Linux GPU的使用
1,nvidia-smi指令解析
Nvidia自带了一个nvidia-smi的命令行工具,会显示显存使用情况:
nvidia -smi
如图,其可以在终端打印出GPU的各种属性。
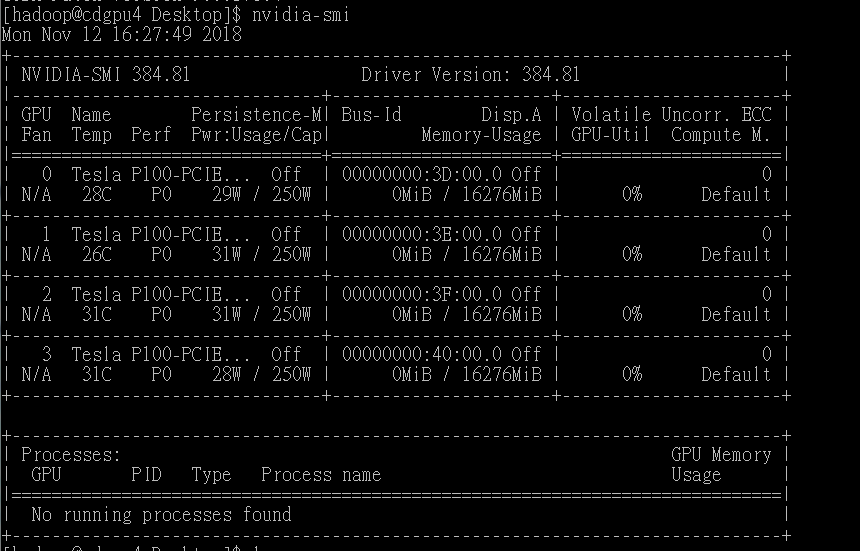
解析:
第一行Driver Version :384.81 表示我们使用的驱动是384.81
第二行中:第一行表示GPU序号,名字,Persisitence-M(持续模式状态),如我中有一个GPU序号为0;名字为 Tesla 系列的P100-PCIE;持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
第一栏Fan:N/A是风扇的转速,从0到100%之间变动。有的nvidia设备如笔记本,tesla系列不是主动散热的可能显示不了转速
第二栏Temp:温度,35摄氏度
第三栏Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示最小性能
第四栏中Pwr表示能耗,29瓦
第五栏中Bus-Id是表示GPU总线的东西
第六栏中Disp.A是DisPlay Active ,表示GPU是否有初始化
下方的Memory-Usage表示显存的使用率:共16GB 我已经使用了0MB
第七栏Volatile GPU-Util表示GPU的利用率
第八栏Uncorr.ECC是表示ECC的相关东西,ECC即 Error Correcting Code 错误检查和纠正,在服务器和工作站上的内存中才有的技术
再下面是关于进程的相关GPU使用率,如这边有三个进程对GPU进行了利用,Xorg,compiz和FireFox和各自调用时显存的使用量
Linux查看显卡信息:
lspci | grep -i vga
使用nvidia GPU可以
lspci |grep -i nvidia
有GPU的Linux服务器

没有GPU的Linux服务器

2,GPU的使用
在用TensorFlow深度学习模型训练中,假设我们在训练之前没有指定具体用哪一块GPU进行训练,则默认的是选用第0块GPU用来训练我们的模型,如果电脑有多块GPU的话,其他几块GPU的也会显示被占用。
有些时候,我们希望可以通过自己指定一块或者几块GPU来训练我们的模型,而不是用这种系统默认的方法。
下面代码是默认指定第0块GPU训练,但是我们指定了第二块进行训练。
# coding: utf-8
import argparse
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
flags = argparse.ArgumentParser()
flags.add_argument('--gpu', default=0, type=float, help='gpu number')
FLAGS = flags.parse_args()
# 使用GPU
gpun = FLAGS.gpu
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpun)
我们发现使用GPU的时候,我们在代码中通过CUDA_VISIBLE_DEVICES来指定,我们可以不用设定外面参数,直接在Python代码中加入下面两行即可:
import os os.environ['CUDA_VISIBLE_DEVICES']='1'
使用这种方法,在训练模型的饿时候,只使用了第“1”块GPU,并且其他几块GPU没有被占用,这就相当于我们在运行程式的时候,将除第”1“块以外的其他GPU全部屏蔽了,只有第”1“块GPU对当前运行的程序是可见的。
同理,如果要指定第“1,2”两块GPU来训练,则上面的代码可以修改为:
import os os.environ['CUDA_VISIBLE_DEVICES']='2,3'
类似的如果还有更多的GPU要指定,都可以仿照上面的代码进行添加,——显卡数字中间使用英文逗号隔开即可。
或者我们可以在终端执行py文件的时候通过CUDA_VISIBLE_DEVICES来指定,与上面类似,只不过在代码外面而已。
CUDA_VISIBLE_DEVICES=1 python train.py