从零开始学习前端JAVASCRIPT — 9、JavaScript基础RegExp(正则表达式)
1:正则的概念
正则表达式(regular expression)是一个描述字符规则的对象。可以用来检查一个字符串是否含有某个子字符串,将匹配的子字符串做替换或者从某个字符串中取出符合某个条件的子串等。
为什么要用正则:前端往往有大量的表单数据校验工作,采用正则表达式会使得数据校验的工作量大大减轻。常用效果:邮箱、手机号、身份证号等。
2:创建方式
i:表示忽略大小写。
g:表示全局匹配,查找所有匹配并返回而非在找到第一个匹配后停止。
m:多行匹配。
第一种方式:var reg = new RegExp(“study”, “ig”); // 第二个参数为修饰符,修饰符可以多个连写
第二种方式:var reg = /study/ig;
var str = 'Good good study day day up!';
// 第一种
var regone = /good/ig;
// 第二种
var regtwo = new RegExp('good', 'ig');
console.log(str.match(regone))
console.log(str.match(regtwo))
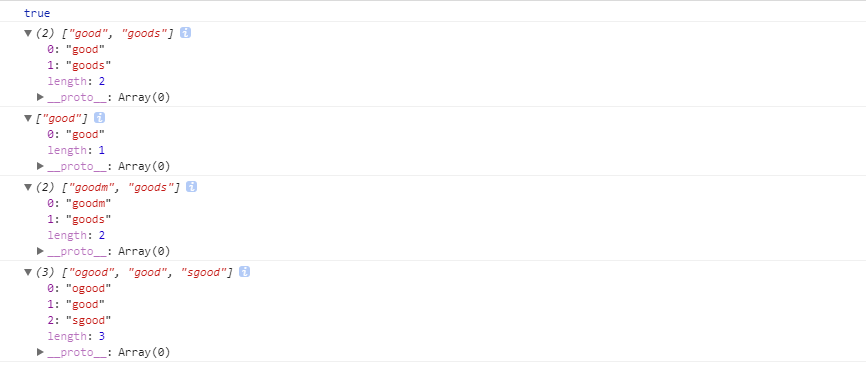
3:正则对象方法
test:检索字符串中指定的值。返回true或false。
exec:用于检索字符串中的正则表达式的匹配。返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为null。
注:如果没有指定g修饰符,那么每次匹配都是从头开始匹配,如果指定g修饰符以后,下次匹配则从上次匹配的结束位置开始匹配。
var str = 'Good good study day day up!';
// 正则表达式对象的方法
var regone = /good/ig;
var regtwo = new RegExp('good', 'ig');
console.log(regone.test(str));
console.log("——————————我是分割线——————————");
regone.lastIndex = 4;//指定索引开始匹配的位置
console.log(regone.exec(str));
console.log(regtwo.exec(str));
console.dir(regone)

4:字符串函数
search:检索与正则表达式相匹配的值。返回字符串中第一个与正则表达式相匹配的子串的起始位置。如果没有找到则返回-1。
match:找到一个或多个正则表达式的匹配。
replace:替换与正则表达式匹配的子串。
replace(捕获正则表达式,$1《对捕获表达式的值引用》)
replace方法第二个参数支持回调函数,回调函数的参毁掉表就是正则表达式匹配到的结果
split:把字符串分割为字符串数组。
var str = 'Good good study day day up!';
// 字符串的方法
var reg = /good/ig;
var result = str.match(reg);
console.log(result)
var result = str.search(reg);
console.log(result)
var result = str.replace(reg, '****');
console.log(result)
var str = 'a=b&c=d&e=f';
var reg = /[=&]/;
var result = str.split(reg);
console.log(result)

5:正则表达式构成
正则表达式是由普通字符(例如字符a到z)以及特殊字符(称为元字符)组成的文字模式。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
元字符---限定符:限定符可以指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
*:匹配前面的子表达式零次或多次。
+:匹配前面的子表达式一次或多次。
?:匹配前面的子表达式零次或一次。
{n}:匹配确定n次。
{n,}:至少匹配n次。
{n, m}:最少匹配n次且最多匹配m次。
// 限定符
var str = 'google good';
var reg = /go*gle/; // 代表0到多次
console.log(str.split(reg));
var reg = /go+gle/; // 代表1到多次
console.log(str.split(reg));
var reg = /go?gle/; // 代表0到1次
console.log(str.split(reg));
var reg = /go{4,}gle/; // 代表最少4次
console.log(str.split(reg));
var reg = /go{3,5}gle/; // 代表最少3次,最多5次
console.log(str.split(reg));
var reg = /go{2}gle/; // 代表只有2次
console.log(str.split(reg));

注:在限定符后紧跟 ? 则由贪婪匹配变成非贪婪匹配。
// 贪婪匹配转换成非贪婪匹配
var str = '<div id="box"></div><p></p>';
var regone = /<.+>/;
var regtwo = /<.+?>/;
console.log(regone.exec(str));
console.log("————————上为贪婪匹配,下为非贪婪匹配————————");
console.log(regtwo.exec(str));

元字符---字符匹配符:字符匹配符用于匹配某个或某些字符。
[xyz]:字符集合。匹配所包含的任意一个字符。
[^xyz]:负值字符集合。匹配未包含的任意字符。
[a-z]:字符范围。匹配指定范围内的任意字符。
[^a-z]:负值字符范围。匹配任何不在指定范围内的任意字符。
例如:[0-9]、[0-9a-z]、[0-9a-zA-Z]
\d:匹配一个数字字符。
\D:匹配一个非数字字符。
\w:匹配包含下划线的任何单词字符。等价于[a-z0-9A-Z_]
\W:匹配任何非单词字符。等价于[^a-z0-9A-Z_]
\s:匹配任何空白字符。
\S:匹配任何非空白字符。
.:匹配除”\n”之外的任何单个字符。
// 字符匹配符
var str = 'a=b&c=d&e=f';
var reg = /[=&]/; // 字符匹配符集合
console.log(reg.exec(str))
var reg = /[^=&]/; // 否值字符匹配符集合
console.log(reg.exec(str))
var reg = /[b-e]/; // 范围字符匹配符
console.log(reg.exec(str))
var reg = /[^b-e]/; // 否值范围字符匹配符
console.log(reg.exec(str))
var str = '2018 we are coming! \n _%$#@';
var reg = /\d{4}/g;
console.log(reg.exec(str))
var reg = /\D{4}/g;
console.log(reg.exec(str))
var reg = /\w{4}/g;
console.log(reg.exec(str))
var reg = /\W{4}/g;
console.log(reg.exec(str))
var reg = /\s{1}/g;
console.log(reg.exec(str))
var reg = /\S{1}/g;
console.log(reg.exec(str))
var reg = /.+/g;
console.log(reg.exec(str))
元字符---定位符:定位符可以将一个正则表达式固定在一行的开始或结束。也可以创建只在单词内或只在单词的开始或结尾处出现的正则表达式。
^:匹配输入字符串的开始位置。
$:匹配输入字符串的结束位置。
\b:匹配一个单词边界,也就是单词和空格间的位置。
\B:匹配非单词边界。
// 定位符
// ^ 和 $ :限定字符串开始和结束的位置
var cellphone = '12345678901';
var reg = /^1\d{10}$/;
console.log(reg.test(cellphone));
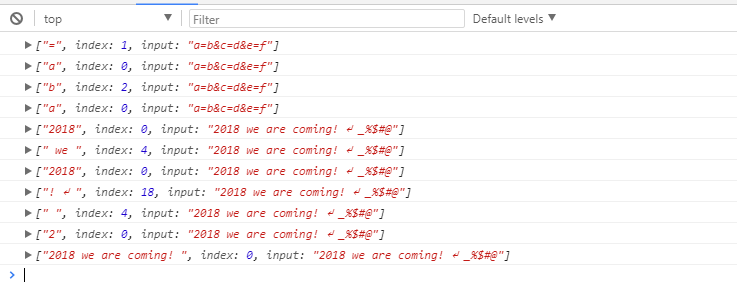
// \b:限定单词以什么开头和结尾,\B:限定单位不以什么开头和结尾
var str = 'good ogoodm goods sgoods';
var reg = /\bg\w+/g;
console.log(str.match(reg));
var reg = /\w+d\b/g;
console.log(str.match(reg));
var reg = /\Bg\w+/g;
console.log(str.match(reg));
var reg = /\w+d\B/g;
console.log(str.match(reg));
元字符---转义符:\:用于匹配某些特殊字符。
// 转义符
var str = 'a*********b';
var reg = /\*+/;
console.log(str.match(reg));

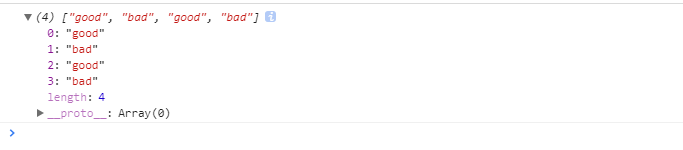
元字符---选择匹配符:|:可以匹配多个规则。
var str = 'good bad goodbad';
var reg = /good|bad/g;
console.log(str.match(reg));
特殊用法:
():捕获性分组,也称为子表达式。使用\1、\2、\3…对子组的引用。当子组发生嵌套时,顺序是从外到内。
var str = '<div>你好</ppp>';
var reg = /<.+?>(?:.*?)<\/.+?>/g;
console.log(str.match(reg));
console.log("————————我是分割线————————")
var reg = /<(.+?)>(.*?)<\/\1>/g;
console.log(str.match(reg));
//释义:\1或\2...表示对表达式的引用及对字符串匹配值方式的引用,不是表义上\数值对(.+?)表达式的引用

//()捕获型分组表达式的应用及表达式返回值的引用 //$对()捕获型分组返回值的引用 var str = '<div>HF胡辣汤!!!!!!</div>'; var reg = /<div>(.*)<\/div>/; console.log(reg.exec(str)); //表达式的匹配的值:<div>HF胡辣汤!!!!!!</div> //子表达式返回的值:HF胡辣汤!!!!!! console.log(str.replace(reg, '<h2>$1</h2>')); //$字符在此处的作用是对子表达式返回值的引用,经replace替换,将字符串改写成<h2>HF胡辣汤!!!!!!</h2>

var str = '<div>HF胡辣汤!!!!!!</div>';
var reg = /<div>(.*)<\/div>/;
var result = str.replace(reg, function (name, name1) {
console.log(name, name1);
return name1;
});
//replace方法第二个参数支持回调函数,回调函数的形参表对应正则表达式匹配到的返回结果
//返回结果(表达式的返回结果及子表达式的返回结果)。

(?:pattern):非捕获性分组。匹配pattern但不获取匹配结果。也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个'industry|industries' 更简略的表达式。
var str = '<div>HF胡辣汤!!!!!!</div>';
var reg = /<div>(?:.*)<\/div>/;//(注意表达式内的变化)
var result = str.replace(reg, function (name, name1) {
console.log(name, name1);
return name1;
});
console.log(result);

(?=pattern):正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如, 'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern):负向预查,在任何不匹配pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如‘Windows (?!95|98|NT|2000)’ 能匹配 “Windows 3.1” 中的 “Windows”,但不能匹配 “Windows 2000” 中的 “Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
// 预查
var str = 'windowsXP windows7 windows10 windows8 windows8.1 windows97';
var regone = /windows(?=[a-z]+)/i; //正向预查
var regtwo = /windows(?![a-z]+)/i;//反向预查
console.log(str.match(regone));
console.log(str.match(regtwo));

扩展:
手机号监测
身份证监测
日期监测
中文监测
unicode编码中文监测:/^[\u2E80-\u9FFF]+$/
用户名监测
正则:/^[a-z0-9_-]{3,16}$/
字符串过滤
用字符串replace方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号