ZfNet解卷积:可视化CNN模型( PythonCode可视化Cifar10)
原文链接:caffe Model的可视化 snapshot: 6000
一个在线可视化小工具:http://blog.csdn.net/10km/article/details/52713027
Place205 Model集结地:http://places.csail.mit.edu/downloadCNN.html
参考文章:深度学习之可视化-ZfNet去卷积
前言
由来已久,ANN方法被称为模式识别里面的“黑盒”方法,因为ANN模型不能使用明确的函数——形式化的数学公式进行表示,同时也意味着应对评价模型,面对函数寻求最优解的优化方程也不能形式化表示。
基于NN的分层堆叠性,NN即使以特定结构三层网便可以以任意精度逼近任意非线性函数,也同时表示函数形式在NN中的难以形式化。K曾经证明(1957),在单位超立方体内的任意连续函数,都可以选择适当的参数展开为两级级数求和问题。后来的研究发现,任意一个从x到y的映射,都存在一个合适的三层神经网络以任意的精度逼近它。
反过来看,从神经网络结构和参数,去描述函数的一个形式,涉及到拟合问题,是个不确定问题。进而以此归结出基于模型函数的优化函数,则是不可能完成的事情。从这个角度上看来,NN是个语义和语法的黑箱。好在对于学习来说,形式化是非必须的,可形式化的SVM也面临着核函数的形式化难题,而CNN可以从语义层次进行解析,以弥补语法不能完备的缺憾。
ZFNet思想及过程
从科学的观点出发,如果不能归纳,只能进行遍历。如果不知道神经网络为什么取得了如此好的效果,那么只能靠不停的实验来寻找更好的模型。
ZFNet使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
反卷积可视化:
一个卷积层加一个对应的反卷积层;
输入是feature map,输出是图像像素;
过程包括反池化操作、relu和反卷积过程。
反池化:
严格意义上的反池化是无法实现的。作者采用近似的实现,在训练过程中记录每一个池化操作的一个z*z的区域内输入的最大值的位置,这样在反池化的时候,就将最大值返回到其应该在的位置,其他位置的值补0。
relu纠正:
卷积神经网络使用relu非线性函数来保证输出的feature map总是为正数。在反卷积的时候,也需要保证每一层的feature map都是正值,所以这里还是使用relu作为非线性激活函数。
滤波:
使用原卷积核的转秩和feature map进行卷积。反卷积其实是一个误导,这里真正的名字就是转秩卷积操作。反卷积网中利用卷积网中的相同的滤波器的转置应用到纠正过的特征图中,而不是上层的输出。也就是对滤波器进行水平方向和垂直方向的翻转。从高层向下投影使用转换变量switch,这个转化变量switch产生自向上的卷积网的最大池化操作。由于重建由一个单独的激活获得,因此也就只对应于原始输入图像的一小块。
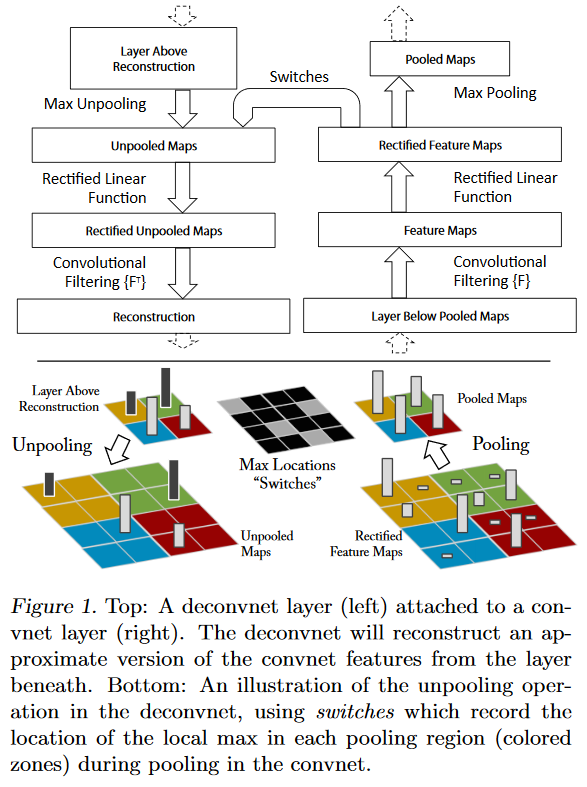
上图左半部分是一个解卷积层,右半部分为一个卷积层。解卷积层将会重建一个来自下一层的卷积特征近似版本。图中使用switc来记录在卷积网中进行最大池化操作时每个池化区域的局部最大值的位置,经过非池化操作之后,原来的非最大值的位置都置为0。
特征可视化:
每个特征单独投影到像素空间揭露了不同的结构能刺激不同的一个给定的特征图,因此展示了它对于变形的输入内在的不变性。下图即在一个已经训练好的网络中可视化后的图。

上图所示是训练结束后,模型各个隐藏层提取的特征,图所示的是给定输出特征时,反卷积产生的最强的9个输入特征。将这些计算所得的特征,用像素空间表示后,可以清晰地看出:一组特定的输入特征(通过重构获得),将刺激卷积网产生一个固定的输出特征。图2的右边是对应的输入图片,和重构特征相比,输入图片和其之间的差异性很大,而重构特征只包含那些具有判别能力的纹理结构。例如,第5层第1行第2列的9张输入图片各不相同差异很大,而对应的重构输入特征则都显示了背景中的草地,没有显示五花八门的前景。
每一层的可视化结果都展示了网络的层次化特点。第2层展示了物体的边缘和轮廓,以及与颜色的组合,第3层拥有了更复杂的不变性,主要展示了相似的纹理,第4层不同组重构特征存在着重大差异性,开始体现了类与类之间的差异,第5层每组图片都展示了存在重大差异的一类物体。
训练过程中的feature变化:
外表突然的变化导致图像中的一个变换即产生了最强烈的激活。模型的底层在少数几个epoches就能收敛聚集,然而上层在一个相当多的epoches(40-50)之后才能有所变化,这显示了让模型完全训练到完全收敛的必要性。可以由下图看到颜色对比度都逐步增强。

特征不变性
下图所示,5个不同的例子,它们分别被平移、旋转和缩放。图5右边显示了不同层特征向量所具有的不变性能力。在第一层,很小的微变都会导致输出特征变化明显,但是越往高层走,平移和尺度变化对最终结果的影响越小,网络的输出对于平移和尺度变化都是稳定的。卷积网无法对旋转操作产生不变性,除非物体具有很强的对称性,看似是个伪命题。
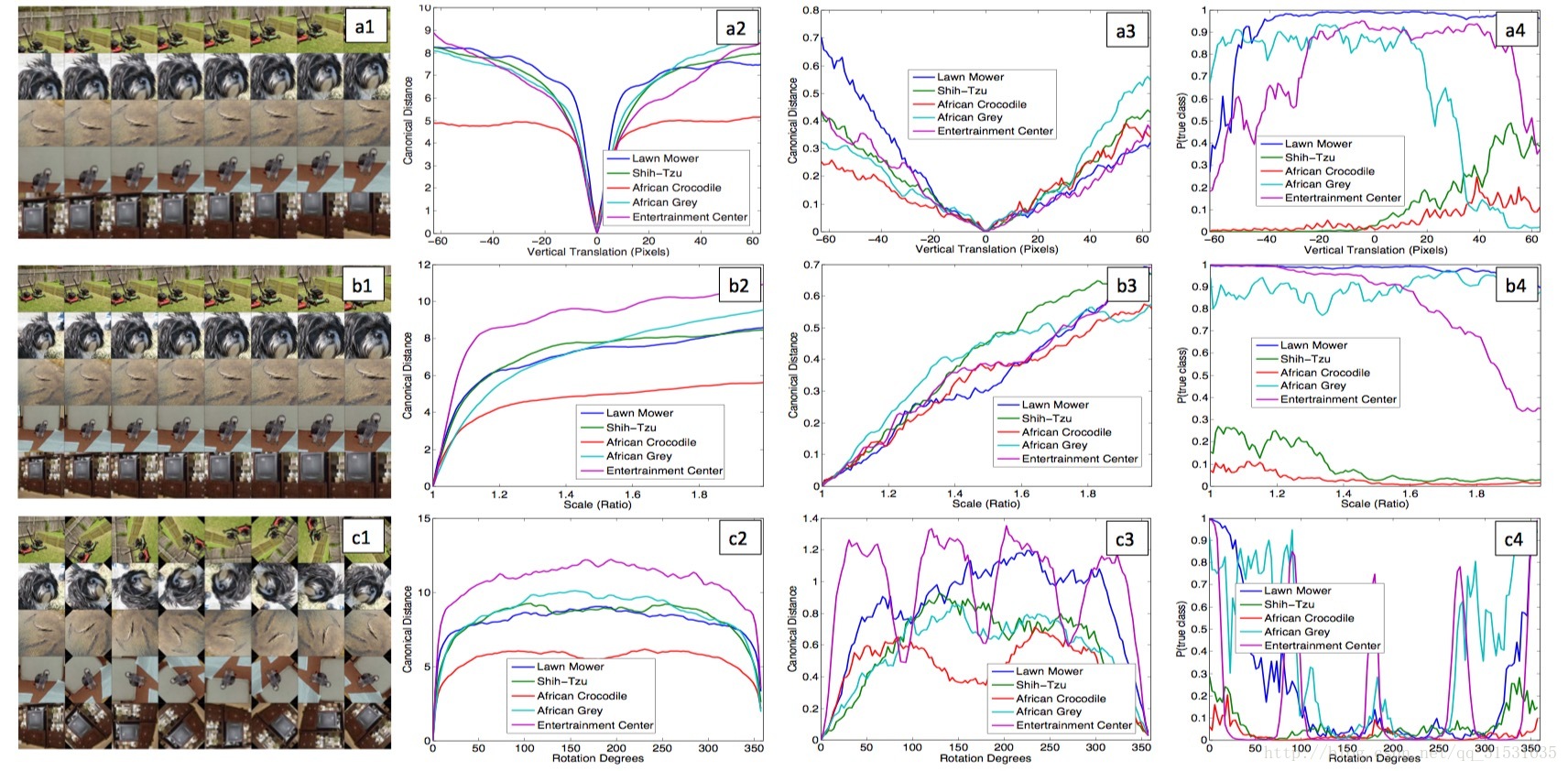
同类不同图像的一致性分析
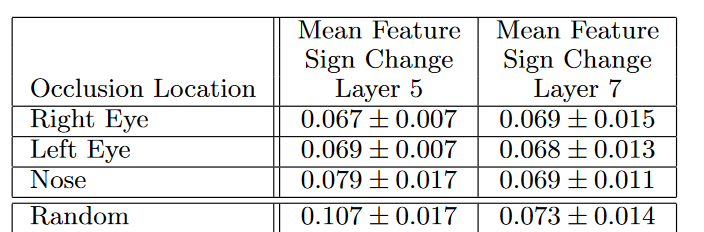
对五张小狗(同一类)的不同图片的不同区域进行掩盖,然后进行分析观察探究深度模型是对一类物体的那部分进行一致性分析的过程...............

第5层随机遮挡的情况比其他眼睛鼻子被遮挡的情况一致性分析较差,而第7层中,这四类却都差不多,那是因为底层判别的是一类物体共有的部分,而高层判别的是类别中不同的品种这种更高维的部分了。
迁移学习的可行性
把预训练的CNN模型用于新的场景,是迁移学习的应用表现。底层CNN-featureMap的通用性为这种移动提供了一个有力的实验支持。迁移学习一般从复杂模型迁移到简单模型,且一般使用迁移模型的底层部分,高层模型需要进行重建。
PythonCode
code1.训练Cifar10网络
下载Cifar10的数据集:得到
mean.binaryproto 文件
cifar10_test_lmdb cifar10_train_lmdb 文件夹,把三个文件和目录,复制到examples\cifar10 目录
建立CMD文件 cifar10_train_full.cmd 到工程的根目录,与example平级
内容为:D:\Works\CNN\MsCaffe\Build\x64\Release/caffe.exe train --solver=examples/cifar10/cifar10_quick_solver.prototxt
pause
运行cmd命令
训练结果:
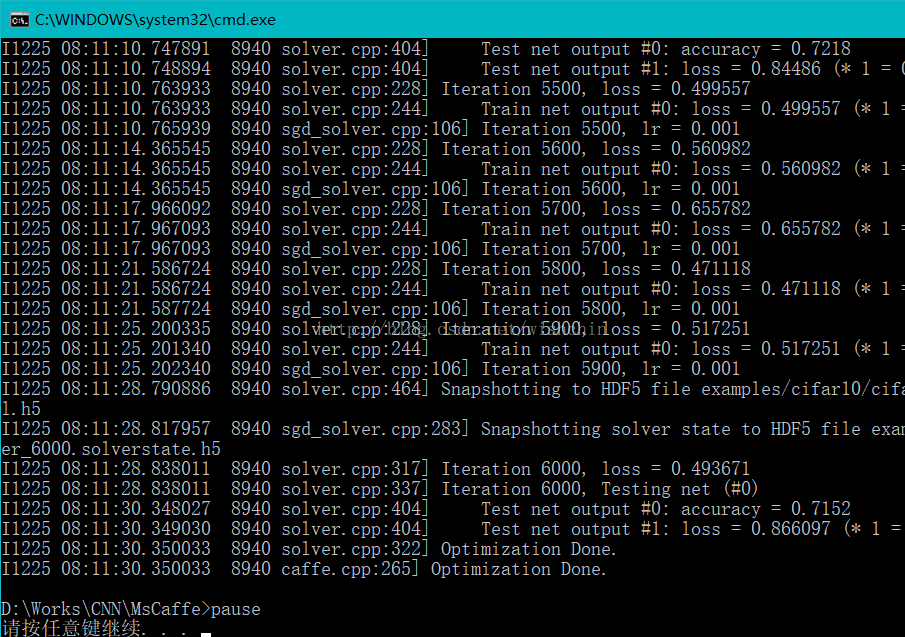
生成结果到 examples/cifar10/根目录,生成了H5后缀的训练模型。
2. 可视化Caffe model
在Eclipse工程中,添加一个py文件,内容为:
#coding=utf-8
"""
Caffe visualize
Display and Visualization Functions and caffe model.
Copyright (c) 2017 Matterport, Inc.
Licensed under the MIT License (see LICENSE for details)
Written by wishchin yang
MayBe I should use jupyter notebook
"""
import numpy as np
import matplotlib.pyplot as plt
import os,sys,caffe
#%matplotlib inline
#编写一个函数,用于显示各层的参数
def show_feature(data, padsize=1, padval=0):
data -= data.min();
data /= data.max();
# force the number of filters to be square
n = int(np.ceil(np.sqrt(data.shape[0])));
padding = ((0, n ** 2 - data.shape[0]), (0, padsize), (0, padsize)) + ((0, 0),) * (data.ndim - 3);
data = np.pad(data, padding, mode='constant', constant_values=(padval, padval));
# tile the filters into an image
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)));
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:]);
plt.imshow(data);
plt.axis('off');
#第一个实例,测试cifar10模型
def mainex():
caffe_root='D:/Works/CNN/MsCaffe/';
os.chdir(caffe_root);
sys.path.insert(0,caffe_root+'python');
plt.rcParams['figure.figsize'] = (8, 8);
plt.rcParams['image.interpolation'] = 'nearest';
plt.rcParams['image.cmap'] = 'gray';
net = caffe.Net(caffe_root + 'examples/cifar10/cifar10_quick_train_test.prototxt',
caffe_root + 'examples/cifar10/cifar10_quick_iter_4000.caffemodel.h5',
caffe.TEST);
[(k, v[0].data.shape) for k, v in net.params.items()];
# 第一个卷积层,参数规模为(32,3,5,5),即32个5*5的3通道filter
weight = net.params["conv1"][0].data
print(weight.shape);
show_feature(weight.transpose(0, 2, 3, 1));
# 第二个卷积层的权值参数,共有32*32个filter,每个filter大小为5*5
weight = net.params["conv2"][0].data;
print weight.shape;
show_feature( weight.reshape(32**2, 5, 5) );
# 第三个卷积层的权值,共有64*32个filter,每个filter大小为5*5,取其前1024个进行可视化
weight = net.params["conv3"][0].data ;
print weight.shape ;
show_feature(weight.reshape(64*32, 5, 5)[:1024]);
if __name__ == '__main__':
import argparse
mainex(); 调试运行.............................................
结果显示:
conv1层 conv2层
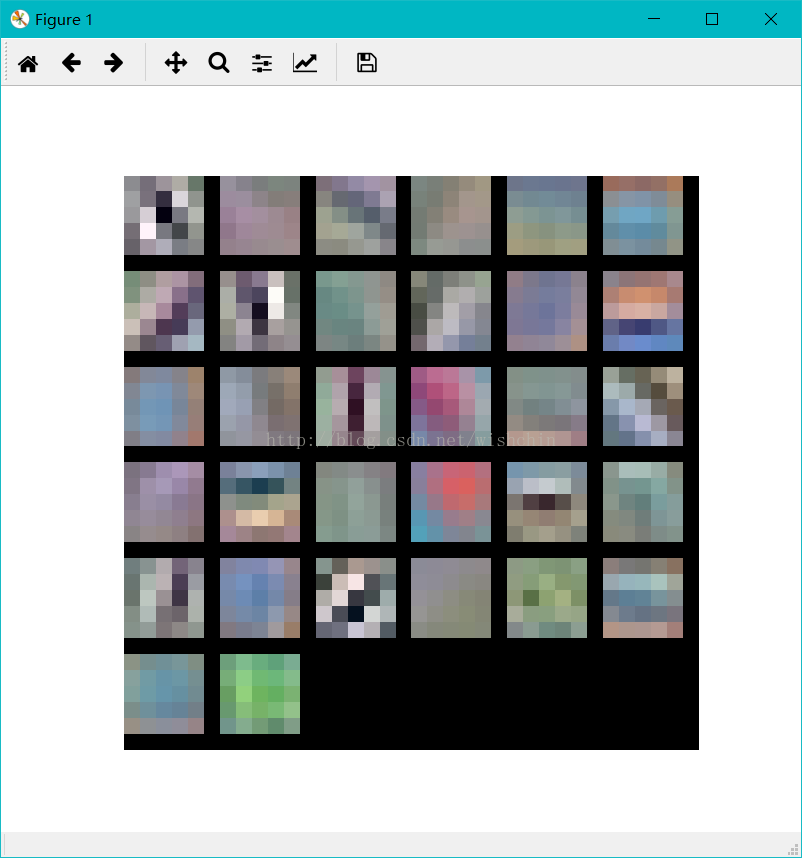
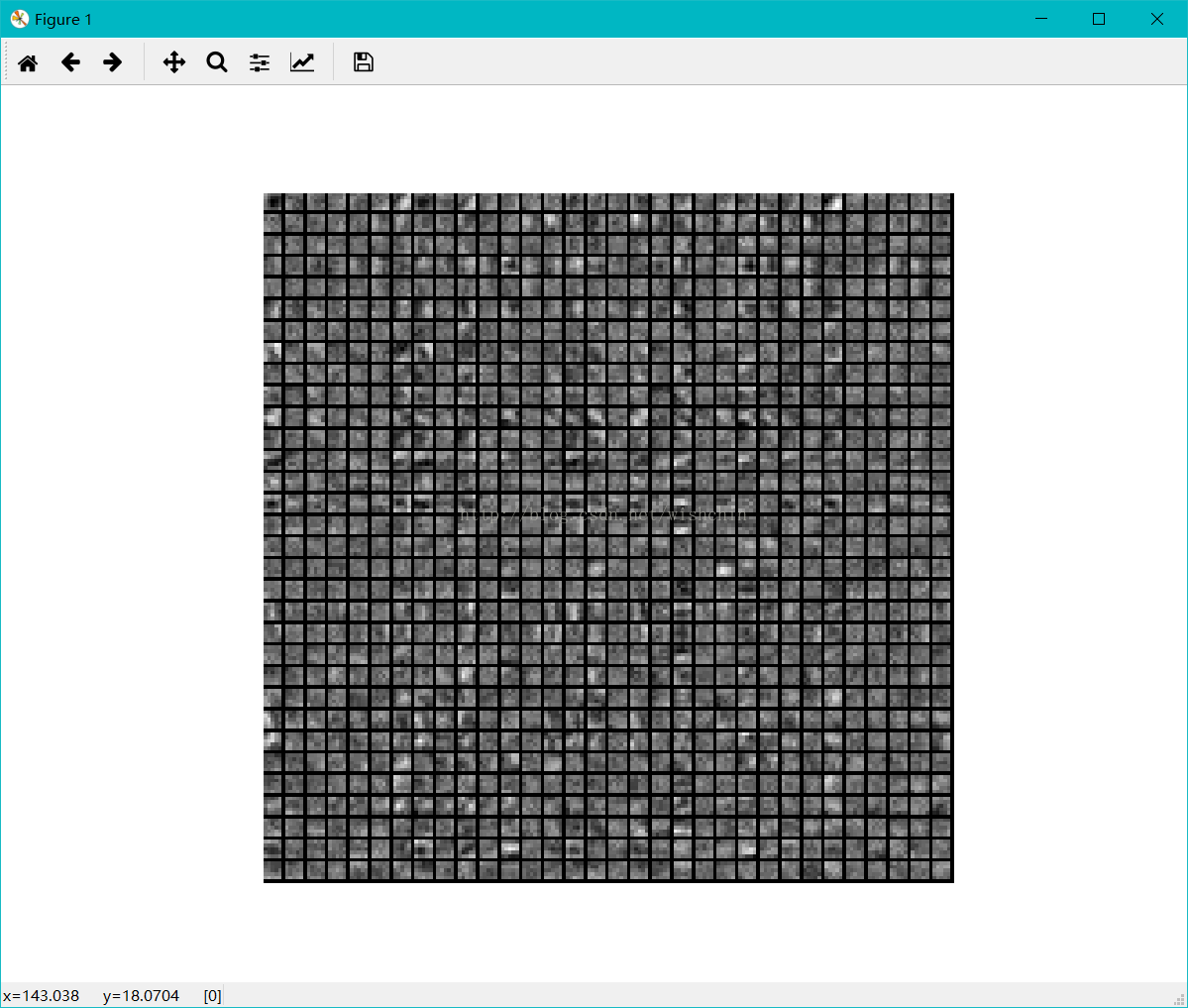
结果分析:迭代4000次训练的结果不是特别好,并没有训练得到明显的底层特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号