
(转载)深度学习基础(2)——线性单元和梯度下降
原文地址:https://www.zybuluo.com/hanbingtao/note/448086
转载在此的目的是自己做个笔记,日后好复习,如侵权请联系我!!
在上一篇文章中,我们已经学会了编写一个简单的感知器,并用它来实现一个线性分类器。你应该还记得用来训练感知器的『感知器规则』。然而,我们并没有关心这个规则是怎么得到的。本文通过介绍另外一种『感知器』,也就是『线性单元』,来说明关于机器学习一些基本的概念,比如模型、目标函数、优化算法等等。这些概念对于所有的机器学习算法来说都是通用的,掌握了这些概念,就掌握了机器学习的基本套路。
线性单元是什么?
感知器有一个问题,当面对的数据集不是线性可分的时候,『感知器规则』可能无法收敛,这意味着我们永远也无法完成一个感知器的训练。为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。

这样的线性单元如下图所示:
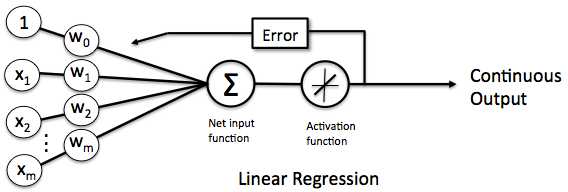
对比此前我们讲过的感知器。
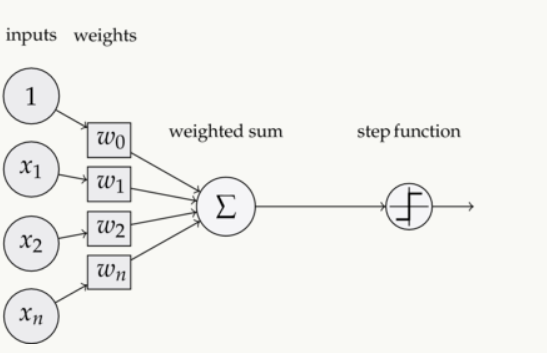
这样替换了激活函数f之后,线性单元将返回一个实数值而不是0,1分类。因此线性单元用来解决回归问题而不是分类问题。
线性单元的模型

你也许会说,这个模型太不靠谱了,是这样的,因为我们考虑的因素太少了,仅仅包含了工作年限。如果要考虑更多的因素,比如所处的行业,公司,职级等等,可能预测就会靠谱的多,我们把工作年限,行业,公司,职级这些信息称之为特征。对于一个工作5年,在IT行业,百度工作,职位T6这样的人,我们可以用这样的一个特征向量表示他
![]()


监督学习和无监督学习
接下来,我们需要关心的是这个模型如何训练,也就是参数w取什么值最合适。
机器学习有一类学习方法叫做监督学习,它是说为了训练一个模型,我们要提供这样一堆训练样本:每个训练样本即包括输入特征x,也包括对应的输出y(y也叫作标记label)。也就是说,我们要找到很多人,我们即知道他们的特征(工作年限,行业...),也知道他们的收入,我们用这样的样本去训练模型,让模型即看到我们提出的每个问题(输入特征x),也看到对应问题的答案(标记y)。当模型看到足够多的样本之后,它就能总结出其中的一些规律。然后,就可以预测那些它没看过的输入所对应的答案了。
另外一类学习方法叫做无监督学习,这种方法的训练样本中只有x而没有y。模型可以总结出特征x的一些规律,但是无法知道其对应的答案y。
很多时候,即有x又有y的训练样本是很少的,大部分都只有x,比如在语音到文本(STT)的识别任务中,x是语音,y是这段语音对应的文本。我们很容易获取大量的语音录音,然而把语音一段一段切分好并标注上对应文字则是非常费力气的事情。这种情况下,为了弥补带标注样本的不足,我们可以用无监督学习方法先做一些聚类,让模型总结出那些音节是相似的,然后再用少量的带标注的训练样本,告诉模型其中一些音节对应的文字。这样模型就可以把相似的音节都对应到相应文字上,完成模型的训练。
线性单元的目标函数
现在我们只考虑监督学习。
在监督学习下,对于一个样本,我们知道它的特征x,以及标记y。同时,我们还可以根据模型H(x)计算得到输出Yhat。注意这里面我们用y表示训练样本里面的标记,也就是实际值;用带上划线的Yhat表示计算模型计算的出来的预测值,我们当然希望模型计算出来的Yhat和Y越接近越好。

我们还可以把上面的公司写成和式的形式。使用和式,不光书写起来简单,逼格也跟着暴涨,一举两得,所以一定要写成下面这样


梯度下降优化算法
大学时候我们学过怎么样求函数的极值。函数y=f(x)的极值点,就是它的导数f'(x) = 0 的那个点,因此我们可以通过解方程f'(x) = 0 ,求得函数的极值点(X0,Y0)。
不过对于计算机来说,它可不会解方程。但是它可以凭借强大的计算能力,一步一步的去把函数的极值点试出来,如下图所示:
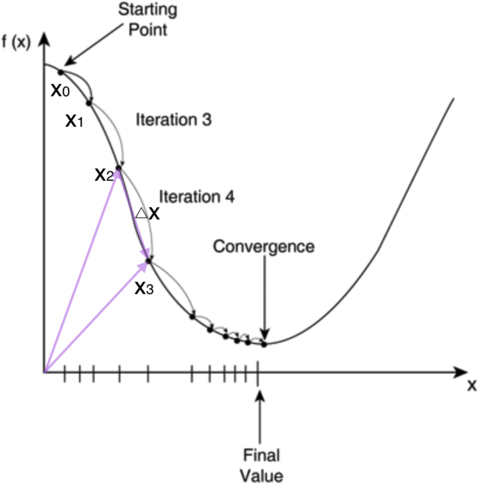
首先,我们随便选择一个点开始,比如上图的X0点,接下来,每次迭代修改x的值为X1,X2,X3,.....经过数次迭代后最终达到函数最小值点。
你可能要问了,为啥每次修改x的值,都能往函数最小值那个方向前进呢?这里的奥秘在于,我们每次都是向函数y =f(x)的梯度的相反方向来修改x,什么是梯度呢?梯度是一个向量,它指向函数值上升最快的方向。显然,梯度的反方向当然是函数值下降最快的方向了。我们每次沿着梯度相反方向去修改x的值,当然就能走到函数的最小值附近。之所以是最小值附近而不是最小值那个点,是因为我们每次移动的步长不会那么恰到好处,有可能最后一次迭代走远了越过了最小值那个点。步长的选择是门手艺,如果选择小了,那么就会迭代很多轮才能走到最小值附近;如果选择大了,那么可能就会越过最小值很远,收敛不到一个好的点上。
按照上面的讨论,我们就可以写出梯度下降算法的公式:

下面,请先做几次深呼吸,保持大脑清醒,我们来求取deltaE(w),然后带入上式,就能得到线性单元的参数修改规则。
关于deltaE(w)的推导过程,请下去再了解。现在我们关注的是目标函数E(w)的梯度:
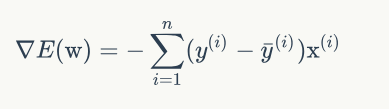
因此,线性单元的参数修改规则最后是这个样子:
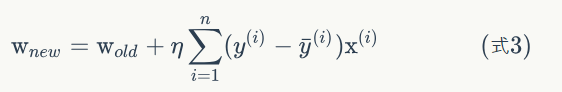




随机梯度下降算法(Stochastic Gradient Descent,SGD)
如果我们根据式(3)来训练模型,那么我们每次更新w的迭代,要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(Batch Gradient Descent)。如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。因此,实用的算法是SGD算法。在SGD算法中,每次更新w的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对w更新数百万次,效率大大提升。由于样本的噪声和随机性,每次更新w并不一定按照减少E的方向。然而,虽然存在一定随机性,大量的更新总体上沿着减少E的方向前进的,因此最后也能收敛到最小值附近。
下图展示了SGD和BGD的区别
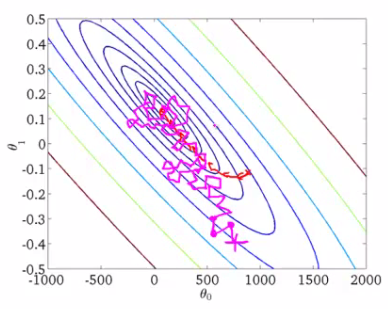
如上图,椭圆表示的是函数值的等高线,椭圆中心是函数的最小值点。红色是BGD的逼近曲线,而紫色是SGD的逼近曲线。我们可以看到BGD是一直向着最低点前进的,而SGD明显躁动了许多,但总体上仍然是向最低点逼近的。
最后需要说明的是,SGD不仅仅效率高,而且随机性有时候反而是好事。今天的目标函数是一个『凸函数』,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。
实现线性单元
完整代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
from perceptron import Perceptron
#定义激活函数f
f = lambda x: x
class LinearUnit(Perceptron):
def __init__(self, input_num):
'''初始化线性单元,设置输入参数的个数'''
Perceptron.__init__(self, input_num, f)
def get_training_dataset():
'''
捏造5个人的收入数据
'''
# 构建训练数据
# 输入向量列表,每一项是工作年限
input_vecs = [[5], [3], [8], [1.4], [10.1]]
# 期望的输出列表,月薪,注意要与输入一一对应
labels = [5500, 2300, 7600, 1800, 11400]
return input_vecs, labels
def train_linear_unit():
'''
使用数据训练线性单元
'''
# 创建感知器,输入参数的特征数为1(工作年限)
lu = LinearUnit(1)
# 训练,迭代10轮, 学习速率为0.01
input_vecs, labels = get_training_dataset()
lu.train(input_vecs, labels, 10, 0.01)
#返回训练好的线性单元
return lu
def plot(linear_unit):
import matplotlib.pyplot as plt
input_vecs, labels = get_training_dataset()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(map(lambda x: x[0], input_vecs), labels)
weights = linear_unit.weights
bias = linear_unit.bias
x = range(0,12,1)
y = map(lambda x:weights[0] * x + bias, x)
ax.plot(x, y)
plt.show()
if __name__ == '__main__':
'''训练线性单元'''
linear_unit = train_linear_unit()
# 打印训练获得的权重
print linear_unit
# 测试
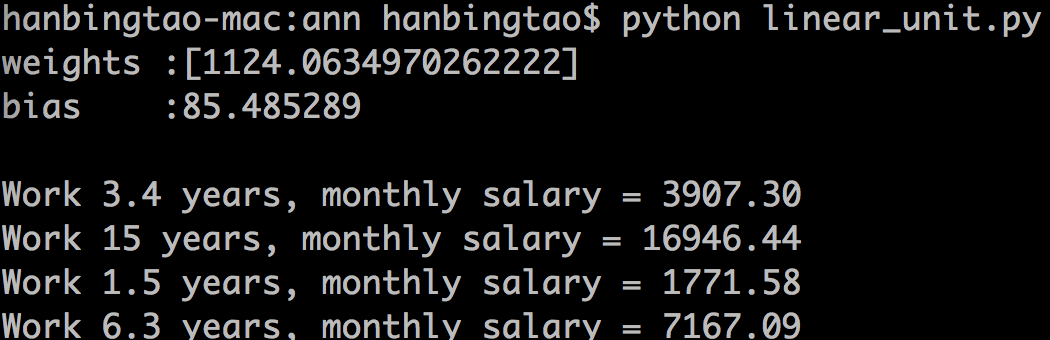
print 'Work 3.4 years, monthly salary = %.2f' % linear_unit.predict([3.4])
print 'Work 15 years, monthly salary = %.2f' % linear_unit.predict([15])
print 'Work 1.5 years, monthly salary = %.2f' % linear_unit.predict([1.5])
print 'Work 6.3 years, monthly salary = %.2f' % linear_unit.predict([6.3])
plot(linear_unit)
接下来,让我们撸一把代码。
因为我们已经写了感知器的代码,因此我们先比较一下感知器模型和线性单元模型,看看哪些代码能够复用。
结果就是,原来除了激活函数f 不同之外,两者的模型和训练规则是一样的(在上表中,线性单元的优化算法是SGD算法)。那么,我们只需要把感知器的激活函数进行替换即可。感知器的代码请参考上一篇文章。
from perceptron import Perceptron
#定义激活函数f
f = lambda x: x
class LinearUnit(Perceptron):
def __init__(self, input_num):
'''初始化线性单元,设置输入参数的个数'''
Perceptron.__init__(self, input_num, f)
通过继承Perceptron,我们仅用几行代码就实现了线性单元。这再次证明了面向对象编程范式的强大。
接下来,我们用简单的数据进行一下测试。
def get_training_dataset():
'''
捏造5个人的收入数据
'''
# 构建训练数据
# 输入向量列表,每一项是工作年限
input_vecs = [[5], [3], [8], [1.4], [10.1]]
# 期望的输出列表,月薪,注意要与输入一一对应
labels = [5500, 2300, 7600, 1800, 11400]
return input_vecs, labels
def train_linear_unit():
'''
使用数据训练线性单元
'''
# 创建感知器,输入参数的特征数为1(工作年限)
lu = LinearUnit(1)
# 训练,迭代10轮, 学习速率为0.01
input_vecs, labels = get_training_dataset()
lu.train(input_vecs, labels, 10, 0.01)
#返回训练好的线性单元
return lu
if __name__ == '__main__':
'''训练线性单元'''
linear_unit = train_linear_unit()
# 打印训练获得的权重
print linear_unit
# 测试
print 'Work 3.4 years, monthly salary = %.2f' % linear_unit.predict([3.4])
print 'Work 15 years, monthly salary = %.2f' % linear_unit.predict([15])
print 'Work 1.5 years, monthly salary = %.2f' % linear_unit.predict([1.5])
print 'Work 6.3 years, monthly salary = %.2f' % linear_unit.predict([6.3])
程序运行结果如下:
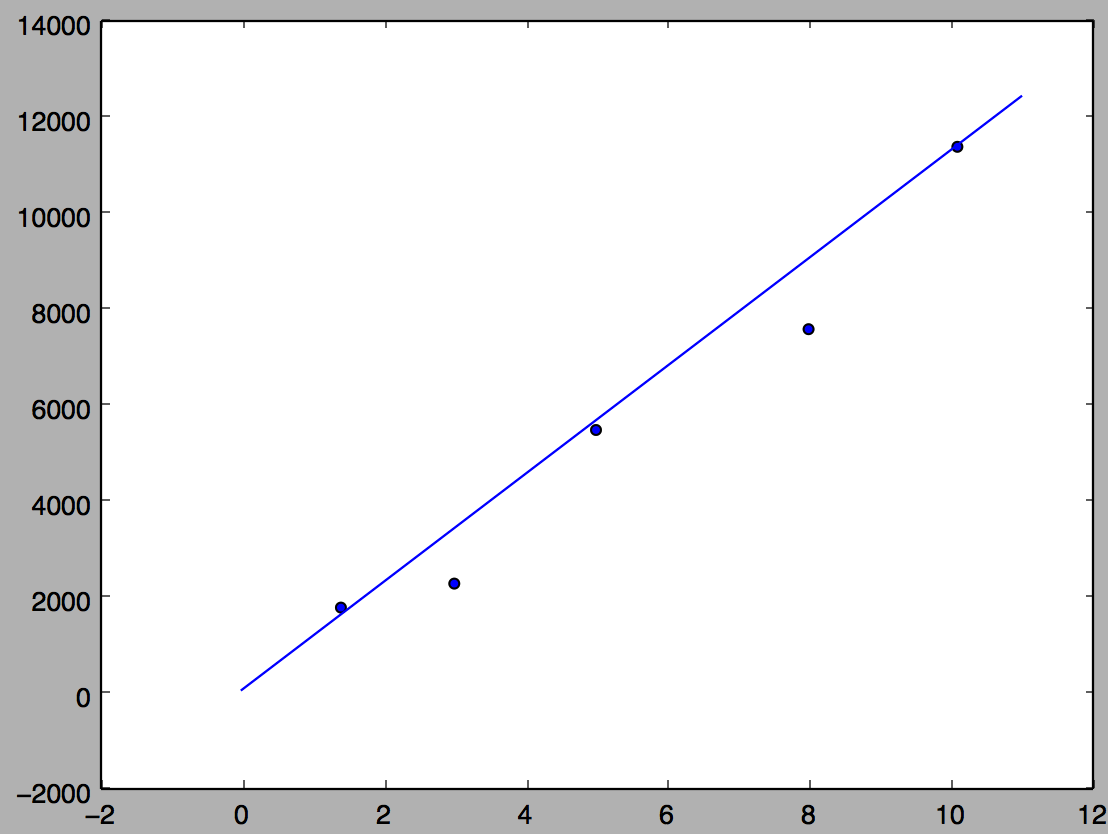
拟合的直线如下图
小结
事实上,一个机器学习算法其实只有两部分
- 模型 从输入特征预测输入的那个函数
- 目标函数 目标函数取最小(最大)值时所对应的参数值,就是模型的参数的最优值。很多时候我们只能获得目标函数的局部最小(最大)值,因此也只能得到模型参数的局部最优值。
因此,如果你想最简洁的介绍一个算法,列出这两个函数就行了。
接下来,你会用优化算法去求取目标函数的最小(最大)值。[随机]梯度{下降|上升}算法就是一个优化算法。针对同一个目标函数,不同的优化算法会推导出不同的训练规则。我们后面还会讲其它的优化算法。
其实在机器学习中,算法往往并不是关键,真正的关键之处在于选取特征。选取特征需要我们人类对问题的深刻理解,经验、以及思考。而神经网络算法的一个优势,就在于它能够自动学习到应该提取什么特征,从而使算法不再那么依赖人类,而这也是神经网络之所以吸引人的一个方面。
现在,经过漫长的烧脑,你已经具备了学习神经网络的必备知识。下一篇文章,我们将介绍本系列文章的主角:神经网络,以及用来训练神经网络的大名鼎鼎的算法:反向传播算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号