点聚类,并将聚类出来的每一个小簇(cluster)连接到一起,如下图所示,这个相关性高的节点应该被连接在一起的结论,即使从神经网络的角度对 Hebbian 原理有效性的证明。

因此一个“好”的稀疏结构,应该是符合 Hebbian原理的,我们应该把相关性高的一簇神经元节点连接在一起。在普通的数据集中,这可能需要对神经元节点聚类,但是在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一空间位置但在不同通道的卷积核的输出结果相关性极高。因此,一个1*1的卷积就可以很自然的把这些相关性很高的,在同一个空间位置但是不同通道的特征连接在一起,这就是为什么1*1卷积这么频繁的被应用到 Inception Net 中的原因。1*1 卷积所连接的节点的相关性是最高的,而稍微大一点尺寸的卷积,比如 3*3 5*5 的卷积所连接的节点的相关性是最高的,而稍微大一点的卷积,比如 3*3,5*5的卷积所连接的节点相关性也很高,因此也可以适当地使用一些大尺寸的卷积,增加多样性(diversity)。最后 Inception Module 通过4个分支中不同尺寸的 1*1 3*3 5*5 等小型卷积将相关性很高的节点连接在一起,就完成了其设计初衷,构建出了很高效的符合 Hebbian原理的稀疏结构。
在Inception Module 中,通常 1*1 卷积的比例(输出通道数占比)最高,3*3 卷积和 5*5 卷积稍低。而在整个网络中,会有多个堆叠的 Inception Module ,我们希望靠后的 Inception Module 可以捕捉更高阶的抽象特征,因此靠后的 Inception Module 的卷积的空间几何度应该逐渐降低,这样可以捕获更大面积的特征。因此,越靠后的 Inception Module 中,3*3 5*5 这两个大面积的 卷积核的占比(输出通道数)应该更多。
inception Net 有22层深,除了最后一层的输出,其中间节点的分类效果也很好。因此在 Inception Net中,还使用到了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信息,也提供了额外的正则化,对于整个 Inception Net的训练很有裨益。
当年的 Inception V1还是跑在TensorFlow 的前辈 DistBelief 上的,并且只允许在CPU上,当时使用了异步的 SGD 训练,学习速率每迭代8个epoch 降低4%,同时,Inception V1也使用了 Multi-Scale,Multi-Crop 登上护具增强方法,并在不同的采样数据上训练了7个模型进行融合,得到了最后的 ILSVRC
2014 的比赛成绩——top -5 错误率 6.67%。

4,inception V1
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。谷歌提出了最原始的Inception的基本结构:

该结构将CNN 中常用的卷积(1*1,3*3, 5*5),池化操作(3*3)堆叠在一起(卷积,池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺寸的适应性。
网络卷积层中的网络能够提取输入的每一个细节信息,同时 5*5 的滤波器也能够覆盖大部分接受层的输入。还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,在每一个卷积层后都要做一个ReLU操作,以增加网络的非线性特征。
然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5*5的卷积核所需要的计算量就太大了,造成了特征图的厚度很大,为了避免这种情况,在3*3, 5*5前,max_pooling 后分别加上了 1*1 的卷积核,以起到了降低特征图厚度的作用,这也就形成了 Inception V1的网络结构,如下图所示:

对上面的 inception模块的四个并行线路解释如下:
1.一个 1 x 1 的卷积,一个小的感受野进行卷积提取特征 2.一个 1 x 1 的卷积加上一个 3 x 3 的卷积,1 x 1 的卷积降低输入的特征 通道,减少参数计算量,然后接一个 3 x 3 的卷积做一个较大感受野的卷积 3.一个 1 x 1 的卷积加上一个 5 x 5 的卷积,作用和第二个一样 4.一个 3 x 3 的最大池化加上 1 x 1 的卷积,最大池化改变输入的特征排列, 1 x 1 的卷积进行特征提取
下面学习 Inception Module 的基本结构,其中有4个分支:第一个分支对输入进行 1*1 的卷积,这其实也是 NIN 中提出的一个重要结构,1*1 的卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。可以看到 Inception Module 的四个分支都用到了 1*1 卷积,来进行低成本(计算量比 3*3 小很多)的跨通道的特征变换。第二个分支先使用了 1*1卷积,然后连接 3*3 卷积,相当于进行了两次特征变换。第三个分支类似,先是 1*1 卷积。然后连接 5*5 卷积,最后一个分支则是 3*3 最大池化后直接使用 1*1 卷积。我们可以发现,有的分支只使用 1*1 卷积,有的分支使用了其他尺寸的卷积时也会再使用 1*1 卷积,这是因为 1*1 卷积的性价比很高,用很小的计算量就能增加一层特征变换和非线性化, Inception Module 的四个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合)。 Inception Module 的四个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合)。 Inception Module 中包含了3种不同尺寸的卷积和1个最大池化,增加了网络对不同尺度的适应性,这一部分和 Multi-Scale 的思想类似。早期计算机视觉的研究中,受灵长类神经视觉系统的启发,Serre 使用不同尺寸的 Gabor 滤波器处理不同的图片,Inception V1借鉴了这种思想。inception V1的论文中指出, Inception Module 可以让网络的深度和宽度高效果地扩充,提升准确率且不至于过拟合。
4.1 辅助分类器
inception v1 引入了辅助分类器的概念,以改善非常深的网络的收敛。最初的动机是将有用的梯度推向较低层,使其立即有用,并通过抵抗非常深的网络中的消失梯度问题来提高训练过程中的收敛。有趣的是,我们发现辅助分类器在训练早期并没有导致改善收敛:在两个模型达到高精度之前,有无侧边网络的训练进度看起来几乎相同。接近训练结束,辅助分支网络开始超越没有任何分支的网络的准确性,达到了更高的稳定水平。
另外,inception V1在网络的不同阶段使用了两个侧分支。移除更下面的辅助分支对网络的最终质量没有任何不利影响。再加上前一段的观察结果,这意味着这些分支有助于演变低级特征很可能是不适当的。相反,我们认为辅助分类器起着正则化项的作用。这是由于如果侧分枝是批标准化的(BN)或具有丢弃层(Dropout),则网络的主分类器性能更好。这也为推测BN作为正则化项给出了一个弱支持证据。
4.2 1*1 的卷积核有什么用呢?
GoogLeNet性能优异很大程度在于使用了降维。降维可以看做卷积网络的因式分解。例如1*1 卷积层后跟着 3*3卷积层。
1*1 卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。比如,上一层的输出为100*100*128,经过具有256个通道的5*5卷积层之后(stride=1, pad=2),输出数据为100*100*256,其中,卷积层的参数为 128*5*5*256=819200。而加入上一层输出先经过具有32个通道的1*1卷积层,再经过具有 256 个输出的 5*5 卷积层,那么输出数据仍为 100*100*256,但卷积参数量已经减少为 128*1*1*32 + 32*5*5*256 = 204800,大约减少了 4倍。
4.3 Inception V1降低参数量的目的
1,参数越多模型越庞大,需要供模型学习的数据量就越大,而且目前高质量的数据非常昂贵;
2,参数越多,耗费的计算资源也会更大;
inception V1 参数少但是效果好的原因除了模型层数更深,表达能力更强外,还有两点:一是去除最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了 AlexNet 或者 VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。用全局平均池化层取代全连接层的做法借鉴了 Network in Network(以下简称 NIN)论文。二是 Inception V1中精心设计的 Inception Module 提高了参数的利用效率,其结构如图所示。这一部分也借鉴了NIN的思想,形象的解释就是 inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。不过 Inception V1比 NIN 更进一步的时增加了分支网络,NIN则主要是级联的卷积层和 MLPConv层。一般来说卷积层要提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大和过拟合。每一个输出通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。而 NIN中的 MLPConv 则拥有更强大的能力,允许在输出通道之间组合信息,因此效果明显。可以说,MLPConv 基本等效于普通卷积层后再连接 1*1 的卷积和 ReLU激活函数。
基于 Inception 构建了 GoogLeNet 的网络结构如下(共 22 层):
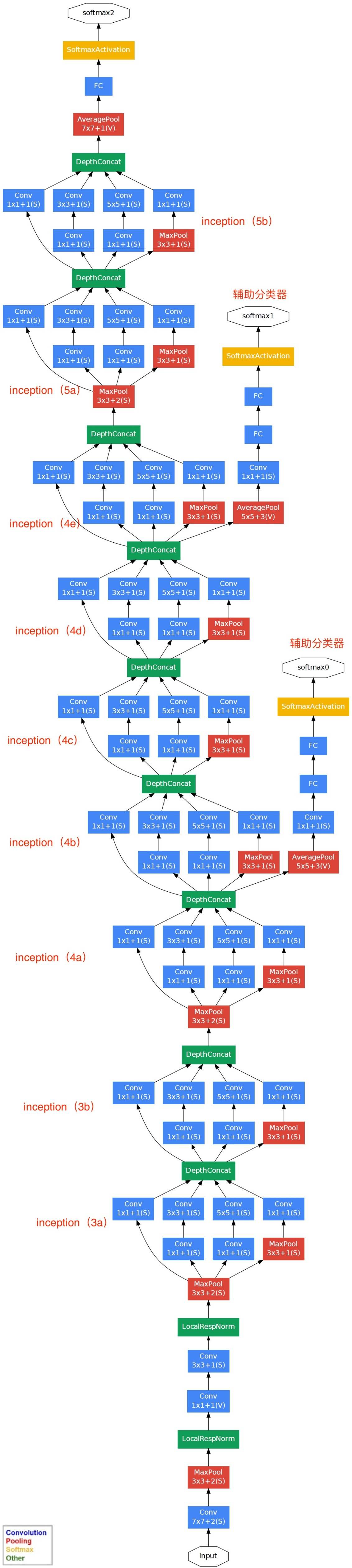
对上图说明如下:
(1) GoogLeNet 采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了 average pooling (平均池化)来代替全连接层,该想法来自于 NIN(Network in Network),事实证明这样可以将准确率提高 0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接层,但是网络中依然使用了Dropout;
(4)为了避免梯度小时,网络额外增加两个辅助的 softmax 用于前向传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的 softmax 会被去掉。
所以总结来说就是:inception V1 参数少但是效果好的原因除了模型层数更深,表达能力更强外,还有两点:一是去除最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了 AlexNet 或者 VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。用全局平均池化层取代全连接层的做法借鉴了 Network in Network(以下简称 NIN)论文。二是 Inception V1中精心设计的 Inception Module 提高了参数的利用效率,其结构如上图所示。这一部分也借鉴了NIN的思想,形象的解释就是 inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。不过 Inception V1比 NIN 更进一步的时增加了分支网络,NIN则主要是级联的卷积层和 MLPConv层。一般来说卷积层要提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大和过拟合。每一个输出通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。而 NIN中的 MLPConv 则拥有更强大的能力,允许在输出通道之间组合信息,因此效果明显。可以说,MLPConv 基本等效于普通卷积层后再连接 1*1 的卷积和 ReLU激活函数。
GoogLeNet 的网络结构图细节如下:
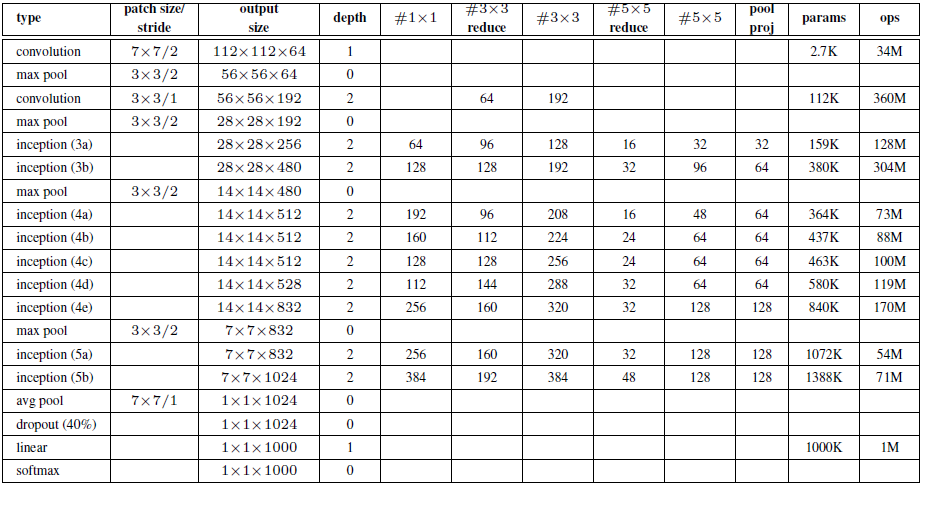
注意:上表的“#3*3 reduce”,“# 5*5 reduce” 表示在 3*3 , 5*5 卷积操作之前使用了 1*1 卷积的数量。
4.3 GoogLeNet 网络结构明细表解析
0、输入
原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
1、第一层(卷积层)
使用7x7的卷积核(滑动步长2,padding为3),64通道,输出为112x112x64,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,即56x56x64,再进行ReLU操作
2、第二层(卷积层)
使用3x3的卷积核(滑动步长为1,padding为1),192通道,输出为56x56x192,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x192,再进行ReLU操作
3a、第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积核来进行处理
(1)64个1x1的卷积核,然后RuLU,输出28x28x64
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
(4)pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
3b、第三层(Inception 3b层)
(1)128个1x1的卷积核,然后RuLU,输出28x28x128
(2)128个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x128,进行ReLU,再进行192个3x3的卷积(padding为1),输出28x28x192
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x32,进行ReLU计算后,再进行96个5x5的卷积(padding为2),输出28x28x96
(4)pool层,使用3x3的核(padding为1),输出28x28x256,然后进行64个1x1的卷积,输出28x28x64。
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为28x28x480
第四层(4a,4b,4c,4d,4e)、第五层(5a,5b)……,与3a、3b类似,在此就不再重复。
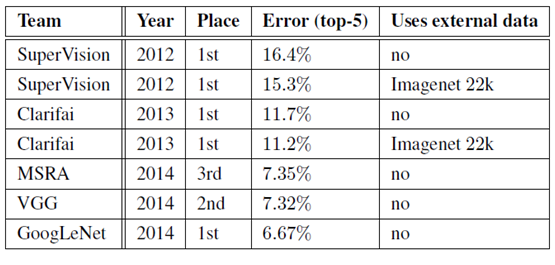
从GoogLeNet 的实验结果来看,效果很明显,差错率比 MSRA,VGG等模型都要低,对比结果如下图:
5,Inception V2
GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此GoogLeNet团队又对其进行了进一步地发掘改进,产生了升级版本的GoogLeNet。GoogLeNet设计的初衷就是要又准又快,而如果只是单纯的堆叠网络虽然可以提高准确率,但是会导致计算效率有明显的下降,所以如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。
Inception V2版本的解决方案就是修改Inception的内部计算逻辑,提出了比较特殊的“卷积”计算结构。
inception V2学习了VGGNet,用两个 3*3 的卷积代替了 5*5 的大卷积(用以降低参数量并减轻过拟合),还提出了 Batch Normalization(以下简称 BN)方法。BN 是一个非常有效地正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅的提高。BN在用于神经网络某层时,会对每一个 mini-batch 数据的内部进行标准化(normalization)处理,使输出规范化到 N(0,1)的正态分布,减少了 Internal Convarate Shift(内部神经元分布的改变)。BN 的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有幸的解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有 1/14,训练时间大大缩短。而达到之前的准确率后,可以继续训练,并最终远超于 Inception V1模型的性能——Top-5 错误率 4.8%,已经优于人眼水平。因为BN某种意义上还起到了正则化的作用。所以可以减少或者取消 Dropout,简化网络结构。
当然,只是单纯的使用 BN获得的增益还不明显,还需要一些相应的调整:增大学习速率并加快学习衰减速度以适用 BN 规范化后的数据;去掉 Dropout并减轻 L2 正则(因 BN已起到正则化的作用);去掉 LRN;更彻底地对训练样本进行 shuffle;减少数据增强过程中队数据的光学畸变(因为BN训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助)。在使用了这些措施后,Inception V2在训练达到 Inception V1的准确率时快了14倍,并且模型在收敛时的准确率上限更高。
5.1,卷积分解(Factorizing Convolutions)
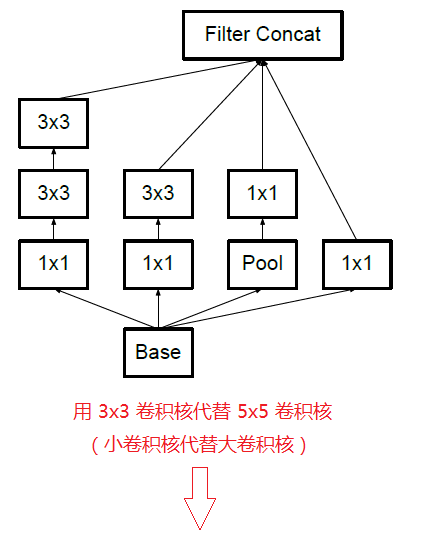
卷积核大,计算量也是平方的增大。大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5x5卷积核的参数有25个,3x3卷积核的参数有9个,前者是后者的25/9=2.78倍。因此,GoogLeNet团队提出可以用2个连续的3x3卷积层组成的小网络来代替单个的5x5卷积层,即在保持感受野范围的同时又减少了参数量,虽然5*5的卷积可以捕捉到更多的临近关联信息,但是两个3*3组合起来,能观察到的“视野” 就和 5*5 的一样了,如下图:
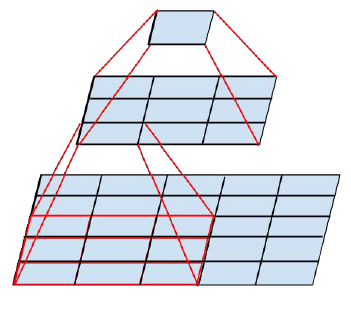
那么这种替代方案会造成表达能力的下降吗?通过大量的实验表明,并不会造成表达缺失。
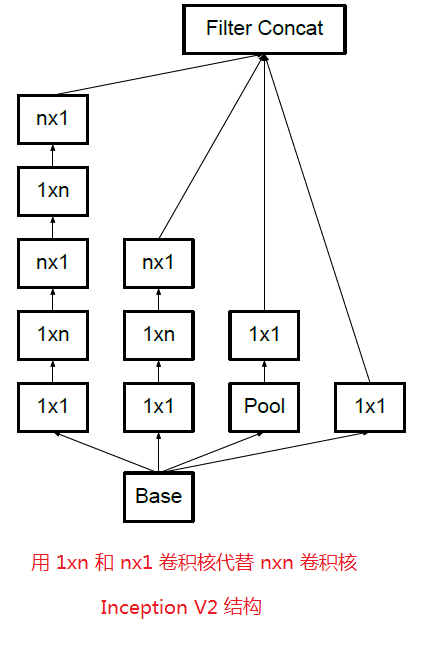
可以看出,大卷积核完全可以由一系列的3*3 卷积核来替代,那能不能再分解得更小一些呢?GoogLeNet团队考虑了 n*1 的卷积核,其实,对于分解的卷积层,实验表明非线性激活比线性激活更好,所以,以上的卷积分解还不是最优策略,3*3卷积还可以进一步分解成1*3 和 3*1 ,两个卷积分别捕捉不同方向的而信息,参数只有之前的6/9。其实,这个可以推广到 n*n 卷积的情况,n*n 卷积因式分解为 1*n 和 n*1。这个方法在网络前面部分似乎表现欠佳,但在中间层起到很好的效果。
上述结果表明,大于3*3的卷积滤波器可能不是通常有用的,因为他们总是可以简化为3*3卷积层序列。我们仍然可以问这个问题,是否应该把他们分解成更小的,例如2*2的卷积。然而,通过使用非对称卷积,可以做出甚至比2*2更好的效果,即 n*1。例如使用3*1卷积后接一个1*3卷积,相当于以与3*3卷积相同的感受野滑动两层网络(如下图)。如果输入和输出老滤波器的数量相等,那么对于相同数量的输出滤波器,两层解决方案便宜33%。相比之下,将3*3卷积分解为两个2*2卷积表示仅节省了11%的计算量。
如下图所示,用 3个 3*1 取代 3*3 卷积:

在理论上,我们可以进一步论证,可以通过1*n 卷积和后面接一个 n*1 卷积替换任何 n*n 卷积,并且随着 n 增长,计算成本节省显著增加(如下图所示)。实际上,GoogLeNet团队发现在网络的前期试验这种分解效果并不好,但是对于中等网格尺寸(在 m*m 特征图上,其中 m 范围在12 到20之间),其给出了非常好的结果。在这个水平上,通过使用 1*7 卷积,然后是 7*1 卷积可以获得非常好的结果。

5.2,降低特征图尺寸
假设有一个 d*d*k 的特征图,为了转换成 d/2 * d/2 *2k 大小,可以先用 1*1 卷积变成 d*d*2k,再进行池化,这样的计算量很大,而先池化再增加通道则会出现 representational bottlenecks 的问题。
传统上,卷积网络使用一些池化操作来缩减特种图的网络大小。为了避免表示瓶颈,在应用最大池化或平均池化之前,需要扩展网络滤波器的激活维度。例如,开始需要一个带有K个滤波器的 d*d 网络,如果我们想要达到一个带有 2k 个滤波器的 d/2 * d/2 网格,我们首先需要用 2k 个滤波器计算步长为1的卷积,然后应用一个额外的池化步骤。这意味着总体计算成本由在较大的网格上使用 2d2k2 次运算的昂贵卷积支配。一种可能性是转换为带有卷积的池化,因此导致 2(d/2)2k2 次运算,将计算成本降低为原来的四分之一。然而,由于表示的整体维度下降到 (d/2)2k ,会导致表示能力较弱的网格(如下图所示)。这会产生一个表示瓶颈。我们建议另一种变体,其甚至进一步降低了计算成本,同时消除了表示瓶颈(下下图所示),而不是这样做。我们可以使用两个平行的步长为2的块:P和C。P是一个池化层(平均池化或最大池化)的激活,两者都是步长为2。
一般情况下,如果想让图像缩小,可以有如下两种方式:
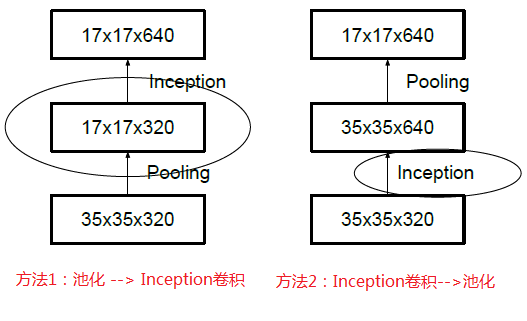
先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大(右边的计算量昂贵3倍)。为了同时保持特征表示且降低计算量,将网络结构改为下图,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)。
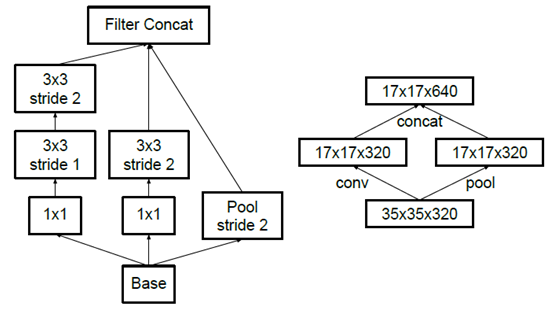
使用 Inception V2作改进版的 GoogLeNet,网络结构如下:

注意:上表中的 Figure 5 指的时没有进化的 Inception ,Figure 6 指的时小卷积版的 Inception (用 3*3 卷积核代替 5*5 卷积核),Figure 7 是指不对称版的 Inception(用1*n, n*1 卷积核代替 n*n 卷积核)。把7*7卷积替换为3个3*3卷积。包含3个inception部分。第一部分为35*35*288,使用了2个3*3 卷积代替了传统的 5*5 ;第二部分减少了 feature map,增多了 filters,为17*17*768,使用了 n*1 ---> 1*n 结构,第三部分多了 filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogleNet 的2.5 倍。
经试验,模型结果与旧的 GoogLeNet 相比有较大的提升,如下表所示:
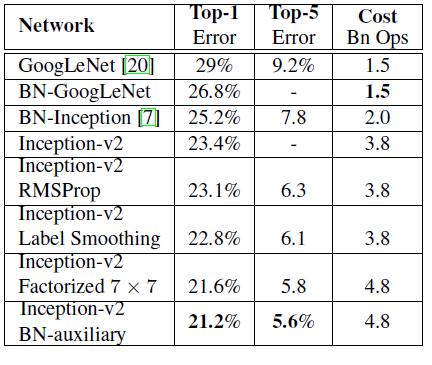
6,Inception V3
Inception V3 网络则主要有两方面的改造:一是引入了分解( Factorization into small convilutions )的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将 7*7 卷积拆成 1*7 卷积和 7*1卷积,或者将 3*3 卷积拆成 1*3 卷积和 3*3 卷积,如下图所示,一方面节省了大量参数,加速运算并减轻了过拟合(比将7*7 卷积拆成1*7 卷积和 7*1 卷积,比拆成3个3*3 卷积更节省参数),同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称的拆为几个相同的晓娟及核下过更明显,可以处理更多,更丰富的空间特征,增加特征多样性。
另一方面,Inception V3优化了Inception Module的结构,现在 Inception Module有 35*35,17*17和8*8三种不同的结构,如下图所示,这些 Inception Module只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3除了在Inception Module中使用分支,还在分支中使用了分支(8*8 的结构中),可以说是 Network In Network In Network,网络输入从224x224变为了299x299。
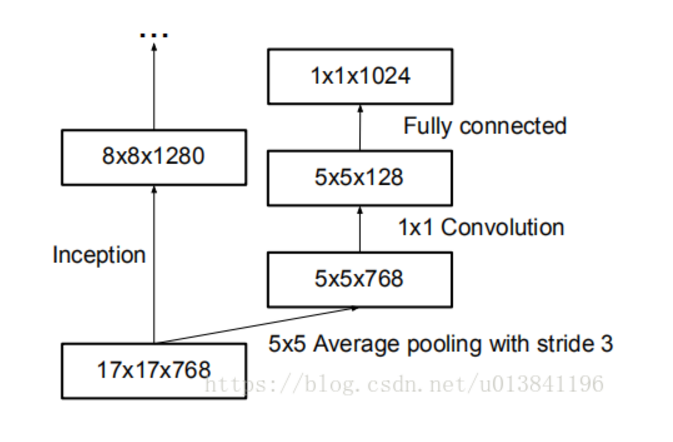
分析:因此问题依然存在:如果计算量保持不变,更高的输入分辨率会有多少帮助?
普遍的看法是,使用更高分辨率感受野的模型倾向于导致显著改进的识别性能。
为了这个目的我们进行了以下三个实验:
- 1)步长为2,大小为299×299的感受野和最大池化。
- 2)步长为1,大小为151×151的感受野和最大池化。
- 3)步长为1,大小为79×79的感受野和第一层之后没有池化。
所有三个网络具有几乎相同的计算成本。虽然第三个网络稍微便宜一些,但是池化层的成本是无足轻重的(在总成本的1%以内)。在每种情况下,网络都进行了训练,直到收敛,并在ImageNet ILSVRC 2012分类基准数据集的验证集上衡量其质量。结果如表所示。虽然分辨率较低的网络需要更长时间去训练,但最终结果却与较高分辨率网络的质量相当接近。

当感受野尺寸变化时,识别性能的比较,但计算代价是不变的。但是,如果只是单纯地按照输入分辨率减少网络尺寸,那么网络的性能就会差得多。
总结:
Inception V3网络主要有两方面的改造:一是引入了Factorization into small convolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将77卷积拆成17卷积和71卷积,或者将33卷积拆成13卷积核31卷积。一方面节约了大量参数,加快运算并减轻过拟合,同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆分为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
另一方面,Inception V3优化了Inception Module的结构,现在Inception Module有35*35、17*17和8*8三种不同结构。这些Inception Module只在网络的后部出现,前面还是普通的卷积层。并且Inception V3除了在Inception Module中使用分支,还在分支中使用了分支(8*8的结构中,可以说是Network In Network 。
7,Inception V4
Inception V4研究了Inception模块与残差连接的结合。ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。
Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。
ResNet的残差结构如下:
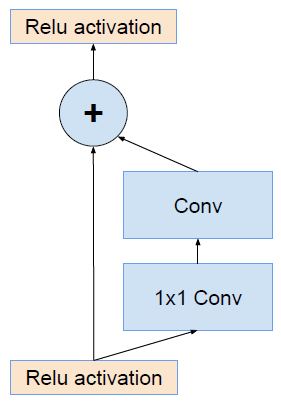
将该结构与 Inception 相结合(即Inception V3结合了微软的ResNet),变为下图:
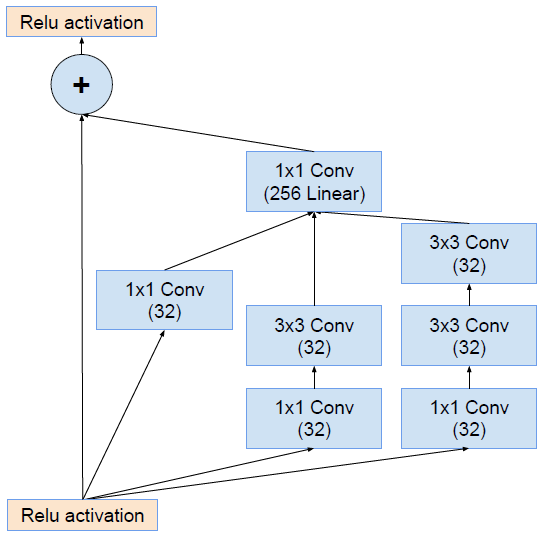
通过20个类似的模块组合,Inception-ResNet 构建如下:
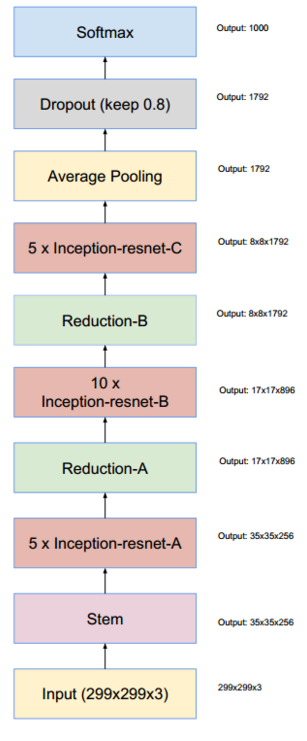
8,TensorFlow实现Inception V3
本文主要实现的是 Inception V3,其整个网络结果如图所示。由于 Google Inception Net V3 相对比较复杂,所以这里使用 tf.contrib.slim辅助设计这个网络。contrib.slim 中一些功能和组件可以大大减少设计 Inception Net 的代码量,我们只需要使用少量代码就可以构建好 有 42层深的 Inception V3。


首先定义一个简单的函数 trunc_normal,产生截断的正态分布。下面代码主要来自TensorFlow的开源实现。
#_*_coding:utf-8_*_ import tensorflow as tf slim = tf.contrib.slim trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev)
下面定义函数 inception_v3_arg_scope,用来生成网络中经常用到的函数的默认参数,比如卷积的激活函数,权重初始化方式,标准化器等。设置L2正则的 weight_decay 默认值为0.00004,标准差 stddev 默认值为 0.1,参数 batch_norm_var_collection 默认值为 moving_vars。接下来,定义 batch normalization 的参数字典,定义其衰减稀疏 decay 为 0.9997,epsilon 为 0.001,updates_collections 为 tf.GrpahKeys.UPDATE_OPS,然后字典 varibales_collections 中 beta 和 gamma 均设置为 None,moving_mean和 moving_variance 均设置为前面的 batch_norm_var_collection。
接下来使用 slim.arg_scope,这是一个非常有用的工具,它可以给函数的参数自动赋予某些默认值。例如,这句 with slim.arg_scope([slim.conv2d, slim.fully_connected],weights_regularizer = slim.l2_regularizer(weight_decay)),会对 [slim.conv2d, slim.fully_connected] 这两个函数的参数自动赋值,将参数 weights_regularizer的值默认设为 slim.l2_regularizer(weight_decay)。使用了 slim.arg_scope 后就不需要每次都重复设置参数了,只需要在有修改时设置。接下来,嵌套一个 slim.arg_scope,对卷积层生成函数 slim.conv2d 的几个参数 赋予默认值,其权重初始化器 weights_initializer 设置为 trunc_normal(stddev),激活函数设置为 ReLU,标准化器设置为 slim.batch_norm,标准化器的参数设置为前面定义的 batch_norm_params。最后返回定义好的 scope。
因为事先定义好了 slim.conv2d中的各种默认参数,包括激活函数和标准化器,因此后面定义一个卷积层将会变得非常方便。我们可以用一行代码定义一个卷积层,整体代码会变得非常简洁美观,同时设计网络的工作量也会大大减轻。
#_*_coding:utf-8_*_
import tensorflow as tf
slim = tf.contrib.slim
trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev)
def inception_v3_arg_scope(weight_decay=0.00004, stddev=0.1,
batch_norm_var_collection='moving_vars'):
batch_norm_params = {
'decay': 0.9997,
'epsilon': 0.001,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
'variables_collections': {
'beta': None,
'gamma': None,
'moving_mean': [batch_norm_var_collection],
'moving_variance': [batch_norm_var_collection],
}
}
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope(
[slim.conv2d],
weights_initializer=tf.truncated_normal_initializer(stddev=stddev),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params
) as sc:
return sc
接下来我们就定义函数 inception_v3_base,它可以生成 Inception V3 网络的卷积部分,参数 Inputs 为输入的图片数据的 tensor,scope为包含了函数默认参数的环境。我们定义一个字典表 end_points,用来保存某些关键节点供以后使用。接着再使用 slim.arg_scope,对 slim,conv2d, slim.max_pool2d 和 slim_avg_pool2d 这三个函数的参数设置默认值,将 stride 设为1 ,padding 设为 VALID。下面正式开始定义 Inception V3的网络结构,首先是前面的非 Inception Module的卷积层。这里直接使用 slim.conv2d创建卷积层,slim.conv2d的第一个参数为输入的 tensor,第二个参数为输出的通道数,第三个参数为卷积核尺寸,第四个参数为步长 stride,第五个参数为padding模式。我们的第一个卷积层的输出通道数为32,卷积核尺寸为3*3,步长为2,padding模式则是默认的VALID。后面的几个卷积层采用相同的形式,按照论文中的定义,逐层定义好网络结构。因为使用了 slim 及 slim.arg_scope,我们一行代码就可以定义好的一个卷积层,相比之前 AlexNet的实现中使用好几行代码定义一个卷积层,或者 VGGNet 中专门写一个函数来定义卷积层,都更加方便。
我们可以观察到,在前面几个普通的非 Inception Module 的卷积层中,主要使用了 3*3 的小卷积核,这是充分借鉴了 VGGNet 的结构,同时,Inception V3论文中也提出了 Factorization into small convolutions 思想,利用两个1维卷积模拟大尺寸的2维卷积,减少参数数量同时增加非线性。前面几层卷积中还有一层1*1卷积,这也是前面提到的Inception Module 中经常使用的结果之一,可低成本的跨通道的对特征进行组合。另外可以看到,除了第一个卷积层步长为2,其余的卷积层步长均为1,而池化层则是尺寸为3*3,步长为2的重叠最大池化,这是AlexNet中使用过的结构。网络的输入数据尺寸为 299*299*3,在经历3个步长为2的层之后,尺寸最后缩小为 35*35*192,空间尺寸大大降低,但是输出通道增加了很多。这部分代码中一共有 5个卷积层,2个池化层,实现了对输入图片数据的尺寸压缩,并对图片特征进行了抽象。
def inception_v3_base(inputs, scope=None):
end_points = {}
with tf.variable_scope(scope, 'InceptionV3', [inputs]):
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='VALID'):
# 一共5个卷积层,两个池化层,实现了对输入图片数据的尺寸压缩,并对图片特征进行了抽象
net = slim.conv2d(inputs, 32, [3, 3], stride=2, scope='Conv2d_1a_3x3')
net = slim.conv2d(net, 32, [3, 3], scope='Conv2d_2a_3x3')
net = slim.conv2d(net, 64, [3, 3], padding='SAME', scope='Conv2d_2b_3x3')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_3a_3x3')
net = slim.conv2d(net, 80, [1, 1], scope='Conv2d_3b_1x1')
net = slim.conv2d(net, 192, [3, 3], scope='conv2d_4a_3x3')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_5a_3x3')
接下来就是将三个连续的 Inception模块组,这三个 Inception 模块组中各自分别由多个 Inception Module,这部分的网络结构即是Inception V3 的精华所在。每个Inception模块组内部的几个Inception Module 结构非常类似,但是存在一些细节不同。
第1个Inception 模块组包含了3个结构类似的 Inception Module,他们的结构和上面分解的第一幅图非常相似。其中第一个 Inception Module的名称为Mixed_5d。我们先使用 slim.arg_scope 设置所有 Inception 模块组的默认参数,将所有卷积层,最大池化,平均池化层的步长设为1,padding 模式设为SAME。然后设置这个 Inception Module的 variable_scope 名称为 Mixed_5d。这个Inception Module中有4个分支,从 Branch_0 到Branch_3,第一个分支为有64输出通道的1*1卷积;第二个分支为有48输出通道的1*1卷积,连接有64输出通道的5*5卷积;第三个分支为有64输出通道的1*1卷积,再连续2个有96输出通道的 3*3 卷积;第四个分支为3*3 的平均池化,连接有32 输出通道的1*1 卷积。最后,使用 tf.concat 将4个分支的输出合并在一起(在第3个维度合并,即输出通道上合并),生成这个Inception Module 的最终输出。因为这里所有的层步长均为1,并且 padding模式为SAME,所以图片的尺寸并不会缩小,依然维持在 35*35。不过通道数增加了,4个分支的输出通道数之和 64+64+96+32=256,即最终输出的tensor尺寸为35*35*256.这里需要注意,第一个 Inception模块组中所有 Inception Module输出的图片尺寸均为35*35,但是后两个 Inception Module 的通道数会发生变化。
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope('Mixed_5b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch2 = slim.conv2d(branch_2, 96, [3, 3], scope='COnv2d_0b_1x1')
branch2 = slim.conv2d(branch_2, 96, [3, 3], scope='COnv2d_0c_1x1')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
接下来是第一个Inception模块组的第2个 Inception Module——Mixed_5c,这里依然使用前面设置的默认参数:步长为1,padding模式为SAME。这个Inception Module同样有4个分支,唯一不同的是第4个分支最后接的是64输出通道的1*1卷积,而此前是32输出通道。因此,我们输出 tensor 的最终尺寸为35*35*288,输出通道数相比之前增加了32。
with tf.variable_scope('Mixed_5c'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0b_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv_1_0c_5x5')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branhc_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
而第一个 Inception 模块组的第3个Inception Module——Mixed_5d 和上一个 Inception Module完全相同,4个分支的结构,参数一模一样,输出 tensor 的尺寸也为 35*35*288。
with tf.variable_scope('Mixed_5d'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
第二个 Inception 模块组是一个非常大的模块组,包含了5个 Inception Module,其中第二个到第五个Inception Module的结构非常类似,他们的结构如因式分解图第二幅所示。其中第一个Inception Module名称为Mixed_6a ,它包含3个分支。第一个分支是一个384输出通道的3*3卷积,这个分支的通道数一下就超过了之前的通道数之和。不过步长为2,因此图片尺寸将会被压缩,且padding模式为VALID,所以图片尺寸缩小为17*17;第二个分支有三层,分布是一个64输出通道的1*1卷积和两个96输出通道的3*3 卷积。这里需注意,最后一层的步长为2,padding模式为 VALID,因此图片尺寸也被压缩,本分支最终输出的 tensor尺寸为17*17*96。最后依然是使用 tf.concat 将三个分支在输出通道上合并,最后的输出尺寸为 17*17*(384+96+256)=17*17*768。在第二个 Inception 模块组中,5个Inception Module输出tensor的尺寸将全部定格为 17*17*768,即图片尺寸和输出通道数都没有发生变化。
with tf.variable_scope('Mixed_6a'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 384, [3, 3], strides=2,
padding='VALID', scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_1a_3x3')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 64, [3, 3], strides=2,
padding='VALID', scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3)
接下来是第2个Inception模块组的第二个 Inception Module——Mixed_6b,它有4个分支。第一个分支是一个简单的192输出通道的1*1卷积;第二个分支由三个卷积层组成,第一层是128输出通道的1*1 卷积,第二层是128通道数的1*7卷积,第三次是192输出通道数的7*1卷积。这里既是前面提到的Factorization into small convolutions 思想,串联的1*7 卷积和 7*1 卷积相当于合成了一个7*7 卷积,不过参数量大大减少了(只有后者的2/7)并减轻了过拟合,同时多了一个激活函数增强了非线性特征变换;第3个分支一下子拥有了5个卷积层,分别是128输出通道的1*1卷积,128输出通道的7*1卷积,128输出通道的1*7卷积,128输出通道的7*1卷积和192输出通达的1*7卷积。这个分支可以算是利用 Factorization into small convolutions 的典范,反复的将7*7卷积进行拆分;最后,第四个分支是一个3*3的平均池化层,再连接192输出通道的1*1卷积。最后将4个分支合并,这一层输出 tensor 的尺寸即为 17*17*(192+192+192+192)=17*17*768。
with tf.variable_scope('Mixed_6b'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 128, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
然后是我们第二个Inception模块组的第三个Inception Module——Mixed_6c。Mixed_6c和前面一个Inception Module非常相似,只有一个地方不同,即第二个分支和第三个分支中前几个卷积层的输出通道数不同,从128变成了160,但是这两个分支的最终输出通道数不变,都是192。其他地方则完全一致。需要注意的是,我们的网络每经过一个Inception Module ,即使输出 tensor尺寸不变,但是特征都相当于被重新精炼了一遍,其中丰富的卷积和非线性化对提升网络性能帮助很大。
with tf.variable_scope('Mixed_6c'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
Mixed_6d 和前面的 Mixed_6c 完全一致,目的是通过Inception Module 精心设计的结构增加卷积和非线性,提炼特征。
with tf.variable_scope('Mixed_6d'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
Mixed_6e 也和前面两个 Inception Module完全一致。这是第二个Inception 模块组的最后一个Inception Module。我们将 Mixed_6e 存储于 end_points中,作为 Auxiliary Classifier 辅助模型的分类。
with tf.variable_scope('Mixed_6e'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
end_points['Mixed_6e'] = net
第3个 Inception 模块组包含了三个 Inception Module,其中后两个 Inception Module的结构非常类似,他们的结构如因式分解的第三幅图所示。其中第一个Inception Module的名称为 Mixed_7a,包含了3个分支。第一个分支是192输出通道的1*1 卷积,再接320输出通道数的3*3卷积,不过步长为2,padding模式为VALID,因此图片尺寸缩小为8*8;第二个分支有4个卷积层,分别是192 输出通道的1*1卷积,192输出通道的1*7卷积,192输出通道的7*1卷积,以及192输出通道的3*3 卷积。注意最后一个卷积层同样步长为2,padding为 VALID,因此最后输出的tensor尺寸为 8*8*192;第三个分支则是一个3*3 的最大池化层,步长为2,padding为VALID,而池化层不会对输出通道产生改变,因此这个分支的输出尺寸为 8*8*768。最后,我们将3个分支在输出通道上合并,输出tensor尺寸为 8*8*(320+192+768)=8*8*1280。从这个Inception Module开始,输出的图片尺寸又被缩小了,同时通道数也增加了,tensor的总size在持续下降中。
with tf.variable_scope('Mixed_7a'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_0 = slim.conv2d(net, 320, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope("Branch_2"):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2,
padding='VALID', scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
接下来是第三个Inception 模块组的第二个Inception Module,它有四个分支。第一个分支是一个简单的320输出通道和1*1卷积;第二个分支先是1个384输出通道的1*1卷积,随后在分支内开了两个分支,这两个分支分别是 384输出通道的 3*1 卷积,然后使用 tf.concat 合并两个分支,得到的输出 tensor尺寸为 8*8*(384+384)=8*8*768;第三个分支更复杂,先是 448输出通道的1*1卷积,然后是 384输出通道的 3*3 卷积,然后同样在分支内拆成两个分支,分别是384输出通道的 1*3 卷积和 384输出通道的 3*1 卷积,最后合并得到 8*8*768 的输出tensor;第四个分支是在一个 3*3 卷积,然后同样在分支内拆成两个分支,分别是 384输出通道的 1*3 卷积和 384输出通道的 3*1卷积,最后合并德达 8*8*768的输出tensor;第四个分支是在一个 3*3 的平均池化层后接一个 192 输出通道的 1*1 卷积。最后,将这个非常复杂的 Inception Module 的四个分支合并在一起,得到的输出tensor 尺寸为 8*8*(320+768+78+192)=8*8*2048。到这个Inception Module,输出通道数从 1280 增加到 2048。
with tf.variable_scope('Mixed_7b'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0c_3x1')
], 3)
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='COnv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 384, [3, 3],
scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')
], 3)
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='COnv2d_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1],
scope='Conv2d_0b_1x3')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
Mixed_7c 是第三个 Inception 模块组的最后一个 Inception Module,不过他们和前面的 Mixed_7b 是完全一致的,输出 tensor 也是8*8*2048。最后,我们返回这个Inception Module的结果,作为 inception_v3_base 函数的最终输出。
with tf.variable_scope('Mixed_7c'):
with tf.variable_scope("Branch_0"):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope("Branch_1"):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0c_3x1')
], 3)
with tf.variable_scope("Branch_2"):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='COnv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 384, [3, 3],
scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')
], 3)
with tf.variable_scope("Branch_3"):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1],
scope='Conv2d_0b_1x3')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
return net, end_points
至此,Inception V3 网络的核心部分,即卷积层部分就完成了。回忆一下 Inception V3的网络结构:首先是五个卷积层和两个池化层交替的普通结构,然后是三个Inception 模块组,每个模块组内包含多个结构类似的 Inception Module。设计 Inception Net的一个重要原则是,图片尺寸是不断缩小的,从299*299 通过五个步长为2的卷积层或池化层后,缩小为8*8,同时,输出通道数持续增加,从一开始的3(RGB的三色)到 2048.从这里可以看出,每一层卷积,池化或 Inception模块组的目的都是将空间结构简化,同时将空间信息转化为高阶抽象的特征信息,即将空间的维度转化为通道的维度。这一过程同时也使每层输出 tensor的总size持续下降,降低了计算量。我们可能也发现了 Inception Module的规律,一般情况下有四个分支,第一个分支一般是1*1卷积,第二个分支一般是1*1卷积再接分解后(factorized)的1 x n 和 n x 1卷积,第三个分支和第二个分支类似,但是一般更深一点,第四个分支一般具有最大池化或平均池化。因此,Inception Module是通过组合比较简单的特征抽象(分支1),比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4),一共四种不同程度的特征抽象和变换来选择地保留不同层次的高阶特征,这样可以最大程度地丰富网络的表达能力。
接下来,我们来实现 Inception V3 网络的最后一部分——全局平均池化,Softmax和 Auxiliary Logits。先看函数 Inception V3 的输入参数,num_classes 即最后需要分类的数据量,这里默认的1000是ILSVRC比赛数据集的种类数;is_training 标志是否是训练过程,对Batch Normalization 和 Dropout 有影响,只有在训练时Batch Normalization 和 Dropout 才会被启用;dropout_keep_prob 即训练时 Dropout所需保留节点的比例,默认为 0.8;predicetion_fn 是最后用来进行分类的函数,这里默认是使用 slim.softmax;spatial_squeeze 参数标志是否对输出进行 squeeze 操作(即去除维数为1的维度,比如 5*3*1转为 5*3);reuse标志是否会对网络和Variable 进行重复使用;最后,scope为包含了函数默认参数的环境。首先,使用 tf.variable_scope 定义网络的 name 和 reuse 等参数的默认值,然后使用 slim.arg_scope定义 Batch Normalization 和 Dropout 的 is_training 标志的默认值。最后,使用前面定义好的 inception_v3_base 构筑整个网络的卷积部分,拿到最后一层的输出net和重要节点的字典表 end_points。
def inception_v3(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.8,
prediction_fn=slim.softmax,
spatial_squeeze=True,
reuse=None,
scope='InceptionV3'):
with tf.variable_scope(scope, 'InceptionV3', [inputs, num_classes],
reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = inception_v3_base(inputs, scope=scope)
接下来处理 Auxiliary Logits 这部分的逻辑, Auxiliary Logits 作为辅助分类的节点,对分类结果预测有很大帮助,先使用 slim.arg_scope将卷积,最大池化,平均池化的默认步长设为1,默认padding模式设为 SAME 。然后通过 end_points 取到 Mixed_6e,并在Mixed_6e之后再接一个5*5 的平均池化,步长为3,padding设为 VALID,这样输出的尺寸就从 17*17*768 变为 5*5*768。接着连接一个 128输出通道的1*1 卷积和一个 768输出通道的 5*5卷积,这里权重初始化方式重设为标准差为 0.01的正态分布,padding模式设为 VALID,输出尺寸为 1*1*768。然后再连接一个输出通道数为 num_classes的 1*1 卷积,不设激活函数和规范化函数,权重初始化重设为标准差为 0.001的正态分布,这样输出变为了1*1*1000。接下来,使用 tf.squeeze函数消除输出 tensor 中前两个为1 的维度,最后将辅助分类节点的输出 aux_logits储存到字典表 end_points中。
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
aux_logits = end_points['Mixed_6e']
with tf.variable_scope('AuxLogits'):
aux_logits = slim.avg_pool2d(
aux_logits, [5, 5], stride=3, padding='VALID',
scope='AvfPool_1a_5x5'
)
aux_logits = slim.conv2d(aux_logits, 128, [1, 1],
scope='COnv2d_1b_1x1')
aux_logits = slim.conv2d(
aux_logits, 768, [5, 5],
weights_initializer=trunc_normal(0.01),
padding='VALID', scope='COnv2d_2a_5x5'
)
aux_logits = slim.conv2d(
aux_logits, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, weights_initializer=trunc_normal(0.001),
scope='Conv2d_2b_1x1'
)
if spatial_squeeze:
aux_logits = tf.squeeze(aux_logits, [1, 2],
name='SpatialSqueeze')
end_points['AuxLogits'] = aux_logits
下面处理正常的分类预测的逻辑。我们直接对Mixed_7e即最后一个卷积层的输出进行一个8*8全局平均池化,padding模式为 VALID,这样输出 tensor的尺寸就变为了 1*1*2048。然后连接一个 Dropout层,节点保留率为 dropout_keep_prob。接着连接一个输出通道数为 1000 的1*1 卷积,激活函数和规范化函数设为空。下面使用 tf.squeeze去除输出 tensor中维度为1的维度。再连接一个Softmax对结果进行分类预测。最后返回输出结果Logits和包含辅助节点的 end_points。
with tf.variable_scope('Logits'):
net = slim.avg_pool2d(net, [8, 8], padding='VALID',
scope='AvgPool_1a_8x8')
net = slim.dropout(net, keep_prob=dropout_keep_prob,
scope='Dropout_1b')
end_points['PreLogits'] = net
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='Conv2d_1c_1x1')
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
至此,整个Inception V3网络的构建就完成了。Inception V3是一个非常复杂,精妙的模型,其中用到了非常多值钱积累下来的设计大型卷积网络的经验和技巧。不过,虽然Inception V3论文中给出了设计卷积网络的几个原则,但是其中很多超参数的选择,包含层数,卷积核的尺寸,池化的位置,步长的大小,Factorization使用的时机,以及分支的设计,都很难一一解释。目前,我们只能认为深度学习,尤其是大型卷积网络的设计,是一门实验学科,其中需要大量的探索和实践。我们很难正面某种网络结构一定更好,更多的是通过实验积累下来的经验总结出一些结论。深度学习的研究中,理论正面部分依然是短板,但是通过实验得到的结论通常也具有不错的推广性,在其他数据集上泛化性良好。
下面对 Inception v3进行运算性能测试,这里使用的 time_tensorflow_run 函数和 ALexNet一样,这里直接写代码,不重复说明了。因为Inception V3网络结构较大,所以依然令 batch_size 为32,以便GPU显存不够,图片尺寸设为 299*299,并用 tf.random_uniform 生成随机图片数据作为Input。接着,我们使用 slim.arg_sope 加载前面定义好的 inception_v3_arg_scope() ,在这个scope中包含了 Batch Normalization 的默认参数,以及激活函数和参数初始化方式的默认值。然后在这个 arg_scope 下,调用 inception_v3函数,并传入 Inputs,获取logits 和 end_points。下面创建Session并初始化全部模型参数,最后我们设置测试的 batch数量为100,并使用 time_tensorflow_run 测试 Inception V3网络的 forward 性能。
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0 # 记录总时间
total_duration_squared = 0.0 # 记录平方和total_duration_squared用于计算方差
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: stpe %d, duration=%.3f'%(datetime.now(),
i-num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn*mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch'%(datetime.now(),
info_string, num_batches, mn, sd))
代码2:
if __name__ == '__main__':
batch_size = 32
height, width = 299, 299
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(inception_v3_arg_scope()):
logits, end_points = inception_v3(inputs, is_training=False)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, logits, 'Forward')
从结果来看,Inception V3 网络的 forward性能不错,在GPU的环境下,每个batch(包含32张图片)预测耗时仅为0.071s。虽然输入图片的面积比 VGGNet的 224*224大了 78%,但是 forward速度却比 VGGNet的0.072s更快。这主要归功于其较小的参数量,Inception V3网络仅有 2500 万个参数,虽然比 Inception V1的700万多了很多,不过任然不到 AlexNet 的6000万参数量的一半,相比于 VGGNet的 1.4亿参数量就更少了,这对一个42层深的大型网络来说极为不易的。同时,整个网络的浮点计算量仅为50亿次,虽也比 Inception V1的15亿次大了不少,但是相比 VGGNet仍然不算大。较小的计算量让 Inception V3网络变得非常实用,我们可以将其轻松的移到普通的服务器上提供快速响应的服务,甚至是移植到收集上进行实时的图像识别。
2019-09-16 09:47:11.291271: step 0, duration=0.072 2019-09-16 09:47:12.007825: step 10, duration=0.072 2019-09-16 09:47:12.723585: step 20, duration=0.072 2019-09-16 09:47:13.437683: step 30, duration=0.071 2019-09-16 09:47:14.151189: step 40, duration=0.071 2019-09-16 09:47:14.864866: step 50, duration=0.071 2019-09-16 09:47:15.579139: step 60, duration=0.071 2019-09-16 09:47:16.291750: step 70, duration=0.071 2019-09-16 09:47:17.005981: step 80, duration=0.071 2019-09-16 09:47:17.721084: step 90, duration=0.071 2019-09-16 09:47:18.362285: Forward across 100 steps, 0.007 +/- 0.021 sec / batch
Inception V3作为一个极深的卷积神经网络,拥有非常精妙的设计和构造,整个网络的结构和分支非常复杂,我们平时可能不必设计这么复杂的网络的,但是Inception V3中让然有许多CNN的思想和 Trick值得借鉴。
(1) Factorization into small convolutions 很有效,可以降低参数量,减轻过拟合,增加网络非线性的表达能力。
(2)卷积网络从输入到输出,应该让图片尺寸逐渐减少,输出通道数逐渐增加,即让空间结构简化,将空间信息转化为高阶抽象的特征信息。
(3)Inception Module用多个分支提取不同抽象程度的高阶特征的思路很有效,可以丰富网络的表达能力。
完整代码如下:
import tensorflow as tf
slim = tf.contrib.slim
trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev)
def inception_v3_base(inputs, scope=None):
end_points = {}
with tf.variable_scope(scope, 'InceptionV3', [inputs]):
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='VALID'):
# 299 x 299 x 3
net = slim.conv2d(inputs, 32, [3, 3], stride=2, scope='Conv2d_1a_3x3')
# 149 x 149 x 32
net = slim.conv2d(net, 32, [3, 3], scope='Conv2d_2a_3x3')
# 147 x 147 x 32
net = slim.conv2d(net, 64, [3, 3], padding='SAME', scope='Conv2d_2b_3x3')
# 147 x 147 x 64
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_3a_3x3')
# 73 x 73 x 64
net = slim.conv2d(net, 80, [1, 1], scope='Conv2d_3b_1x1')
# 73 x 73 x 80.
net = slim.conv2d(net, 192, [3, 3], scope='Conv2d_4a_3x3')
# 71 x 71 x 192.
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_5a_3x3')
# 35 x 35 x 192.
# Inception blocks
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
# mixed: 35 x 35 x 256.
with tf.variable_scope('Mixed_5b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_1: 35 x 35 x 288.
with tf.variable_scope('Mixed_5c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0b_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv_1_0c_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_2: 35 x 35 x 288.
with tf.variable_scope('Mixed_5d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_3: 17 x 17 x 768.
with tf.variable_scope('Mixed_6a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 384, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_1x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3)
# mixed4: 17 x 17 x 768.
with tf.variable_scope('Mixed_6b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 128, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_5: 17 x 17 x 768.
with tf.variable_scope('Mixed_6c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_6: 17 x 17 x 768.
with tf.variable_scope('Mixed_6d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_7: 17 x 17 x 768.
with tf.variable_scope('Mixed_6e'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
end_points['Mixed_6e'] = net
# mixed_8: 8 x 8 x 1280.
with tf.variable_scope('Mixed_7a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_0 = slim.conv2d(branch_0, 320, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
branch_1 = slim.conv2d(branch_1, 192, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3)
# mixed_9: 8 x 8 x 2048.
with tf.variable_scope('Mixed_7b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0b_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_10: 8 x 8 x 2048.
with tf.variable_scope('Mixed_7c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0c_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
return net, end_points
def inception_v3(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.8,
prediction_fn=slim.softmax,
spatial_squeeze=True,
reuse=None,
scope='InceptionV3'):
with tf.variable_scope(scope, 'InceptionV3', [inputs, num_classes],
reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = inception_v3_base(inputs, scope=scope)
# Auxiliary Head logits
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
aux_logits = end_points['Mixed_6e']
with tf.variable_scope('AuxLogits'):
aux_logits = slim.avg_pool2d(
aux_logits, [5, 5], stride=3, padding='VALID',
scope='AvgPool_1a_5x5')
aux_logits = slim.conv2d(aux_logits, 128, [1, 1],
scope='Conv2d_1b_1x1')
# Shape of feature map before the final layer.
aux_logits = slim.conv2d(
aux_logits, 768, [5, 5],
weights_initializer=trunc_normal(0.01),
padding='VALID', scope='Conv2d_2a_5x5')
aux_logits = slim.conv2d(
aux_logits, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, weights_initializer=trunc_normal(0.001),
scope='Conv2d_2b_1x1')
if spatial_squeeze:
aux_logits = tf.squeeze(aux_logits, [1, 2], name='SpatialSqueeze')
end_points['AuxLogits'] = aux_logits
# Final pooling and prediction
with tf.variable_scope('Logits'):
net = slim.avg_pool2d(net, [8, 8], padding='VALID',
scope='AvgPool_1a_8x8')
# 1 x 1 x 2048
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')
end_points['PreLogits'] = net
# 2048
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='Conv2d_1c_1x1')
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
# 1000
end_points['Logits'] = logits
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
def inception_v3_arg_scope(weight_decay=0.00004,
stddev=0.1,
batch_norm_var_collection='moving_vars'):
batch_norm_params = {
'decay': 0.9997,
'epsilon': 0.001,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
'variables_collections': {
'beta': None,
'gamma': None,
'moving_mean': [batch_norm_var_collection],
'moving_variance': [batch_norm_var_collection],
}
}
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope(
[slim.conv2d],
weights_initializer=trunc_normal(stddev),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params) as sc:
return sc
from datetime import datetime
import math
import time
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
if __name__ == '__main__':
batch_size = 32
height, width = 299, 299
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(inception_v3_arg_scope()):
logits, end_points = inception_v3(inputs, is_training=False)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, logits, "Forward")
本文是学习GoogLeNet网络的笔记,参考了《tensorflow实战》这本书中关于GoogLeNet的章节,写的非常好,所以在此做了笔记,侵删。
而且本文在学习中,摘抄了下面博客的GoogLeNet笔记,也写的通俗易通:https://www.zybuluo.com/rianusr/note/1419006
https://my.oschina.net/u/876354/blog/1637819
在学习后,确实对GoogLeNet 理解了不少,在此很感谢! 侵删,谢谢
强烈建议:
2014至2016年,GoogLeNet团队发表了多篇关于GoogLeNet的经典论文《Going deeper with convolutions》、《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》、《Rethinking the Inception Architecture for Computer Vision》、《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》,在这些论文中对Inception v1、Inception v2、Inception v3、Inception v4 等思想和技术原理进行了详细的介绍,建议阅读这些论文以全面了解GoogLeNet。
inception-4 论文地址:https://arxiv.org/pdf/1602.07261.pdf
inception-3 论文地址:https://arxiv.org/pdf/1409.4842v1.pdf
Rethinking the Inception Architecture for Computer Vision, 3.5% test error :http://arxiv.org/abs/1512.00567

 浙公网安备 33010602011771号
浙公网安备 33010602011771号