

Web 应用架构基础课(转载)
Web 应用架构基础课
初级 web 应用开发者必学的基础网络架构概念
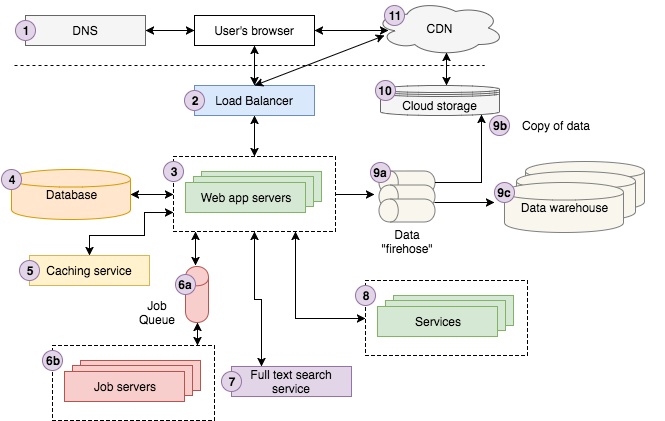
web 应用主流架构概览
上图便是我司(Storyblocks)网络架构的很好展现。如果你还没成为经验老道的 web 工程师,可能觉得上图巨复杂。在详解各个模块前,我们先简单过一下流程。
用户在 Google 搜索关键字 “Strong Beautiful Fog And Sunbeams In The Forest”,首条结果便是来自我司的拳头产品:Storyblocks —— 图片矢量图素材站,用户点击搜索结果进入图片详情页。在用户操作的背后,客户端浏览器向 DNS 服务器查询图片所在服务器,并发送访问请求。
用户请求通过负载均衡(随机选择多个服务器中的一个)访问站点处理请求。服务器从缓存服务中查找图片信息,并从数据库中调取其它信息。我们注意到此时,图片尚未进行色彩渲染计算,便发送“色彩渲染”任务到任务队列。此时该服务所在服务器异步处理任务,适时将结果更新到数据库。
接下来,我们尝试匹配相似图片,以图片标题作为输入,进行全文搜索服务。用户登入系统,系统通过账户服务查找账户信息。最后,系统将该页面查看事件作为日志流处理并在云存储系统中记录,再录入数据仓库,供数据分析师做之后的商业分析。
服务器将渲染的 HTML 页面先经过负载均衡,再返回到用户浏览器。页面包含 Javascript 脚本和 CSS 资源文件,存于与我们的 CDN 相连的云端存储系统中,用户浏览器直接通过 CDN 获取内容。最后,浏览器显式地渲染页面,供用户浏览。
下面,我们就每一个组件详细讨论,做最最基础的介绍,帮你建构认知模型,思考整个前面提到的整个网络服务架构。之后我还会发布其它文章,基于在我司学习到的内容,为大家更有针对性地从实践角度做推荐。
1. DNS
DNS(Domain Name Server)是域名服务器的简称,它是互联网依存的基础设施。简单来说,DNS 提供域名与 IP 地址的键值对查找,例如(http://google.com 域名对应 85.129.83.120 IP 地址),这非常有必要,它让你的电脑通过请求寻路到特定服务器。就好比打电话,域名与 IP 地址的关系类似于联系人和电话号码的关系。以前你需要电话号码簿记录他人的电话号码,现在你需要 DNS 服务器寻找域名对应的 IP 地址。所以你可以把 DNS 想象成互联网世界的电话簿。
这里我们还有很多细节可以深入,暂时先跳过,因为这不是我们基础课的重点。
2. 负载均衡
在详解负载均衡之前,我们先退一步讨论一下应用的纵向扩展和横向扩展。两者有什么区别?简单来说,参考 StackOverflow 的这篇帖子,横向规模扩展意味着通过在资源池中加机器,纵向扩展意味着在已有机器上增强算力(如 CPU,RAM)。
在 web 开发绝大多数情况下,会选择横向扩展。理由很简单,服务器会宕机,网络会断线,数据中心会掉电。多台服务器可以保证你的应用在能够一边停机维护,一边持续工作。换句话说,应用能够“容错”。另外,横向扩展能最小限度地耦合不同后台服务(web 服务器,数据库,等等),使不同服务在不同机器上运行。还有一点,纵向扩展是有上限的,到达一定限度就无法再扩展。世界上也不存在一台超算计算机承载应用的所有计算,典型例子想象一下 Google 的搜索平台,哪怕其它公司达不到这么大的规模。其它公司,比如我司,Storyblocks,任何时候都把服务跑在 150-400 个 AWS EC2 实例上。通过纵向扩展提供算力是相当有挑战的。
回到负载均衡,可以说它是横向扩展的黑魔法。它将传入请求转路到多个服务器中的其中一个,再将响应回传给客户端。多个服务器彼此作为镜像,任意机器都会以同样的方式处理请求。向服务集群分发消息,便不会出现单个服务器过载的情况。
理论上负载均衡就这些要点,很简单直接。当然了,简单的理论背后有更多细节,这篇入门文章里我们不再赘述。
3. Web 应用服务器
从上层角度来看,web 应用服务器相对好理解,它们用来处理核心业务逻辑,处理用户请求,给客户端浏览器返回 HTML。处理这些任务便是与后台基础设施间通信,比如数据库、缓存服务、任务队列、搜索服务、其它微服务和消息/日志队列等等。一般情况下至少两个应用服务器,或者更多,这些应用服务接入负载均衡,处理用户请求。
应用服务器的实现通常需要某种特定语言(Node.js, Ruby, PHP, Scala, Java, C# .NET 等)和对应的 MVC 框架上(Node.js 的 Express、Ruby on Rails、Scala 的 Play、PHP 的 Larave 和 Java 的 Spring 等等)。语言和框架的细节我们这里不做赘述,有兴趣的读者可以自行深入研究。
4. 数据库服务器
任意现代 Web 应用都使用一个甚至多个数据库来存储信息。数据库用来定义数据结构,对数据进行增删改查,高级运算操作等等。多数情况下,web 应用服务器与一个数据库进行直接通信,任务服务器同理。另外,每个后台服务都有一个自己的数据库,并与其它的应用隔离。
尽管在本文中,我们尽量避免深入讨论架构中的某个特定技术,这里我还是想特殊地提一下数据库中的 SQL 和 NoSQL。
SQL(Structured Query Language)全称结构化查询语言,1970 年代发布,提供了查询关系型数据库的一种标准形式,并广为大众接受。SQL 数据库将数据以表的形式存储,通过 ID (通常为 int 整型)这种方式使表之间相互关联。举个简单的例子,我们想要存储用户的历史地址信息。需要准备两张表,用户表 users 和用户地址表 user_addresses,并通过 user_id 进行关联,如下图。表间相关联是通过在 user_addresses 表中使用 user_id 作为外键实现的。
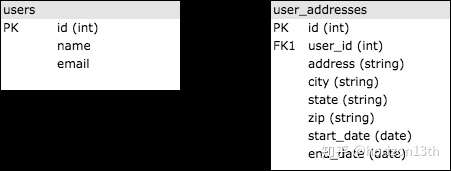
如果你不了解 SQL,这里推荐可汗学院的课程学习。在 web 开发中 SQL 非常普遍,了解其基础作为应用架构还是很有必要的。
NoSQL,如其字面意思,“非-SQL”,是一种新型数据库,用来应对大规模 web 应用中的海量数据(大部分 SQL 不能很好支持横向扩展,只能从某些方面支持纵向扩展)。如果你完全不了解 NoSQL,推荐下列文章:
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
我还想顺便提一点,业界通常使用 SQL 作为 NoSQL 数据库的表层调用,不懂 SQL 的话还是很有必要去学习的,如今的业务场景很难避开它。
5. 缓存服务
缓存服务提供一种简单的键值对数据存储,使存取信息时间复杂度接近 O(1) 。应用内通常使用缓存服务存储运算成本高昂的运算结果,再次请求时从缓存中检索结果,而非在每次请求时都重新计算。缓存内容可以是数据库查询,外部服务调用结果,链接返回的 HTML,等等。下面我们从真实场景中举例:
- 搜索引擎服务(比如百度)会缓存一些常见的查询结果,比如“狗”,“周杰伦”,而不是在每次查询时都实时计算。
- 社交网站服务(比如 Facebook)会缓存每次登陆时用户看到的数据,比如最近博文,好友,等等。这里有一篇 Facebook 如何做缓存的文章。
- 我司(Storyblocks)会缓存服务器端 React 渲染的 HTML 页面,搜索结果,预输入结果,等等。
最常用到的服务器缓存技术是 Redis 和 Memcache。我之后会在其它文章中深入讨论。
6. 任务队列及服务器
大部分 web 应用背后都有异步任务在处理,这些任务不必直接响应用户请求。比如说,谷歌需要爬取整个互联网并建立索引以返回搜索结果,但这实际上并不是在你每次搜索时都实时进行,而是通过异步方式爬取网络结果并更新索引。
异步任务有很多不同的方式来完成,最常用的是任务队列。它包含两部分:正在运行的任务队列,和一或多个处理任务的服务器(通常称为 workers)。
任务队列存储了一系列需要异步运行的任务。最简单的任务调度是 FIFO(先进先出)的方式,不过大部分应用使用按优先级排序的调度方式处理任务。每当一个任务需要被执行,要么使用统一的调度算法,要么是按用户行为按需调度,该任务便被加入队列中等待被执行。
举个例子,我司利用任务队列,赋能后台任务以支持营销活动。我们用后台任务编码多媒体文件如视频图片,处理数据如在 CSV 做元数据标记,聚合用户行为分析,运行邮件服务比如给用户发送重置密码的邮件,等等。我们最初使用 FIFO 调度任务,后来优化为优先队列,以保证时间敏感的操作完成的实时性,比如立马发送重置密码邮件。
任务服务器执行任务时,先查看任务队列中是否有任务需要执行,若有任务便弹出该任务并执行。有很多语言和框架可以在服务器上使用作为任务队列,这里不多讲。
7. 全文检索服务
在一些应用中,为用户提供搜索功能,用户输入文字时(查询语句)应用返回相近结果。这种技术通常指的是“全文检索”,运用倒排索引快速查找包含查询关键字的文档。

上图中例子显示了三个文档标题被转换成倒排索引,通过某些标题关键字能够快速检索文档。通常停用词(英文中的:in、the、with 等,中文中:我、这、和、啊等)不会被加入到索引中。
尽管我们可以直接通过数据库做全文检索,比如 MySQL 支持全文检索,但通常我们会跑一个单独的“搜索服务”计算并存储倒排索引,并提供查询接口。目前主流的全文检索服务是 Elasticsearch,还有 Sphinx,Apache Solr 等选择。
8. 服务
当应用到达一定的规模,通常倾向于拆分其为单个应用,作为“微服务”。外界对这些微服务是不可感知的,但应用内服务间相互通信。比如我司有各种运维服务和计划执行服务:
- 用户服务 存储所有平台网站用户数据,便捷地提供交叉销售商机,以及统一的用户体验。
- 内容服务 存储多媒体文件的元数据,并提供文件下载接口和下载历史信息等。
- 支付服务 提供客户付款信息接口。
- PDF 导出服务 提供统一接口,将 HTML 转换成相对应的 PDF 文件并下载。
9. 数据
如今各大公司成败在于 “如何很好地管理数据”,在应用到达一定规模时规范数据流程。一般来说有:加工数据、存储数据和分析数据,这三个步骤:
- 数据加工 应用响应用户交互事件,将数据发送到数据流处理平台(提供流数据处理接口)进行处理。通常原始数据被转换或加工并传入另一个数据流处理平台。AWS Kinesis 和 Kafka 是此类数据流处理最常用的工具。
- 数据存储 原始数据和转换加工后的数据在云端存储。例如 AWS Kinesis 提供叫做 “firehose” 的配置,将原始数据存储在其云平台 Amazon S3 上,使用起来极其方便。
- 数据分析 转换加工后的数据会加载入数据仓库来做后续分析。我司使用 AWS Redshift 作为数据仓库,很多创业公司也都在用,大型公司一般选择 Oracle 或者其它的数据仓库服务。当数据量十分庞大时,可能需要用类 Hadoop 的 NoSQL MapReduce 技术来做后续分析。
还有一个步骤没有在架构图中绘出:从应用和服务运维数据库中把数据导入数据仓库。例如在我司,我们每晚都会把各个服务的数据存到 AWS Redshift,把核心业务的数据和用户交互行为的数据放在一起,提供给我们的数据分析师一个整体化的数据集。
10. 云存储
“云存储既简单,扩展性又好,方便用户在全网获取、存储、分享数据” —— AWS 云存储服务。任意在本地文件系统存储的文件,你都可以通过云存储存取,并用 HTTP 协议通过 RESTful API 访问并交互。Amazon S3 提供了目前最流行的云存储,我司在其上广泛存储各种东西,从多媒体素材、视频、图片、音频,到 CSS、Javascript 乃至用户行为数据等等。
11. CDN
CDN 指的是内容分发网络,该技术提供一种素材服务,比如存储静态 HTML,CSS,Javascript 和图片。从全网获取这些静态素材比从单个源服务器获取要快的多。它的工作原理是将内容分布在世界各地的边缘服务器上,而不是仅仅放在一个源节点上。比如说,下图中一个西班牙的用户访问某个源节点位于纽约的网站,但是页面的静态素材通过英国的 CDN 边缘服务器载入,这样就避免了冗余的跨大西洋的 HTTP 请求,提快了访问速度。
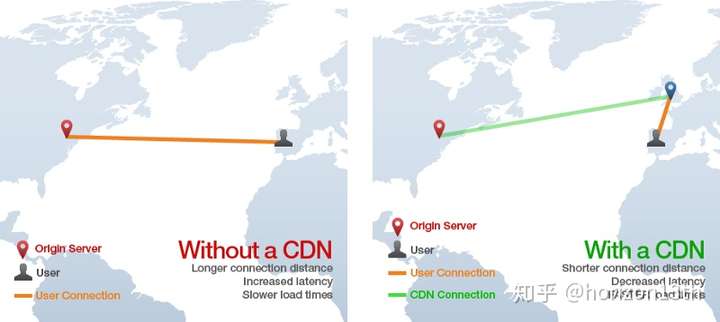
这篇文章 更详细解释了为什么使用 CDN。总的来说,网络应用可以使用 CDN 来存储诸如 CSS、Javascript 和图片视频等素材,甚至静态 HTML 网页。
一些想法
以上便是网络应用架构基础课的全部内容,希望这篇文章对你有帮助。接下来我还会发布进阶课的文章,详细研究上述的某些组件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号