HDFS架构与原理
HDFS
HDFS 全称hadoop分布式文件系统,其最主要的作用是作为 Hadoop 生态中各系统的存储服务
特点
优点
• 高容错、高可用、高扩展 -数据冗余多副本,副本丢失后自动恢复 -NameNode HA、安全模式 -10K节点规模
• 海量数据存储 -典型文件大小GB~TB,百万以上文件数量 PB以上数据规模
• 构建成本低、安全可靠 -构建在廉价的商用服务器上 -提供了容错和恢复机制
• 适合大规模离线批处理 -流式数据访问 -数据位置暴露给计算框架
缺点
• 不适合低延迟数据访问
• 不适合大量小文件存储 -元数据占用NameNode大量内存空间 -磁盘寻道时间超过读取时间
• 不支持并发写入 -一个文件同时只能有一个写入者
• 不支持文件随机修改 -仅支持追加写入
架构图
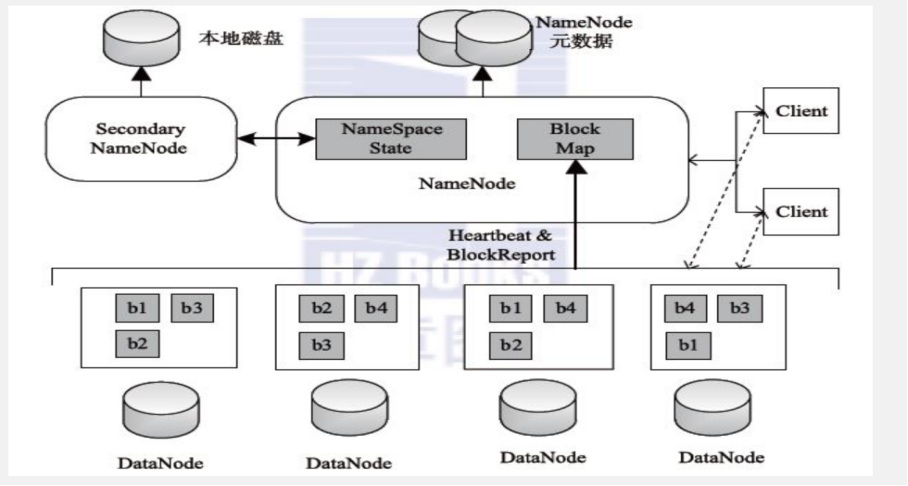
Namenode 主节点
管理HDFS文件系统的命名空间、维护元数据信息
处理客户端读写请求
Datanode 从节点
存储数据(Block)
集群启动时, DataNode向NameNode汇报Block列表信息 集群运行期间, 通过心跳机制定期(默认3秒) 与NameNode保持通信
Secondary node
主要存在于HDFS1.x架构当中, 并不是NameNode的热备,只是在namende发生故障的时候快速切换
辅助NameNode完成元数据文件fsimage、 edits的定期合并
HDFS存储机制:元数据
元数据(Metadata)
信息存放在NameNode内存当中 包含:HDFS中文件及目录的基本属性信息(如拥有者、权限信息创建时间等)、文件有哪些block构成、 以及block的位置存放信息。
元数据信息持久化
fsimage(元数据镜像检查点文件)
edits(编辑日志文件,记录写操作)
注:block的位置信息并不会做持久化,仅仅只是在DataNode启动汇报给NameNode,存放在NameNode内存空间内
HDFS存储机制:block
Block
• Block是HDFS的最小存储单元 • Block的大小 -默认大小:128M(HDFS 1.x中,默认64M)
-若文件大小不足128M,则会单独成为一个block -实质上就是Linux相应目录下的普通文件
-名称格式:blk_xxxxxxx
• Block和元数据分开存储,Block存储于DataNode,元数据存储于NameNode
• Block多副本 -默认副本数:3
-机架感知:将副本存储到不同的机架上,实现数据的高容错
-副本均匀分布:提高访问带宽和读取性能,实现负载均衡,避免出现数据倾斜
HDFS存储机制:读写流程

写流程
• 客户端发送创建文件指令给分布式文件系统
• 文件系统告知namenode • 检查权限,查看文件是否存在
• EditLog增加记录 • 返回输出流对象
• 客户端往输出流中写入数据,分成一个个数据包
• 根据namenode分配,输出流往datanode写数据
• 多个datanode构成一个管道pipeline,输出流写第一个,后面的转发
• 每个datanode写完一个块后,返回确认信息
• 写完数据,关闭输出流
• 发送完成信号给namenode
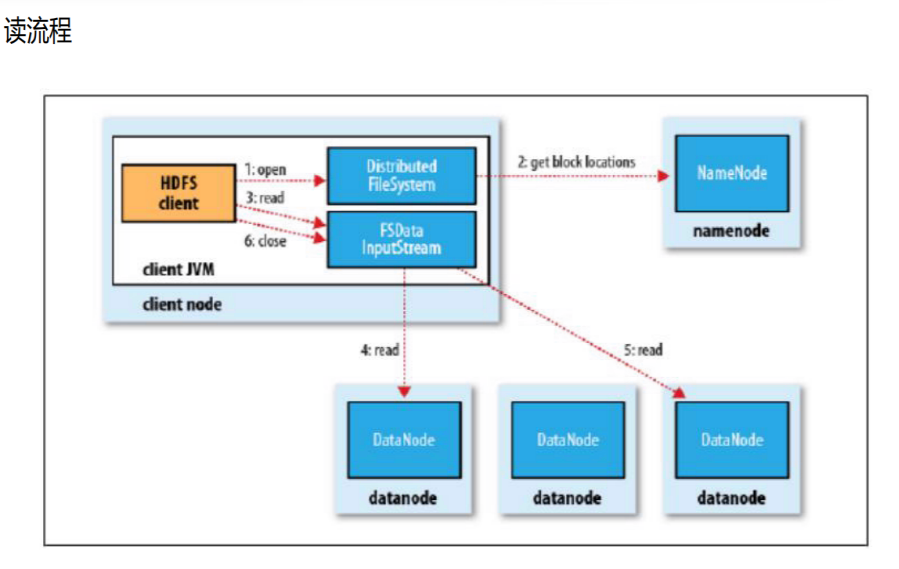
读流程
• 客户端发送打开文件指令给分布式文件系统
• 文件系统访问namenode,获得这个文件的数据块位置列表,返回输入流对象
• 客户端从输入流中读取数据
• 输入流从各个datanode读取数据
• 关闭输入流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号