[nlp] 浅层句法分析
有关自然语言,特别是语义方面的诸多问题仍未得到解决。目前,完全句法分析、浅层句法分析、信息抽取、词义消歧、潜在语义分析、文本蕴含和指代消解。这些技术都不能完美或者完全的翻译出语言的本义。与程序语言不同,人类语言不具备完整的逻辑结构。
句法分析的基本任务是确定句子的语法结构或句子中词汇之间的依存关系
浅层句法分析(shallow parsing),也叫部分句法分析(partial parsing)或语块分析(chunk parsing),来自然语言处理领域出现的一种新的语言处理策略。它是与完全句法分析相对的,完全句法分析要求通过一系列分析过程,最终得到句子的完整的句法树。而浅层句法分析则不要求得到完全的句法分析树,它只要求识别其中的某些结构相对简单的成分,如非递归的名词短语、动词短语等。这些识别出来的结构通常被称作语块(chunk),语块和短语这两个概念通常可以换用。
浅层句法分析的两个子任务:
- 语块的识别和分析
- 语块之间的依附关系分析
在文章《自然语言处理NLP(9)——句法分析c:局部句法分析、依存关系分析》中,作者提到在局部句法分析中,可以将组块的分析转化成序列标注问题解决。
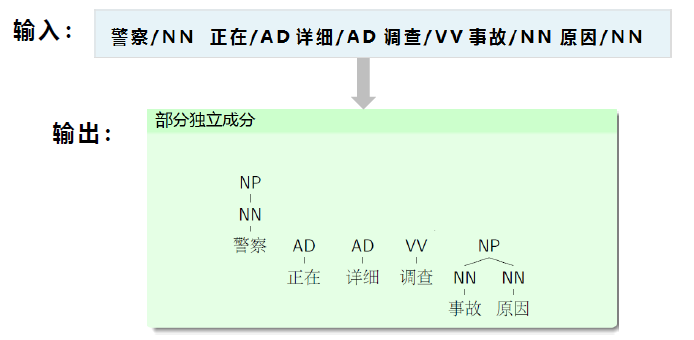
《汉语组块分析研究综述(2013年)》 李业刚,黄河燕
组块分析作为浅层句法分析的代表,既可以满足很多语言信息处理系统对于句法功能的需求,又可以作为子任务,在词法分析和完全句法分析以及语义分析中间架起一座桥梁,为句子进行进一步深入分析提供有力的支持,因此众多的研究将注意力集中于组块分析上。该文主要对组块的定义和分类、组块识别方法、组块的标注和评测以及组块内部关系分析等几方面的研究进展进行详细的综述。最后,探讨了组块分析存在的问题并对未来的发展方向进行了展望。
完全句法分析是当前自然语言处理中的一个难点和重点。为了降低完全句法分析的难度,研究人员提出了“分而治之”的策略,进行浅层分析也就是组块分析。在自然语言处理领域,组块分析对于句法分析,机器翻译和信息检索等都具有重要的理论意义与实际应用价值。本文对汉语和英语组块的分析方法和技术进行了研究。
本文首先分析了当前句法分析所面临的困境和组块分析的重要性,并介绍了组块分析的研究现状以及组块分析的两条技术路线,随后对组块的界定方法进行了探讨。
本文工作的目的之一是为建立英汉双语在短语级上的对齐提供良好的组块识别基础。因此,在现有研究的基础上,本文参考 CoNLL-2000会议所定义的英语组块的标准,从句法功能的角度考虑,定义了5种组块类型。本文所用的实验语料是从宾州中英文树库中获取的,也就是根据本文对组块的定义和分类,从宾州中英文树库的句法树中获取汉语和英语组块库,进而转化成本文所需的实验语料。支持向量机(SVM)作为一种新兴的统计学习算法,在解决小样本、非线性以及高特征维数的样本学习问题中表现了其特有的优势。
本文设计实现了一种SVM和基于转换的错误驱动学习相结合的组块识别方法。在SVM的组块识别的基础上,加入了基于转换的错误驱动学习方法对SVM的分析结果进行校正。将SVM分析结果和正确结果进行比较,不断学习和反馈,生成转换规则集合。转换规则较好地处理了语言现象中的特殊情况,进一步提高了SVM的识别结果。实验结果表明将SVM与基于转换的错误驱动学习相结合进行组块识别,有效地提高了组块识别的性能。本文设计了不同的实验方案,对影响SVM组块识别结果的各种因素:组块的定义,特征向量中的特征选取,语料库的规模进行了分析,实验中得出的结论对组块分析的研究工作有较好的参考作用。
句法分析与浅层句法分析
摘自《浅谈自然语言处理基础》,据说作者写了一个月
句法分析分为句法结构分析和依存关系分析两种。以获取整个句子的句法结构为目的的称为完全句法分析,而以获得局部成分为目的的语法分析称为局部分析,依存关系分析简称依存分析。
一般而言,句法分析的任务有三个:
-
判断输出的字符串是否属于某种语言
-
消除输入句子中词法和结构等方面的歧义
-
分析输入句子的内部结构,如成分构成、上下文关系等。
(第二三个任务一般是句法分析的主要任务)
一般来说,构造一个句法分析器需要考虑两部分工作:一部分是语法的形式化表示和词条信息描述问题,形式化的语法规则构成了规则库,词条信息等由词典或同义词表等提供,规则库与词典或同义词表构成了句法分析的知识库;另一部分就是基于知识库的解析算法了。
语法形式化属于句法理论研究的范畴,目前在自然语言处理中广泛使用的是上下文无关文法(CFG)和基于约束的文法,后者又称合一文法。
简单的讲,句法结构分析方法可以分为基于规则的分析方法和基于统计的分析方法两大类。
基于规则的分析方法
基于规则的句法结构分析方法的基本思路是,由人工组织语法规则,建立语法知识库,通过条件约束和检查来实现句法结构歧义的消除。
根据句法分析树形成方向的区别,人们通常将这些方法划分为三种类型:自顶向下的分析方法,自底向上的分析方法和两者相结合的分析方法。自顶向下分析算法实现的是规则推导的过程,分析树从根结点开始不断生长,最后形成分析句子的叶结点。而自底向上分析算法的实现过程恰好想法,它是从句子符号串开始,执行不断规约的过程,最后形成根节点。
基于规则的语法结构分析可以利用手工编写的规则分析出输入句子所有可能的句法结构;对于特定领域和目的,利用有针对性的规则能够较好的处理句子中的部分歧义和一些超语法(extra-grammatical)现象。
但对于一个中等长度的输入句子来说,要利用大覆盖度的语法规则分析出所有可能的句子结构是非常困难的,而且就算分析出来了,也难以实现有效的消歧,并选择出最有可能的分析结果;手工编写的规则带有一定的主观性,还需要考虑到泛化,在面对复杂语境时正确率难以保证;手工编写规则本身就是一件大工作量的复杂劳动,而且编写的规则领域有密切的相关性,不利于句法分析系统向其他领域移植。
基于规则的句法分析算法能够成功的处理程序设计语言的编译,而对于自然语言的处理却始终难以摆脱困境,是因为程序设计语言中使用的知识严格限制的上下文无关文法的子类,但自然语言处理系统中所使用的形式化描述方法远远超过了上下文无关文法的表达能力;而且人们在使用程序设计语言的时候,一切表达方式都必须服从机器的要求,是一个人服从机器的过程,这个过程是从语言的无限集到有限集的映射过程,而在自然语言处理中则恰恰相反,自然语言处理实现的是机器追踪和服从人的语言,从语言的有限集到无限集推演的过程。
浅层句法分析
由于完全语法分析要确定句子所包含的全部句法信息,并确定句子中各成分之间的关系,这是一项十分苦难的任务。到目前为止,句法分析器的各方面都难以达到令人满意的程度,为了降低问题的复杂度,同时获得一定的句法结构信息,浅层句法分析应运而生。
浅层句法分析将句法分析分解为两个主要子任务,一个是语块的识别和分析,另一个是语块之间的依附关系分析。其中,语块的识别和分析是主要任务。在某种程度上说,浅层句法分析使句法分析的任务得到了简化,同时也有利于句法分析系统在大规模真实文本处理系统中迅速得到应用。
基本名词短语(base NP)是语块中的一个重要类别,它指的是简单的、非嵌套的名词短语,不含有其他子项短语,并且base NP之间结构上是独立的。示例如下:

base NP识别就是从句子中识别出所有的base NP,根据这种理解,一个句子中的成分和简单的分为baseNP和非base NP两类,那么base NP识别就成了一个分类问题。
base NP的表示方法有两种,一种是括号分隔法,一种是IOB标注法。括号分隔法就是将base NP用方括号界定边界,内部的是base NP,外部的不属于base NP。IOB标注法中,字母B表示base NP的开端,I表示当前词语在base NP内,O表示词语位于base NP之外。
基于SVM的base NP识别方法
由于base NP识别是多值分类问题,而基础SVM算法解决的是二值分类问题,所以一般可以采用配对策略(pairwise method)和一比其余策略(one vs. other method)。
SVM一般要从上下文的词、词性、base NP标志中提取特征来完成判断。一般使用的词语窗口的长度为5(当前词及其前后各两个词)时识别的效果最好。
基于WINNOW的base NP识别方法
WINNOW是解决二分问题的错误驱动的机器学习方法,该方法能从大量不相关的特征中快速学习。
WINNOW的稀疏网络(SNoW)学习结构是一种多类分类器,专门用于处理特征识别领域的大规模学习任务。WINNOW算法具有处理高维度独立特征空间的能力,而在自然语言处理中的特征向量恰好具有这种特点,因此WINNOW算法也常用于词性标注、拼写错误检查和文本分类等等。
简单WINNOW的基本思想是,已知特征向量和参数向量和实数阈值θ,先将参数向量均初始化为1,将训练样本代入,求特征向量和参数向量的内积,将其与θ比较,如果大于θ,则判定为正例,小于θ则判定为反例,将结果与正确答案作比较,依据结果来改变权值。
如果将正例估计成了反例,那么对于原来值为1的x,把它的权值扩大。如果将反例估计成了正例,那么对于原来值为1的x,把它的权值缩小。然后重新估计重新更改权重,直到训练完成。
这其实让我想到了LR算法,因为LR算法也是特征向量与参数向量的内积,最后将其送到Sigmoid函数中去拿到判定结果,然后大于0.5的为正例,小于0.5的为反例,实际上只要反过来,Sigmod函数输出0.5时候的输入就是WINNOW算法里的那个实数阈值θ。但是区别在于WINNOW算法只判定大小,不判定概率,而LR利用Sigmoid函数给出了概率。LR利用这给出的概率,通过使训练集的生成概率最大化来调整参数,而WINNOW则是直接朴素的错误情况来增大或缩小相关参数。目测LR因为使用了梯度下降,它的收敛速度要快于WINNOW,而WINNOW的优势则在于可以处理大量特征。
基于CRF的base NP识别方法
基于CRF的base NP识别方法拥有与SVM方法几乎一样的效果,优于基于WINNOW的识别方法、基于MEMM的识别方法和感知机方法,而且基于CRF的base NP识别方法在运行速度上较其他方法具有明显优势。
基于浅层句法分析的应用
以下书籍、文章中的应用方向均用加粗体标注。
《机器翻译中的英语浅层句法分析》马建军、黄德根著
书籍,2015年
本书主要研究了面向英汉机器翻译的英语浅层句法研究,内容包括词性标注、名词短语识别和介词短语识别,其目的是解决机器翻译中的结构歧义问题。与其他研究不同,本研究句法分析所基于的语法体系是语言学领域的一个主流语法,即系统功能语法,而不是自然语言处理领域所常用的计算机形式语法。
《利用浅层句法分析提取特征的词义消歧》孙超、张仰森
文章,计算机工程与设计,2010,Vol.31(21),pp.4704-4707 [同行评议]
针对如何从文本中提取高质量消歧特征的问题,提出了基于浅层句法分析的消歧特征提取算法,建立了以语块分析识别为核心的特征提取模型。该模型通过对实词类型语块识别、分析中心词语词性和虚词类型语块分析,得到多义词的消歧特征。以北京大学计算语言研究所的现代汉语基本标注语料库为基础,选取了44个多义词,通过使用最大熵消歧模型进行训练和预测实验,准确率达到了78.71%。
《基于浅层句法分析的中文语义角色标注研究》王鑫、孙薇薇、穗志方
文章,中文信息学报 - Journal of Chinese Information Processing,2011,Vol.25(1),pp.116-122
语义角色标注是获取语义信息的一种重要手段。许多现有的语义角色标注都是在完全句法分析的基础上进行的,但由于现阶段中文完全句法分析器性能比较低,基于自动完全句法分析的中文语义角色标注效果并不理想。因此该文将中文语义角色标注建立在了浅层句法分析的基础上。在句法分析阶段,利用构词法获得词语的"伪中心语素"特征,有效缓解了词语级别的数据稀疏问题,从而提高了句法分析的性能,F值达到了0.93。在角色标注阶段,利用构词法获得了目标动词的语素特征,细粒度地描述了动词本身的结构,从而为角色标注提供了更多的信息。此外,该文还提出了句子的“粗框架”特征,有效模拟了基于完全句法分析的角色标注中的子类框架信息。该文所实现的角色标注系统的F值达到了0.74,比前人的工作(0.71)有较为显著的提升,从而证明了该文的方法是有效的。
《基于浅层句法分析的术语抽取研究》 刘俊杰、黄圆圆、任智军、崔碧莹
文章,微计算机信息,2010,Vol.26(18),pp.180-182
本文提出基于浅层句法分析的术语抽取的算法,其基本思想是大规模无标注真实科技文本库中,通过基于概率模型的句法分析对句子进行句子切分,提取形成术语数据库。在此方法基础上,我们对管理科学各学科领域的技术文本自动提取出管理科学关键词体系。实验证明基于浅层句法分析的术语自动抽取技术对术语抽取有很好的成效。
浅层句法分析的实现
《随机森林及其改进模型在浅层句法分析中的应用》魏松
文章,计算机工程与应用,2008,Vol.44(9),pp.159-161
文章首先阐述浅层句法分析可以转化为一个分类问题,然后论述了如何用随机森林的方法来完成这个分类任务。接下来对随机森林算法进行了改进,即基本模型+Bootstrap方式。实验结果显示,针对CoNLL2000提出的浅层句法分析任务,基本模型+Bootstrap方式的Fβ值可以达到92.25%,较基本模型有明显提高。
《基于实例学习在浅层句法分析中的应用》 徐睿、王惠临
文章,情报科学 - Information Science,2010,Issue 2,pp.248-251
机器学习技术在自然语言处理中的应用是一个研究热点。简单介绍并分析、评价了机器学习的方法之一——基于实例学习。就其在自然语言处理关键环节之一——浅层句法分析方面进行实验研究并分析其结果。最后,讨论了基于实例学习在自然语言处理中的应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号