

elasticsearch入门二-安装
看完本章将了解以下几点
- es常见基本概念
- 基本增删改查操作
- 常见聚合函数使用
- 提供本章例子的postman例子的json文件
基本概念
Elasticsearch提供了一个简单一致的REST API,用于管理您的集群以及索引和搜索数据。es提供Java, JavaScript, Go, .NET, PHP, Perl, Python or Ruby这些语言客户端。
名词
-
index(索引)- 相当于mysql中的数据库,索引,由很多的Document组成 -
type(类型)- 相当于mysql中的一张表 -
document(文档)- 相当于mysql中的一行(一条记录),由很多的Field组成,是Index和Search的最小单位。 -
field(域)- 相当于mysql中的一列(一个字段),由很多的Term组成,包括name(String)、fieldsData(BytesRef)和type(FieldType)这3个属性。 -
Term- 相当于mysql中的一列(一个字段)中存储的一个具体内容,由很多的字节组成,可以分词 -
Invert Index- 倒排索引,或者简称Index,通过Term可以查询到拥有该Term的文档。可以配置为是否分词,如果分词可以配置不同的分词器。 -
节点- 一个服务器,由一个名字来标识 -
集群- 一个或多个节点组织在一起 -
分片- 将一份数据划分为多小份的能力,允许水平分割和扩展容量。多个分片可以响应请求,提高性能和吞吐量。 -
副本- 复制数据,一个节点出问题时,其余节点可以顶上。
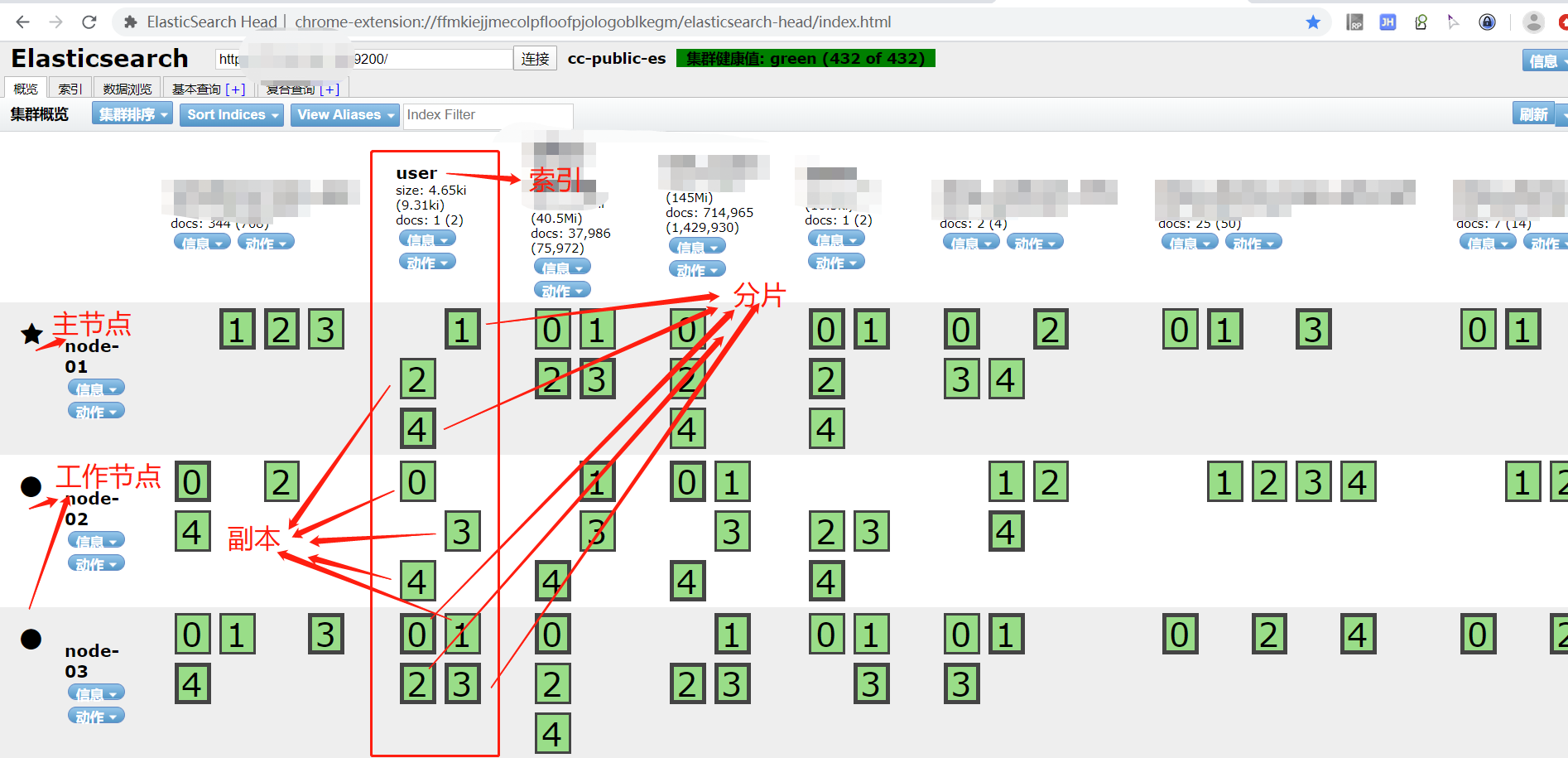
交互操作
集群启动并运行后,就可以为某些数据建立索引了。Elasticsearch有多种存入方式,但最终它们都做同样的事情:将JSON文档放入Elasticsearch索引中。案例使用curl进行操作,下面先介绍下curl命令
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB 适当的HTTP方法或动词。例如,GET,POST, PUT,HEAD,或DELETE。
PROTOCOL 无论是http或https。如果您在Elasticsearch前面有一个HTTPS代理,或者您使用Elasticsearch安全功能来加密HTTP通信,请使用后者。
HOST Elasticsearch集群中任何节点的主机名。或者, localhost用于本地计算机上的节点。
PORT 运行Elasticsearch HTTP服务的端口,默认为9200。
PATH API端点,可以包含多个组件,例如 _cluster/stats或_nodes/stats/jvm。
QUERY_STRING 任何可选的查询字符串参数。例如,?pretty 将漂亮地打印 JSON响应以使其更易于阅读。
BODY JSON编码的请求正文(如有必要)。
实操
前言
-
所有与es交互的操作均提供postman测试案例
-
鉴于cmd使用curl命令不方便,在此可以借助docker来操作
#下载docker镜像,该镜像包含基本常用命令
docker pull donch/net-tools
#启动镜像并进入容器
docker run -it --net host cd1 /bin/bash

插入
单条插入
curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "John Doe"
}
'
#响应结果
{
"_index" : "customer", #索引名
"_type" : "_doc", #类型
"_id" : "1", #主键(通过_id值(ES内部转换成_uid)可以唯一在es中确定一个Doc)
"_version" : 1, #更新版本(保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失)
"result" : "created", #操作类型
"_shards" : { #分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0, #任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no
"_primary_term" : 1 #和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
}
批量插入
命令中的accounts.json文件点我下载(注意文件末尾需要以换行符结束,windows即末尾是空行)
#批量插入
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary "@accounts.json"
#查看
curl "localhost:9200/_cat/indices?v"
#响应结果
#集群状态 状态 索引名 索引uuid 主分片 副本 文档数量 删除文档数 总存储量 主分片存储量
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open bank l7sSYV2cQXmu6_4rJWVIww 5 1 1000 0 128.6kb 128.6kb
修改
PUT修改
PUT定义为幂等操作,所以更新/插入时必须指定id,重复执行相同命令内容不变,version _seq_no更新
curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "John Doe"
}
'
#响应结果
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_version" : 23,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 29,
"_primary_term" : 3
}
POST修改
POST不是幂等操作,因此POST可以不指定id,当不传id时es将自动生成id,即数据会不断增加;传id时,效果同PUT
#插入数据(未指定id)
curl -X POST "localhost:9200/customer/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"name": "John Doe"
}
'
#查看结果
curl -X GET "localhost:9200/customer/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"from": 1,
"size": 3
}
'
#响应结果
{
"took": 6,#花费时长
"timed_out": false,#是否超时
"_shards": {#分片查找信息
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {#命中信息
"total": {
"value": 8,
"relation": "eq"
},
"max_score": 1,
"hits": [#命中文档信息
{
"_index": "customer",
"_type": "_doc",
"_id": "NcePk3IBWT1mnviEpD7P",
"_score": 1,
"_source": {#命中文档内容
"name": "John Doe"
}
},
{
"_index": "customer",
"_type": "_doc",
"_id": "NsePk3IBWT1mnviEzD7Z",
"_score": 1,
"_source": {
"name": "John Doe"
}
},
{
"_index": "customer",
"_type": "_doc",
"_id": "N8ePk3IBWT1mnviE2T5S",
"_score": 1,
"_source": {
"name": "John Doe"
}
}
]
}
}
查询
条件获取
函数介绍
query- 查询条件bool- 组合多个查询条件must- 必须满足must_not- 可以视为过滤器。它影响文件是否包含在结果中,但不会影响文件的评分方式。match- 必须匹配,查询字段可分开搜索,如"address": "mill lane",将查询address中有mill或者lanematch_phrase- 必须匹配,查询字段作为短语搜索,如"address": "111 mill lane",将查询address中有"mill lane"filter- 过滤器range- 范围
#按条件分页查询,且字段排序、
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match_phrase": { "address": "mill lane" } }
],
"must_not": [
{ "match": { "age": "40" } }
],
"filter": {
"range": {
"balance": {
"gte": 40000,
"lte": 50000
}
}
}
}
},
"sort": [
{ "account_number": "asc" }
],
"from": 0,
"size": 2
}
'
#搜索结果
{
"took": 21,#花费时长,毫秒
"timed_out": false,#是否有分片超时,若配置了超时时间,分片查找聚合返回未超时的结果,牺牲了部分准确性提高性能
"_shards": {#搜索了多少个分片,以及成功,失败或跳过了多少个分片
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {#命中信息
"total": {
"value": 1,#找到了多少个匹配的文档
"relation": "eq"
},
"max_score": null,#找到的最相关文件的分数
"hits": [#命中文档信息
{
"_index": "bank",
"_type": "_doc",
"_id": "136",
"_score": null,#文档的相关性得分(使用时不适用match_all)
"_source": {#命中文档内容(field(域))
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
},
"sort": [#文档的排序位置(不按相关性得分排序时)
136
]
},
{
"_index": "bank",
"_type": "_doc",
"_id": "1",
"_score": null,
"_source": {
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
},
"sort": [
1
]
}
]
}
}
聚合获取
es支持聚合分析,也支持结果缓存,前提是同时满足以下规则(包括但不限于):
- 参数不变
- 查询的文档未更新
- 聚合请求函数中不带动态参数,如Date Range中的now
- size=0(最外层),即不查询具体文档信息
函数介绍
aggs- Aggregations(聚合函数)terms- 分组,结果不完全准确,准确度/效率根据size/shard_size变化size- 总查询结果个数,由各分片查询结果合并得来shard_size- 每个分片查询个数,追求准确度应该调高该参数,同时性能降低,缺省为(size* 1.5 + 10)include- 包含该值的文档,支持数组格式["mazda", "honda"],支持通配符(待补充)exclude- 排除包含该值的文档missing- 缺省值,如"missing": "N/A"collect_mode- 子聚合算法,取值depth_first,breadth_first,缺省为深度优先
avg- 平均值order- 排序stats- 统计extended_stats- 扩展统计sum- 求和max- 最大值min- 最小值cardinality- 求基数(去重求个数)percentile_ranks- 百分比min_doc_count- 最小的文档数目,只有满足这个参数要求的个数的词条才会被记录返回shard_min_doc_count- 同上,分片script- 脚本及自定义脚本
#查询40岁及其以上的用户,再将结果按地区(state)分组并降序,查询排名前2位地区(state)的用户的账户余额(balance)平均值及统计
#group_by_state/average_balance/stats_balance均为自定义名称
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 40
}
}
}
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
},
"size": 2,
"shard_size": 4
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
},
"stats_balance": {
"stats": {
"field": "balance"
}
}
}
}
}
}
'
#查询结果
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 45,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {#聚合结果
"group_by_state": {#请求时定义的名称
"doc_count_error_upper_bound": -1,#因分片聚合导致被遗漏的terms,可能的最大值
"sum_other_doc_count": 42,#这次聚合中没有统计到的文档数
"buckets": [#聚合结果信息
{
"key": "PA",
"doc_count": 1,#分组后数量,因分片聚合,所以不精确
"stats_balance": {#请求时定义的名称
"count": 1,
"min": 49159,
"max": 49159,
"avg": 49159,
"sum": 49159
},
"average_balance": {#请求时定义的名称
"value": 49159
}
},
{
"key": "KY",
"doc_count": 2,
"stats_balance": {
"count": 2,
"min": 47887,
"max": 48972,
"avg": 48429.5,
"sum": 96859
},
"average_balance": {
"value": 48429.5
}
}
]
}
}
}
删除
#删除指定id
curl -X DELETE "localhost:9200/customer/_doc/1?pretty"
#结果
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
#删除指定索引
curl -X DELETE "localhost:9200/customer?pretty"
#结果
{
"acknowledged": true
}
集群信息
#查看索引信息
curl "localhost:9200/_cat/indices?v"
#响应结果
#集群状态 状态 索引名 索引uuid 主分片 副本 文档数量 删除文档数 总存储量 主分片存储量
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open bank l7sSYV2cQXmu6_4rJWVIww 5 1 1000 0 128.6kb 128.6kb
#查看集群状态
curl "localhost:9200/_cat/health?v"
#响应结果
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1591686205 07:03:25 es-docker-cluster green 3 3 4 2 0 0 0 0 - 100.0%
#查看字段含义
curl "localhost:9200/_cat/health?help"
#查看更多命令
curl http://localhost:9200/_cat

