


三维重建面试0:*SLAM滤波方法的串联综述
知乎上的提问,高翔作了回答:能否简单并且易懂地介绍一下多个基于滤波方法的SLAM算法原理?
写的比较通顺,抄之。如有异议,请拜访原文。如有侵权,请联系删除。
要讲清这个问题,得从状态估计理论来说。先摆上一句名言:
状态估计乃传感器之本质。(To understand the need for state estimation is to understand the nature of sensors.)
任何传感器,激光也好,视觉也好,整个SLAM系统也好,要解决的问题只有一个:如何通过数据来估计自身状态。每种传感器的测量模型不一样,它们的精度也不一样。换句话说,状态估计问题,也就是“如何最好地使用传感器数据”。可以说,SLAM是状态估计的一个特例。
=====================离散时间系统的状态估计======================
记机器人在各时刻的状态为,其中
是离散时间下标。在SLAM中,我们通常要估计机器人的位置,那么系统的状态就指的是机器人的位姿。用两个方程来描述状态估计问题:
解释一下变量:-运动方程
- 输入
- 输入噪声
- 观测方程
- 观测数据
- 观测噪声
运动方程描述了状态是怎么变到
的,而观测方程描述的是从
是怎么得到观察数据
的。
请注意这是一种抽象的写法。当你有实际的机器人,实际的传感器时,方程的形式就会变得具体,也就是所谓的参数化。例如,当我们关心机器人空间位置时,可以取。进而,机器人携带了里程计,能够得到两个时间间隔中的相对运动,像这样
,那么运动方程就变为:
同理,观测方程也随传感器的具体信息而变。
例如激光传感器可以得到空间点离机器人的距离和角度,记为,那么观测方程为:
,其中
是一个2D路标点。
举这几个例子是为了说明,运动方程和观测方程具体形式是会变化的。但是,我们想讨论更一般的问题:当我不限制传感器的具体形式时,能否设计一种方式,从已知的(输入和观测数据)从,估计出
呢?
这就是最一般的状态估计问题。我们会根据是否线性,把它们分为线性/非线性系统。同时,对于噪声
,根据它们是否为高斯分布,分为高斯/非高斯噪声系统。最一般的,也是最困难的问题,是非线性-非高斯(NLNG,
Nonlinear-Non Gaussian)的状态估计。下面先说最简单的情况:线性高斯系统。
=====================线性高斯系统============================
线性高斯系统(LG,Linear Gaussian)
在线性高斯系统中,运动方程、观测方程是线性的,且两个噪声项服从零均值的高斯分布。这是最简单的情况。简单在哪里呢?主要是因为高斯分布经过线性变换之后仍为高斯分布。而对于一个高斯分布,只要计算出它的一阶和二阶矩,就可以描述它(高斯分布只有两个参数)。
线性系统形式如下:
其中
是两个噪声项的协方差矩阵。
为转移矩阵和观测矩阵。
对LG系统,可以用贝叶斯法则,计算的后验概率分布——这条路直接通向卡尔曼滤波器。卡尔曼是线性系统的递推形式(recursive,也就是从
估计
)的无偏最优估计。由于解释EKF和UKF都得用它,所以我们来推一推。如果读者不感兴趣,可以跳过公式推导环节。
符号:用表示
的后验概率,用
表示它的先验概率。因为系统是线性的,噪声是高斯的,所以状态也服从高斯分布,需要计算它的均值和协方差矩阵。记第
时刻的状态服从:
我们希望得到状态变量的最大后验估计(MAP,Maximize a Posterior),于是计算:
第二行是贝叶斯法则,第三行分母和无关所以去掉。
第一项即观测方程,有:,很简单。
第二项即运动方程,有:,也很简单。
现在的问题是如何求解这个最大化问题。对于高斯分布,最大化问题可以变成最小化它的负对数。当我对一个高斯分布取负对数时,它的指数项变成了一个二次项,而前面的因子则变为一个无关的常数项,可以略掉(这部分我不敲了,有疑问的同学可以问)。于是,定义以下形式的最小化函数:
那么最大后验估计就等价于:
这个问题现在是二次项和的形式,写成矩阵形式会更加清晰。定义:
就得到矩阵形式的,类似最小二乘的问题:
于是令它的导数为零,得到:
(*)
读者会问,这个问题和卡尔曼滤波有什么问题呢?事实上,卡尔曼滤波就是递推地求解(*)式的过程。所谓递推,就是只用来计算
。对(*)进行Cholesky分解,就可以推出卡尔曼滤波器。详细过程限于篇幅就不推了,把卡尔曼的结论写一下:
前两个是预测,第三个是卡尔曼增益,四五是校正。
另一方面,能否直接求解(*)式,得到呢?答案是可以的,而且这就是优化方法(batch optimization)的思路:将所有的状态放在一个向量里,进行求解。与卡尔曼滤波不同的是,在估计前面时刻的状态(如
)时,会用到后面时刻的信息(
等)。从这点来说,优化方法和卡尔曼处理信息的方式是相当不同的。
==================扩展卡尔曼滤波器===================
线性高斯系统当然性质很好啦,但许多现实世界中的系统都不是线性的,状态和噪声也不是高斯分布的。例如上面举的激光观测方程就不是线性的。当系统为非线性的时候,会发生什么呢?
一件悲剧的事情是:高斯分布经过非线性变换后,不再是高斯分布。而且,是个什么分布,基本说不上来。(摊手)
如果没有高斯分布,上面说的那些都不再成立了。于是EKF说,嘛,我们睁一只眼闭一只眼,用高斯分布去近似它,并且,在工作点附近对系统进行线性化。当然这个近似是很成问题的,有什么问题我们之后再说。
EKF的做法主要有两点。其一,在工作点附近,对系统进行线性近似化:
这里的几个偏导数,都在工作点处取值。于是呢,它就被活生生地当成了一个线性系统。
第二,在线性系统近似下,把噪声项和状态都当成了高斯分布。这样,只要估计它们的均值和协方差矩阵,就可以描述状态了。经过这样的近似之后呢,后续工作都和卡尔曼滤波是一样的了。所以EKF是卡尔曼滤波在NLNG系统下的直接扩展(所以叫扩展卡尔曼嘛)。EKF给出的公式和卡尔曼是一致的,用线性化之后的矩阵去代替卡尔曼滤波器里的转移矩阵和观测矩阵即可。
其中
考虑一个服从高斯分布的变量
我概率比较差,不过这个似乎是叫做卡尔方布。
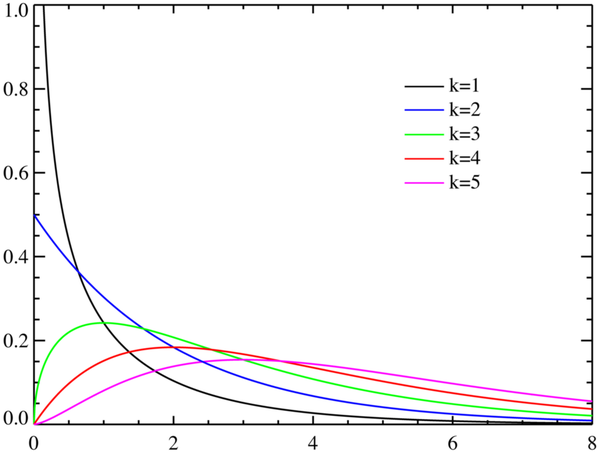
但是按照EKF的观点,我们要用一个高斯分布去近似。假设我们采样时得到了一个
,那么就会近似成一个均值为0.25的高斯分布,然而卡方分布的期望应该是1。……但是各位真觉得k=1那条线像哪个高斯分布吗?
- 即使是高斯分布,经过一个非线性变换后也不是高斯分布。EKF只计算均值与协方差,是在用高斯近似这个非线性变换后的结果。(实际中这个近似可能很差)。
- 系统本身线性化过程中,丢掉了高阶项。
- 线性化的工作点往往不是输入状态真实的均值,而是一个估计的均值。于是,在这个工作点下计算的
,也不是最好的。
- 在估计非线性输出的均值时,EKF算的是
的形式。这个结果几乎不会是输出分布的真正期望值。协方差也是同理。
那么,怎么克服以上的缺点呢?途径很多,主要看我们想不想维持EKF的假设。如果我们比较乖,希望维持高斯分布假设,可以这样子改:
- 为了克服第3条工作点的问题,我们以EKF估计的结果为工作点,重新计算一遍EKF,直到这个工作点变化够小。是为迭代EKF(Iterated EKF, IEKF)。
- 为了克服第4条,我们除了计算
如果不那么乖,可以说:我们不要高斯分布假设,凭什么要用高斯去近似一个长得根本不高斯的分布呢?于是问题变为,丢掉高斯假设后,怎么描述输出函数的分布就成了一个问题。一种比较暴力的方式是:用足够多的采样点,来表达输出的分布。这种蒙特卡洛的方式,也就是粒子滤波的思路。
如果再进一步,可以丢弃滤波器思路,说:为什么要用前一个时刻的值来估计下一个时刻呢?我们可以把所有状态看成变量,把运动方程和观测方程看成变量间的约束,构造误差函数,然后最小化这个误差的二次型。这样就会得到非线性优化的方法,在SLAM里就走向图优化那条路上去了。不过,非线性优化也需要对误差函数不断地求梯度,并根据梯度方向迭代,因而局部线性化是不可避免的。
可以看到,在这个过程中,我们逐渐放宽了假设。
由于题主问题里没谈IEKF,我们就简单说说UKF和PF。
UKF主要解决一个高斯分布经过非线性变换后,怎么用另一个高斯分布近似它。假设
UKF的做法是找一些叫做Sigma Point的点,把这些点用
 这里选了三个点:
这里选了三个点:- 不必线性化,也不必求导,对
没有光滑性要求。
- 计算量随维数增长是线性的。
=============== PF 粒子滤波 (蒙特卡洛方法)==================
UKF的一个问题是输出仍假设成高斯分布。然而,即使在很简单的情况下,高斯的非线性变换仍然不是高斯。并且,仅在很少的情况下,输出的分布有个名字(比如卡方),多数时候你都不知道他们是啥……更别提描述它们了。
因为描述很困难,所以粒子滤波器采用了一种暴力的,用大量采样点去描述这个分布的方法(老子就是无参的你来打我呀)。框架大概像下面这个样子,就是一个不断采样——算权重——重采样的过程:
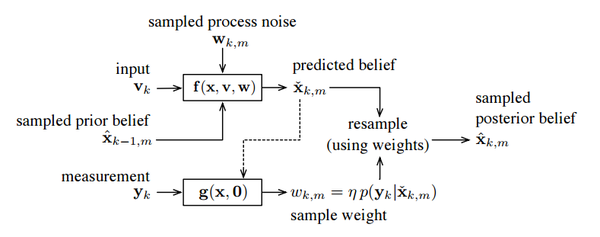
越符合观测的粒子拥有越大的权重,而权重越大就越容易在重采样时被采到。当然,每次采样数量、权重的计算策略,则是粒子滤波器里几个比较麻烦的问题,这里就不细讲了。
这种采样思路的最大问题是:采样所需的粒子数量,随分布是指数增长的。所以仅限于低维的问题,高维的基本就没办法了。
=============== 非线性优化 ==================
非线性优化,计算的也是最大后验概率估计(MAP),但它的处理方式与滤波器不同。对于上面写的状态估计问题,可以简单地构造误差项:
然后最小化这些误差项的二次型:
这里仅用到了噪声项满足高斯分布的假设,再没有更多的了。当构建一个非线性优化问题之后,就可以从一个初始值出发,计算梯度(或二阶梯度),优化这个目标函数。常见的梯度下降策略有牛顿法、高斯-牛顿法、Levenberg-Marquardt方法,可以在许多讲数值优化的书里找到。
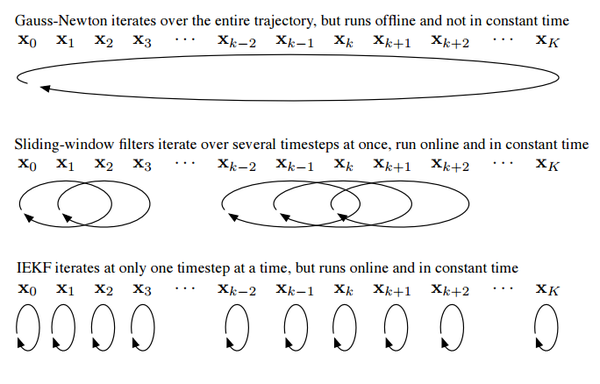
当然优化方式也存在它的问题。例如优化时间会随着节点数量增长——所以有人会提double window optimization这样的方式,以及可能落入局部极小。但是就目前而言,它比EKF还是优不少的。
=============== 小结 ==================- 卡尔曼滤波是递归的线性高斯系统最优估计。
- EKF将NLNG系统在工作点附近近似为LG进行处理。
- IEKF对工作点进行迭代。
- UKF没有线性化近似,而是把sigma point进行非线性变换后再用高斯近似。
- PF去掉高斯假设,以粒子作为采样点来描述分布。
- 优化方式同时考虑所有帧间约束,迭代线性化求解。
呃好像题主还问了FastSLAM,有空再写吧……
注:* 本文大量观点来自Timothy. Barfoot, "State estimation for Robotics: A Matrix Lei Group Approach", 2016. 图片若有侵权望告知。
