

第一次个人作业—个人汇报(总)
基本功能
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题
要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
http://msdn.microsoft.com/en-us/library/dd264897.aspx
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客。
个人汇报
受限于能力不足,我的作业进度比较慢,尤其是在刚开始对于命令行参数,以及遍历文件夹操作,cmd,VS性能分析,GitHub的使用,一窍不通,摸索了两天,直到星期天下午才真正开始进行代码编码。
一:架构方面

在整个编码过程的实际过程中,遇到了很多麻烦,前后难互顾,但大概的架构思路没变很多,构架在最后编写完时是这样的
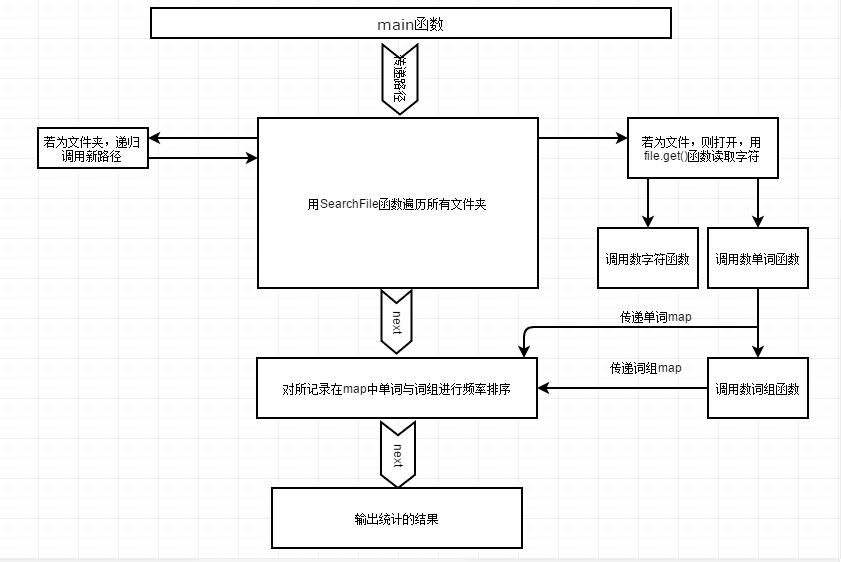
(注:图中的大箭头表示main函数的流程)
下面继续对每一部分具体进行分析
①变量方面:
int g_LineNumber = 0; //The number of rows used for recording int g_CharacterNumber = 0; //The number of characters used to record the number of characters int g_Wordnumber = 0; //The number of words used to record the number of words int g_circle = 4; //A loop counter, used to judge whether itit is the beginning of a word typedef struct MyWord //To store the information of the word { string originword; int frequency; string originprefix; }MyWord; typedef struct Pharze //Storage of phrases and frequency of appearance in a structure { string firstword; string secondword; int frequency; string originword; }Pharze; Pharze g_pharsesample; //Used for statistical phrases
四个全局变量用于记录单词数,字符数,行数,以及用于判断是否构成单词的循环计数器。
单词的结构体中记录的分别为 原始单词(包括数字),出现次数,原始单词前缀(不包含数字)
词组结构体中记录的为词组中的两个单词的第一个单词,第二个单词,出现次数,以及拼起来之后的单词。
②自定义的辅助的判断函数
为了使得代码更简洁,使if语句更容易读懂而特地分出来的bool型函数


bool JudgeLetter(char letter) //Judge whether a character is an English letter { if (((letter >= 'A') && (letter <= 'Z')) || ((letter >= 'a') && (letter <= 'z'))) { return true; } else { return false; } } bool JudgeNumber(char number) { if ((number >= '0') && (number <= '9')) { return true; } else { return false; } } bool JudgeCase(string dest, string source) //To distinguish Case { if ((size(dest) != size(source))||(dest==source)) { return false; } int i = size(dest); for (int j = 0; j < i; j++) { if ((((source.at(j) - dest.at(j)) % 32) == 0)&&((source.at(j)-dest.at(j))>=0)) { continue; } else { return false; } } return true; }
③main函数:
我的main函数比较简洁,只是作为函数的接口,同时给函数传递以必须的参数。
int main(int argc,char **argv) //Get the folder path with the command line parameters { string path = argv[1]; //Path command line unordered_map<string, Pharze> mapPharze; unordered_map<string, MyWord> mapWord; g_pharsesample.frequency = 1; //Initial variables for initializing phrases SearchFile(path,mapWord,mapPharze); WPSort(mapWord, mapPharze,path); cout << "行数总数"<<g_LineNumber << endl; cout << "字符总数" << g_CharacterNumber << endl; cout << "单词总数" << g_Wordnumber << endl; system("pause"); return 0; }
⑤遍历文件夹函数SearchFile
此部分的代码比较繁琐,因为这部分相当于一个重要的枢纽,内含判断单词的条件,连通了单词统计,字符统计,词组统计,行数统计。
void SearchFile(string folderpath, unordered_map<string,MyWord> &mapWord, unordered_map<string,Pharze> &mapPharze) //Traverse all files { char fileword; //The character used to store and read in a file bool isWord=false; string singleword; //It is used to record words when conditions are satisfied ifstream readfile; _finddata_t fileinfo; string deep_path = folderpath + "\\*.*"; //Find all the files in the current folder long Handle = _findfirst(deep_path.c_str(), &fileinfo); //Looking for the first file handle if (Handle == -1) //When the folder is empty, it returns directly { cout<<"The file is at the end"<<endl; return ; } do { if (fileinfo.attrib&_A_SUBDIR) { if ((strcmp(fileinfo.name, ".") != 0)&&(strcmp(fileinfo.name,"..")!=0)) //Used to determine whether or not a folder is a folder { string newpath = folderpath + "\\" + fileinfo.name; //If it is, then continue to call the function recursively SearchFile(newpath,mapWord,mapPharze); } } else { readfile.open(folderpath + "\\" + fileinfo.name); //Open the current folder if (!readfile.is_open()) { cout << folderpath+"\\"+fileinfo.name<<"fail to open" << endl; exit(1); system("pause"); } cout << folderpath+"\\"+ fileinfo.name << endl; while (!readfile.eof()) { fileword = readfile.get();//Take a word out of the document CounterCharacter(fileword); if (isWord) //Judge whether the word has been made up. { if (JudgeLetter(fileword) || JudgeNumber(fileword)) { singleword = singleword + fileword; } else { isWord = false; //No words can be made up again CounterWord(singleword, mapWord, mapPharze); //Transfer words singleword.clear(); } } else { if (JudgeLetter(fileword)) { g_circle--; if (singleword.empty()) { singleword = fileword; } else { singleword = singleword + fileword; } } else { g_circle = 4; singleword.clear(); } if (g_circle == 0) //The description has met the 4 consecutive characters as the English alphabet { isWord = true; g_circle = 4; } } } if (fileword != '\n') g_LineNumber++; //A file used to consider only one line without a newline character cout << folderpath + "\\" + fileinfo.name << "已经打开完成" << endl; readfile.close(); } } while (_findnext(Handle, &fileinfo) != -1); _findclose(Handle); }
⑥字符统计函数
当字符符合条件即用全局变量,进行统计加一。
void CounterCharacter(char buffer) //Statistical character number { if ((buffer >= 32) && (buffer <= 126)) //Determine whether the character is in the Ascii code { g_CharacterNumber++; } if (buffer == '\n') { g_LineNumber++; } }
⑦单词统计函数
此函数的功能也比较重要,因为这里决定了存入map中的单词是什么,我所使用的思路是,对所传递进入的单词进行分离,将少了数字后缀的一部分分离出来。同时这部分有一个相当重要的功能,即考虑单词的大小写问题后,如何统计单词。这一点将在后面优化内容中介绍,一段艰辛的路程。
void CounterWord(string singleword, unordered_map<string, MyWord> &mapWord, unordered_map<string, Pharze> &mapPharze) //Count the total number of words and the number of words and phrases { if (size(singleword) > 1024) { return; } int wordend = 0; //Used to record the end of the word int numberinit = 0; //Used to record the starting position of a number in a word string word_prefix; //Used to record prefixes of words MyWord word_detail; //Used to record full words and frequencies unordered_map<string,MyWord>::iterator worditer; word_detail.frequency = 1; g_Wordnumber++; wordend = size(singleword); for (numberinit = wordend-1; JudgeNumber(singleword.at(numberinit)); numberinit--){} numberinit++; //Find the starting position of the number word_detail.originprefix= singleword.substr(0, numberinit); for (int i = 0; i < numberinit; i++) { if ((singleword.at(i) <= 'Z') && (singleword.at(i) >= 'A')) { singleword.at(i) = singleword.at(i) + 32; } } word_prefix = singleword.substr(0, numberinit); //Record prefix word_detail.originword = singleword; worditer = mapWord.find(word_prefix); //Whether there is the same prefix in map if (worditer != mapWord.end()) { worditer->second.frequency++; //The word frequency plus one of the word if (strcmp(word_detail.originprefix.c_str(), worditer->second.originprefix.c_str())<0) //Find the lexicographic sorting earlier in the map { worditer->second.originprefix = word_detail.originprefix; } } else { mapWord.insert(pair<string, MyWord> (word_prefix, word_detail)); //If you can't find it, insert it in map } CounterPhrase(word_prefix, mapPharze); }
⑧词组统计函数
为了提高效率,避免重复遍历文件获取单词,我所选用的方法是设置词组结构体全局变量,这样,它就只管接受单词,每当有一个单词送入单词统计函数时,同时把他传递给词组统计函数,当词组结构体中的两个单词都被占满了,即认为构成了一个词组,此时即可用map储存或者增加map中其频率。
void CounterPhrase(string partword, unordered_map<string, Pharze> &mapPharze) //Statistical phrase number { unordered_map<string, Pharze>::iterator pharzeiter; if (g_pharsesample.firstword.empty()) //After judging the word, if yes,it has become the first word { g_pharsesample.firstword = partword; } else { g_pharsesample.secondword = partword; pharzeiter = mapPharze.find(g_pharsesample.firstword + g_pharsesample.secondword); //Judge whether the phrase can be found, the number of it is increased, and it is inserted into the map if (pharzeiter != mapPharze.end()) { pharzeiter->second.frequency++; } else { mapPharze.insert(pair<string, Pharze>(g_pharsesample.firstword + g_pharsesample.secondword, g_pharsesample)); } g_pharsesample.firstword.clear(); //Re initialize the phrase global variable to prepare to continue to accept the next phrase g_pharsesample.secondword.clear(); g_pharsesample.frequency = 1; g_pharsesample.originword.clear(); } }
⑨排序输出函数
我选用的排序方法是遍历map中十次,每次从map选出一个频率最大的,同时把它从删去,继续寻找下一个,在循环中还起着拼接词组,输出文件作用。
void WPSort(unordered_map<string, MyWord> &mapWord, unordered_map<string, Pharze> &mapPharze,string path) //Words and phrases with the highest statistical frequency { ofstream write; string word[10]; //Record 10 most frequent words int wordfrequency[10] = { 0 }; //Record the number of the 10 most frequent words string pharze[10]; //Record 10 most frequent phrases int pharsefrequency[10] = { 0 }; //Record the number of 10 most frequent phrases unordered_map<string, MyWord>::iterator worditer; unordered_map<string, Pharze>::iterator pharzeiter; unordered_map<string, Pharze>::iterator pmax; //Used to record the largest pharze in each round sort unordered_map<string, MyWord>::iterator wmax; //Used to record the largest word in each round sort unordered_map<string, MyWord>::iterator findorigin1; //To retrieve the original word, 1 represents the first word, 2 represents second words. unordered_map<string, MyWord>::iterator findorigin2; bool isPlacew=false; //TO judge whether word has been placed bool isPlacep = false; write.open(path+"\\"+"Result.txt"); for (int i = 0; i < 10; i++) { for (pharzeiter = mapPharze.begin(); pharzeiter != mapPharze.end(); pharzeiter++) { if (pharzeiter->second.frequency > pharsefrequency[i]) { findorigin1 = mapWord.find(pharzeiter->second.firstword); findorigin2 = mapWord.find(pharzeiter->second.secondword); pharzeiter->second.originword = findorigin1->second.originprefix + " " + findorigin2->second.originprefix; pharsefrequency[i] = pharzeiter->second.frequency; pharze[i] = pharzeiter->second.originword; pmax = pharzeiter; isPlacew = true; } } if (isPlacew) { mapPharze.erase(pmax); isPlacew = false; } } for (int i = 0; i < 10;i++) { for (worditer = mapWord.begin(); worditer != mapWord.end(); worditer++) { if (worditer->second.frequency > wordfrequency[i]) { wordfrequency[i] = worditer->second.frequency; word[i] = worditer->second.originprefix; wmax = worditer; isPlacep = true; } } if (isPlacep) { mapWord.erase(wmax); isPlacep = false; } } write << "Line Number" << g_LineNumber << endl; write << "Character Number" << g_CharacterNumber << endl; write << "Word Number" << g_Wordnumber << endl; write << "<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<" << endl; //The following are the things stored in the txt file write << "The number of word" << endl; for (int i =0; i < 10; i++) { if (!word[i].empty()) { cout << word[i] << " " << wordfrequency[i] << endl; write << word[i] << " " << wordfrequency[i] << endl; } else { cout << "The number of word is less than ten and has benn enumerated completely" << endl; write << "The number of word is less than ten and has benn enumerated completely" << endl; break; } } write << endl; write << endl; write << "<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<" << endl; write << "The number of pharze" << endl; for (int i = 0; i < 10; i++) { if (!pharze[i].empty()) { cout << pharze[i] << " " << pharsefrequency[i] << endl; write << pharze[i] << " " << pharsefrequency[i] << endl; } else { cout << "The number of pharze is less than ten, and has benn enumerated completely" << endl; write << "The number of pharze is less than ten, and has benn enumerated completely" << endl; break; } } }
整个源代码如下:
#include "stdafx.h" #include<iostream> #include<io.h> #include<fstream> #include<string> #include<Windows.h> #include<stdio.h> #include<map> #include < unordered_map > using namespace std::tr1; using namespace std; int g_LineNumber = 0; //The number of rows used for recording int g_CharacterNumber = 0; //The number of characters used to record the number of characters int g_Wordnumber = 0; //The number of words used to record the number of words int g_circle = 4; //A loop counter, used to judge whether itit is the beginning of a word typedef struct MyWord //The storage of the original word in the structure and the frequency of its appearance, as well as its replacement letters { string originword; int frequency; string originprefix; }MyWord; typedef struct Pharze //Storage of phrases and frequency of appearance in a structure { string firstword; string secondword; int frequency; string originword; }Pharze; Pharze g_pharsesample; //Used for statistical phrases void CounterCharacter(char buffer) //Statistical character number { if ((buffer >= 32) && (buffer <= 126)) //Determine whether the character is in the Ascii code { g_CharacterNumber++; } if (buffer == '\n') { g_LineNumber++; } } bool JudgeLetter(char letter) //Judge whether a character is an English letter { if (((letter >= 'A') && (letter <= 'Z')) || ((letter >= 'a') && (letter <= 'z'))) { return true; } else { return false; } } bool JudgeNumber(char number) { if ((number >= '0') && (number <= '9')) { return true; } else { return false; } } bool JudgeCase(string dest, string source) //To distinguish Case { if ((size(dest) != size(source))||(dest==source)) { return false; } int i = size(dest); for (int j = 0; j < i; j++) { if ((((source.at(j) - dest.at(j)) % 32) == 0)&&((source.at(j)-dest.at(j))>=0)) { continue; } else { return false; } } return true; } void CounterPhrase(string partword, unordered_map<string, Pharze> &mapPharze) //Statistical phrase number { unordered_map<string, Pharze>::iterator pharzeiter; if (g_pharsesample.firstword.empty()) //After judging the word, if yes,it has become the first word { g_pharsesample.firstword = partword; } else { g_pharsesample.secondword = partword; pharzeiter = mapPharze.find(g_pharsesample.firstword + g_pharsesample.secondword); //Judge whether the phrase can be found, the number of it is increased, and it is inserted into the map if (pharzeiter != mapPharze.end()) { pharzeiter->second.frequency++; } else { mapPharze.insert(pair<string, Pharze>(g_pharsesample.firstword + g_pharsesample.secondword, g_pharsesample)); } g_pharsesample.firstword.clear(); //Re initialize the phrase global variable to prepare to continue to accept the next phrase g_pharsesample.secondword.clear(); g_pharsesample.frequency = 1; g_pharsesample.originword.clear(); } } void CounterWord(string singleword, unordered_map<string, MyWord> &mapWord, unordered_map<string, Pharze> &mapPharze) //Count the total number of words and the number of words and phrases { if (size(singleword) > 1024) { return; } int wordend = 0; //Used to record the end of the word int numberinit = 0; //Used to record the starting position of a number in a word string word_prefix; //Used to record prefixes of words MyWord word_detail; //Used to record full words and frequencies unordered_map<string,MyWord>::iterator worditer; word_detail.frequency = 1; g_Wordnumber++; wordend = size(singleword); for (numberinit = wordend-1; JudgeNumber(singleword.at(numberinit)); numberinit--){} numberinit++; //Find the starting position of the number word_detail.originprefix= singleword.substr(0, numberinit); for (int i = 0; i < numberinit; i++) { if ((singleword.at(i) <= 'Z') && (singleword.at(i) >= 'A')) { singleword.at(i) = singleword.at(i) + 32; } } word_prefix = singleword.substr(0, numberinit); //Record prefix word_detail.originword = singleword; worditer = mapWord.find(word_prefix); //Whether there is the same prefix in map if (worditer != mapWord.end()) { worditer->second.frequency++; //The word frequency plus one of the word if (strcmp(word_detail.originprefix.c_str(), worditer->second.originprefix.c_str())<0) //Find the lexicographic sorting earlier in the map { worditer->second.originprefix = word_detail.originprefix; } } else { mapWord.insert(pair<string, MyWord> (word_prefix, word_detail)); //If you can't find it, insert it in map } CounterPhrase(word_prefix, mapPharze); } void SearchFile(string folderpath, unordered_map<string,MyWord> &mapWord, unordered_map<string,Pharze> &mapPharze) //Traverse all files { char fileword; //The character used to store and read in a file bool isWord=false; string singleword; //It is used to record words when conditions are satisfied ifstream readfile; _finddata_t fileinfo; string deep_path = folderpath + "\\*.*"; //Find all the files in the current folder long Handle = _findfirst(deep_path.c_str(), &fileinfo); //Looking for the first file handle if (Handle == -1) //When the folder is empty, it returns directly { cout<<"The file is at the end"<<endl; return ; } do { if (fileinfo.attrib&_A_SUBDIR) { if ((strcmp(fileinfo.name, ".") != 0)&&(strcmp(fileinfo.name,"..")!=0)) //Used to determine whether or not a folder is a folder { string newpath = folderpath + "\\" + fileinfo.name; //If it is, then continue to call the function recursively SearchFile(newpath,mapWord,mapPharze); } } else { readfile.open(folderpath + "\\" + fileinfo.name); //Open the current folder if (!readfile.is_open()) { cout << folderpath+"\\"+fileinfo.name<<"fail to open" << endl; exit(1); system("pause"); } cout << folderpath+"\\"+ fileinfo.name << endl; while (!readfile.eof()) { fileword = readfile.get();//Take a word out of the document CounterCharacter(fileword); if (isWord) //Judge whether the word has been made up. { if (JudgeLetter(fileword) || JudgeNumber(fileword)) { singleword = singleword + fileword; } else { isWord = false; //No words can be made up again CounterWord(singleword, mapWord, mapPharze); //Transfer words singleword.clear(); } } else { if (JudgeLetter(fileword)) { g_circle--; if (singleword.empty()) { singleword = fileword; } else { singleword = singleword + fileword; } } else { g_circle = 4; singleword.clear(); } if (g_circle == 0) //The description has met the 4 consecutive characters as the English alphabet { isWord = true; g_circle = 4; } } } if (fileword != '\n') g_LineNumber++; //A file used to consider only one line without a newline character cout << folderpath + "\\" + fileinfo.name << "已经打开完成" << endl; readfile.close(); } } while (_findnext(Handle, &fileinfo) != -1); _findclose(Handle); } void WPSort(unordered_map<string, MyWord> &mapWord, unordered_map<string, Pharze> &mapPharze,string path) //Words and phrases with the highest statistical frequency { ofstream write; string word[10]; //Record 10 most frequent words int wordfrequency[10] = { 0 }; //Record the number of the 10 most frequent words string pharze[10]; //Record 10 most frequent phrases int pharsefrequency[10] = { 0 }; //Record the number of 10 most frequent phrases unordered_map<string, MyWord>::iterator worditer; unordered_map<string, Pharze>::iterator pharzeiter; unordered_map<string, Pharze>::iterator pmax; //Used to record the largest pharze in each round sort unordered_map<string, MyWord>::iterator wmax; //Used to record the largest word in each round sort unordered_map<string, MyWord>::iterator findorigin1; //To retrieve the original word, 1 represents the first word, 2 represents second words. unordered_map<string, MyWord>::iterator findorigin2; bool isPlacew=false; //TO judge whether word has been placed bool isPlacep = false; write.open(path+"\\"+"Result.txt"); for (int i = 0; i < 10; i++) { for (pharzeiter = mapPharze.begin(); pharzeiter != mapPharze.end(); pharzeiter++) { if (pharzeiter->second.frequency > pharsefrequency[i]) { findorigin1 = mapWord.find(pharzeiter->second.firstword); findorigin2 = mapWord.find(pharzeiter->second.secondword); pharzeiter->second.originword = findorigin1->second.originprefix + " " + findorigin2->second.originprefix; pharsefrequency[i] = pharzeiter->second.frequency; pharze[i] = pharzeiter->second.originword; pmax = pharzeiter; isPlacew = true; } } if (isPlacew) { mapPharze.erase(pmax); isPlacew = false; } } for (int i = 0; i < 10;i++) { for (worditer = mapWord.begin(); worditer != mapWord.end(); worditer++) { if (worditer->second.frequency > wordfrequency[i]) { wordfrequency[i] = worditer->second.frequency; word[i] = worditer->second.originprefix; wmax = worditer; isPlacep = true; } } if (isPlacep) { mapWord.erase(wmax); isPlacep = false; } } write << "Line Number" << g_LineNumber << endl; write << "Character Number" << g_CharacterNumber << endl; write << "Word Number" << g_Wordnumber << endl; write << "<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<" << endl; //The following are the things stored in the txt file write << "The number of word" << endl; for (int i =0; i < 10; i++) { if (!word[i].empty()) { cout << word[i] << " " << wordfrequency[i] << endl; write << word[i] << " " << wordfrequency[i] << endl; } else { cout << "The number of word is less than ten and has benn enumerated completely" << endl; write << "The number of word is less than ten and has benn enumerated completely" << endl; break; } } write << endl; write << endl; write << "<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<" << endl; write << "The number of pharze" << endl; for (int i = 0; i < 10; i++) { if (!pharze[i].empty()) { cout << pharze[i] << " " << pharsefrequency[i] << endl; write << pharze[i] << " " << pharsefrequency[i] << endl; } else { cout << "The number of pharze is less than ten, and has benn enumerated completely" << endl; write << "The number of pharze is less than ten, and has benn enumerated completely" << endl; break; } } } int main(int argc,char **argv) //Get the folder path with the command line parameters { string path = argv[1]; //Path command line unordered_map<string, Pharze> mapPharze; unordered_map<string, MyWord> mapWord; g_pharsesample.frequency = 1; //Initial variables for initializing phrases SearchFile(path,mapWord,mapPharze); WPSort(mapWord, mapPharze,path); cout << "行数总数"<<g_LineNumber << endl; cout << "字符总数" << g_CharacterNumber << endl; cout << "单词总数" << g_Wordnumber << endl; system("pause"); return 0; }
- map
- 优点:
- 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
- 红黑树,内部实现一个红黑书使得map的很多操作在的时间复杂度下就可以实现,因此效率非常的高
- 缺点:
- 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间
- 适用处,对于那些有顺序要求的问题,用map会更高效一些
- 优点:
- unordered_map
- 优点:
- 因为内部实现了哈希表,因此其查找速度非常的快
- 缺点:
- 哈希表的建立比较耗费时间
- 优点:
void WordMerge(unordered_map<string, MyWord> &mapWord) { unordered_map<string, MyWord>::iterator worditer; unordered_map<string, MyWord>::iterator worditer_s; for (worditer = mapWord.begin(); worditer != mapWord.end(); worditer++) { for (worditer_s = mapWord.begin(); worditer_s != mapWord.end(); worditer_s++) //Conversion case { if (JudgeCase(worditer->first, worditer_s->first)) { worditer->second.frequency = worditer_s->second.frequency+worditer->second.frequency; worditer_s->second.frequency = 0; worditer_s->second.Maxword = worditer->first; } } } }
但加入了这个函数后,我发现我的程序不对劲了,其运行时间变为了原来的十倍。我仔细想了想,调试分析,终于发现了哪里不对劲。我的map中存储的单词数目为差不多10W,若做双重循环,那就是要进行10W*10W=10亿次循环!可以说是很恐怖的一个数字了。幸运的是,在ddl截止前,我想到了一个更好的合并方法。
这次,我在结构体中增加了一个string变量originprefix,用于储存单词的原始的前缀。我在统计单词的函数中,将原始单词的前缀全部存入了originprefix中,之后,把单词的前缀全部转化为小写,作为关键字,然后进行map插入,同时如果发现map中有相同的关键字,则比较originprefix,如果map中的关键字的originprefix比较大,则把它替换掉,否则,不做替换,单纯的将频率加一。
就这样经过一个轻微的结构体的改动,我避免了做10亿次循环的蠢事。让程序的运行时间大大削减为原来的十分之一!
附上改动后的源代码:
void CounterWord(string singleword, unordered_map<string, MyWord> &mapWord, unordered_map<string, Pharze> &mapPharze) //Count the total number of words and the number of words and phrases { if (size(singleword) > 1024) { return; } int wordend = 0; //Used to record the end of the word int numberinit = 0; //Used to record the starting position of a number in a word string word_prefix; //Used to record prefixes of words MyWord word_detail; //Used to record full words and frequencies unordered_map<string,MyWord>::iterator worditer; word_detail.frequency = 1; g_Wordnumber++; wordend = size(singleword); for (numberinit = wordend-1; JudgeNumber(singleword.at(numberinit)); numberinit--){} numberinit++; //Find the starting position of the number word_detail.originprefix= singleword.substr(0, numberinit); for (int i = 0; i < numberinit; i++) { if ((singleword.at(i) <= 'Z') && (singleword.at(i) >= 'A')) { singleword.at(i) = singleword.at(i) + 32; } } word_prefix = singleword.substr(0, numberinit); //Record prefix word_detail.originword = singleword; worditer = mapWord.find(word_prefix); //Whether there is the same prefix in map if (worditer != mapWord.end()) { worditer->second.frequency++; //The word frequency plus one of the word if (strcmp(word_detail.originprefix.c_str(), worditer->second.originprefix.c_str())<0) //Find the lexicographic sorting earlier in the map { worditer->second.originprefix = word_detail.originprefix; } } else { mapWord.insert(pair<string, MyWord> (word_prefix, word_detail)); //If you can't find it, insert it in map } CounterPhrase(word_prefix, mapPharze); }
三:测试
①测试一行十多万个字符的文件:
发现使用getline()函数读取文件有局限性,不能设置足够大的数组,详情见下文。
②字符较少的单个文件测试
发现程序崩溃了。仔细排查内容,发现原来是进行频率排序时,我默认了单词数,词组数大于10,从而导致设置的字符串数组并不能都储存有单词与数组,而我在最后访问的时候又访问了这些未初始化字符串的数组,由此导致了访问错误,引起了程序崩溃。
改进方法:增加字符串数组是否为空的检验。
③空白txt文件测试
出现的问题和字符较少的单个文件测试一样,增加安全性检验后,问题得到了解决。
④乱七八糟的文件格式的单个测试
测试了jpeg,js,java,html......等等文件,都可以正常运行。
⑤大样本测试:
使用大样本测试时,大概功能没有差错
四:一些整个作业过程中遇到的困难与总结
困难1:“.”与“..”是什么鬼
在调用函数遍历文件夹的时候,我使用的是_findfrst以及_findnext函数,并且我设置了一个打印文件名字的语句,用来观察有哪些文件以及文件的打开次序。其中,我发现了在打印语句输出时,会输出名字为"."以及“..”的文件,刚开始时,我以为这是代表文件夹的意思,于是,在编写遍历文件夹的语句时候,我不断的试图读取进入“.”与“..”文件夹。显然,结果是我的程序陷入了死循环,输出了错误信息。后来,我请教室友才知道,原来“.”代表的是当前文件夹,你用读取进入它就相当于在当前文件夹无限循环下去,而“..”则代表的是上一层文件夹,读取它则会跳到上一层。而且,查找这两个文件的属性,发现居然还是文件夹。因此,在遍历文件夹时,遇到这两个文件名,都需要跳过,否则程序要么崩溃要么输出错误答案。
困难2: 如何储存单词,哈希或map?
历经千辛万苦,我解决了文件夹遍历的问题,终于能开始编码后续的计算单词以及词组的功能了。然后没高兴多久,我又发现了一件事情不对头。我要统计不同单词的数目,但是文件那么多,单词千变万化,面对这种未知的情况,很难去设置数组,而且,设置了一堆很大的数组后,还要在数组内一个一个的查找单词,想一想就让人头皮发麻。正在我不知所措的时候,室友又给了我一个建议,用哈希表或者C++的map功能。我想了想上学期学的数据结构,觉得哈希的构造太麻烦了,还要用拉链法,或是重定址法,为冲突的解决费一番心思。最后,我选择了用map,原因有三,一是其效率高,查找的时间复杂度只有log(n),二是其查找插入删除操作简单,便于同时一对一储存关键字以及统计的次数。三是在其中还可以用string类型变量,string字符串变量的拷贝以及截取操作比字符数组的操作方便多了。
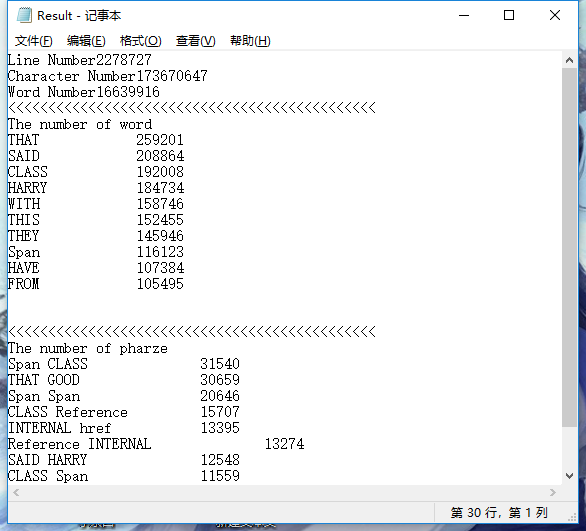
困难3:当file.geline()碰上一行二十多万字的文件
一阵爆肝,我终于解决了单词的统计问题,于是我兴高采烈地的用开始用file.getline函数读取我所打开的文件,我刚开始的打算是一行一行的读取文件的内容,然后存到一个字符串中,再将该字符串传给数单词的函数。我在QQ群上听说文本编译器大多一行最多只有1024个字符,为此,我设置了一个2000容量的字符数组,用于存放所存取的行。但是,在跑程序的过程中,我发现程序死活不动了,于是,我便又添加了一些输出命令,来观察文件的打开与读取情况。然后,我发现程序在打开searchindex.js,只显示已经打开该文件,而没有显示该文件已经读取完成。原来,程序就是在这里跑飞了。我在测试样本里找到了这个文件,并用txt格式打开了,然后发现里面的字符还真是密密麻麻的一大串,当时的第一反应是觉得字符串设置的太小了,于是,字符串大小从2000加到10W,但发现还是继续卡在了这个文件里。我又一怒之下加到了100W,结果发现编译器直接提示我内存访问错误。之后,我又好几次打开了这个文件的txt格式,心里觉得不对劲,在txt格式中,直观上感觉这个文件一行并没有十多万行字符。于是我换了一个文档打开器,Notepad++,这下终于发现问题了。原来,这个文件只有一行,而且一行有20多万字,记事本可以说是很坑人了。如下图所示。

一行二十多万个字符,用数组记录一行的字符看来是不可能了,于是,我只能换了一种读取文件的方式,那就是使用file.get()函数来读取。这也意味着,我又得忍痛刚写好的单词统计函数又得大改一通。唉,都是构造结构的时候没想好极端情况,没做好准备带来的苦果。
困难4:release与debugg
又是一通爆肝,程序终于写完了,结果发现跑一遍要一个小时,然后又听同学说,他们只要十多二十秒,顿时把我吓到了。幸运的是,有同学在这个时候建议我使用release来运行程序。果然,在我使用release运行程序后,程序运行时间下降到了几分钟。后来,我了解到,使用debugg来运行程序是一条一条语句执行的,而release则是经过了底层优化,使用多指令并发运行的模式,大大缩减了程序运行时间。
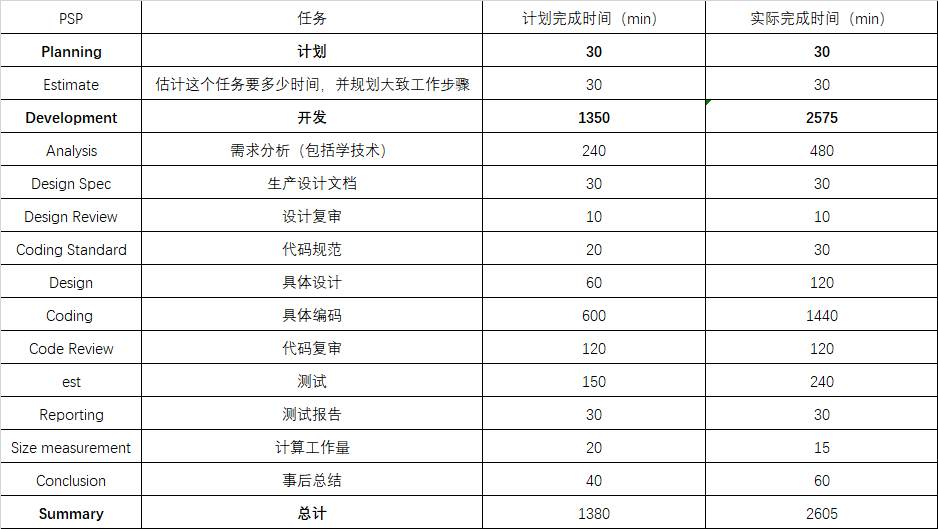
附上PSP图:
总结:架构不好,方向不对,越努力,越尴尬。储备不够,思维僵化,不知起手,事倍功半。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号