[pyqt] 基于特征匹配的动漫头像检索系统(一)
引言
大三下的某大作业项目,要求是做一个图像检索系统。根据名字检索大概也可以吧,但思来想去还是选择带有图片识别的功能为基础进行检索。定位取巧在头像上面,因为头像图片较小。程序使用的是pyQt,需要实现的主要功能是鼠标绘制黑白图片并通过特征匹配进行检索,次要功能是根据图像的主要颜色进行分类显示,并对surf匹配算法进行了一定优化。
爬取图像
在网上找了一段简单的python爬虫代码,在百度图片上搜索爬取动漫头像并保存至本地。页数部分仿佛有bug,不过问题不大,一共爬了600张。
# 配置以下模块
import requests
import re
import os
import time
# 1.运行 py源文件
# 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
# 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片
# 获取图片url连接
def get_parse_page(pn, name, searchName):
for i in range(int(pn)):
# 1.获取网页
print('正在获取第{}页'.format(i+1))
# 百度图片首页的url
# name是你要搜索的关键词
# pn是你想下载的页数
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s' %(searchName)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400'}
# 发送请求,获取相应
response = requests.get(url, headers=headers)
html = response.content.decode()
# print(html)
# 2.正则表达式解析网页
# "objURL":"http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg"
results = re.findall('"objURL":"(.*?)",', html) # 返回一个列表
# 根据获取到的图片链接,把图片保存到本地
save_to_txt(results, name, i)
# 保存图片到本地
def save_to_txt(results, name, i):
j = 0
# 在当目录下创建文件夹
if not os.path.exists('./' + name):
os.makedirs('./' + name)
# 下载图片
for result in results:
print('正在保存第{}个'.format(j))
try:
pic = requests.get(result, timeout=10)
time.sleep(1)
except:
print('当前图片无法下载')
j += 1
continue
# 可忽略,这段代码有bug
# file_name = result.split('/')
# file_name = file_name[len(file_name) - 1]
# print(file_name)
#
# end = re.search('(.png|.jpg|.jpeg|.gif)$', file_name)
# if end == None:
# file_name = file_name + '.jpg'
# 把图片保存到文件夹
file_full_name = './' + name + '/' + str(i) + '-' + str(j) + '.jpg'
with open(file_full_name, 'wb') as f:
f.write(pic.content)
j += 1
# 主函数
if __name__ == '__main__':
searchName = input('请输入你要下载的关键词:')
name = '动漫头像'
pn = input('你想下载前几页:')
get_parse_page(pn, name, searchName)
线条化处理
在我们的构想中,用户使用鼠标进行图像的绘制,这意味着我们不能对用户的绘画水平有过高的要求。因为大部分用户没有条件使用数位板绘制,而采用鼠标绘制的难度较大,无论用户有无绘画基础,基本只能画出人物的基本特征,对于一般的动漫作品而言,绘制比较粗糙。加之上色之后颜色匹配会因为主观判断产生歧义,并且上色效果也一般,我们只打算进行用户作品的线条采集,将其与数据集中的内容进行对比与匹配。
因此,我们首先将数据集进行了预处理,将彩色图片处理为黑白线条画,便于之后与手绘图片进行比对。
PIL库的线条提取
PIL库中有con_image = image.filter(ImageFilter.CONTOUR) 函数可以直接提取线条,但效果并不好。

使用cv2进行线条提取
cv2中有canny函数可以直接进行边缘提取,首先转换为灰度图,之后调用函数即可。
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 75, 150, apertureSize=3)
效果与PIL库的函数相比,线条提取的完整度明显较强。

但是当图像有噪点时,提取效果依旧稍差。这是因为cv2中的canny函数未包含降噪部分,需要手动将图片中的噪声消除。
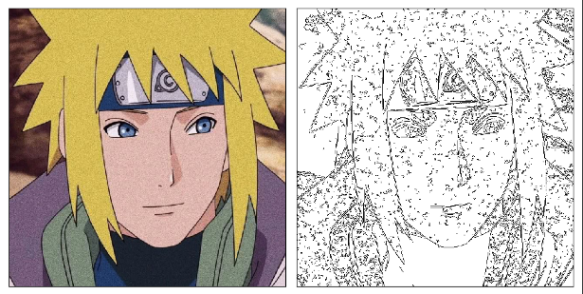
此时使用cv2中的中值滤波函数进行处理,注意,如果模糊程度过高会造成部分线条的丢失。
blur = cv.medianBlur(gray, 3)

此时发现线条依旧过细,鼠绘的时候线条必然粗很多,因为太细了看不清。这里没有找到好的线条加粗方式,只能用粗暴的手段进行原画的上下左右平移叠加,最后得到较粗的线条。
imgTemp = np.zeros((500, 500), np.uint8)
imgTemp[0:499, 0:500] = edges[1:500, 0:500]
edges = cv.add(edges, imgTemp)
imgTemp = np.zeros((500, 500), np.uint8)
imgTemp[0:500, 0:499] = edges[0:500, 1:500]
edges = cv.add(edges, imgTemp)
imgTemp = np.zeros((500, 500), np.uint8)
imgTemp[1:500, 0:500] = edges[0:499, 0:500]
edges = cv.add(edges, imgTemp)
imgTemp = np.zeros((500, 500), np.uint8)
imgTemp[0:500, 1:500] = edges[0:500, 0:499]
edges = cv.add(edges, imgTemp)
最后进行一次反色,完成图片的预处理流程(上面的截图均为反色之后的截图)。
cv.bitwise_not(edges, edges)
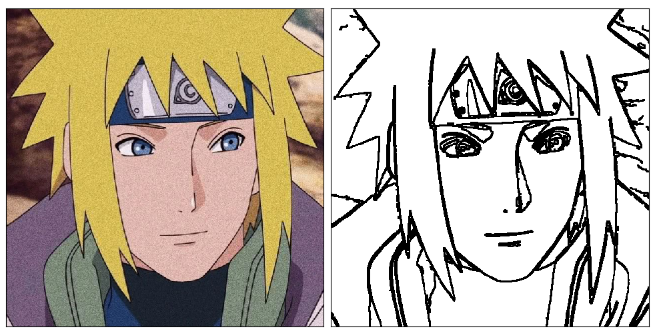
四代真帅

 浙公网安备 33010602011771号
浙公网安备 33010602011771号