利用Kafka的Assign模式实现超大群组(10万+)消息推送
引言
IM即时通信场景下,最重要的一个能力就是推送:在线的直接通过长连接网关服务转发,离线的通过APNS或者极光等系统进行推送。
本文主要是针对在线用户推送场景来进行总结和探讨:如何利用Kafka的Assign模式,解决百万级长链接海量消息的路由广播问题?如何解决超大聊天室成员(超过10万)的消息推送问题?
问题背景
考虑到用户体验和一些技术限制,通常一些社交软件都会限制群成员的上限,比如微信是500,QQ是2000。但是某些特定的场景下,希望突破这个上限,需要怎么实现呢?
如下图,这是一个游戏社交类App,传统的群被重新定义成了房间(有点类似直播聊天室),你可以不加入房间,仅接收消息。如果需要发言,就必须加入房间,后续逻辑和玩法就和QQ类似了。

那么,这种超过 10 万成员的房间(或者叫聊天群)的实时消息推送要怎么实现呢?
接下来,暂且抛开存储、分布式ID生成等等不谈,我们只从长连接网关层面来看看都有哪些可能的问题和挑战。
问题分解
这个里面,主要有3个问题。
1)长连接网关要支持10万+用户在线
这个问题好解决,使用epoll i/o复用模型即可单机轻松支持1-10万并发,取中位数5万计算。支持10万+用户只需要部署2-3个节点即可。
另外,go在linux下就是封装了epoll模型实现的网络通信,按照peer connection peer go routine的指导思想,很容易就能开发出一个高性能的websocket长连接服务。这里有一个示例:websocket example
2)群ID到成员列表的转换
上游存储消息不管是写扩散还是读扩散,至少都应该是以groupId来存储和查询历史消息的。那么在推送广播给所有群成员的时候,势必需要进行一次从group到群成员列表的查询转换。
考虑到成员可以动态加入或者退出,以及分布式下数据一致性的问题,可能最简单做法就是每发一条消息,从mysql查询一次成员列表(顶多在redis中冗余一下成员列表),然后再检查哪些用户在线,再把需要推送的userId列表发给长连接网关。
这里的问题:每一次发消息,都需要从mysql查群成员列表,很容易成为瓶颈。
所以,群和成员的关系需要下沉到长连接网关动态维护,来降低数据库的查询压力,这一块也不是什么大问题。
3)长连接网关之间的路由通信问题
网关集群部署,然后群和成员的关系下沉到长连接网关处理。那么,当一个房间的成员会分布在多个网关节点上时,那么一个用户发消息,就需要广播给所有网关,网关再根据room-member关系进行转发广播才行。
所以,在该场景下,长连接网关之间的路由问题变成了瓶颈,我们来看一下能想到的解决方案。
解决方案
1)连接池
以 goim 举例,goim是b站开源的一个能支持百万级并发的聊天室服务端,它的架构如下:
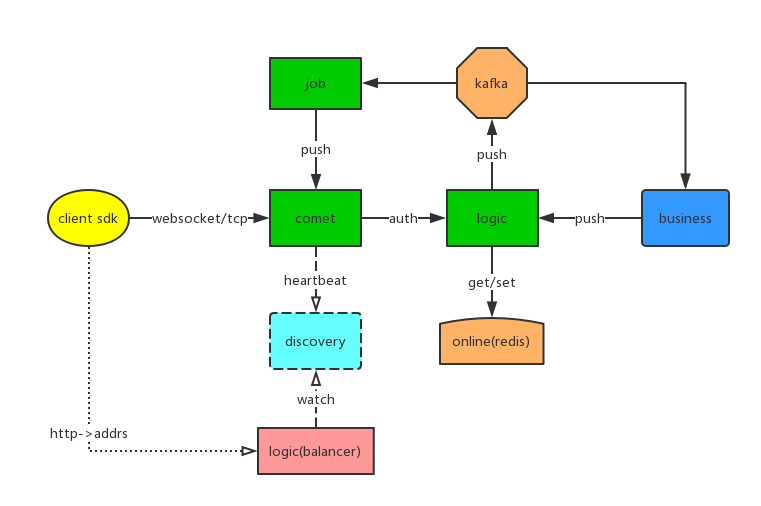
comet是websocket长连接网关,job和comet之间的通信是本文所说的问题所在(多对多)。那么它是怎么实现的呢?
实际上,goim通过服务发现监听了一个事件,每当有新的comet启动就会触发,从而建立和新的comet的grpc连接,流程示意如下图:
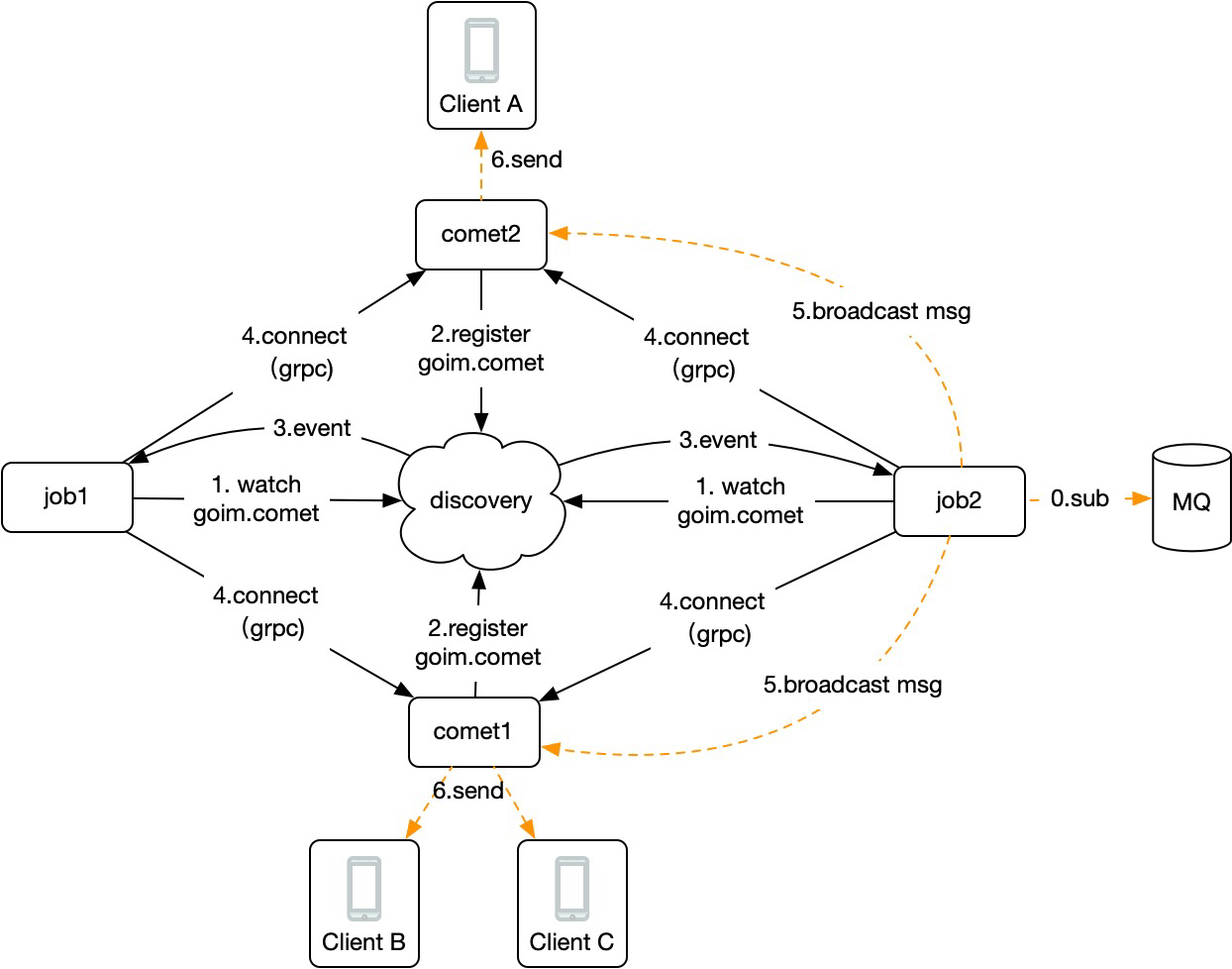
那么,当上游logic生产一条消息到kafka时,consume group确保只有一个job能消费到该消息,然后job通过本地维护的所有comet的连接进行便利发送,达到广播目的。
而comet本地也维护了room和user的关系,这样一套流程下来,就解决了上述问题,实现了超大房间的成员消息推送以及房间成员下沉到长连接网关管理。代码可以查看:https://github.com/Terry-Mao/goim/blob/master/internal/job/job.go
PS:额外多说一句,TeamTalk开源项目中把p2p的连接提取成了router server,所有comet都连接到router server上,job需要广播消息直接发到router server即可。看起来更简单,但是这很明显就是有状态的服务,要确保router server的可用性也需要额外花费很多精力,比如使用haproxy,自己做主从等等,各有利弊吧。
2)kafka实现
服务直连总是会涉及到连接的维护和管理,需要额外的开发成本。
另外,你仔细研究会发现这里是推模型,那么如果数据量足够大,大到下游处理不过来,就会丢消息(我猜测一般人应该遇不到这种场景,故也无需考虑)。
如果部署在不同机房,很可能还会遇到网络中断或者延迟等问题,此时推模型就会丢很多消息,所以,kafka作为大数据必备的组建,为什么采用拉模型,我推测这可能是原因之一吧。
这里介绍2种使用kafka 来实现广播的目的的方案,相比goim的方案更简洁,经过实践,线上运行良好。
方式一:使用consumer group
《Kafka权威指南》对Consumer Group介绍的很细,我们可以不同consumer group可以重复消费的特性,创建对应数量的consumer group,里面只启动一个网关就能实现广播的目的。
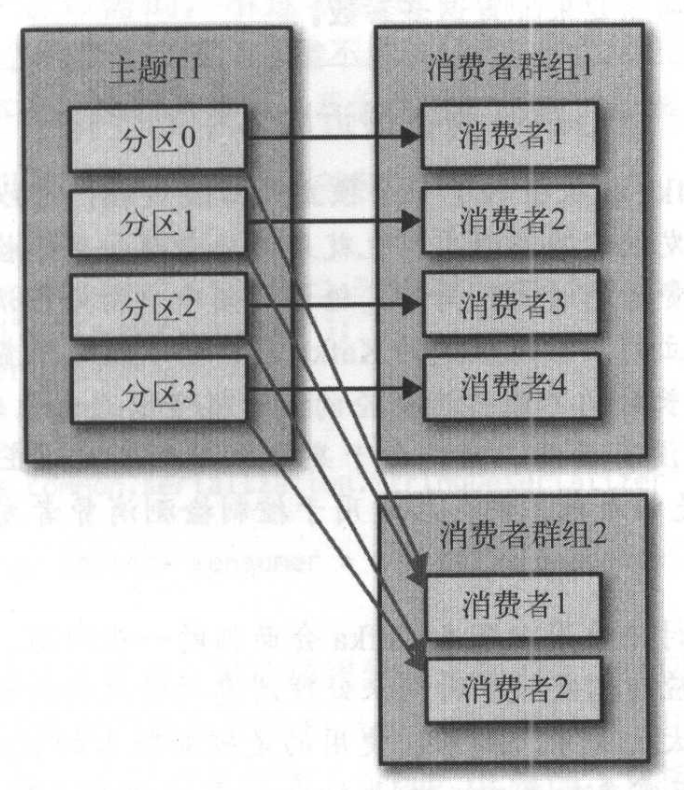
如下图,我们让每个消费组只有1个消费者就是我们要的模型:
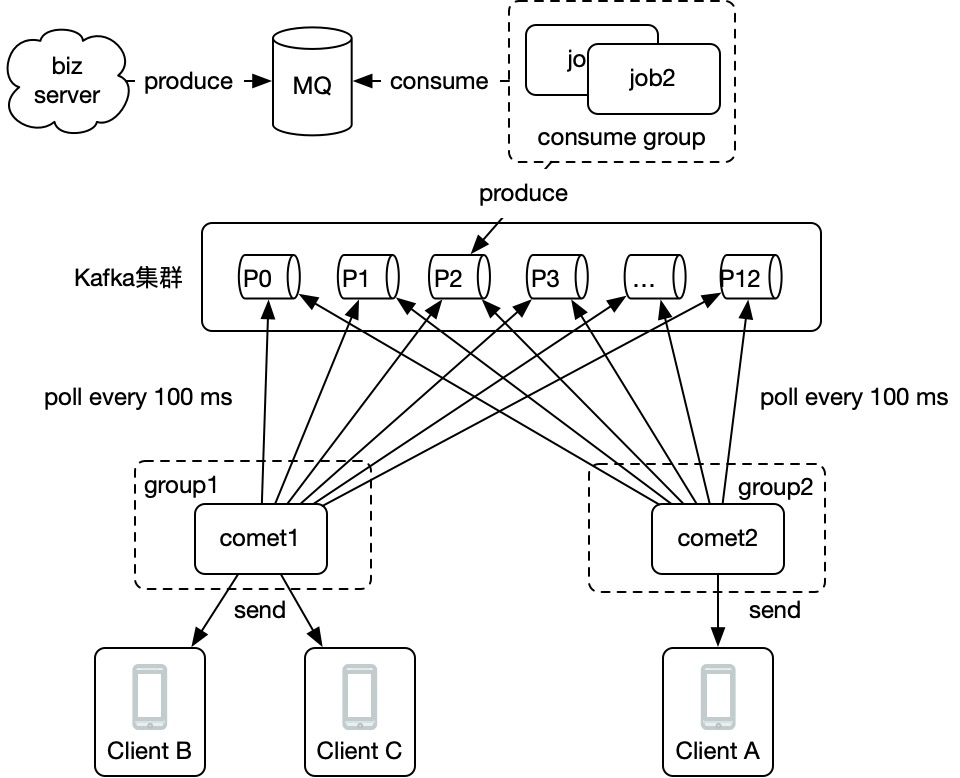
看起来很好像是那么回事对吧?
实际使用时,比如阿里云就对consumer group的数量有限制:

这将导致,长连接网关不能动态指定consumer group的名字。所以,还需要开发一个服务,给网关分配可用的consumer group,这也是一个麻烦的地方。
方式二:使用assign,手动订阅所有分区,不使用consumer group
那么能不能不指定consumer group,自己手动订阅所有分区消费所有消息呢?答案是可以的!
看下图:
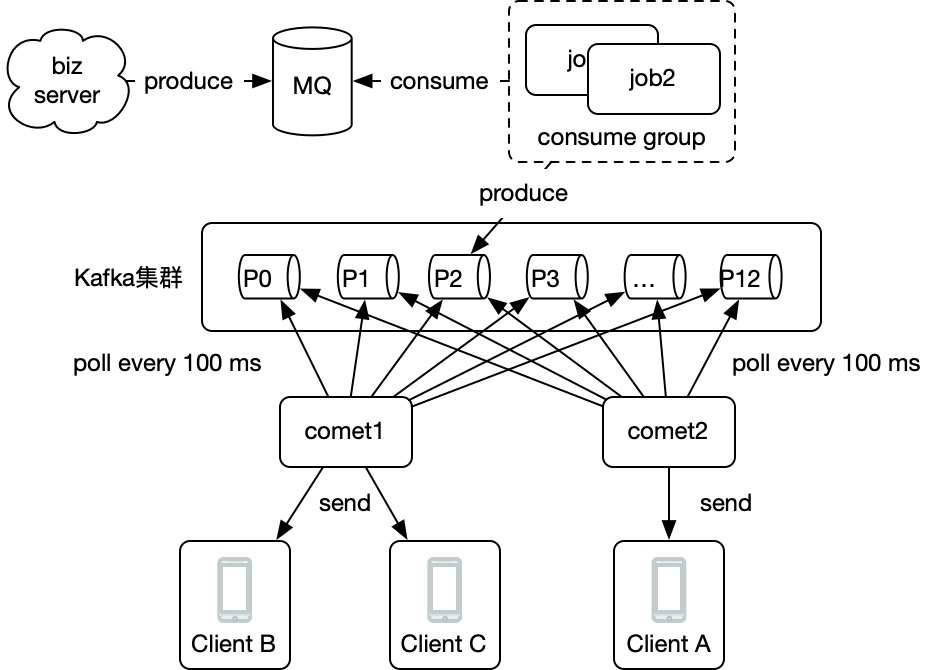
每个comet都订阅所有broker上的所有partition,当上图P2分区生产一条消息后,comet1和comet2都能拉取到,也就达到了广播的目的。
consumer group vs assign模式
最后,总结一下2种模式实现广播的优劣。
一个进程一个consumer group:
- 优点:分区的管理通过group自动实现,不用考虑新分区创建、新消费者加入等等情况。在kafka中还能很方便的看到每一个消费者的消费情况。
- 缺点:受限于云产品的group数量限制,再加上k8s动态启动容器,故需要开发额外的group name分配服务来动态分配提前创建好的group name。
使用assign自动手动订阅所有分区:
- 优点:不需要创建consumer group,简单方便。
- 缺点:由于是程序自己管理分区,故 kafka tools 等工具上看不到消费情况,消息堆积情况等等。另外如果新增分区,要么重启程序,要么程序中定时拉取,kafka需要预先就估算创建好分区数量,有一定难度。
到底使用consumer group还是assign手动订阅,取决于你的场景。建议使用assign模式,根据业务估算并发,一次性创建好分区数量。另外,一般情况下我们也很少会动态创建新的分区,因为一旦如此,IM中的消息乱序也会是一个问题。
Assign模式代码实现
assign模式由来
在java的client api中,KafkaConsumer类提供了2个方法:
- subscribe:为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给同group下的不同consumer
// Subscribe to the given list of topics to get dynamically assigned partitions. void subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
- assign:为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制,相当于指定的group无效(this method does not use the consumer's group management)
// Manually assign a list of partitions to this consumer. void assign(Collection<TopicPartition> partitions)
正常情况下,都是使用subscribe,这样kafka client sdk会自动为我们均衡的分配分区,当创建新的分区或者有新的消费者加入时,rebanlance重均衡操作会进行重新分配,确保每个消费者分到恰当数量的分区:
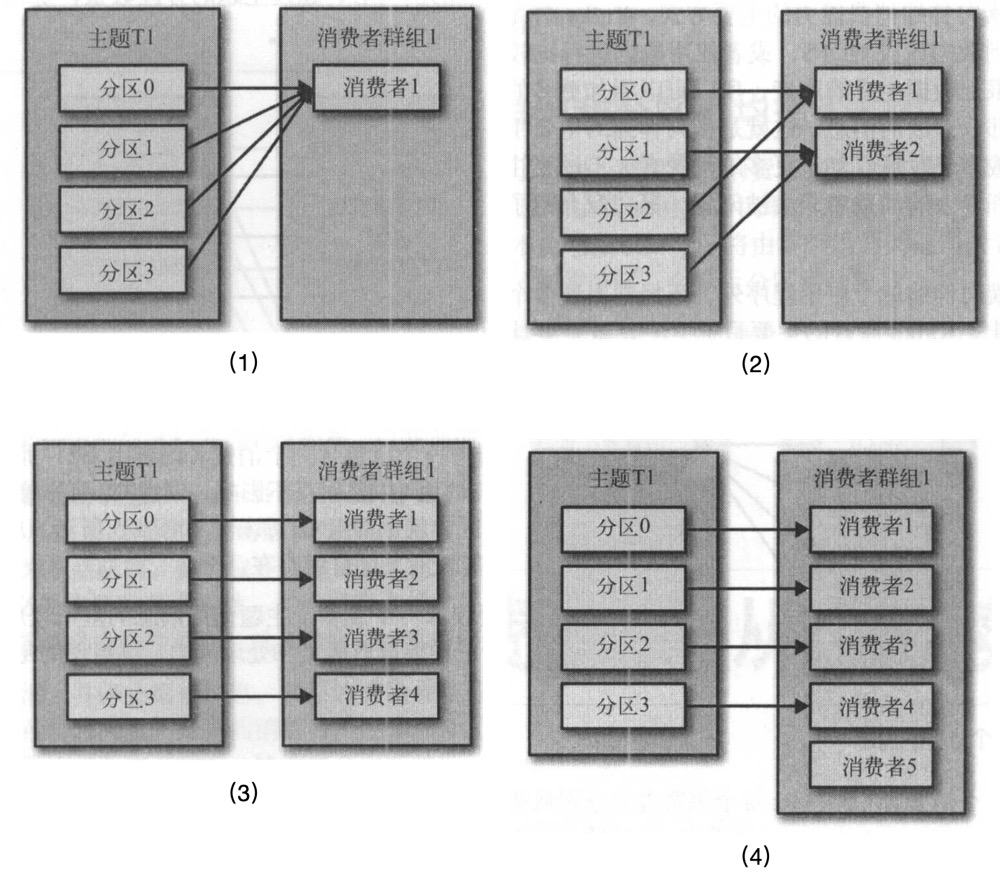
如果使用assign模式手动消费对应的分区,也就没有了上述的特性,如果分区新创建了,需要手动处理。当启动多个实例时,如果只希望消费某个topic一次,也需要自己管理控制哪些实例消费哪些分区。当同一个服务的不同实例分配到一个分区时,消息将会被重复消费多次(请观察上图,同一个消费组下,一个partition同时只被一个实例消费,这也是实现消费一次的关键所在!!!)。
但是,这恰恰是我们需要的!就是要让一个mq消息,被所有长连接网关消费!
go中代码实现
所谓的assign模式是指java中的 KafkaConsumer.assign() 方法,在go中,如果你使用的是Sarama包,那就是对应 consumer.go,java的KafkaConsumer.subscribe() 方法对应go sarama包中的consumer_group.go。
所以,我们只需要启动一个 Consumer ,然后消费指定分区就能实现广播的效果啦!
封装一个consumer.go:
package main
import (
"context"
"sync"
"time"
"github.com/Shopify/sarama"
)
type ConsumerHandler func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage)
func NewConsumer(addrs []string, config *sarama.Config) (sarama.Consumer, error) {
if config == nil {
config = sarama.NewConfig()
// Aliyun kafka version 2.2.0
config.Version = sarama.V2_0_0_0
}
return sarama.NewConsumer(addrs, config)
}
// Consume start consume, will block until exit, call in `goroutine`
// note: `handle` called in `goroutine`
func Consume(ctx context.Context, consumer sarama.Consumer, topic string, handle ConsumerHandler) error {
defer consumer.Close()
// 获取所有分区
partitions, err := consumer.Partitions(topic)
if err != nil {
return err
}
// 消费所有分区
waitGroup := sync.WaitGroup{}
for k, part := range partitions {
p, err := consumer.ConsumePartition(topic, part, sarama.OffsetNewest)
if err != nil {
return err
}
waitGroup.Add(1)
go func(partition int32, partitionConsumer sarama.PartitionConsumer) {
defer waitGroup.Done()
defer partitionConsumer.AsyncClose()
for {
select {
case <-ctx.Done():
return
case m := <-partitionConsumer.Messages():
handle(partition, partitionConsumer, m)
default:
time.Sleep(time.Millisecond)
}
}
}(int32(k), p)
}
waitGroup.Wait()
return nil
}
main.go中使用:
func main() {
// create and start consumer
consumer, err := NewConsumer(kafkaAddr, nil)
if err != nil {
panic(err)
}
for {
log.Println("consumer is running...")
// will block
err := Consume(context.Background(), consumer, topic, func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage) {
log.Println("consumer new mq, paritition=", partition, ",topic:", message.Topic, ",offset:", message.Offset)
})
if err != nil {
log.Println(err)
} else {
log.Println("consume exit")
}
time.Sleep(time.Second * 3)
}
}
producer代码:
func startProducer(addrs []string, topic string) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
producer, err := sarama.NewSyncProducer(addrs, config)
if err != nil {
panic(err)
}
for i := 0; i < 1000; i++ {
p, offset, err := producer.SendMessage(&sarama.ProducerMessage{
Key: sarama.StringEncoder(strconv.Itoa(i)),
Value: sarama.StringEncoder("hello" + strconv.Itoa(i)),
Topic: topic,
})
if err != nil {
log.Println(err)
} else {
log.Println("produce success, partition:", p, ",offset:", offset)
}
time.Sleep(time.Second)
}
log.Println("exit producer.")
}
效果如下:
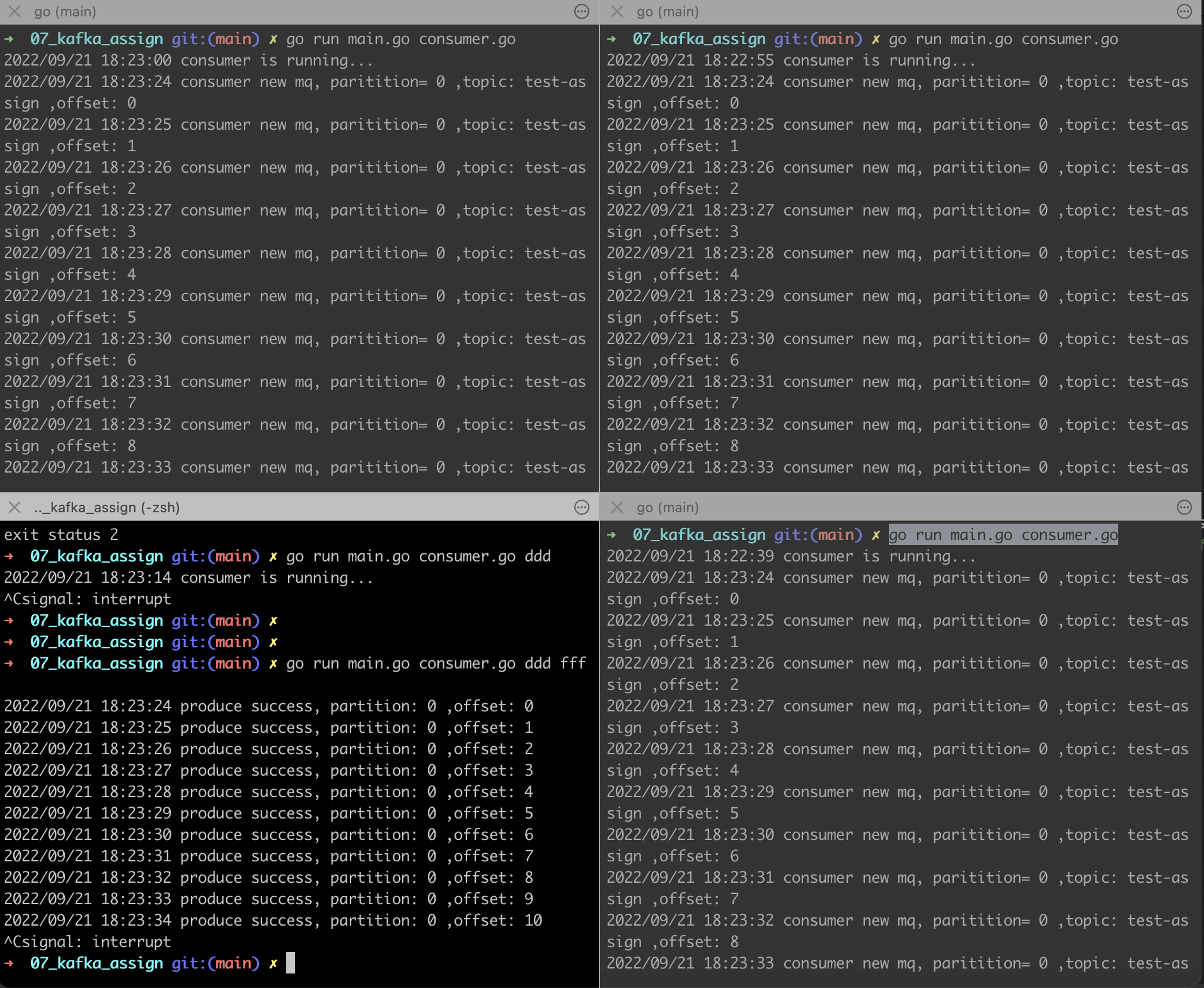
左下角是生产者,其他3个是消费者,我们看到都能消费到,达到了广播的效果!
当然,kafka 上面看不到消费者的情况:
加餐:epoll和连接池的应用以及其局限
1)单体性能
为了充分发挥单台机器的性能,我们可以使用epoll I/O复用技术,来实现单机1-10万的长链接并发在线支持。在该场景下,我们只需要维护好本地的连接和用户关系即可,如下图:
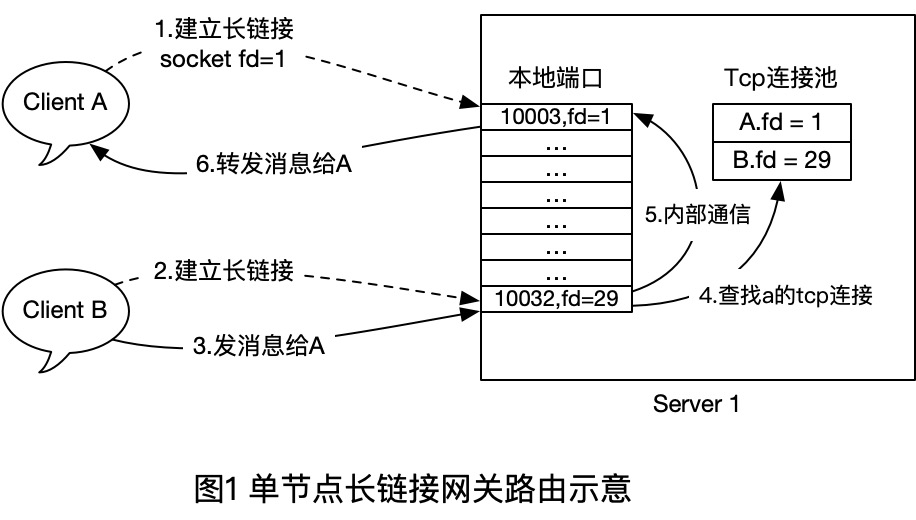
- 首先客户端A和B都和Server1建立TCP长连接,建立时,Server1在内存中插入一条 `User - TcpConn` 的关系,断开时,移除一个对应的关系。
- 当B 给 A发消息时,服务端直接使用本地维护的路由表(连接池)来查找对方的soket句柄,然后Send()到对方的Tcp连接即可。
通过上面的一个流程,就完成了支持IM即时通信场景中最基本的私聊功能,群聊也是类似,多了一层 `Group - User - TcpConn` 的转换而已。
附:
这里说的路由表就是一个 map而已,读者不用纠结 `路由表` 字眼,明白其用途即可。
map[int64]tcp.Conn
2)水平扩展和信息孤岛
现在,假设我们要支持10万用户在线,单机按5万最大用户支持计算,那么只需要部署2-3台网关即可。
这个时候,有一个新的问题:A在Server1上,C在Server2上,他们之间要如何通信(A和C无法发消息聊天)?也就是说,Server之间要如何通信?
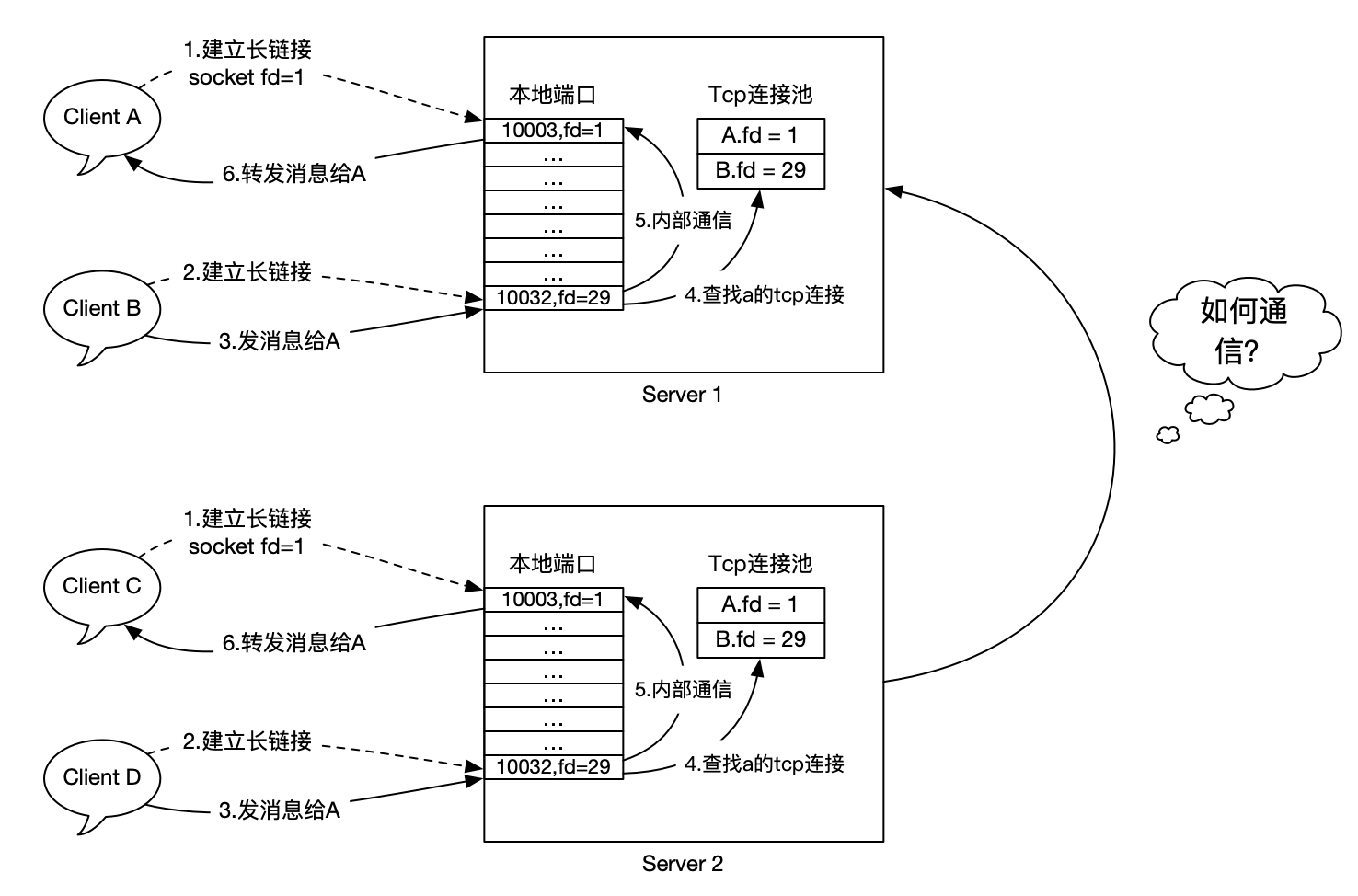
这个其实就是我们玩游戏时候选择的大区,一个大区和另外一个大群的用户不能聊天,只能在一个服里面玩,除非进行跨服务器互通才行,那要如何实现呢?
大体有2个解决方案:
- 分布式路由表。在某个地方统一存放用户登录的节点,推送的时候倒查即可。
- 服务广播。给所有服务器广播消息,那么在该服务器上的用户自然也能收到。
上文主要是围绕服务广播来进行讨论,分布式路由可以简单理解为使用redis记录用户所在网关位置,然后动态查找进行针对性的推送,不过细节较多,暂不讨论。
总结
通过 Kafka Assign模式,我们能很方便的实现进程间广播的效果,如果你已经再使用Kafka,又不想引入额外的服务发现组件或者是自行管理grpc连接,那么将是一个很好的选择!
Reference

 浙公网安备 33010602011771号
浙公网安备 33010602011771号