
白盒-CNN纹理深度可视化: 使用MIT Place 场景预训练模型
MIT发文:深度视觉的量化表示................
Places2 是一个场景图像数据集,包含 1千万张 图片,400多个不同类型的场景环境,可用于以场景和环境为应用内容的视觉认知任务。
GitHub源代码:https://github.com/CSAILVision/NetDissect
论文地址:http://netdissect.csail.mit.edu/final-network-dissection.pdf
Place205 Model集结地;http://places.csail.mit.edu/downloadCNN.html ,Place205模型给出了205个场景的分析。
一个在线可视化小工具:http://blog.csdn.net/10km/article/details/52713027
launch editor之后,把网络结构直接copy到editor,shift+enter 可视化。
Caffe Model ZOO:https://github.com/BVLC/caffe/wiki/Model-Zoo#places-cnn-model-from-mit
关于可视化
基于Caffe结构的网络连接可视化,理论上你可以自己写一个.
Scene Recognition Demo: Input a picture of a place or scene and see how our Places-CNN predicts it.
DrawCNN: a visualization of units’ connection for CNNs.
Indoor/Outdoor label: the label of indoor and outdoor for each of the 205 place categories. You could use the labels of the top5 predicted place categories from the Places-CNN to vote if the given image is indoor or outdoor. The indoor and outdoor classification accuracy is more than 95%.
所谓黑箱
ML的传统方法被称为“白盒方法”,而神经网络被称为“黑箱”。
关于黑箱的一个解释:题主的『可解释性』不是指泛化性等理论保证,也不是复杂模型的理论解释。而是指『判别过程是否可以转化成具备逻辑关系的规则』。更新回答如下:
1. 如果想把决策结果解释成规则,那么建议使用基于决策树的机器学习模型/算法(包括原始的各种决策树、一些利用了ensemble的决策树模型,比如random forest等),这样得到的结果可以理解成依据特征做的一系列选择,也许就满足了你们产品经理的喜好。但是,实际中如果决策树得到的规则太多的话,其实也不是有很好的『解释性』。
2. 关于题主提到的『选择权重大的特征作为白盒规则,得到的效果一定好吗?』,实用中很可能会有不错的效果,这大概可以看做是最原始的特征选择方法,也有可能大大降低准确度。
3. 你为啥这么在乎产品经理的感受?是白盒还是黑盒真的有这么重要?毕竟最后的你『选择用户』是你的模型和算法策略决定的,不是产品经理手工决定的。实际场景中,产品经理关心的很可能是用户画像这些方面,而非你的决策过程。
=====原答案======这要看题主要的可解释性是指什么?
所谓黑箱
相对于CNN和众多DNN方法,ML的传统方法被称为“白盒方法”,这种由来已久的观点是从数学模型可验证可优化性的角度来分析的。在众多ML方法中,布尔决策树方法是唯一的白盒方法,即给出了语法又给出了语义阐述,并等价于专家规则。一系列线性和非线性方法之所以被称为是“白盒方法”,是因为其方程的明确形式化。不管是贝叶斯方法、还是线性判别、以至于各种非线性模型或者生成式模型,都可以明确地归结为函数形式,这意味着ML模型是可显示优化的,即结果是可进行定理论证的。我们看着结果到最优化的方向迭代,便以为我们明了了真实的意义;我们掌握了语法,便以为解释了语义。
众多NN方法难以从神经元模型汇总,抽取出一个形式化的函数,因此也不能针对函数进行优化,给出最优解或者最优方向的证明,可行的一个方法即是随机初始加通过反向传播调参反复迭代。CNN的特别之处在于卷积核的存在,卷积过程是一个反向模板匹配的过程,而这个模板,是可以看见的。在CNN网络中,每一层都是可以看见的。CONV层效果占比越多的网络,可视化表达能力越强。
可表示性:ResNet > VGG >GoogLeNet > AlexNet
借用一张图:
关于深度 可视化的解释
高层和中层语义可视化,此回答作了一个(地址):小小的翻译...
CVPR'17 Oral论文Network Dissection: Quantifying Interpretability of Deep Visual Representations(论文:https://arxiv.org/pdf/1704.05796.pdf, 主页:http://netdissect.csail.mit.edu/)
神经网络的可解释性一直是我比较关注的问题。从ICLR'15那篇Object Detectors emerge from Deep Scene CNNs (现在的深度学习的模型越来越大,有个结论是说,大脑的激活是非常稀疏的,对模型参数有什么好的办法压缩吗? - 知乎), 到CVPR'16的CNN Discriminative Localization and Saliency,再到最新的这篇Network Dissection,算是我PhD阶段较完整地探索了这个问题。我自己是非常喜欢这篇network dissection:)。
了解我研究工作的朋友都知道,我很少提fancy的模型和跟踪潮流topic,我更感兴趣的是分析问题和现象本身,能用越普适的方法越好。这篇CVPR'17工作是想更好量化分析不同卷积神经网络内部神经元的语义特征 (Network Interpretability and Network Explainability)。尝试回答一些有意思的问题:神经网络是不是只是个black box?神经网络内部到底学习了些什么东西?为什么需要这么深度的网络?等等。之前我ICLR'15论文是用人力来标定了AlexNet的每层网络内神经元的语义性,这篇论文我们提出了一个叫Network Dissection的方法,可以自动化地标定任意给定的网络内部的带有语义的神经元。
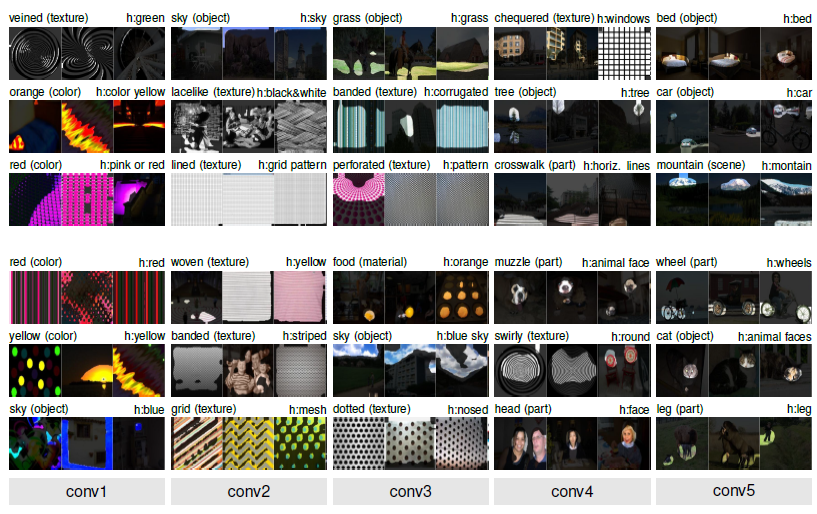
Network Dissection大致做法如下图所示,我们准备了一个带有不同语义概念的图片数据库,里面每张图都有pixel-wise的标定(颜色,纹理,场景,物体部分,物体等),然后我们把每个神经元在图像上的激活响应当做对这些概念进行语义分割(Semantic segmentation),然后看每个神经元对哪个语义概念分割得最好,那么这个神经元就是在检测这个语义概念。

Network Dissection项目网页上(http://netdissect.csail.mit.edu),有对不同网络的详细可视化(参见Network Dissection Results),感兴趣的同学可以看看。数据库和代码已经release(CSAILVision/NetDissect)。到时候在CVPR'17的Tutorial上 (Deep Learning for Objects and Scenes),我也会把Network Interpretability作为一个专题来报告, stay tuned:)
总结来说,Network Interpretability & Explainability将是AI里非常重要的研究问题。去年美国政府的军费研究机构DARPA就有个重要的立项Explainable Artificial Intelligence。随着AI模型在生活中的广泛应用,性能提升的同时,人们也更关注AI模型自身的安全性和可解释性。如果连我们自己都无法理解AI模型是如何运作以及内部到底学习到了什么,还会放心AI模型在医疗,国防等一些性命攸关的方向应用么。最近MIT Tech Review上最近有篇文章,也分析了这个问题:The Dark Secret at the heart of AI(There’s a big problem with AI: even its creators can’t explain how it works)。
结论:
Place205主要使用AlexNet和VGG-Net用于场景分类,在网络结构上没有大的改进,暂时只是使用了专门的数据集对这个专门的模型进行了特定的优化。论文对语义化的实验数据也是对长久以来CNN模式识别的一个通用总结。
参考:
主页:http://netdissect.csail.mit.edu/
代码:https://github.com/CSAILVision/NetDissect
论文:https://arxiv.org/pdf/1704.05796.pdf

