

python基础作业2
目录
编写一个用户认证装饰器
"""
1.编写一个用户认证装饰器
函数:register login transfer withdraw
基本要求
执行每个函数的时候必须先校验身份 eg: jason 123
拔高练习(有点难度)
执行被装饰的函数 只要有一次认证成功 那么后续的校验都通过
提示:全局变量 记录当前用户是否认证 """
# 定义一个变量记录用户的登录状态
is_login = False
def login_auth(func_name):
def inner(*args, **kwargs):
global is_login
if is_login:
res = func_name(*args, **kwargs)
return res
username = input('username>>>:').strip()
password = input('password>>>>:').strip()
if username == 'jason' and password =='123':
# 将全局名称空间中记录用户登录状态的数据值改为True
# global is_login
is_login = True
res = func_name(*args, **kwargs)
return res
else:
print('用户名或密码错误 无法执行函数')
return inner
@login_auth #register = login_auth(register)
def register():
print('注册功能')
@login_auth
def login():
print('登录功能')
@login_auth
def shopping():
print('购物功能')
register()
login()
shopping()
利用有参装饰器编写多种用户登录校验策略
"""
1.直接写死的 jason 123
2.数据来源于列表 ['jason|123','kevin|321','tony|222']
3.数据来源于文件 jason|123\n tom|321\n
"""
def login_auth(condition):
def outer(func_name):
def inner(*args, **kwargs):
# 获取用户名和密码
username =input('username>>>:').strip()
password=input('password>>>:').strip()
if condition == 'absolute':
if username == 'jason' and password == '123':
res = func_name(*args, **kwargs)
return res
else:
print('用户名或密码错误')
elif condition == 'list_type':
user_list = ['jason|123','tony|321','kevin|222']
user_data = f'{username}|{password}'
if user_data in user_list:
res = func_name(*args, **kwargs)
return res
else:
print('用户名或密码错误')
elif condition == 'file_type':
with open(r'userinfo.txt','r',encoding='utf8') as f:
for line in f:
real_name,real_pwd = line.split('|')
if real_name == username and real_pwd.strip('\n') == password:
res = func_name(*args, **kwargs)
return res
return inner
return outer
@login_auth('absolute')
def index(*args, **kwargs):
print('from index')
@login_auth('list_type')
def func(*args, **kwargs):
print('from func')
@login_auth('file_type')
def foo(*args, **kwargs):
print('from foo')
# index()
# func()
foo()
利用递归函数依次打印列表中每一个数据值
# 2.利用递归函数依次打印列表中每一个数据值
l1 = [1,[2,[3,[4,[5,[6,[7,[8,]]]]]]]]
def getl(l1):
if len(l1) == 0:
return
for i in l1:
if isinstance(i,int):
print(i)
else:
return getl(i)
getl(l1)
# 递归循环解题套路思路:
# 1. 拿到题目先用伪代码实现
# 2. 再用python代码实现,看是否需要重复几次,如果需要重复几次,观察规律,是否每次都变得更简单,如果发现重复几次且变得越来越简单,
# 那就使用循环递归,循环递归要设置结束条件。
#案例举例子:
l1 = [1,[2,[3,[4,[5,[6,[7,[8,]]]]]]]]
for i in l1:
if isinstance(i,int):
print(i)
else:
for j in i:
if isinstance(j,int):
print(j)
else:
for k in j:
if isinstance(k,int):
print(k)
else:
for n in k:
if isinstance(n,int):
print(n)
#遇到上述情况就考虑使用递归,而且考虑最后一层l1是什么状态,比如l1有几个元素之类的
获取用户权限并校验用户登录
"""
有下列用户数据
user_data = {
'1': {'name': 'jason', 'pwd': '123', 'access': ['1', '2', '3']},
'2': {'name': 'kevin', 'pwd': '321', 'access': ['1', '2']},
'3': {'name': 'oscar', 'pwd': '222', 'access': ['1']}
}
并有三个函数
def func1():
pass
def func2():
pass
def func3():
pass
要求: 调用上述三个函数的时候需要从user_data中校验用户身份是否正确
并获取当前登录用户拥有的可执行函数功能编号即键access对应的功能编号列表
func1是1、func2是2、func3是3
并且一旦用户登录成功之后后续函数的调用不再校验用户身份
请思考如何获取函数功能编号
如何校验用户身份
如何校验权限
ps: 装饰器知识
附赠: 实现上述主体功能即可
其他扩展优化功能可暂且不写
"""
"""
1.先写模板
2. 再写用户校验
3. 记录用户登录状态
4. 再考虑用户权限问题
"""
user_data = {
'1': {'name': 'jason', 'pwd': '123', 'access': ['1', '2', '3']},
'2': {'name': 'kevin', 'pwd': '321', 'access': ['1', '2']},
'3': {'name': 'oscar', 'pwd': '222', 'access': ['1']}
}
is_login = {
'login_status': False, # 记录用户是否登录
'user_access': None # 记录登录用户的权限
}
def login_auth(func_id):
def outer(func_name):
def inner(*args, **kwargs):
# 6.先校验用户是否登录
if is_login.get('login_status'):
# 8. 也需要校验功能编号是否在当前登录的用户权限中
if func_id not in is_login.get('user_access'):
print(f'您没有功能编号为{func_id}的函数执行权限')
return
res = func_name(*args, **kwargs)
return res
# 1. 先获取用户的编号
user_id = input('请输入您的编号>>>>:').strip()
# 2. 校验用户编号是否存在
if user_id not in user_data:
print('用户编号不存在 无法完成身份校验')
return
# 3. 获取用户的用户名和密码
username = input('请输入您的用户名>>>>:').strip()
password = input('请输入您的密码>>>>:').strip()
# 4. 获取用户编号对应的真实数据进行比对
user_dict = user_data.get(user_id)
if user_dict.get('name') == username and user_dict.get('pwd') == password:
# 5. 登录成功之后修改字典登录状态
is_login['login_status'] = True
# 6. 记录当前登录用户的权限编号
is_login['user_access'] = user_dict.get('access')
#7. 校验当前函数编号是否在当前用户权限列表内
if func_id in user_dict.get('access'):
res = func_name(*args, **kwargs)
return res
else:
print(f'您没有功能编号为{func_id}的函数执行权限')
else:
print('用户名或密码错误')
return inner
return outer
@login_auth('1')
def func1():
print('from func1')
@login_auth('2')
def func2():
print('from func2')
@login_auth('3')
def func3():
print('from func3')
func1()
func2()
func3()
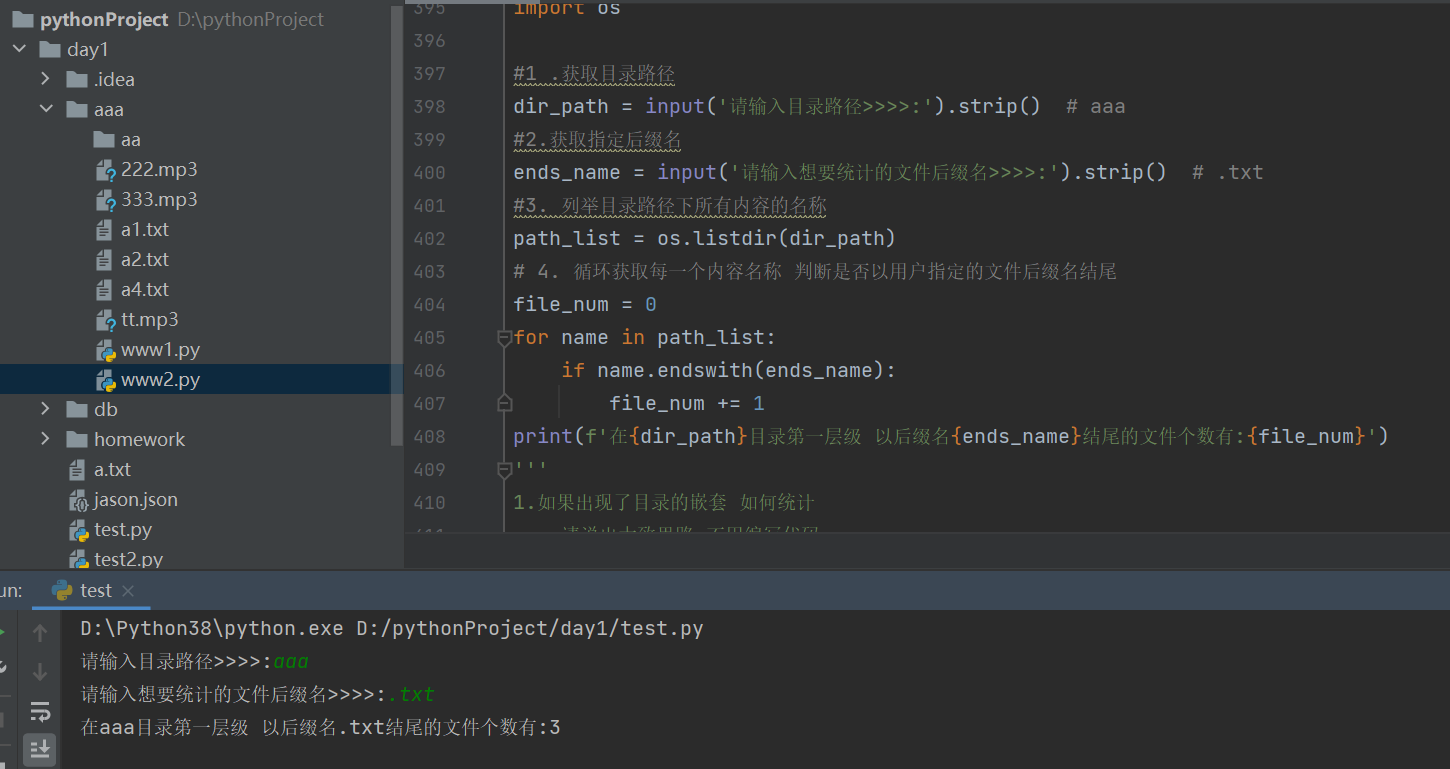
编写一个统计指定文件类型的脚本工具
# 输入指定类型的文件后缀 eg:.txt
# 并给出一个具体路径 之后统计该类型文件在该文件下的个数
# ps:简单实现即可 无需优化
import os
#1 .获取目录路径
dir_path = input('请输入目录路径>>>>:').strip() # aaa
#2.获取指定后缀名
ends_name = input('请输入想要统计的文件后缀名>>>>:').strip() # .txt
#3. 列举目录路径下所有内容的名称
path_list = os.listdir(dir_path)
# 4. 循环获取每一个内容名称 判断是否以用户指定的文件后缀名结尾
file_num = 0
for name in path_list:
if name.endswith(ends_name):
file_num += 1
print(f'在{dir_path}目录第一层级 以后缀名{ends_name}结尾的文件个数有:{file_num}')
'''
1.如果出现了目录的嵌套 如何统计
请说出大致思路 不用编写代码
2.只给一个目录的路径 直接统计该目录下第一层所有类型的内容数量
.txt:3 .py:2 目录:2 课下尝试编写代码
'''
循环打印用户指定的文件内容
"""
3.编程小练习
有一个目录文件下面有一堆文本文件
eg:
db目录
J老师视频合集
R老师视频合集
C老师视频合集
B老师视频合集
文件内容自定义即可 要求循环打印出db目录下所有的文件名称让用户选择
用户选择哪个文件就自动打开该文件并展示内容
涉及到文件路径全部使用代码自动生成 不准直接拷贝当前计算机固定路径
"""
import os
#1. 获取执行文件所在的路径
base_dir = os.path.dirname(__file__)
#2.拼接存储文本文件的目录路径
data_dir=os.path.join(base_dir,'data')
#3.列举目录下所有内容名称
file_name_list = os.listdir(data_dir)
while True: # 添加循环让项目更加的合理
# 4. 循环打印文件名供用户选择查看
for num, file_name in enumerate(file_name_list,start=1): #枚举 主要用于给数据添加编号便于查看和选取
print(num, file_name)
# 5.等待for循环展示完毕之后 获取用户想要查看的编号
choice_num = input('请输入您想要查看的文件编号(q)>>>:').strip() # 获取到的用户输入是字符串 而列表索引取值需要用数字
if choice_num.lower() == 'q':
print('拜拜 下次再见')
break
# 6. 判断用户输入是否是纯数字
if not choice_num.isdigit():
print('编号只能是数字')
continue
choice_num = int(choice_num)
# 7. 判断数字是否在列表的索引范围内
if choice_num not in range(1,len(file_name_list) +1): # range(1,6)
print('编号不在范围内')
continue
# 8.索引取值获取用户想要查看的文件名称
target_name = file_name_list[choice_num-1] # B老师视频合集.txt
# 9. 拼接文件的绝对路径(因为站在执行文件的角度找不到文本文件)
target_file_path = os.path.join(data_dir, target_name)
# 10. 利用文件操作打开文件并读取内容
with open(target_file_path,'r',encoding='utf8') as f:
for line in f:
print(line,end='')
print()
print('--------观看完毕------------')
购物车
import os
import json
# 3.校验用户名是否已存在(拼接存储用户数据的目录 拼接文件路径)
base_dir = os.path.dirname(__file__) # 获取执行文件所在的目录路径
db_dir = os.path.join(base_dir,'db') # 拼接存储用户数据的目录路径
if not os.path.exists(db_dir):
os.mkdir(db_dir)
# 定义一个全局变量存储用户登录相关的信息
is_login = {'username':''} # 一旦用户登录存储用户名 这样方便后续获取用户详细信息
#校验用户是否登录装饰器
def login_auth(func_name):
def inner(*args, **kwargs):
#判断全局字典是否有值
if is_login.get('username'):
res = func_name(*args, **kwargs) # 执行真正被装饰的函数 并用变量名res接收函数的返回值
return res # 返回被装饰函数执行之后的返回值
else:
print('您尚未登录 请先登录')
login()
return inner
def register():
while True: # 添加循环
# 1. 获取用户相关信息
username = input('请输入您的用户名>>>:').strip()
password = input('请输入您的密码>>>>:').strip()
confirm_pwd = input('请确认您的密码>>>:').strip()
# 2. 先校验两次密码是否一致 如果输入错误应该重新执行注册程序
if not password == confirm_pwd:
print('密码不一致')
continue
#拼接当前用户名构成的文件路径 如果已存在表示用户名已存在 不存在则可以完成用户注册
user_file_path = os.path.join(db_dir,f'{username}.json')
if os.path.exists(user_file_path):
print('用户名已存在,请重新注册')
continue
# 创建用户字典数据并序列化到文件中
user_dict = {
'username': username,
'password': password,
'balance': 15000,
'shop_car':{}
}
with open(user_file_path,'w',encoding='utf8') as f:
json.dump(user_dict,f)
print(f'用户{username}注册成功')
break
def login():
while True:
# 1.获取用户名
username = input('请输入您的用户名(按q退出)>>>:').strip()
if username.lower() == 'q':
break
# 2.判断用户名是否存在
user_file_path = os.path.join(db_dir,f'{username}.json')
if not os.path.exists(user_file_path):
print('用户名不存在')
continue
# 3.获取用户输入的密码
password = input('请输入您的密码>>>:').strip()
# 4.获取当前用户对应的真实数据
with open(user_file_path,'r',encoding='utf8') as f:
user_dict = json.load(f)
# 5. 判断用户输入的密码和文件中存储的真实密码是否一致
if not password == user_dict.get('password'):
print('密码错误')
continue
# 6.完成登录操作
# 修改全局字典 记录当前登录用户名
is_login['username'] = username
print(f'{username}登录成功')
return
@login_auth
def add_shop_car():
# 8.构造临时小字典存储商品信息
temp_shop_car = {}
while True:
# 1.获取商品信息(目前是写死的 后期可以动态获取)
good_list = [
['挂壁面',3],
['印度飞饼',22],
['极品木瓜', 666],
['土耳其土豆',999],
['伊拉克拌面',1000],
['董卓戏张飞公仔',2000],
['仿真木偶',10000 ]
]
#2.循环打印商品信息供用户选择
for num,good_data in enumerate(good_list): # 0 []
print(f'商品编号:{num} | 商品名称:{good_data[0]} | 商品单价:{good_data[1]}')
# 3.获取用户输入的商品编号
choice_num = input('请输入您想要购买的商品编号(q)>>>:').strip()
'''10.添加结束标志 用于保存购物车数据'''
if choice_num.lower() == 'q':
# 11.获取当前登录用户的字典数据
user_file_path = os.path.join(db_dir,f'{is_login.get("username")}.json')
with open(user_file_path,'r',encoding='utf8') as f:
user_data_dict = json.load(f)
old_shop_car = user_data_dict.get('shop_car') # {'印度飞饼':[10,22]}
# 12.保存购物车数据
"""
user_data_dict['shop_car'] = temp_shop_car 不能直接替换 可能有原先的数据
{"username":"jason","password":"123","balance":15000,"shop_car":{'印度飞饼':[10,22]}}
{'印度飞饼':[1888,22],'极品木瓜':[10,666]}
"""
for g_name,g_list in temp_shop_car.items():
if g_name in old_shop_car:
old_shop_car[g_name][0] += temp_shop_car[g_name][0]
else:
old_shop_car[g_name] = g_list
user_data_dict['shop_car'] = old_shop_car
with open(user_file_path,'w',encoding='utf8') as f:
json.dump(user_data_dict,f,ensure_ascii=False)
print('商品添加成功 欢迎下次再来')
break
# 4.判断编号是否是纯数字
if not choice_num.isdigit():
print('商品编号必须是纯数字')
continue
choice_num = int(choice_num)
# 5.判断数字是否超出范围
if choice_num not in range(len(good_list)):
print('商品编号不在已存在的商品编号内 无法选择购买')
continue
# 6.根据商品编号获取商品信息
target_good_list = good_list[choice_num] # ['印度飞饼',22]
# 7.获取想要购买的商品个数
good_num = input(f'请输入您想要购买的{target_good_list[0]}的商品数量>>>:').strip()
if not good_num.isdigit():
print('商品数量必须是纯数字')
continue
good_num = int(good_num)
# 9.写入临时小字典中
"""
temp_shop_car [target_good_list[0]] = [good_num,target_good_list[1]]
# t={'印度飞饼':[10,22]} t['印度飞饼'] = [10,22] 字典的键存在会替换值
t = {'印度飞饼': [10, 22]}
t['印度飞饼'] = [10, 22] 字典的键存在会替换值
判断键是否已存在 如果存在则回去值列表 将第一个数据值数字自增用户输入的数量
"""
good_name = target_good_list[0]
if good_name in temp_shop_car:
temp_shop_car.get(good_name)[0] += good_num
else:
temp_shop_car[good_name] = [good_num,target_good_list[1]]
@login_auth
def pay_shop_car():
# 1.拼接当前登录用户文件路径
user_file_path = os.path.join(db_dir,f'{is_login.get("username")}.json')
# 2.读取用户数据
with open(user_file_path,'r',encoding='utf8') as f:
user_data_dict = json.load(f)
# 3.获取当前用户购物车数据及账户余额
shop_car = user_data_dict.get('shop_car') #{'印度飞饼':[10,22],'公仔':[100,100]}
if not shop_car:
print('您的购物车空空如也 赶紧取添加商品吧')
return
current_balance = user_data_dict.get('balance')
# 4.统计购物车商品总价
total_money = 0
for g_list in shop_car.values(): #[10,22] [100,100]
total_money += g_list[0] * g_list[1]
# 5.比较余额是否充足
if total_money > current_balance:
print('账户余额不足,再想想办法吧')
return
user_data_dict['balance'] -= total_money
# 6.清空购物车
user_data_dict['shop_car'] = {}
with open(user_file_path,'w',encoding='utf8') as f:
json.dump(user_data_dict,f)
print(f'尊敬的{is_login.get("username")} 您本次消费{total_money} 卡上余额剩余{user_data_dict.get("balance")}')
func_dict = {
'1':register,
'2':login,
'3':add_shop_car,
'4':pay_shop_car
}
while True:
print(
"""
1.注册功能
2.登录功能
3.添加购物车
4.结算购物车
""")
choice_num = input('请选择您想要执行的功能编号>>>>:').strip()
if choice_num in func_dict:
func_name = func_dict.get(choice_num) # 获取函数名
func_name() # 调用函数名
else:
print('功能编号不存在 请重新输入')
利用正则打印指定数据
"""
网络爬虫没有我们现在接触的那么简单
有时候页面数据无法直接拷贝获取
有时候页面还存在防爬机制 弄得不好ip会被短暂拉黑
"""
1.直接拷贝页面数据到本地文件
2.读取文件内容当做字符串处理
3.编写正则筛选内容
import re
# 1.文件操作读取文本内容
with open(r'红牛.html','r',encoding='utf8') as f:
# 2.直接读取全部内容 无需优化
data = f.read()
# 3.研究各部分数据的特征 编写相应的正则表达式
"""
思路1:
一次性获取每个公司全部的数据
分部分挨个获取最后统一整合
"""
#一次性获取全部数据
#内容来源于view-source:http://www.redbull.com.cn/about/branch
# res = re.findall("<h2>(.*?)</h2><p class='mapIco'>(.*?)</p><p class='mailIco'>(.*?)</p><p class='telIco'>(.*?)</p>",data)
# print(res) #[(),(),(),()]
comp_title_list = re.findall('<h2>(.*?)</h2>',data)
comp_address_list = re.findall("<p class='mapIco'>(.*?)</p>",data)
comp_email_list = re.findall("<p class='mailIco'>(.*?)</p>",data)
comp_phone_list = re.findall("<p class='telIco'>(.*?)</p>",data)
res=zip(comp_title_list,comp_address_list,comp_email_list,comp_phone_list)
# print(res)
# print(list(res))
# for data_tuple in res:
#方式一打印
# print(f"""
# 公司名称:{data_tuple[0]}
# 公司地址:{data_tuple[1]}
# 公司邮编:{data_tuple[2]}
# 公司电话:{data_tuple[3]}
# """)
# 方式二打印
# print("""
# 公司名称:%s
# 公司地址:%s
# 公司邮编:%s
# 公司电话:%s
# """ %data_tuple)
with open(r'com_info.txt','w',encoding='utf8') as f:
for data_tuple in res:
print("""
公司名称:%s
公司地址:%s
公司邮编:%s
公司电话:%s
""" % data_tuple)
f.write("""
公司名称:%s
公司地址:%s
公司邮编:%s
公司电话:%s\n
"""%data_tuple)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗