AI:IPPR的数学表示-CNN稀疏结构进化(Mobile、xception、Shuffle、SE、Dilated、Deformable)
接上一篇:AI:IPPR的数学表示-CNN基础结构进化(Alex、ZF、Inception、Res、InceptionRes)。
抄自于各个博客,有大量修改,如有疑问,请移步各个原文.....
前言:AutoML-NasNet
VGG结构和INception结构、ResNet基元结构的出现,验证了通过反复堆叠小型inception结构可以构建大型CNN网络,而构建过程可以通过特定的规则自动完成。自动完成大型网络的稀疏性构建出现了一定的人为指导,如Mobile、xception、Shuffle、SE各个网络,另一方面是远未得到泛用性的AutoML自动搜索网络结构。
Google I/O开发者大会上,万恶的资本主义垄断公司全球私人信息的无耻把持者—美国谷歌,推出能自动设计机器学习模型的方法AutoML,想让神经网络更“平易近人”。虽然AutoML能设计出与人类设计的神经网络同等水平的小型神经网络,但始终被限制在CIFAR-10和Penn Treebank等小型数据集上。即使在CIFAR-10 等小型数据集上进行搜索CNN结构,仍然需要500块TESLA显卡的水准。
AutoML方法主要使用了強化學習和遷移學習。论文NAS-NeuralArchitecture Search With ReinforcementLearning的基础做了突破性的改进,使得能让机器在小数据集(CIFAR-10数据集)上自动设计出CNN网络,并利用迁移学习技术使得设计的网络能够被很好的迁移到ImageNet数据集,验证集上达到了82.7%的预测精度,同时也可以迁移到其他的计算机视觉任务上(如目标检测)。
至此,Google接近完成布局整个AI的基础设施,主推的中间件平台(机器学习框架)TensorFlow,向上延伸到直接面对问题域的自动生成结构框架AutoML,向下延伸到Android系统,以及硬件执行处理器TPU。这样,你只要给出问题描述和一部分数据,使用Google的服务可以一站式完成。这就意味着,只要哪天Google不爽了或者美国不爽了,Google不再给你服务,你将不仅连空中楼阁都不是,而是海市蜃楼。
神经网络结构自动搜索初探:
Neural Architecture Search with Reinforcement Learning(ICLR 2017 Best Paper)。为了增加网络结构搜索的 scalability,Google Residency Program 的成员 Barrret Zoph 在 Quoc Le 的带领下开始了神经网络自动调参的尝试,Neural Architecture Search with Reinforcement Learning 就是对这一工作的总结。该论文获得了 ICLR 2017 的 Best Paper。Barret Zoph 的工作成功在 CIFAR 和 PTB 上面搜索到了 state-of-the-art 的 CNN 和 LSTM 结构。
Barret Zoph 使用强化学习进行网络结构搜索,网络框架图如下图:
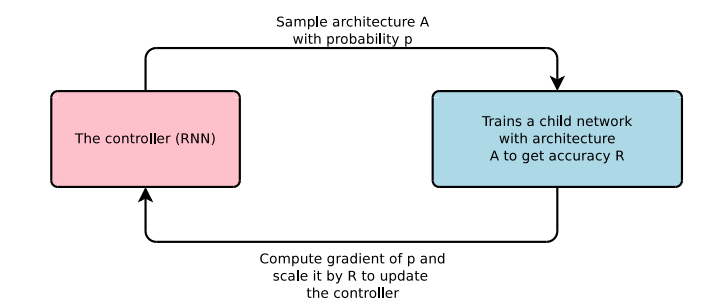
Controller 是由 RNN 构成能够产生每层网络的 Kernel 大小和 skip connection 的连接,产生了网络结构之后,使用网络结构的准确率作为 Reward function。Controller 会根据 reward function 的反馈进行网络结构调节,最后会得到最优的网络结构。Controller 生成网络结构预测如下图:
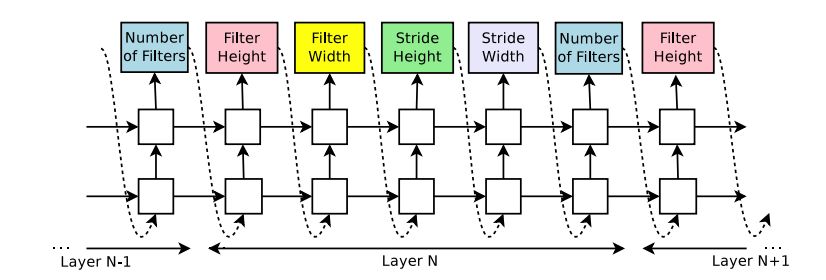
............................
AutoML分别找到在CIFAR-10和ImageNet图像分类、COCO物体检测中的最佳层。这两层结合形成一种新架构,我们称之为“NASNet”。
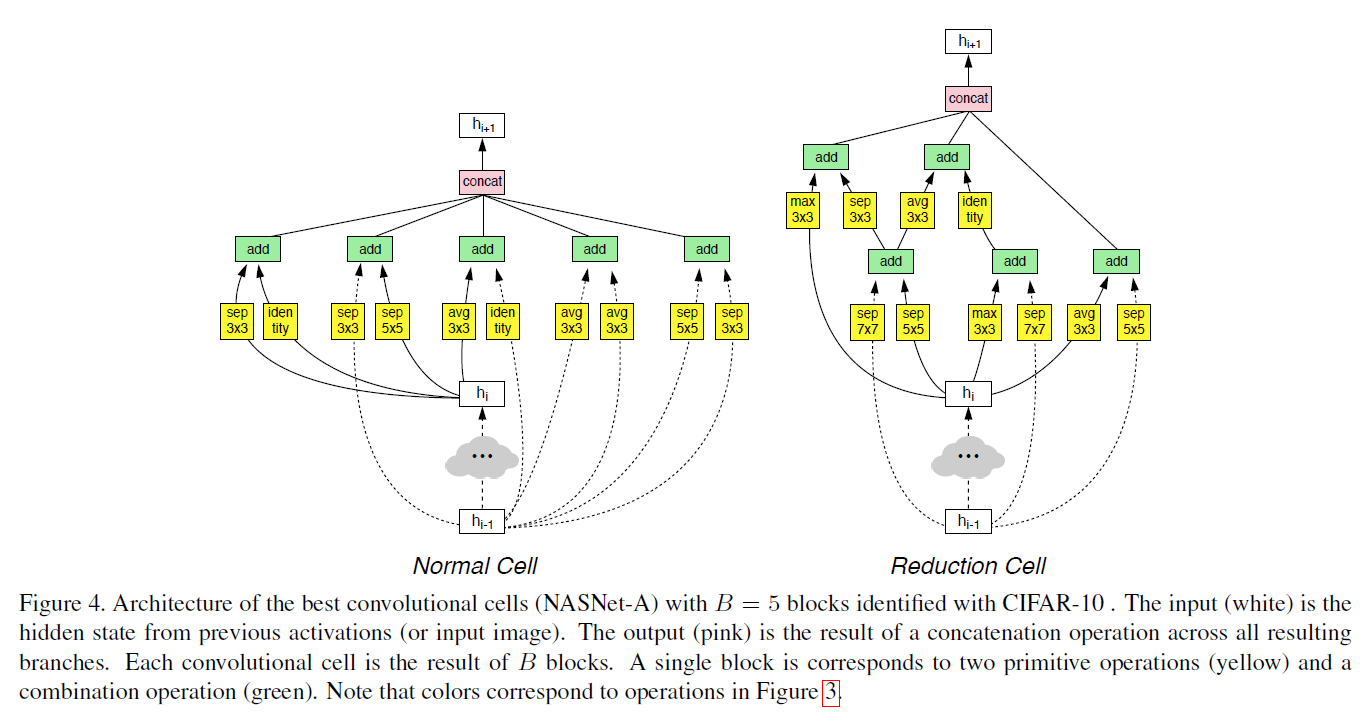
第一个改进其实是一个经验:cnn 可以由同构模块进行堆叠而构成。这样设计一个大型cnn网络就直接简化为设计一个block就行了,也就可以用nas解决了。
第二个改进:合理选择搜索空间中的操作,使得block运行时对输入尺寸没有要求(例如卷积,pooling等操作)。这样图像由cifar的32 到imagenet的大尺寸图片就不会有问题了。
第三个改进还是经验:block的连接,block内部的一些拓扑结构根据经验可以固定,不用去学。
基于以上几条,nas那一套就可以直接用啦。这篇工作里面的网络也看起来人性化一些,一个原因就是经验性的东西加入了很多。
有了上面的想法,留给机器来做就好了,剩下的事情就简单了。。。。。。。。。个屁啊,好的想法和最终的paper之间还差500块gpu呢(ノ`⊿´)ノ。
另一個分支
CNN的一個方向是模塊化以及結構化,進而可以自動化生成。另外一個方向則向著輕量化、稀疏化的方向發展,主力為人工設計優化網路結構。網絡結構產生各種進化,有MobileNet、ShuffleNet、deformNet等。一切都是为了结构再稀疏。
搜狗总是无辜切换繁体字 ...
...
Bottleneck-为降低参数而降低参数
为降低参数而降低参数,微软的发展了ResNet网络,对应Google发展了Inception结构,加入1×1卷积核。
文章: ResNet之Deeper Bottle Architecture,简称DBA
关于ResNet,原作者阐述
Because of concerns on the training time that we can afford, we modify the building block as abottleneck design.
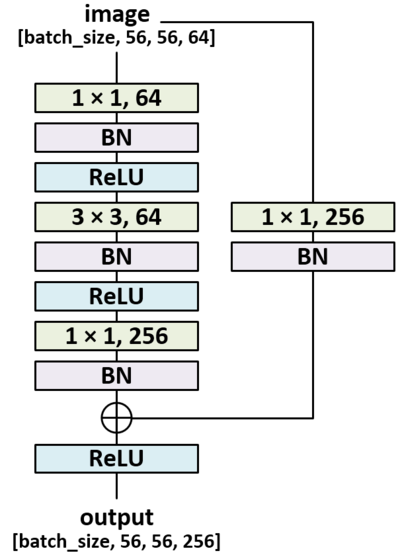
就是说,作者考虑到自己GPU的计算能力有限,所以才采用了bottleneck design!说到底还是没钱上1080呗!不过2015年的时候1080还没出来,那他为什么不上TITAN,还是没钱呗!一个DBA内部的结构图如下:
另一方面,GoogleNet的团队发现,如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,如图所示:

加入1×1卷积核的Inception结构

根据上图,我们来做个对比计算,假设输入feature map的维度为256维,要求输出维度也是256维。有以下两种操作:
256维的输入直接经过一个3×3×256的卷积层,输出一个256维的feature map,那么参数量为:256×3×3×256 = 589,824
256维的输入先经过一个1×1×64的卷积层,再经过一个3×3×64的卷积层,最后经过一个1×1×256的卷积层,输出256维,参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69,632。足足把第一种操作的参数量降低到九分之一!
1×1卷积核也被认为是影响深远的操作,往后大型的网络为了降低参数量都会应用上1×1卷积核。
可分離卷積結構-xception/MobileNet
DepthWise操作:卷积操作非必须同时考虑通道和区域,由此引发把通道和空间区域分开考虑的DepthWise操作。
一个2×2的卷积核在卷积时,对应图像区域中的所有通道均被同时考虑,问题在于,为什么一定要同时考虑图像区域和通道?下图为对比标准卷积核DepthWise操作。
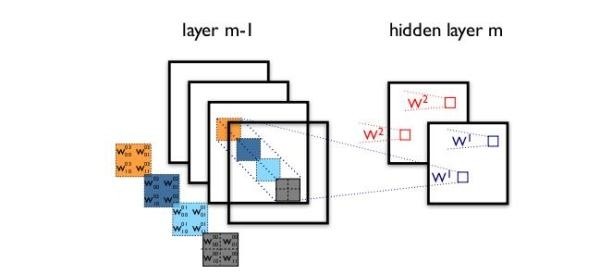
我们为什么不能把通道和空间区域分开考虑?

我们首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道feature maps之后,这时再对这批新的通道feature maps进行标准的1×1跨通道卷积操作。这种操作被称为 “DepthWise convolution” ,缩写“DW”。
这种操作是相当有效的,在imagenet 1000类分类任务中已经超过了InceptionV3的表现,而且也同时减少了大量的参数,我们来算一算,假设输入通道数为3,要求输出通道数为256,两种做法:
1.直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6,912
2.DW操作,分两步完成,参数量为:3×3×3 + 3×1×1×256 = 795,又把参数量降低到九分之一 ! 因此,一个depthwise操作比标准的卷积操作降低不少的参数量,同时论文中指出这个模型得到了更好的分类效果。
Inception假设:卷积层试图在3D空间学习过滤器,2个空间维度( 宽和高)以及1个通道维度,因此一个卷积核需要同时绘制跨通道相关性和空间相关性。Inception模块背后的思想就是通过将这个过程分解成一系列相互独立的操作以使它更为便捷有效。进一步讲,典型的Inception模块首先处理跨通道相关性,通过一组1×1卷积,将输入数据绘制到3或4个小于原始输入的不同空间,然后通过3×3或者5×5卷积将所有相关性绘制到更小的3D空间。图示如上。实际上Inception背后基本的假设是使跨通道相关性和空间相关性的绘制有效脱钩。
通道间的相关性和空间相关性完全分离,文章:对Xception(一种深度可分离卷积)模型的介绍
Google现在作恶已经肆无忌惮了:如何评价google的inceptionX网络,阐述的比较详细
xception:一个完全基于深度可分卷积层的卷积神经网络结构。实际上,我们做如此假设:卷积神经网络的特征图中的跨通道相关性和空间相关性的绘制可以完全脱钩。由于这种假设是Inception结构中极端化的假设,我们将它称作Xception,意指极端Inception。
交错组卷积IGC-模块:
7 月 17 日,微软亚洲研究院的一篇论文《Interleaved Group Convolutions for Deep Neural Networks》入选计算机视觉领域顶级会议 ICCV 2017(International Conference on Computer Vision)。论文中提出了一种全新的通用卷积神经网络交错组卷积(Interleaved Group Convolution,简称 IGC)模块,解决了神经网络基本卷积单元中的冗余问题,可以在无损性能的前提下,缩减模型、提升计算速度,有助于深度网络在移动端的部署。研究就从通道的角度出发,设计了一种全新的卷积冗余消除策略。文章:交错组卷积详解 ,消除冗余卷积核
论文:Interleaved Group Convolutions for Deep Neural Networks
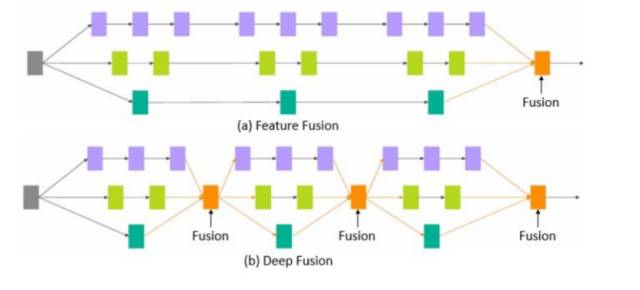
研究的设计思路是来自于微软亚洲研究院去年提出的深度融合(Deep Fusion)概念,其本质是将不同分支的网络在中间层进行融合。他们在进一步研究中发现,一个标准的卷积也可以采用类似的多分支结构,由此展开深入研究,研究出了较为简单的交错组卷积模块,即 IGC 模块。
每个交错组卷积模块包括两个组卷积(group convolution)过程——第一次组卷积(primary group convolution)以及第二次组卷积(secondary group convolution)。组卷积曾被用于 AlexNet 中,将模型分布在两个 GPU 上以解决内存处理问题。用一个 32 通道的例子来解释一下组卷积:把 32 个输入通道平均分为 4 组,每组拥有 8 个通道,并分别对 4 组单独做卷积运算。这样的好处是参数较少可以提升计算速度,但是同时,由于每组卷积之间不存在交互,不同组的输出通道与输入通道并不相关。为了让输入通道与每一个输入通道实现关联,交错组卷积过程巧妙地引入了第二次组卷积,即第二次组卷积过程中,每组的输入通道均来自于第一次组卷积过程不同的组,达到交错互补的目的。
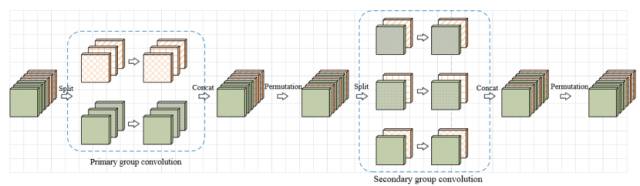
交错组卷积过程
从消除卷积核冗余的角度看,一个组卷积等价于具有稀疏核的普通卷积,而交错组卷积,即两次组卷积则等价于两个稀疏核相乘的普通卷积。这两个稀疏矩阵相乘可以得到两两相关的稠密矩阵,是一个线性的过程。在网络模型大小及计算复杂度相同的条件下,相较于普通卷积,使用 IGC 模块的网络更宽,性能更优。
........................
Xception 模块可以看作交错组卷积的一个特例。如果第一次组卷积过程中,每组只有一个输出通道,那么就变成了特殊的组卷积,即 channel-wise convolution,第二次组卷积成为 1X1 的卷积,这与 Xception 相似;如果第一次组卷积过程里仅有一组,那么这个过程就变成了普通卷积,第二次组卷积过程则相当于分配给每个通过一个不同的权重。那么问题来了,极端情况下是否能带来最佳结果?研究团队也针对这个问题进行了探讨,并设计了相关实验,结果发现并不是这样。
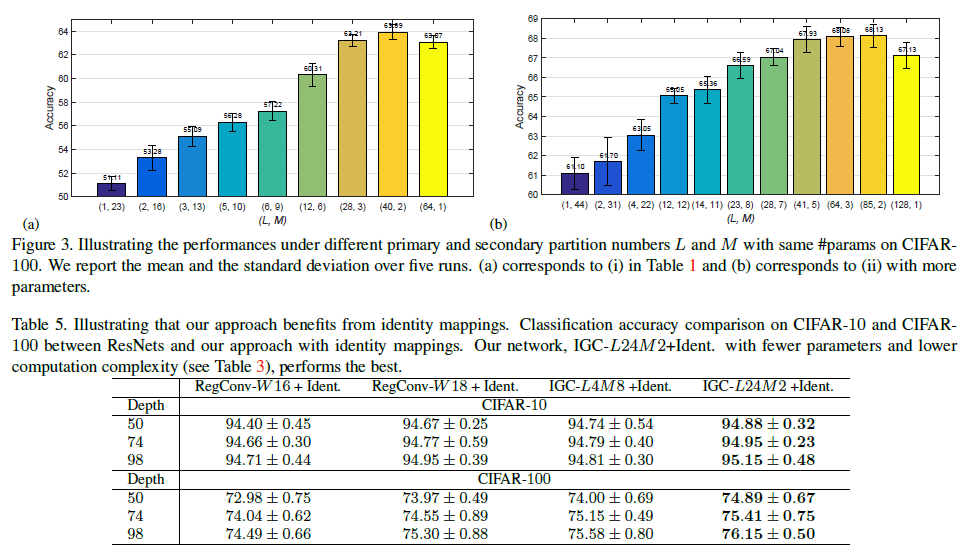
通过实验结果可以发现,网络的性能会随着通道数及组数的变化而变化,最优性能配置点存在于两个极端情况之间。精确度会随着第一次组卷积分成的组数的增加(第二次组卷积分成的组数的减少)而提升,达到极值后开始降低。
MobileNet:
MobileNet的主要工作是用depthwise sparable convolutions替代过去的standard convolutions来解决卷积网络的计算效率和参数量的问题。使用深度分离的卷积可以极大地减少运算和内存的消耗,同时仅牺牲1%~5%的准确率损失,准确率的折损率取决于需要达到的运算节约。
ShulffeNet-分组卷积操作:
在AlexNet的Group Convolution当中,特征的通道被平均分到不同组里面,最后再通过两个全连接层来融合特征,这样一来,就只能在最后时刻才融合不同组之间的特征,对模型的泛化性是相当不利的。为了解决这个问题,ShuffleNet在每一次层叠这种Group conv层前,都进行一次channel shuffle,shuffle过的通道被分配到不同组当中。进行完一次group conv之后,再一次channel shuffle,然后分到下一层组卷积当中,以此循环。
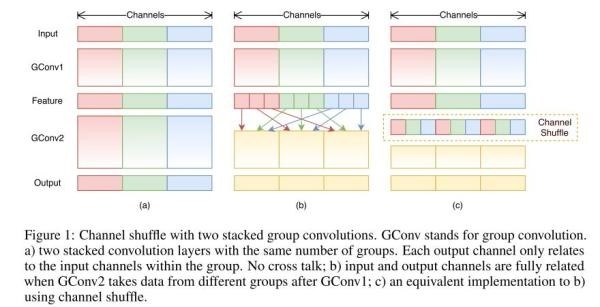
来自ShuffleNet论文
经过channel shuffle之后,Group conv输出的特征能考虑到更多通道,输出的特征自然代表性就更高。另外,AlexNet的分组卷积,实际上是标准卷积操作,而在ShuffleNet里面的分组卷积操作是depthwise卷积,因此结合了通道洗牌和分组depthwise卷积的ShuffleNet,能得到超少量的参数以及超越mobilenet、媲美AlexNet的准确率!速度可以超过AlexNet10倍。
要注意的是,Group conv是一种channel分组的方式,Depthwise +Pointwise是卷积的方式,只是ShuffleNet里面把两者应用起来了。因此Group conv和Depthwise +Pointwise并不能划等号。
此文打的字比较多:从MobileNet到ShuffleNet-CNN网络优化学习总结 ,长文也算比较有条理性,建议花半个小时读一下这个翻译。
........................
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
分析一下 Xception 与 ResNeXt 的问题。先说效率,Xception 和 ResNeXt 所引入的 depthwise separable convolution 和 group convolution 虽然能协调模型的能力与计算量,但被发现它们的 pointwise convolution 占据着很大的计算量。因此ShuffleNet考虑引入 pointwise group convolution 来解决这个问题,后文有例子能看出这点。再说准确率,前面也提到过 ResNeXt 的 C 参数是有极限的,也就是说给 ResNeXt 调参是没有前途的,仅有的参数还有极限。而且 group convolution 用 groups 数来协调模型效果与计算量,这本身就是一对技术矛盾。TRIZ理论告诉我们遇到技术矛盾,一定要打消协调的念头,并深入挖掘矛盾本质,寻找机会消除矛盾。
我认为 ShuffleNet 解决这两个问题的思路是,先引入 pointwise group convolution 解决效率问题,再想办法把它所带来的次级问题与原来的效果问题合在一起解决,原因是次级问题也是group的调整。实际上,引入 pointwise group convolution 可以认为利用 TRIZ 的 STC 算子或提前做原则,这跟 Xception 把 groups 分到最小变成 depthwise 的极限思路也像。既然 ResNeXt 在瓶颈模块中间采用了 splitting 策略,为何就不在输入就采用这种策略呢?这样不网络整体就分离了么?然而,这个分组数 g 跟 Cardinality 一样影响着模型的能力,由此 pointwise group convolution 带来了次级问题。而这个问题的本质是什么呢?对比分组卷积和常规卷积的运算规则,我们能够发现根本矛盾可能是分组卷积没有 Channel Correlation,那么需要解决的矛盾就变成如何让分组卷积也有 Channel Correlation。Face++ 用 Channel Shuffle 来解决这个问题。
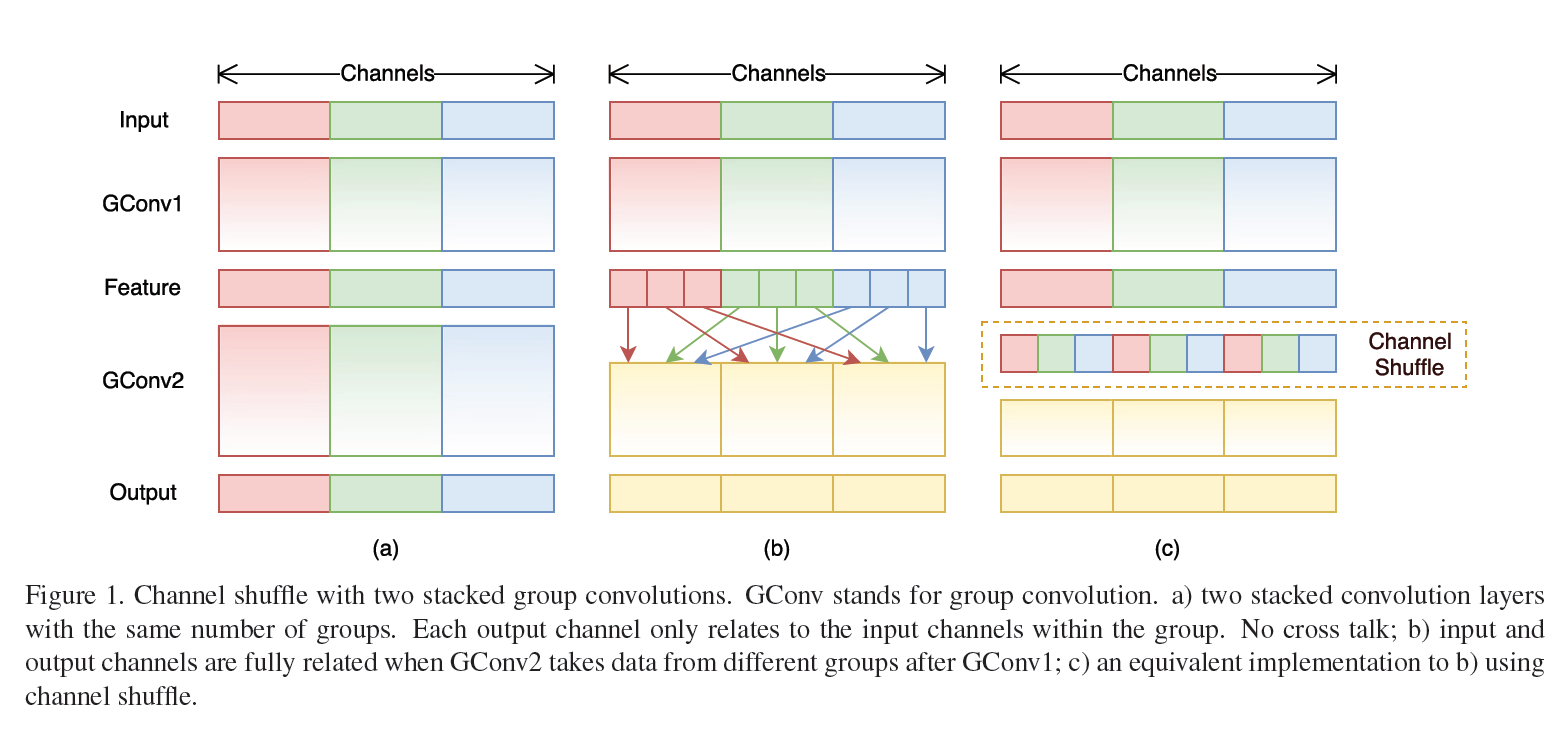
如上图(b)所示,Input 分成 3 组并分别做了对应的变换( 3x3 GConv1),然后在下一次变换(3x3 GConv2)之前做了一次分组间的 Channel Shuffle。如此一来,每个分组就含有了 其它分组的局部 Channel Correlation 了。如果 Channel Shuffle 次数足够多,我觉着就可以认为这完全等效于常规卷积运算了。这是一个不错的创新点,只是效率看起来并不那么完美,原因是 Channels Shuffle 操作会导致内存不连续这个影响有待评估。另外,即使两个分组的大小不一样,Channel Shuffle 仍然是可以做的。ShuffleNet 以 Channel Shuffle 为基础构造出 ShuffleNet Unit,最后我们看一下这个 ShuffleNet Unit。
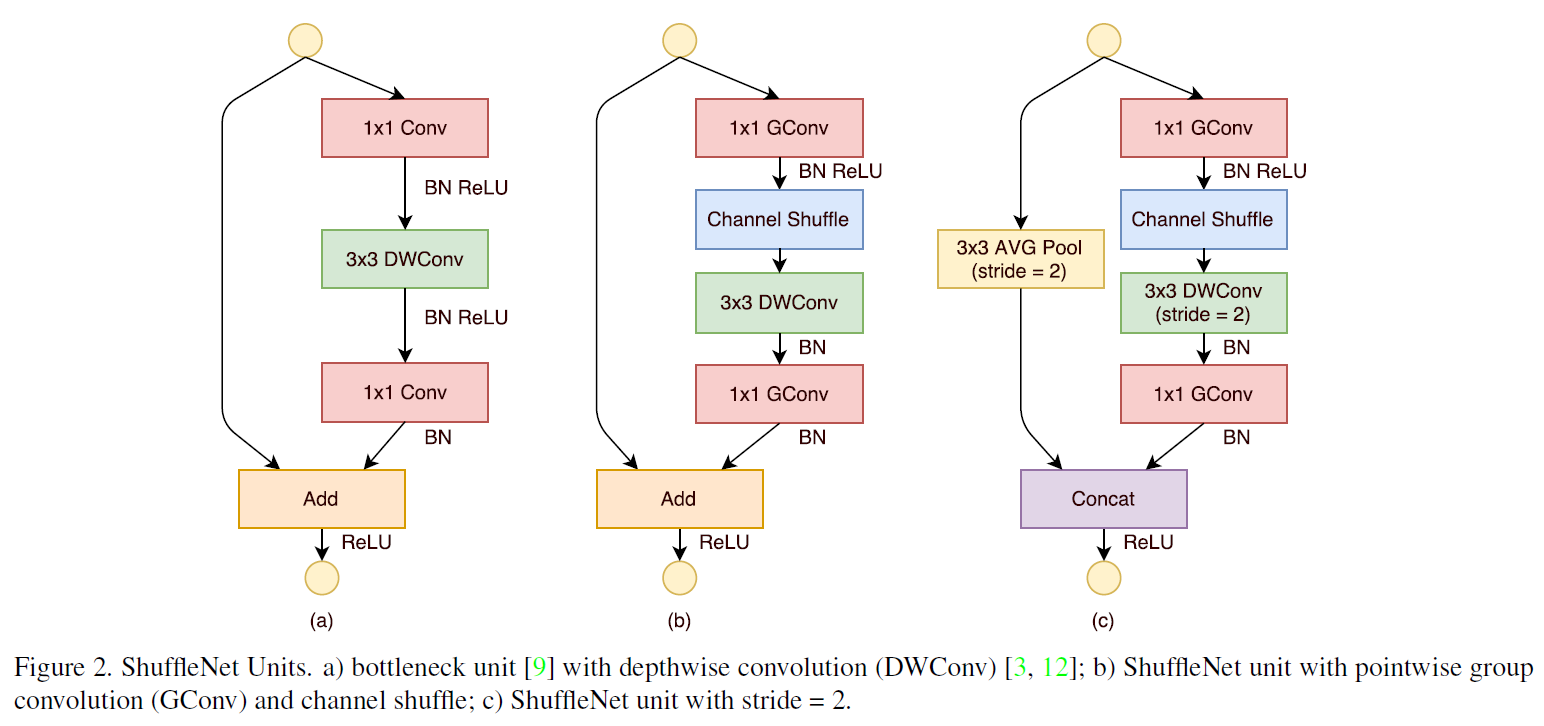
关于计算和推导还是看原文吧:从MobileNet到ShuffleNet-CNN网络优化学习总结
ShuffleNet,通过引入 Channel Shuffle 解决分组卷积的 Channel Correlation 问题,并充分验证它的有效性,同时具备理论创新与实用性。理论上,用了一种轻量级的方法解决了 AlexNet 原有的分组并行信息交互问题。而且这个网络的效率很高,适合嵌入式产品。美中不足的是,Channel Shuffle 看起来对现有 CPU 不大友好,毕竟破坏了数据存储的连续性,使得 SIMD(单指令多数据流) 的发挥不是特别理想,估计在实现上需要再下点功夫。
通道之间特征稀疏性——SENet
无论是在Inception、DenseNet或者ShuffleNet里面,我们对所有通道产生的特征都是不分权重直接结合的,那为什么要认为所有通道的特征对模型的作用就是相等的呢? 这是一个好问题,于是,ImageNet2017 冠军SEnet就出来了。
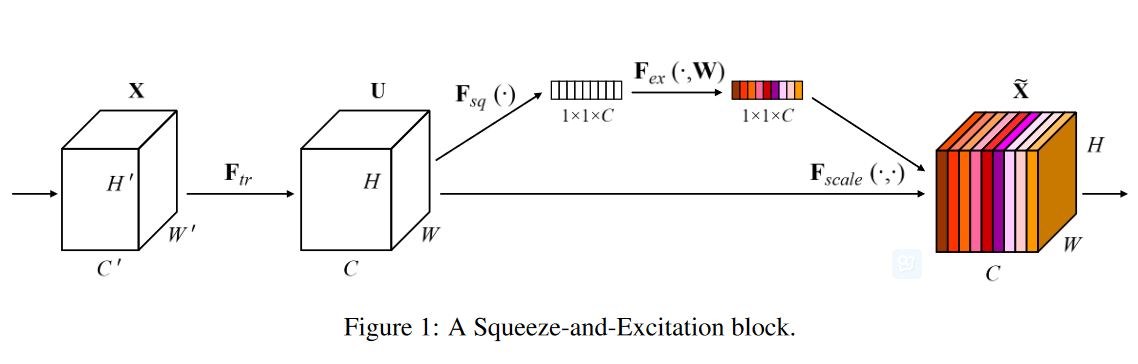
SEnet 结构 : 一组特征在上一层被输出,这时候分两条路线,第一条直接通过,第二条首先进行Squeeze操作(Global Average Pooling),把每个通道2维的特征压缩成一个1维,从而得到一个特征通道向量(每个数字代表对应通道的特征)。然后进行Excitation操作,把这一列特征通道向量输入两个全连接层和sigmoid,建模出特征通道间的相关性,得到的输出其实就是每个通道对应的权重,把这些权重通过Scale乘法通道加权到原来的特征上(第一条路),这样就完成了特征通道的权重分配。作者详细解释可以看这篇文章:专栏 | Momenta详解ImageNet 2017夺冠架构SENet.
中国人写的,就不必要装13看英文了......
论文下载链接:https://arxiv.org/pdf/1709.01507.pdf
Pretrained模型和相关代码可访问github获取: https://github.com/hujie-frank/SENet
固定卷积核增加感受野-dilated conv孔洞卷积
参考:MIT SceneParsing 与dilated conv网络;如何理解扩展卷积网络?下一段摘抄于此文
论文:Multi-scale context aggregation by dilated convolutions
诞生背景,在图像分割领域,图像输入到CNN(典型的网络比如FCN[3])中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(upsampling一般采用deconv反卷积操作,deconv可参见知乎答案如何理解深度学习中的deconvolution networks?),之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。
标准的3×3卷积核只能看到对应区域3×3的大小,但是为了能让卷积核看到更大的范围,dilated conv使其成为了可能。dilated conv原论文中的结构如图所示:
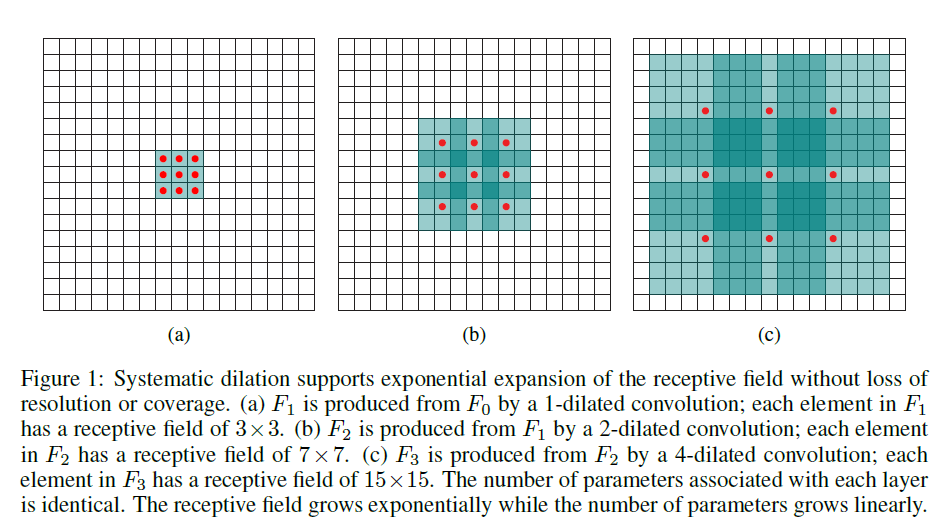
上图b可以理解为卷积核大小依然是3×3,但是每个卷积点之间有1个空洞,也就是在绿色7×7区域里面,只有9个红色点位置作了卷积处理,其余点权重为0。这样即使卷积核大小不变,但它看到的区域变得更大了。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割[3]、语音合成WaveNet[2]、机器翻译ByteNet[1]中。
消除边缘冗余-变形卷积核
同样的物体在图像中可能呈现出不同的大小、姿态、视角变化甚至非刚体形变,如何适应这些复杂的几何形变是物体识别的主要难点,也是计算机视觉领域多年来关注的核心问题。
微软亚洲研究院视觉计算组的研究员在arXiv上公布了一篇题为“Deformable Convolutional Networks”(可变形卷积网络)的论文,首次在卷积神经网络(convolutional neutral networks,CNN)中引入了学习空间几何形变的能力,得到可变形卷积网络(deformable convolutional networks),从而更好地解决了具有空间形变的图像识别任务。研究员们通过大量的实验结果验证了该方法在复杂的计算机视觉任务(如目标检测和语义分割)上的有效性,首次表明在深度卷积神经网络(deep CNN)中学习空间上密集的几何形变是可行的。
论文:Deformable Convolutional Networks
文章翻译:可变形卷积网络—计算机新“视”界
传统的卷积核一般都是长方形或正方形,但MSRA提出了一个相当反直觉的见解,认为卷积核的形状可以是变化的,变形的卷积核能让它只看感兴趣的图像区域 ,这样识别出来的特征更佳。
微软亚洲研究院的研究员们发现,标准卷积中的规则格点采样是导致网络难以适应几何形变的“罪魁祸首”。为了削弱这个限制,研究员们对卷积核中每个采样点的位置都增加了一个偏移的变量。通过这些变量,卷积核就可以在当前位置附近随意的采样,而不再局限于之前的规则格点。这样扩展后的卷积操作被称为可变形卷积(deformable convolution)。标准卷积和可变形卷积在图1中有简要的展示。
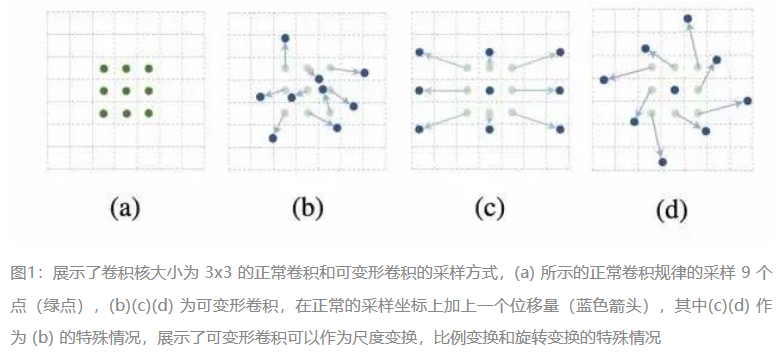
可变形卷积单元中增加的偏移量是网络结构的一部分,通过另外一个平行的标准卷积单元计算得到,进而也可以通过梯度反向传播进行端到端的学习。加上该偏移量的学习之后,可变形卷积核的大小和位置可以根据当前需要识别的图像内容进行动态调整,其直观效果就是不同位置的卷积核采样点位置会根据图像内容发生自适应的变化,从而适应不同物体的形状、大小等几何形变,如图2、3中所展示。

总结:要做到可变性操作,可以直接在原来的过滤器前面再加一层过滤器,这层过滤器学习的是下一层卷积核的位置偏移量(offset),这样只是增加了一层过滤器,或者直接把原网络中的某一层过滤器当成学习offset的过滤器,这样实际增加的计算量是相当少的,但能实现可变形卷积核,识别特征的效果更好。
CNN结构的新发展
一个类似于穷举的大CNN结构到了貌似接近遍历整个图像状态空间的程度,迭代更新的过程中附带着CNN结构的稀疏性构建。同时也代表了解决一般问题的通路,逐步划分子空间,从归纳到遍历的一般套路。
卷积核方面:大卷积核用多层多个个小卷积核代替;单一尺寸卷积核用多尺寸卷积核代替;固定形状卷积核趋于使用可变形卷积核;使用1×1卷积核(bottleneck结构)。
卷积层通道方面:标准卷积用depthwise卷积代替;使用分组卷积;分组卷积前使用channel shuffle;通道加权计算。
卷积层连接方面:使用skip connection,让模型更深,集成为概率模型;densely connection,使每一层都融合上其它层的特征输出(DenseNet),这种方法不一定妥当......
其他启发:类比到通道加权操作,卷积层跨层连接能否也进行加权处理?bottleneck + Group conv + channel shuffle + depthwise的结合会不会成为以后降低参数量的标准配置?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号