

语音跟踪:信号分解、锁相、鸡尾酒会效应、基于PR的信号分离
NLP中关于语音的部分,其中重要的一点是语音信号从背景噪音中分离。比如在一个办公室场景中,有白天的底噪-类似于白噪音的噪音、空调的声音、键盘的啪啪声、左手边45度7米元的地方同事讨论的声音、右手边1.5米远处同事讨论的声音、打印机的声音。各种声音混杂在一起,从自然人的角度来分别,很容易做到区分各种声音。
以自然人的观点来看,不自觉的感知中使用了空间传播模型和声音模式识别,具体的机理暂时没能搞清楚。以一般人的能力看来,区分特定的人的声音是简单从容的,一般只要记得曾经听过即可。且可以在嘈杂的环境中持续的听清楚这个人的说话声。
在嘈杂的环境中,人们非常善于把注意力集中在某个特定的人身上,在心理上"屏蔽"所有其他语音和声音。这种能力被称为鸡尾酒会效应,它是我们人类与生俱来的本领。然而,尽管关于自动语音分离(将音频信号分离为单独的语音源)的研究已经非常深入,这个课题仍是计算机领域的一项重大挑战。
从声音到语义,以此经过音素分析、单词识别、句子识别、语义理解过程。
锁相环-信号跟踪
模式识别从另一个方面来源于自动化技术,主要研究控制系统的自动化仍为普遍的模式识别科学很多的启示。
信号分离是一种模式识别方案,锁相环是一个反馈控制系统,本应该不相交。不过语音信号分离可以看做一种语音信号的锁定和跟踪技术。 参考: 锁相环的基本组成和工作原理 。
锁相环路是一种反馈控制电路,简称锁相环(PLL)。锁相环的特点是:利用外部输入的参考信号控制环路内部振荡信号的频率和相位。
因锁相环可以实现输出信号频率对输入信号频率的自动跟踪,所以锁相环通常用于闭环跟踪电路。锁相环在工作的过程中,当输出信号的频率与输入信号的频率相等时,输出电压与输入电压保持固定的相位差值,即输出电压与输入电压的相位被锁住,这就是锁相环名称的由来。
锁相环通常由鉴相器(PD)、环路滤波器(LF)和压控振荡器(VCO)三部分组成,锁相环组成的原理框图如图8-4-1所示。
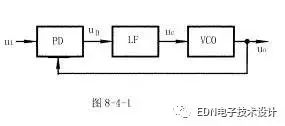
锁相环中的鉴相器又称为相位比较器,它的作用是检测输入信号和输出信号的相位差,并将检测出的相位差信号转换成uD(t)电压信号输出,该信号经低通滤波器滤波后形成压控振荡器的控制电压uC(t),对振荡器输出信号的频率实施控制。
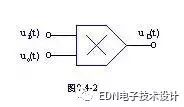
锁相环的应用:应用集中在以下三个方面:第一 信号的调制和解调;第二 信号的调频和解调;第三信号频率合成电路。
信号分离基础
信号分离的模式识别基础认知为模式分解的方法,一般可以把信号分解为更小尺度的基信号,通过基信号的组合模式进行模式识别。通过识别不同的模式来进行信号分离。
参考:信号分离研究内容基础1、;信号分离研究内容基础、2;讲解的通俗易懂。
到目前为止,我们将现有的信号分析方法分为6大类方法:
1、最大后验概率的方法MAP(Maximal aposterior probability)
2、基于稀疏性的表示方法 Sparsity based method:based onsparse representation(根源于小波的表示)
3、基于新的范数(度量)的方法,Norm based method:based on newnorm
4、经验的方法,Empirical method:EMD etc(告诉你怎么算,但是不知道怎么办)
5、变分框架分解方法,VMD
6、基于一些数学工具,Other method:basis,frame,ICA(小波基,框架,ICA)
(6)现有数学手段
基于数学工具的方法是大家用的最多,但是常常忘记的方法,如降维方法中的PCA,SVD方法,盲分离方法ICA,FastICA方法等等。几乎所有的降维算法都能用于信号分离,如流行学习的算法。同时包括一些框架的算法,这些方法就是传统数学理论的运用,这里就不多讲了。
最后总结下现有信号处理方法的现状和进展,以下个人观点,请辩证的阅读,如有错误,作者本人不承担任何责任。
- 时域分析--所有基于统计的方法。
- 频域--傅里叶变换(平稳信号处理方法)。
- 时频分析方法--窗口傅里叶变换STFT、时频分布方法(Winger-Ville、Cohen分布等等),小波方法WT,双树复数小波DTCWT,多小波Multi-WT,脊波变换等等(传统非平稳信号分析)
- EMD方法,LMD,LCD,ITD等方法,这些都是基于EMD方法本身,属于自适应非平稳信号处理方法。理论基础薄弱。
- 字典方法,SWT,EWT,这些方法都是基于字典或是小波框架的方法,但是具有自适应分析能力,也属于自适应非平稳信号处理方法。
- 稀疏时频分析的方法,这类方法是基于字典的优化方法,也是稀疏表达大类的方法,属于自适应非平稳分析方法。
- VMD方法,不讲了,讲过了。。。
- 还有很多。。。读者自行查阅相关文档
基于深度学习的语音分离
对于采样频率一般固定的声音采样,固定模式的声音因此是变长的,RNN的循环结构可以用于处理变长模型,基于保留残差改进为LSTM模型。
参考:搜狗研究员讲解基于深度学习的语音分离技术 。文章很长,慢慢地看。
技术词汇:频谱映射 方法
根据干扰的不同,语音分离任务可以分为三类:
当干扰为噪声信号时,可以称为 “语音增强”(Speech Enhancement)
当干扰为其他说话人时,可以称为 “多说话人分离”(Speaker Separation)
当干扰为目标说话人自己声音的反射波时,可以称为 “解混响”(De-reverberation)
由于麦克风采集到的声音中可能包括噪声、其他人说话的声音、混响等干扰,不做语音分离、直接进行识别的话,会影响到识别的准确率。因此在语音识别的前端加上语音分离技术,把目标说话人的声音和其它干扰分开就可以提高语音识别系统的鲁棒性,这从而也成为现代语音识别系统中不可或缺的一环。
基于深度学习的语音分离,主要是用基于深度学习的方法,从训练数据中学习语音、说话人和噪音的特征,从而实现语音分离的目标。
练目标包括两类,一类是基于 Mask 的方法,另一类是基于频谱映射的方法。
..............
如果使用频谱映射,分离问题就成为了一个回归问题。
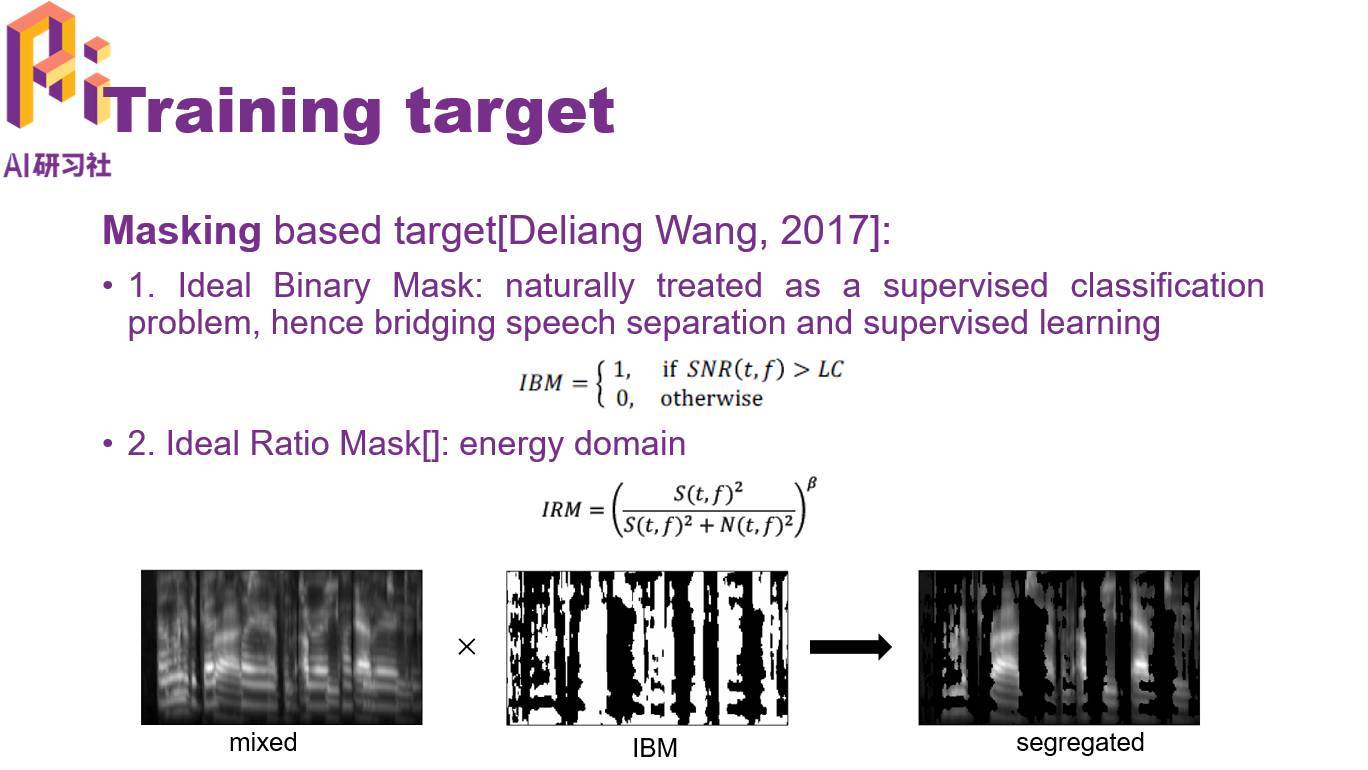
频谱映射可以使用幅度谱、功率谱、梅尔谱以及 Gammatone 功率谱。Gammatone 是模拟人耳耳蜗滤波后的特征。为了压缩参数的动态范围以及考虑人耳的听觉效应,通常还会加上对数操作,比如对数功率谱。
基于频谱映射的方法,是让模型通过有监督学习,自己学习有干扰的频谱到无干扰的频谱(干净语音)之间的映射关系;模型可以是 DNN、CNN、LSTM 甚至 GAN。
.......................
最后,文仕学给大家留了两个思考题,欢迎大家在评论区给出自己的见解。
第一个问题是语音分离任务中,是按传统思路先变换到频域,然后在频域上进行处理,还是直接在时域上处理比较好?后者的好处是端到端训练,不用考虑频域方法做傅立叶反变换时相位的问题。
第二个问题是对于语音增强任务,应该使用真实噪声加噪还是使用人工仿真生成的噪声进行降噪?
语音分离-噪声中分离
参考一个中文简介:语音分离-从噪声中分离,没有仔细看。
单声道语音分离,一般用到两种技术:语音增强,和计算听觉场景分析。
语音增强通过分析语音和噪声的一般统计量,从带噪语音中估计噪声,进而从带噪语音中减去噪声估计,得到目标语音。其中最简单的也是使用最广泛的技术是谱减,它估计噪声的功率谱,从带噪语音中减去噪声得到目标语音。
计算听觉场景分析模拟了人类听觉系统的场景分析过程,它将听觉场景分析分成分段(segmentation)和组织(grouping)两个步骤,首先利用时间连续性及谐波特性等信息,将语音信号分解成独立的来自于单个声源的片段,再根据语音基音(pitch)以及语音开始(onset)和结束位置(offset)等线索,将语音片段组织连接起来。这些连接起来的语音就是分离得到的目标语音。
GitHub上的开源代码:
GitHub项目:自然语言处理领域的相关干货整理
使用其他感知进行辅助
1.MIT提出像素级声源定位系统PixelPlayer:无监督地分离视频中的目标声源:
论文链接:https://arxiv.org/pdf/1804.03160.pdf
项目地址:http://sound-of-pixels.csail.mit.edu/
2. GoogleAI技术:google 指哪儿看哪儿,多重信号分离
论文地址:https://arxiv.org/pdf/1804.03619.pdf


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2017-06-01 Caffe2:ubuntuKylin17.04使用Caffe2.LSTM
2016-06-01 人脸Pose检测:ASM、AAM、CLM总结