Go死锁——当Channel遇上Mutex时
背景
用metux lock for循环,在for循环中又 向带缓冲的Channel 写数据时,千万要小心死锁!
最近,我在测试ws长链接网关,平均一个星期会遇到一次服务假死问题,因为并不是所有routine被阻塞,故runtime的检查无法触发,http health check又是另开的一个端口,k8s检查不到异常,无法重启服务。
经过一番排查论证之后,确定了是 混用带缓冲的Channel和Metux造成的死锁 (具体在文末总结)问题,请看下面详细介绍。
死锁现象
我们使用了gin框架,预先接入了pprof封装组件,这样通过http(非生产)就能很方便的查看go runtime的一些信息。
果不其然,我们打开后发现了大量的 goroutine泄漏:

点开 full goroutiine stack dump,可以看到有很多死锁等待,导致goroutine被阻塞:
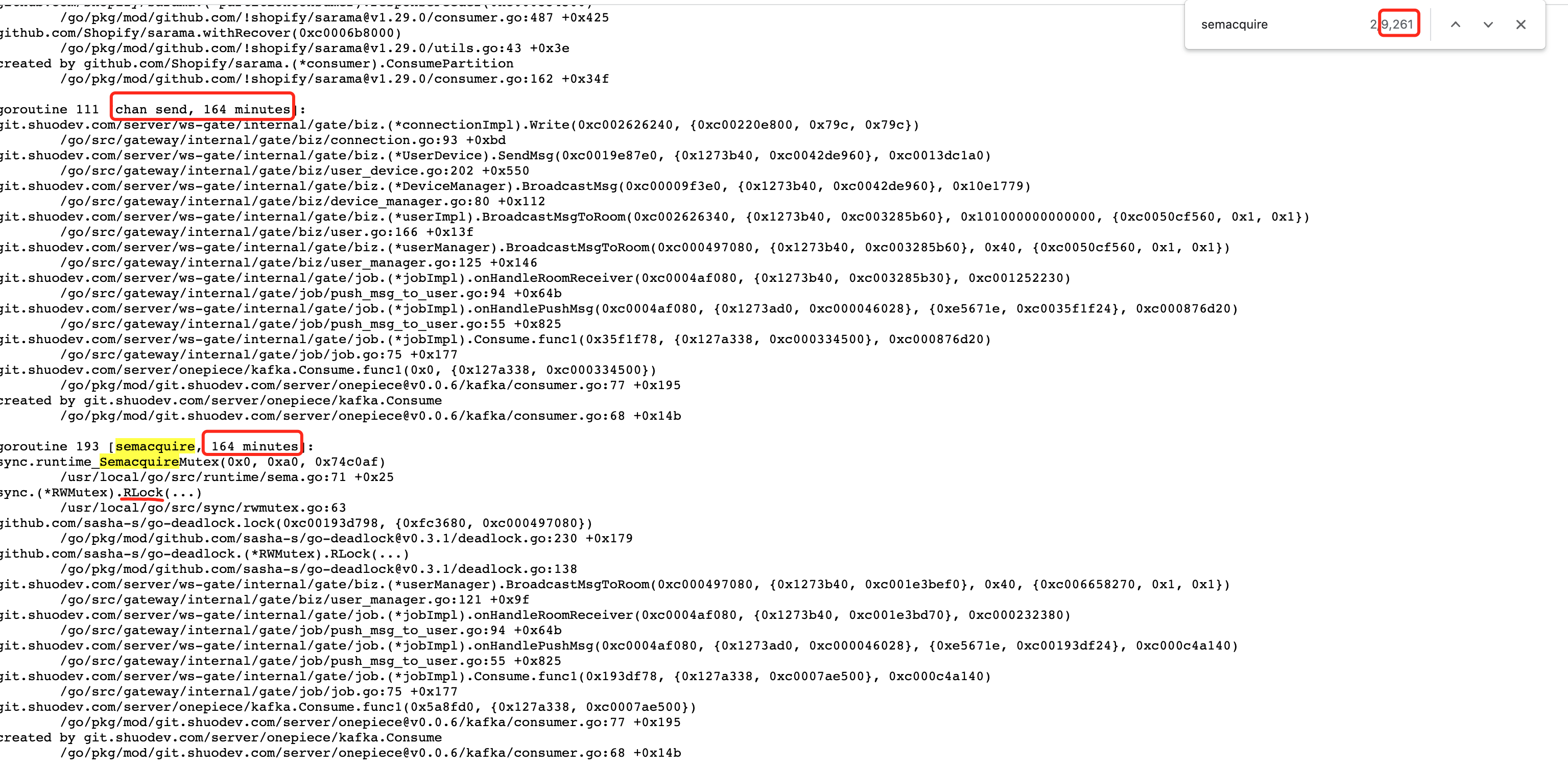
其中:
- semacquire阻塞:有9261/2 个 routine
- chan send阻塞:有9处
问题出在哪里?
启发
有一个作者:https://wavded.com/post/golang-deadlockish/ 分享了一个类似的问题。下面是引用的部分正文内容。
1)Wait your turn
在我们为应用程序提供的一项支持服务中,每个组都有自己的Room,可以这么说。我们在向房间广播消息之前锁定了members列表,以避免任何数据竞争或可能的崩溃。像这样:
func (r *Room) Broadcast(msg string) {
r.membersMx.RLock()
defer r.membersMx.RUnlock()
for _, m := range r.members {
if err := s.Send(msg); err != nil { // ❶
log.Printf("Broadcast: %v: %v", r.instance, err)
}
}
}
请注意,我们等待❶,直到每个成员收到消息,然后再继续下一个成员。这很快就会成为问题。
2)另一个线索
测试人员还注意到,他们可以在重新启动服务时进入房间,并且事情似乎在一段时间内运行良好。然而,他们一离开又回来,应用程序就停止了正常工作。事实证明,他们被这个向房间添加新成员的功能挂断了:
func (r *Room) Add(s sockjs.Session) {
r.membersMx.Lock() // ❶
r.members = append(r.members, s)
r.membersMx.Unlock()
}
我们无法获得锁❶,因为我们的 Broadcast 函数仍在使用它来发送消息。
分析
得益于上面的思路,我发现确实有大量的死锁发生在 Add 位置:
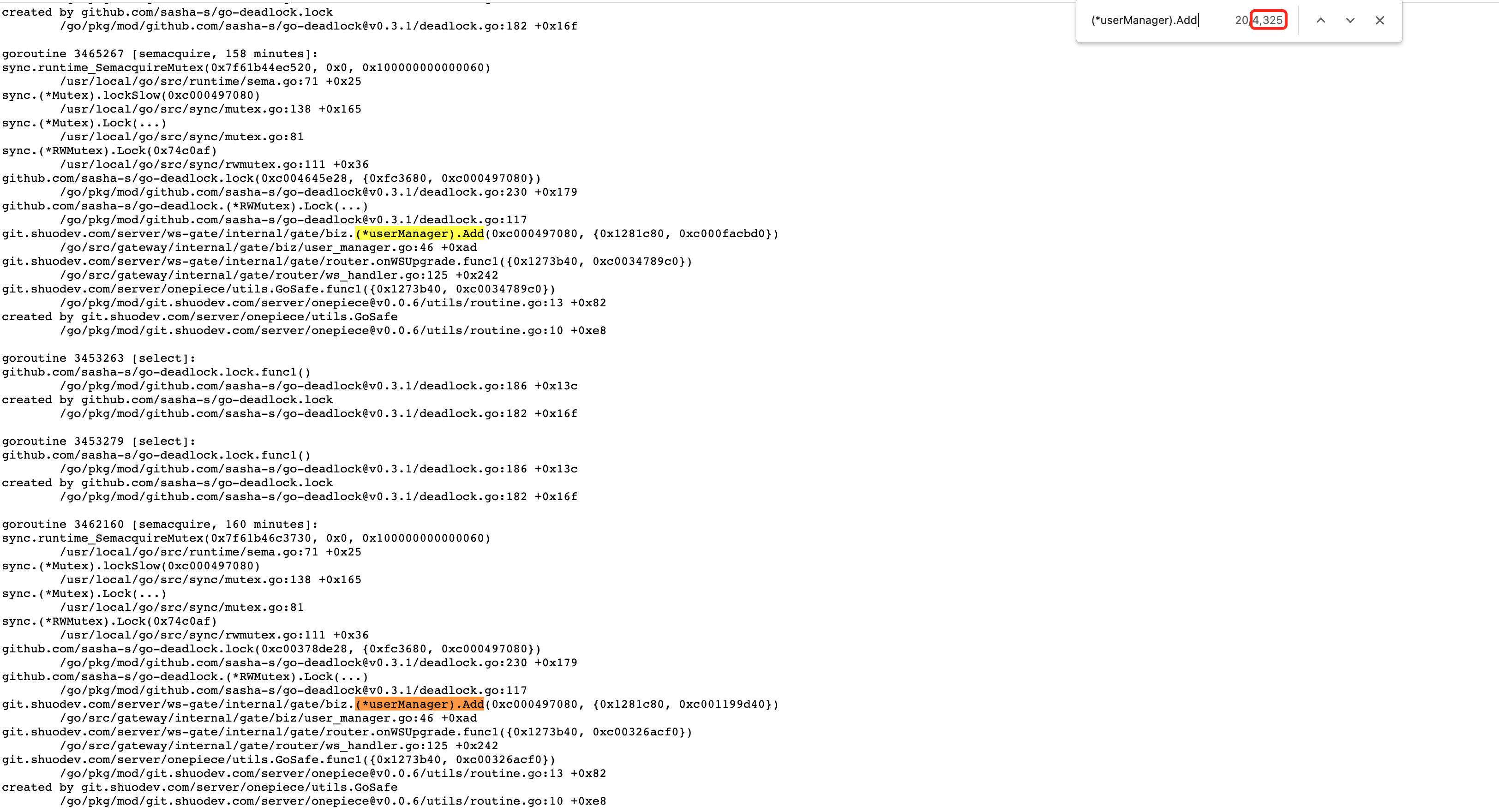
和 wavded 直接调用 Send() 不同,我们是往一个带缓冲的channel中写数据(因为使用了 github.com/gorilla/websocket 包,它的 Writer() 函数不是线程安全的,故需要自己开一个Writer routine来处理数据的发送逻辑):
func (ud *UserDevice) SendMsg(ctx context.Context, msg *InternalWebsocketMessage) {
// 注意,不是原生的Write
if err = ud.Conn.Write(data); err != nil {
ud.L.Debug("Write error", zap.Error(err))
}
}
func (c *connectionImpl) Write(data []byte) (err error) {
wsMsgData := &MsgData{
MessageType: websocket.BinaryMessage,
Data: data,
}
c.writer <- wsMsgData // 注意这里,writer是有缓冲的,数量目前是10,如果被写满,就会阻塞
return
}
然后在 给room下面的用户广播消息 的业务代码(实际有删减)调用:
func (m *userManager) BroadcastMsgToRoom(ctx context.Context, msg *InternalWebsocketMessage, roomId []int64) {
// 这里有互斥锁,确保map的遍历
m.RLock()
defer m.RUnlock()
// m.users 是一个 map[int64]User类型
for _, user := range m.users {
user.SendMsg(ctx, msg) // ❶
}
}
当这个channel写满了,位置 ❶ 的代码就会被阻塞,从而下面的逻辑也会阻塞(因为它一直在等待读锁释放):
func (m *userManager) Add(device UserDeviceInterface) (User, int) {
uid := device.UID()
m.Lock() // ❶
defer m.Unlock()
user, ok := m.users[uid]
if !ok {
user = NewUser(uid, device.GetLogger())
m.users[uid] = user
}
remain := user.AddDevice(device)
return user, remain
}
那么,当一个ws连接建立后,它对应的go routine也就一直阻塞在 Add中了。
func onWSUpgrade(ginCtx *gin.Context) {
// ...
utils.GoSafe(ctx, func(ctx context.Context) {
// ...
userDevice.User, remain = biz.DefaultUserManager.Add(userDevice)
}, logger)
}
但是 c.writer <- wsMsgData 为什么会满了呢?再继续跟代码,发这里原来有个超时逻辑:
func (c *connectionImpl) ExecuteLogic(ctx context.Context, device UserDeviceInterface) {
go func() {
for {
select {
case msg, ok := <-c.writer:
if !ok {
return
}
// 写超时5秒
_ = c.conn.SetWriteDeadline(time.Now().Add(types.KWriteWaitTime))
if err := c.conn.WriteMessage(msg.MessageType, msg.Data); err != nil {
c.conn.Close()
c.onWriteError(err, device.UserId(), device.UserId())
return
}
}
}
}()
}
这下就能解释的通了!
别人是如何解决的?
既然有人遇到了同样的问题,我猜一些开源项目中可能就有一些细节处理,打开goim(https://github.com/Terry-Mao/goim),看到如下细节:
// Push server push message.
func (c *Channel) Push(p *protocol.Proto) (err error) {
select {
case c.signal <- p:
default:
err = errors.ErrSignalFullMsgDropped
}
return
}
有一个select,发现了吗?如果c.signal缓冲区满,这个i/o就被阻塞,select轮询机制会执行到default,那么调用方在循环中调用Push的时候,也不会block了。
修改为下面代码,问题解决:
func (c *connectionImpl) Write(data []byte) (err error) {
wsMsgData := &MsgData{
MessageType: websocket.BinaryMessage,
Data: data,
}
// if buffer full, return error immediate
select {
case c.writer <- wsMsgData:
default:
err = ErrWriteChannelFullMsgDropped
}
return
}
后记
其实runtime是自带死锁检测的,只不过比较严格,仅当所有的goroutine被挂起时才会触发:
func main() {
w := make(chan string, 2)
w <- "1"
fmt.Println("write 1")
w <- "2"
fmt.Println("write 2”)
w <- "3"
}
上面的代码创建了带缓冲的channel,大小为2。然后向其中写入3个字符串,我们故意没有起go routine来接收数据,来看看执行的效果:
write 1
write 2
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/Users/xu/repo/github/01_struct_mutex/main.go:133 +0xdc
exit status 2
这个程序只有一个 main routine(runtime创建),当它被阻塞时,相当于所有的go routine被阻塞,于是触发 deadlock 报错。
我们改进一下,使用 select 来检查一下channel,发现满了就直接返回:
func main() {
w := make(chan string, 2)
w <- "1"
fmt.Println("write 1")
w <- "2"
fmt.Println("write 2")
select {
case w <- "3":
fmt.Println("write 3")
default:
fmt.Println("msg flll")
}
}
此时,不会触发死锁:
write 1 write 2 msg flll
总结
用metux lock for循环,在for循环中又 向带缓冲的Channel 写数据时,千万要小心死锁!
Bad:
func (r *Room) Broadcast(msg string) {
r.mu.RLock()
defer r.mu.RUnlock()
for _, m := range r.members {
r.writer <- msg // Bad
}
}
Good:
func (r *Room) Broadcast(msg string) {
r.mu.RLock()
defer r.mu.RUnlock()
for _, m := range r.members {
// Good👍
select {
case c.writer <- wsMsgData:
default:
fmt.Println(“ErrWriteChannelFullMsgDropped”)
}
}
}
最后,抛出2个问题
- 当 带缓冲的channel 被写满时,到底是应该阻塞好?还是丢弃立即返回错误好?
- 为什么不用 len(w) == cap(w) 判断channel是否写满呢?
第1个问题:我的答案是,根据实际业务特点决定。
第2个问题:我也暂时无法回答。
——————传说中的分割线——————
大家好,我目前已从C++后端转型为Golang后端,可以订阅关注下《Go和分布式IM》公众号,获取一名转型萌新Gopher的心路成长历程和升级打怪技巧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号