SIFT算法总结:用于图像搜索
原始文章链接:http://bubblexc.com/y2011/163/ 原文链接:http://blog.csdn.net/cserchen/article/details/5606859
关于三种特征点检测的对比:http://blog.csdn.net/cy513/article/details/4285579
利用SURF特征点进行检测(有code):http://www.cnblogs.com/tornadomeet/archive/2012/08/17/2644903.html
利用特征点进行定位:http://www.jdl.ac.cn/project/faceId/res-landmarks.htm
有少许改动......参考这个文章是因为要找到实时的3D检测描绘子,对于图像,sift系列的有很好的效果,对于3维图像,相当于添加一个灰度通道,期待有很好的效果。不过从直觉上来看,成功的概率还是很小的。所以我不想实验这个特征了...
推荐搜索系列:http://blog.csdn.net/cserchen/article/category/785155
(1): 算法介绍:
SIFT算法由D.G.Lowe 1999年提出,2004年完善总结,论文发表在2004年的IJCV上:
David G. Lowe, "Distinctive image features from scale-invariant keypoints,"International Journal of Computer Vision, 60, 2 (2004), pp. 91-110
论文的原文可见:
http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
后来Y.Ke将其描述子部分用PCA代替直方图的方式,对其进行改进。
SIFT方法一经推出就在图像处理界引起巨大反响,其方法效果良好、实现便捷,很快风靡世界。很多图像检测、识别的应用里都能找到sift方法的身影
SIFT算法是一种提取局部特征的算法,在尺度空间寻找极值点,提取位置,尺度,旋转不变量。算法的主要特点为:
a) SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
b) 独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配[23]。
c) 多量性,即使少数的几个物体也可以产生大量SIFT特征向量。
d) 高速性,经优化的SIFT匹配算法甚至可以达到实时的要求。
e) 可扩展性,可以很方便的与其他形式的特征向量进行联合。
SIFT算法主要步骤:
1) 检测尺度空间极值点
2) 精确定位极值点
3) 为每个关键点指定方向参数
4) 关键点描述子的生成
SIFT算法详细
尺度空间理论目的是模拟图像数据的多尺度特征。 高斯卷积核是实现尺度变换的唯一线性核,于是一副二维图像的尺度空间定义为:
L(x,y,e) = G(x,y,e)*I(x,y)
其中G(x,y,e)是尺度可变高斯函数,
G(x,y,e) = [1/2*pi*e2] * exp[ -(x2 + y2)/2e2]
(x,y)是空间坐标, e是尺度坐标。
为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。
D(x,y,e) = ((G(x,y,ke) - G(x,y,e)) * I(x,y) = L(x,y,ke) - L(x,y,e)
DOG算子计算简单,是尺度归一化的LoG算子的近似 :
http://blog.csdn.net/abcjennifer/article/details/7639488
Gaussian卷积是有尺寸大小的,使用同一尺寸的滤波器对两幅包含有不同尺寸的同一物体的图像求局部最值将有可能出现一方求得最值而另一方却没有的情况,但是容易知道假如物体的尺寸都一致的话它们的局部最值将会相 同。SIFT的精妙之处在于采用图像金字塔的方法解决这一问题,我们可以把两幅图像想象成是连续的,分别以它们作为底面作四棱锥,就像金字塔,那么每一个 截面与原图像相似,那么两个金字塔中必然会有包含大小一致的物体的无穷个截面,但应用只能是离散的,所以我们只能构造有限层,层数越多当然越好,但处理时 间会相应增加,层数太少不行,因为向下采样的截面中可能找不到尺寸大小一致的两个物体的图像。有了图像金字塔就可以对每一层求出局部最值,但是这样的稳定
点数目将会十分可观,所以需要使用某种方法抑制去除一部分点,但又使得同一尺度下的稳定点得以保存
图像金字塔的构建:图像金字塔共O组,每组有S层,下一组的图像由上一组图像降采样得到。

图1 Two octaves of a Gaussian scale-space image pyramid with s =2 intervals. The first image in the second octave is created by down sampling the second to last image in the previous
图2 The difference of two adjacent intervals in the Gaussian scale-space pyramid create an interval in the difference-of-Gaussian pyramid (shown in green).
空间极值点检测
为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图3所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。
构建尺度空间需确定的参数
e -尺度空间坐标
O -octave坐标
S - sub-level 坐标
注:octaves 的索引可能是负的。第一组索引常常设为0或者-1,当设为-1的时候,图像在计算高斯尺度空间前先扩大一倍。
空间坐标x是组octave的函数,设 是0组的空间坐标,注:在Lowe的文章中,Lowe使用了如下的参数:
在组o=-1,图像用双线性插值扩大一倍(对于扩大的图像 )。
精确确定极值点位置
通过拟和三维二次函数以精确确定关键点的位置和尺度(达到亚像素精度),同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力。
边缘响应的去除
一个定义不好的高斯差分算子的极值在横跨边缘的地方有较大的主曲率,而在垂直边缘的方向有较小的主曲率。主曲率通过一个2x2 的Hessian矩阵H求出:
导数由采样点相邻差估计得到。
D的主曲率和H的特征值成正比,令为最大特征值
关键点方向分配
利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性。
在实际计算时,我们在以关键点为中心的邻域窗口内采样,并用直方图统计邻域像素的梯度方向。梯度直方图的范围是0~360度,其中每10度一个柱,总共36个柱。直方图的峰值则代表了该关键点处邻域梯度的主方向,即作为该关键点的方向。图4是采用7个柱时使用梯度直方图为关键点确定主方向的示例。

图4 由梯度方向直方图确定主梯度方向
在梯度方向直方图中,当存在另一个相当于主峰值80%能量的峰值时,则将这个方向认为是该关键点的辅方向。一个关键点可能会被指定具有多个方向(一个主方向,一个以上辅方向),这可以增强匹配的鲁棒性[53]。
至此,图像的关键点已检测完毕,每个关键点有三个信息:位置、所处尺度、方向。由此可以确定一个SIFT特征区域(在实验章节用椭圆或箭头表示)。 陈运文
特征点描述子生成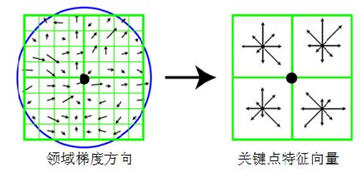
由关键点邻域梯度信息生成特征向量
接下来以关键点为中心取8×8的窗口。图5-4左部分的中央黑点为当前关键点的位置,每个小格代表关键点邻域所在尺度空间的一个像素,箭头方向代表该像素的梯度方向,箭头长度代表梯度模值,图中蓝色的圈代表高斯加权的范围(越靠近关键点的像素梯度方向信息贡献越大)。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点,如图5右部分所示。此图中一个关键点由2×2共4个种子点组成,每个种子点有8个方向向量信息。这种邻域方向性信息联合的思想增强了算法抗噪声的能力,同时对于含有定位误差的特征匹配也提供了较好的容错性。
实际计算过程中,为了增强匹配的稳健性,Lowe建议对每个关键点使用4×4共16个种子点来描述,这样对于一个关键点就可以产生128个数据,即最终形成128维的SIFT特征向量。此时SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则可以进一步去除光照变化的影响。
当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。
SIFT算法的实际匹配效果如下:

(2):SIFT的应用范围:
鉴于sift的特征点检测和特征描述的详细描述,sift的特征检测用于大规模图像检索准确率应该不是很高。图像检索必须走到图像语义层,至于这个鸿沟用什么样的方法填平,还是很值得商酌的事情。搜索最重要的难题是
根据SIFT对关键点周围的特征描述,sift检测用于图像旋转配准 最能发挥它的作用。
SIFT算法在图像搜索方面,用作基础特征,个人感觉有一些问题,记录在这里:
1 求主方向阶段太过依赖图像局部像素的梯度方向,有可能使找到的主方向不准确;而后面的特征向量以及匹配严重依赖主方向,一旦有偏差效果会显著下降
2 图层金字塔的层如何取是个问题,如果取得不够紧密,会在匹配时出现偏差;而如果取的过多,造成keypointer数量过大,则会带来很大的计算负担
3 图像中大片平滑区域时,由于会过滤掉低对比度的点,因此特征点的提取有问题;
4 高维向量如何构建倒排索引并实现近似检索,是个难题;VA-file+ 的方法并不能完全解决问题
-----------------------------------
针对我们可能的应用,我觉得解决上述问题可以有以下思路:
问题1:我们的应用不需要处理很强的旋转不变性(rotation-invairant)问题,
可以将主方向寻找步骤省略,直接在keypointer周围区域进行特征向量提取
问题2:考虑设置统一的缩放尺度,解决匹配问题
问题3:除了SIFT descriptor本身以外,还需要提取一些像素区域的统计信息,作为补充特征
问题4:借鉴一些本文倒排索引和搜索的技术,这块非常复杂,可能需要多级搜索,实现由粗到精的检索策略,还需摸索

 浙公网安备 33010602011771号
浙公网安备 33010602011771号