


Dirichlet distribution【转】
Dirichlet distribution--deeply understand

In probability and statistics, the Dirichlet distribution (after Johann Peter Gustav Lejeune Dirichlet), often denoted  , is a family of continuous multivariate probability distributions parametrized by a vector
, is a family of continuous multivariate probability distributions parametrized by a vector 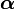 of positive reals. It is the multivariate generalization of the beta distribution. Dirichlet distributions are very often used as prior distributions in Bayesian statistics, and in fact the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution. That is, its probability density function returns the belief that the probabilities of K rival events are xi given that each event has been observedαi − 1 times.
of positive reals. It is the multivariate generalization of the beta distribution. Dirichlet distributions are very often used as prior distributions in Bayesian statistics, and in fact the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution. That is, its probability density function returns the belief that the probabilities of K rival events are xi given that each event has been observedαi − 1 times.
The infinite-dimensional generalization of the Dirichlet distribution is the Dirichlet process.
[edit]Probability density function

The Dirichlet distribution of order K ≥ 2 with parameters α1, ..., αK > 0 has a probability density function with respect to Lebesgue measure on the Euclidean space RK–1 given by
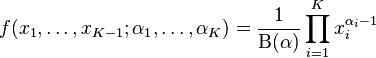
for all x1, ..., xK–1 > 0 satisfying x1 + ... + xK–1 < 1, where xK is an abbreviation for 1 – x1 – ... – xK–1. The density is zero outside this open (K − 1)-dimensional simplex.
The normalizing constant is the multinomial beta function, which can be expressed in terms of the gamma function:
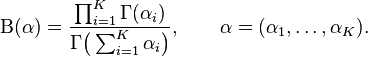
[edit]Support
The support of the Dirichlet distribution is the set of K-dimensional vectors 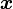 whose entries are real numbers in the interval (0,1); furthermore,
whose entries are real numbers in the interval (0,1); furthermore, 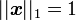 , i.e. the sum of the coordinates is 1. These can be viewed as the probabilities of a K-way categorical event. Another way to express this is that the domain of the Dirichlet distribution is itself a probability distribution, specifically a K-dimensional discrete distribution. Note that the technical term for the set of points in the support of a K-dimensional Dirichlet distribution is the open standard K − 1-simplex, which is a generalization of a triangle, embedded in the next-higher dimension. For example, with K = 3, the support looks like an equilateral triangle embedded in a downward-angle fashion in three-dimensional space, with vertices at (1,0,0),(0,1,0) and (0,0,1), i.e. touching each of the coordinate axes at a point 1 unit away from the origin.
, i.e. the sum of the coordinates is 1. These can be viewed as the probabilities of a K-way categorical event. Another way to express this is that the domain of the Dirichlet distribution is itself a probability distribution, specifically a K-dimensional discrete distribution. Note that the technical term for the set of points in the support of a K-dimensional Dirichlet distribution is the open standard K − 1-simplex, which is a generalization of a triangle, embedded in the next-higher dimension. For example, with K = 3, the support looks like an equilateral triangle embedded in a downward-angle fashion in three-dimensional space, with vertices at (1,0,0),(0,1,0) and (0,0,1), i.e. touching each of the coordinate axes at a point 1 unit away from the origin.
A very common special case is the symmetric Dirichlet distribution, where all of the elements making up the parameter vector have the same value. Symmetric Dirichlet distributions are often used when a Dirichlet prior is called for, since there typically is no prior knowledge favoring one component over another. Since all elements of the parameter vector have the same value, the distribution alternatively can be parametrized by a single scalar value α, called the concentration parameter[citation needed]. When this value is 1[1], the symmetric Dirichlet distribution is equivalent to a uniform distribution over the open standard standard K − 1-simplex, i.e. it is uniform over all points in its support. Values of the concentration parameter above 1 prefer variates that are dense, evenly-distributed distributions, i.e. all probabilities returned are similar to each other. Values of the concentration parameter below 1 prefer sparse distributions, i.e. most of the probabilities returned will be close to 0, and the vast majority of the mass will be concentrated in a few of the probabilities.
More generally, parameter vector is sometimes written as the product αn of a (scalar) concentration parameter α and a (vector) base measure 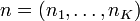 where n lies within the K-1 simplex (ie: it's coordinates ni sum to one). The concentation parameter in this case is larger by a factor of K than the concentration parameter for a symmetric Dirichlet distribution described above. This construction ties in with concept of a base measure when discussing Dirichlet processes and is often used in the topic modelling literature.
where n lies within the K-1 simplex (ie: it's coordinates ni sum to one). The concentation parameter in this case is larger by a factor of K than the concentration parameter for a symmetric Dirichlet distribution described above. This construction ties in with concept of a base measure when discussing Dirichlet processes and is often used in the topic modelling literature.
- ^ If we define the concentration parameter as the sum of the Dirichlet parameters for each dimension, the Dirichlet distribution is uniform with a concentration parameter is K, the dimension of the distribution.
[edit]Properties
[edit]Moments
Let 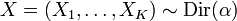 , meaning that the first K – 1 components have the above density and
, meaning that the first K – 1 components have the above density and
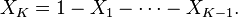
Define  . Then[1]
. Then[1]
![\mathrm{E}[X_i] = \frac{\alpha_i}{\alpha_0},](http://upload.wikimedia.org/wikipedia/en/math/7/6/9/76941af82bb219bd4ecf15bd866df3e7.png)
![\mathrm{Var}[X_i] = \frac{\alpha_i (\alpha_0-\alpha_i)}{\alpha_0^2 (\alpha_0+1)}.](http://upload.wikimedia.org/wikipedia/en/math/3/3/7/3376d062dda46cb0f0a45d24816de873.png)
Furthermore, if 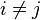
![\mathrm{Cov}[X_i,X_j] = \frac{- \alpha_i \alpha_j}{\alpha_0^2 (\alpha_0+1)}.](http://upload.wikimedia.org/wikipedia/en/math/b/a/9/ba9e62f8f5cedd033827513a27a55be5.png)
(Note that the matrix so defined is singular.).
[edit]Mode
The mode of the distribution is[citation needed] the vector (x1, ..., xK) with

[edit]Marginal distributions
The marginal distributions are Beta distributions[2]:
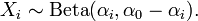
[edit]Conjugate to multinomial
The Dirichlet distribution is conjugate to the multinomial distribution in the following sense: if
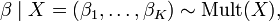
where βi is the number of occurrences of i in a sample of n points from the discrete distribution on {1, ..., K} defined by X, then[citation needed]
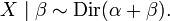
This relationship is used in Bayesian statistics to estimate the hidden parameters, X, of a categorical distribution (discrete probability distribution) given a collection ofn samples. Intuitively, if the prior is represented as Dir(α), then Dir(α + β) is the posterior following a sequence of observations with histogram β.
[edit]Entropy
If X is a Dir(α) random variable, then the exponential family differential identities can be used to get an analytic expression for the expectation of log(Xi) and its associated covariance matrix:[citation needed]
![\operatorname{E}[\log(X_i)] = \psi(\alpha_i)-\psi(\alpha_0)](http://upload.wikimedia.org/wikipedia/en/math/8/6/5/86595ed8c4eca0a796ca0698b39d2f4e.png)
and
![\operatorname{Cov}[\log(X_i),\log(X_j)] = \psi'(\alpha_i) \delta_{ij} - \psi'(\alpha_0)](http://upload.wikimedia.org/wikipedia/en/math/0/6/8/068dd2df102484a265d4afdbc1e553ac.png)
where ψ is the digamma function, ψ' is the trigamma function, and δij is the Kronecker delta. The formula for ![\operatorname{E}[\log(X_i)]](http://upload.wikimedia.org/wikipedia/en/math/0/5/8/05870c109f2bc260e98603eaf2184fd7.png) yields the following formula for the information entropy of X:[citation needed]
yields the following formula for the information entropy of X:[citation needed]
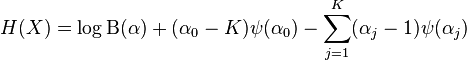
[edit]Aggregation
If 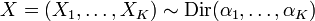 then, if the random variables with subscripts i and j are dropped from the vector and replaced by their sum,
then, if the random variables with subscripts i and j are dropped from the vector and replaced by their sum,

This aggregation property may be used to derive the marginal distribution of Xi mentioned above.
[edit]Neutrality
If , then the vector X is said to be neutral[3] in the sense that XK is independent of X( − K)[citation needed] where
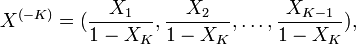
and similarly for removing any of  . Observe that any permutation of X is also neutral (a property not possessed by samples drawn from a generalized Dirichlet distribution[citation needed]).
. Observe that any permutation of X is also neutral (a property not possessed by samples drawn from a generalized Dirichlet distribution[citation needed]).
[edit]Related distributions
If, for 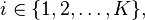
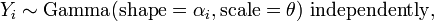
then[citation needed]
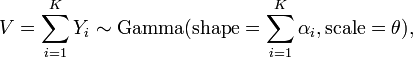
and
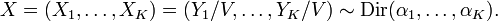
Although the Xis are not independent from one another, they can be seen to be generated from a set of K independent gamma random variables (see [4] for proof) . Unfortunately, since the sum V is lost in forming X, it is not possible to recover the original gamma random variables from these values alone. Nevertheless, because independent random variables are simpler to work with, this reparametrization can still be useful for proofs about properties of the Dirichlet distribution.
[edit]Applications
Multinomial opinions[clarification needed] in subjective logic are equivalent to Dirichlet distributions.
[edit]Random number generation
[edit]Gamma distribution
A fast method to sample a random vector 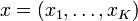 from the K-dimensional Dirichlet distribution with parameters
from the K-dimensional Dirichlet distribution with parameters  follows immediately from this connection. First, draw K independent random samples
follows immediately from this connection. First, draw K independent random samples  from gamma distributions each with density
from gamma distributions each with density

and then set
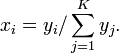
Below is example python code to draw the sample:
params = [a1, a2, ..., ak] sample = [random.gammavariate(a,1) for a in params] sample = [v/sum(sample) for v in sample]
[edit]Marginal beta distributions
A less efficient algorithm[5] relies on the univariate marginal and conditional distributions being beta and proceeds as follows. Simulate x1 from a 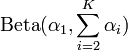 distribution. Then simulate
distribution. Then simulate 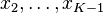 in order, as follows. For
in order, as follows. For 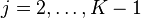 , simulate ϕj from a
, simulate ϕj from a  distribution, and let
distribution, and let  . Finally, set
. Finally, set 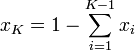 .
.
Below is example python code to draw the sample:
params = [a1, a2, ..., ak] xs = [random.betavariate(params[0], sum(params[1:]))] for j in range(1,len(params)-1): phi = random.betavariate(params[j], sum(params[j+1:])) xs.append((1-sum(xs)) * phi) xs.append(1-sum(xs))
[edit]Intuitive interpretations of the parameters
[edit]The concentration parameter
Dirichlet distributions are very often used as prior distributions in Bayesian inference. The simplest and perhaps most common type of Dirichlet prior is the symmetric Dirichlet distribution, where all parameters are equal. This corresponds to the case where you have no prior information to favor one component over any other. As described above, the single value α to which all parameters are set is called the concentration parameter. If the sample space of the Dirichlet distribution is interpreted as a discrete probability distribution, then intuitively the concentration parameter can be thought of as determining how "concentrated" the probability mass of a sample from a Dirichlet distribution is likely to be. With a value much less than 1, the mass will be highly concentrated in a few components, and all the rest will have almost no mass. With a value much greater than 1, the mass will be dispersed almost equally among all the components. See the article on the concentration parameter for further discussion.
[edit]String cutting
One example use of the Dirichlet distribution is if one wanted to cut strings (each of initial length 1.0) into K pieces with different lengths, where each piece had a designated average length, but allowing some variation in the relative sizes of the pieces. The α/α0 values specify the mean lengths of the cut pieces of string resulting from the distribution. The variance around this mean varies inversely with α0.

[edit]Pólya's urn
Consider an urn containing balls of K different colors. Initially, the urn contains α1 balls of color 1, α2 balls of color 2, and so on. Now perform N draws from the urn, where after each draw, the ball is placed back into the urn with an additional ball of the same color. In the limit as N approaches infinity, the proportions of different colored balls in the urn will be distributed as Dir(α1,...,αK).[6]
For a formal proof, note that the proportions of the different colored balls form a bounded [0,1]K-valued martingale, hence by the martingale convergence theorem, these proportions converge almost surely and in mean to a limiting random vector. To see that this limiting vector has the above Dirichlet distribution, check that all mixed momentsagree.
Note that each draw from the urn modifies the probability of drawing a ball of any one color from the urn in the future. This modification diminishes with the number of draws, since the relative effect of adding a new ball to the urn diminishes as the urn accumulates increasing numbers of balls. This "diminishing returns" effect can also help explain how large α values yield Dirichlet distributions with most of the probability mass concentrated around a single point on the simplex.
[edit]See also
- Beta distribution
- Binomial distribution
- Categorical distribution
- Generalized Dirichlet distribution
- Latent Dirichlet allocation
- Dirichlet process
- Multinomial distribution
- Multivariate Pólya distribution
[edit]References
- ^ Eq. (49.9) on page 488 of Kotz, Balakrishnan & Johnson (2000). Continuous Multivariate Distributions. Volume 1: Models and Applications. New York: Wiley.
- ^ Ferguson, Thomas S. (1973). "A Bayesian analysis of some nonparametric problems". The Annals of Statistics 1 (2): 209–230. doi:10.1214/aos/1176342360.
- ^ Connor, Robert J.; Mosimann, James E (1969). "Concepts of Independence for Proportions with a Generalization of the Dirichlet Distribution". Journal of the American statistical association(American Statistical Association) 64 (325): 194–206. doi:10.2307/2283728. JSTOR 2283728.
- ^ Devroye, Luc (1986). Non-Uniform Random Variate Generation. pp. 594.
- ^ A. Gelman and J. B. Carlin and H. S. Stern and D. B. Rubin (2003). Bayesian Data Analysis (2nd ed.). pp. 582. ISBN 1-58488-388-X.
- ^ Blackwell, David; MacQueen, James B. (1973). "Ferguson distributions via Polya urn schemes". Ann. Stat. 1 (2): 353–355. doi:10.1214/aos/1176342372.

