三维点集拟合:平面拟合、RANSAC、ICP算法
ACM算法分类:http://www.kuqin.com/algorithm/20080229/4071.html
一: 拟合一个平面:使用SVD分解,代码里面去找吧
空间平面方程的一般表达式为:
Ax+By+Cz+D=0;
则有:
平面法向量为n=(A,B,C).
第一种方法: 对于空间中n个点(n3)
空间中的离散点得到拟合平面,其实这就是一个最优化的过程。即求这些点到某个平面距离最小和的问题。由此,我们知道一个先验消息,那就是该平面一定会过众散点的平均值。接着我们需要做的工作就是求这个平面的法向量。
注意:这个方法是直接的计算方法,没办法解决数值计算遇到的病态矩阵问题.在公式转化代码之前必须对空间点坐标进行近似归一化!
第二种方法:使用法线方法, 对于空间中n个点(n3),若已获得点云法线
若在已经获得法线的点云中,可以对法线进行剔除离散点之后,求取最小方差的均值,直接求得法线方向N( alpha, beta, theta );
使用点法式描述三维平面;或者根据形心P和法线方向,计算出平面方程的一般式。
使用法线多次聚类:完成场景平面提取
使用法线两次聚类:第一次根据法线方向进行聚类,使用一个欧式距离约束,找出方向接近的簇S(1),这样得到的S(1)内的集合,每一类指向了大致相同的方向,但距离上并不一定接近;第二次,再次根据点云的空间位置进行聚类,对S(1)的每一簇内再次进行基于距离的聚类,找出每一簇内位置接近的类别,这样再次对集合进行划分,得到的每一类方向大致相同,而位置较近,可以假设为一个平面的点。
此外,若考虑到平面密度要求,还可以再根据密度进行一次聚类,把密度较低的平面从集合中踢出去。
(2):空间向量的旋转:
2-D绕原点旋转变换矩阵是:
[cosA sinA] [cosA -sinA] [-sinA cosA] 或者 [sinA cosA]
2-D绕任意一点旋转变换矩阵是:
[x y 1] [1 0 0] [cosA sinA 0] [1 0 0] [x' y' -] [0 1 0] x [0 1 0] x [-sinA cosA 0] x [0 1 0] = [- - -] [0 0 1] [rtx rty 1] [0 0 1] [-rtx -rty 1] [- - -]
二:利用Ransac算法进行拟合
作者:王先荣 原文链接:http://www.cnblogs.com/xrwang/archive/2011/03/09/ransac-1.html
本文翻译自维基百科,英文原文地址是:http://en.wikipedia.org/wiki/ransac,如果您英语不错,建议您直接查看原文。
RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。该算法最早由Fischler和Bolles于1981年提出。
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;(2)“局外点”是不能适应该模型的数据;(3)除此之外的数据属于噪声。
局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。
本文内容
1 示例2 概述3 算法4 参数5 优点与缺点6 应用7 参考文献8 外部链接
一、示例
一个简单的例子是从一组观测数据中找出合适的2维直线。假设观测数据中包含局内点和局外点,其中局内点近似的被直线所通过,而局外点远离于直线。简单的最小二乘法不能找到适应于局内点的直线,原因是最小二乘法尽量去适应包括局外点在内的所有点。相反,RANSAC能得出一个仅仅用局内点计算出模型,并且概率还足够高。但是,RANSAC并不能保证结果一定正确,为了保证算法有足够高的合理概率,我们必须小心的选择算法的参数。


左图:包含很多局外点的数据集 右图:RANSAC找到的直线(局外点并不影响结果)
二、概述
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为它仅仅被初始的假设局内点估计过。
5.最后,通过估计局内点与模型的错误率来评估模型。
这个过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
三、算法
伪码形式的算法如下所示:
输入:
data —— 一组观测数据
model —— 适应于数据的模型
n —— 适用于模型的最少数据个数
k —— 算法的迭代次数
t —— 用于决定数据是否适应于模型的阀值
d —— 判定模型是否适用于数据集的数据数目
输出:
best_model —— 跟数据最匹配的模型参数(如果没有找到好的模型,返回null)
best_consensus_set —— 估计出模型的数据点
best_error —— 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
RANSAC算法的可能变化包括以下几种:
(1)如果发现了一种足够好的模型(该模型有足够小的错误率),则跳出主循环。这样可能会节约计算额外参数的时间。
(2)直接从maybe_model计算this_error,而不从consensus_set重新估计模型。这样可能会节约比较两种模型错误的时间,但可能会对噪声更敏感。
四、参数
我们不得不根据特定的问题和数据集通过实验来确定参数t和d。然而参数k(迭代次数)可以从理论结果推断。当我们从估计模型参数时,用p表示一些迭代过程中从数据集内随机选取出的点均为局内点的概率;此时,结果模型很可能有用,因此p也表征了算法产生有用结果的概率。用w表示每次从数据集中选取一个局内点的概率,如下式所示:
我们对上式的两边取对数,得出

为了得到更可信的参数,标准偏差或它的乘积可以被加到k上。k的标准偏差定义为:

五、优点与缺点
RANSAC的优点是它能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。
RANSAC的缺点是它计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。
RANSAC的另一个缺点是它要求设置跟问题相关的阀值。
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
六、应用
RANSAC算法经常用于计算机视觉,例如同时求解相关问题与估计立体摄像机的基础矩阵。
三、 点云匹配:ICP算法(Iterative Closest Point迭代最近点)
参考链接:机器视觉之 ICP算法和RANSAC算法:http://www.cnblogs.com/yin52133/archive/2012/07/21/2602562.html
ICP(Iterative Closest Point迭代最近点)算法是一种点集对点集配准方法,
如下图,假设PR(红色块)和RB(蓝色块)是两个点集,该算法就是计算怎么把PB平移旋转,使PB和PR尽量重叠,建立模型的Alignment模型。
 (图1)
(图1)
ICP是改进自对应点集配准算法的对应点集配准算法是假设一个理想状况,将一个模型点云数据X(如上图的PB)利用四元数 旋转,并平移
旋转,并平移 得到点云P(类似于上图的PR)。而对应点集配准算法主要就是怎么计算出qR和qT的,知道这两个就可以匹配点云了。
得到点云P(类似于上图的PR)。而对应点集配准算法主要就是怎么计算出qR和qT的,知道这两个就可以匹配点云了。
但是对应点集配准算法的前提条件是计算中的点云数据PB和PR的元素一一对应,这个条件在现实里因误差等问题,不太可能实线,所以就有了ICP算法(我们无从知道两个点集之间的匹配关系,只能认为距离最近的点为同一个,所以此方法为迭代最近点)。
ICP算法是从源点云上的(PB)每个点 先计算出目标点云(PR)的每个点的距离,使每个点和目标云的最近点匹配。
这样满足了对应点集配准算法的前提条件、每个点都有了对应的映射点,则可以按照对应点集配准算法计算,但因为这个是假设,所以需要重复迭代运行上述过程,直到均方差误差小于某个阀值。
也就是说 每次迭代,整个模型是靠近一点,每次都重新找最近点,然后再根据对应点集批准算法算一次,比较均方差误差,如果不满足就继续迭代。
ICP的求解方法:
把ICP方法看做一个点云位姿变换的过程,可以使用代数方法和非线性优化方法。
假设有两堆点云,分别记为两个集合X=x1,x2,...,xm和Y=y1,y2,...,ym(m并不总是等于n)。
ICP公式为:
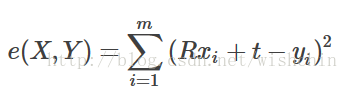
1.SVD等代数方法
先构建误差矩阵,构建最小二乘问题,求使得误差平方和最小的点云旋转和位移R,T。
初始化估计:ICP发展了多年之后,当然有很多的方法来估计初始的R和t,PCL自己的函数 SampleConsensusInitalAlignment 函数以及TransformationEstimationSVD函数 都可以得到较好的初始估计。
优化:得到初始化估计之后仍然存在误差问题,RANSAC之后,若已存在完全正确匹配,则可以再次求取旋转的essential矩阵,通过SVD分解得到最终旋转R和平移t。
2.非线性优化方法
RANSAC算法之后,去除掉 外点之后。
使用位姿的代数变化转换构建一个误差项,在非线性优化过程中不停地迭代,一般能找到极小值。
后记:
在去除外点,匹配已知的情况下,ICP的最小二乘问题总会得到一个最优解,即ICP的SVD方法总会有一个解析解。
(二)RANSAC算法与ICP算法对比(RANdom SAmple Consensus随机抽样一致)
它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。该算法最早由Fischler和Bolles于1981年提出。
光看文字还是太抽象了,我们再用图描述
RANSAC的基本假设是:(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;(2)“局外点”是不能适应该模型的数据;(3)除此之外的数据属于噪声。
而下图二里面、蓝色部分为局内点,而红色部分就是局外点,而这个算法要算出的就是蓝色部分那个模型的参数
 (图二)
(图二)
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
在上图二中 左半部分灰色的点为观测数据,一个可以解释或者适应于观测数据的参数化模型 我们可以在这个图定义为一条直线,如y=kx + b;
一些可信的参数指的就是指定的局内点范围。而k,和b就是我们需要用RANSAC算法求出来的
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为它仅仅被初始的假设局内点估计过。
5.最后,通过估计局内点与模型的错误率来评估模型。
这个过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
这个算法用图二的例子说明就是先随机找到内点,计算k1和b1,再用这个模型算其他内点是不是也满足y=k1x+b2,评估模型
再跟后面的两个随机的内点算出来的k2和b2比较模型评估值,不停迭代最后找到最优点
我再用图一的模型说明一下ICP算法
(图1)
ICP算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
旋转,并平移区别:
ICP算法在迭代的时候,点对是已经匹配的;RANSAC算法在迭代的时候,点匹配对是随着优化函数改变的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号