

NLP学习笔记-逻辑回归
逻辑回归(Logistic Regression)仍然属于线性分类,是一种分类算法,用于解决二分类问题,估计某种事物的可能性,比如判定一封邮件是否为垃圾邮件;判定用户点击某广告的可能性;判定病人患某种疾病的可能性。由于是线性模型,预测时计算简单、预测速度非常快,当数据规模巨大时,相比SVM神经网络等非线性的模型具有特别的优势。
逻辑函数(Logistics function)
上部分说到逻辑回归用于预测某件事的几率,其值必须在区间[0,1]内。样本标签值为0或1 代表负样本和正样本,那么特征向量x属于正样本记为p(y=1|x)。x的取值范围为(-∞,+∞)需要映射到区间[0,1]。
这时我们就要介绍Sigmoid函数,也称为逻辑函数(Logistic function)
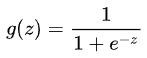
其函数曲线为:
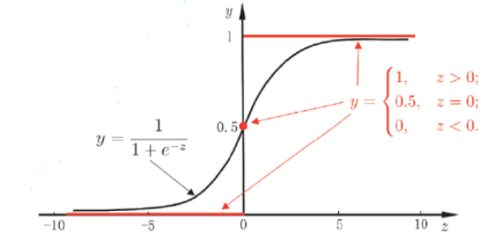
从上图可以看到sigmoid函数是一个s形的曲线,它的取值在[0, 1]之间,当x为0时,sigmoid函数值为0.5。随着x的增大,对应的sigmoid函数的值将逼近于1;而随着x的减小,sigmoid函数的值将逼近于0。
![]()
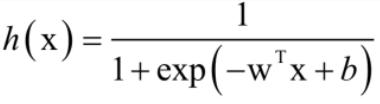
然而函数是无法输入向量的,那么为了实现回归分类器,我们可以给每个特征向量乘一个回归系数然后再累加后送入sigmoid函数,这样就将样本的特征向量映射到了一个概率值p(y =1|x)的函数。
边界决策(Decision Boundary)
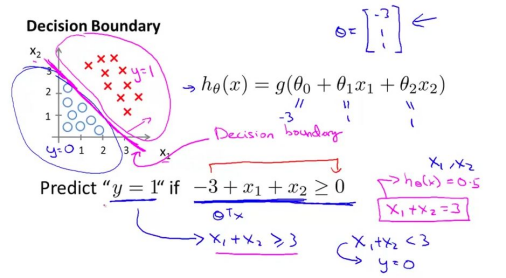
边界决策即在N维平面内,用一个面将不同类别区分开。引用Andrew Ng 课程上的两张图来解释这个问题:
线性决策边界
非线性决策边界

上面两张图清晰的解释了什么是决策边界,即区分类别的一个方程,那么在逻辑回归中,决策边界就是由公式分母中e的系数决定的。
代价函数(Cost function)
代价函数C(θ)用于衡量模型的预测值h和真实值y之间的差异,如果有多个样本,那么将所有代价函数J(θ)的取值求均值。那么确定了模型后,就要训练模型的参数θ,在训练过程中,使代价函数J最小的θ即为最优的参数。当J(θ)=0表示模型完美的拟合了观察的数据,没有任何误差。
过拟合(Overfitting)
然而模型完美拟合了训练数据并不是一件好事,过拟合是机器学习里的一个重要的问题。过拟合就是模型训练时误差很小,但在测试时误差很大,也就是模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,糟糕的一塌糊涂。通俗的讲就是应试能力很强,实际应用能力很差。
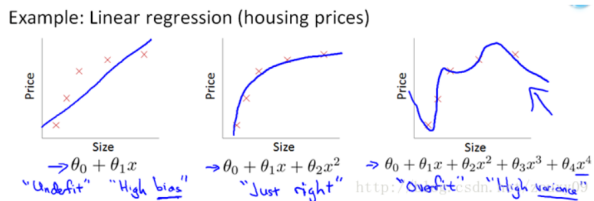
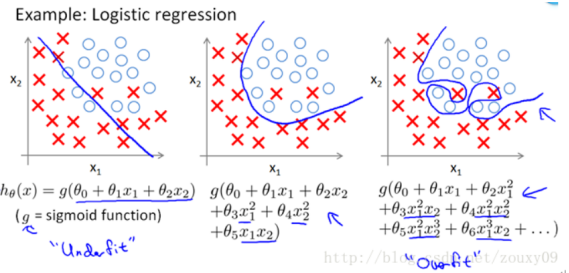
再次借用Ng的course中的图,上面两张图分别为线性回归和逻辑回归,从左到右分别为欠拟合、合适的拟合和过拟合三种情况。
参考
https://blog.csdn.net/JENREY/article/details/83022782
https://zhuanlan.zhihu.com/p/28408516
https://www.csdn.net/tags/NtzaEg3sMzk1ODgtYmxvZwO0O0OO0O0O.html
https://blog.csdn.net/u010899985/article/details/79471909
https://cloud.tencent.com/developer/article/1339818
https://blog.csdn.net/tian_tian_hero/article/details/89409472
https://blog.csdn.net/xq151750111/article/details/121341143
