

高性能MySQL笔记(第十一章 可扩展的MySQL)01
p537~578.
概述
这一章描述了很多扩展系统的方法和思路, 并不仅限数据库.
首先, 尽量做好单机优化(优化SQL或者硬件), 因为扩展机器会带来复杂性的提升. 其次, 再考虑读写分离, 即一主多备的策略, 主库写入, 备库读取. 再次, 考虑数据分片, 将数据按类型不同进行分片存储.
容量规划
准备扩展前, 规划峰值, 计算需要多少服务器.
单机扩展
- 优化SQL, 添加索引.
- 增强硬件
单机优化有极限
分库分片
- 将相对独立的业务分开为不同的库
- 将数据按照类型切分为不同的分片
生成全局唯一ID
- 利用Redis生成自增ID
- 使用雪花ID(snowflake), 依赖系统时钟
- 使用GUID, 不推荐, GUID较长且无序, 插入性能很差. 可以考虑有序GUID.
一台机器多MySQL实例
有时候一台机器一个实例无法发挥所有性能, 建多个实例
使用MySQL集群
如NDB Cluster, Percona XtraDB Cluster, Clustrix等
使用NoSQL
部分数据结构简单, 对性能要求高的任务, 可以放到NoSQL中实现
归档数据
将不活跃数据归档清理
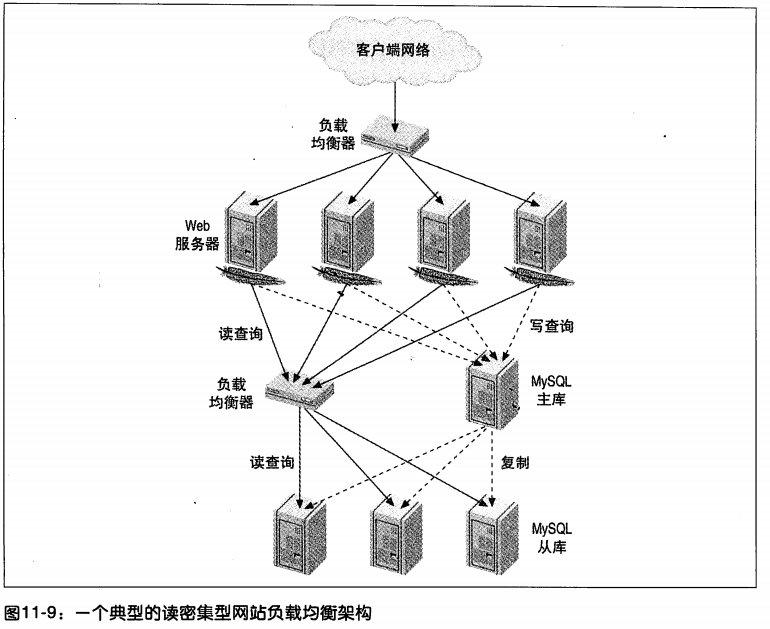
负载均衡
使用Nginx之类的负载均衡器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号