Pytorch入门下 —— 其他
本节内容参照小土堆的pytorch入门视频教程。
现有模型使用和修改
pytorch框架提供了很多现有模型,其中torchvision.models包中有很多关于视觉(图像)领域的模型,如下图:

下面以VGG16为例将讲解如何使用以及更改现有模型:
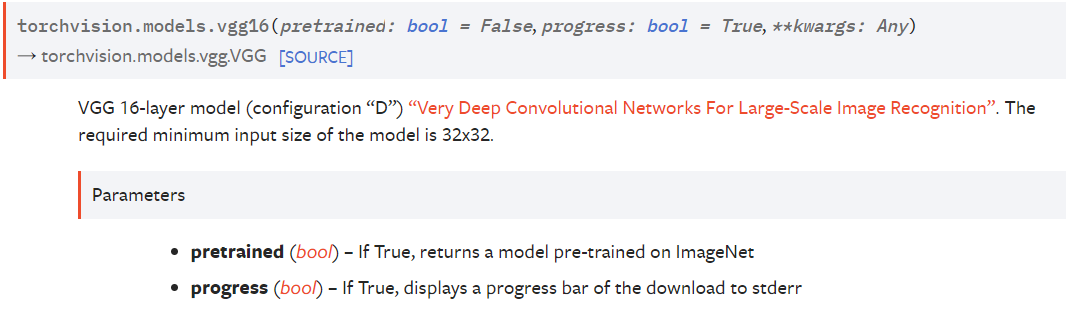
pretrained为True,返回在ImageNet上预训练过的模型;pregress为True在下载模型时会通过标准错误流输出进度条。
创建如下脚本并运行:
from torchvision import models
# 创建预训练过的模型,并输出进度
vgg16_pretrained = models.vgg16(pretrained=True, progress=True)
# 创建没训练过的模型,不输出进度
vgg16 = models.vgg16(pretrained=False, progress=False)
# 控制台输出模型结构
print(vgg16_pretrained)
控制台输出如下:
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to C:\Users\winlsr/.cache\torch\hub\checkpoints\vgg16-397923af.pth
100.0%
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
如上输出中的的VGG表示模型的class名,features是VGG含有的一个Sequential组件(Module),avgpool是AdaptiveAvgPool2d组件,classifier同样为Sequential组件。
创建如下脚本并运行:
from torchvision import models
from torch import nn
# 创建预训练过的模型,并输出进度
vgg16_pretrained = models.vgg16(pretrained=True, progress=True)
# 创建没训练过的模型,不输出进度
vgg16 = models.vgg16(pretrained=False, progress=False)
# 给vgg添加一个线性Module(层)
vgg16_pretrained.add_module("linear", nn.Linear(1000, 10))
# 控制台输出模型结构
print(vgg16_pretrained)
输出如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(linear): Linear(in_features=1000, out_features=10, bias=True) # 添加成功
)
创建如下脚本并运行:
from torchvision import models
from torch import nn
# 创建预训练过的模型,并输出进度
vgg16_pretrained = models.vgg16(pretrained=True, progress=True)
# 创建没训练过的模型,不输出进度
vgg16 = models.vgg16(pretrained=False, progress=False)
# 删除 features 组件
del vgg16_pretrained.features
# 在 classifier 组件中添加组件
vgg16_pretrained.classifier.add_module("7", nn.Linear(1000, 10))
# 修改 classifier 组件中的第1个组件为 softmax(0开始)
vgg16_pretrained.classifier[1] = nn.Softmax()
# 控制台输出模型结构
print(vgg16_pretrained)
输出如下:
VGG(
# 删除features成功
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
# 修改为softmax成功
(1): Softmax(dim=None)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
# 添加成功
(7): Linear(in_features=1000, out_features=10, bias=True)
)
)
模型的保存与读取
pytorch中有两种模型保存和读取方式:
执行如下脚本:
from _07_cifar10_model.cifar10_model import MyModel
import torch
cifar10_model = MyModel()
# 方式1:保存 模型 + 参数
torch.save(cifar10_model, "cifar10_model.pth")
# 方式2:只保存 参数(官方推荐)
torch.save(cifar10_model.state_dict(), "cifar10_model_state_dict.pth")
执行成功后,脚本文件所在目录会生成:cifar10_model.pth、cifar10_model_state_dict.pth两个文件。
恢复方式1保存的模型:
import torch
# 方式1
cifar10_model = torch.load("cifar10_model.pth")
print(cifar10_model)
输出如下:
MyModel(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
恢复方式2保存的模型(官方推荐):
import torch
from _07_cifar10_model.cifar10_model import MyModel
# 方式2(官方推荐)
cifar10_model = MyModel()
cifar10_model.load_state_dict(torch.load("cifar10_model_state_dict.pth"))
print(cifar10_model)
输出如下:
MyModel(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
模型的完整训练套路
前面我们虽然搭建了在CIFAR10数据集上的分类模型,但是我们并没有对模型进行完整的训练。下面会对我们的模型进行一个完整的训练。训练代码如下:
import time
from torch.utils import tensorboard
from torch.utils.data import DataLoader
from _07_cifar10_model.cifar10_model import MyModel
import torchvision
import torch.nn
if __name__ == "__main__":
start_time = time.time()
# 准备训练数据集和测试数据集
transform = torchvision.transforms.Compose({
torchvision.transforms.ToTensor()
})
train_data = torchvision.datasets.CIFAR10("./dataset", train=True,
transform=transform,
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=transform,
download=True)
train_data_len = len(train_data)
test_data_len = len(test_data)
print("训练集的长度: {}".format(train_data_len))
print("测试集的长度: {}".format(test_data_len))
# 创建训练集和测试集的dataloader
train_dataloader = DataLoader(dataset=train_data, batch_size=64,
shuffle=True,
num_workers=16)
test_dataloader = DataLoader(dataset=test_data, batch_size=64,
shuffle=True,
num_workers=16)
# 创建网络
cifar10_model = MyModel()
# 创建损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 创建优化器
# 学习率,科学计数的形式方便改动
learning_rate = 1e-2
optimizer = torch.optim.SGD(cifar10_model.parameters(), lr=learning_rate)
# 训练次数
total_train_step = 0
# 训练轮次
epoch = 20
# 创建 tensorboard SummaryWriter
writer = tensorboard.SummaryWriter("logs")
for i in range(epoch):
print("----------第 {} 轮训练开始-----------".format(i))
# 模型进入训练模式,该方法在当前模型可有可无(加上是个好习惯)
cifar10_model.train()
for data in train_dataloader:
images, targets = data
outputs = cifar10_model(images)
loss = loss_func(outputs, targets)
# 清空上一轮计算的梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 优化器优化参数(执行梯度下降)
optimizer.step()
total_train_step += 1
writer.add_scalar("train/Loss", loss.item(), total_train_step)
if total_train_step % 100 == 0:
print("训练次数: {}, Loss: {}".
format(total_train_step, loss.item()))
total_test_loss = 0.0
total_accuracy = 0.0
# 每轮 epoch 后计算模型在测试集上的loss表现
# 测试时无需计算梯度,可加快计算速度
# 模型进入验证(测试)模式,该方法在当前模型可有可无(加上是个好习惯)
cifar10_model.eval()
with torch.no_grad():
for data in test_dataloader:
images, targets = data
outputs = cifar10_model(images)
loss = loss_func(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("测试准确率:{}".format(total_accuracy/test_data_len))
writer.add_scalar("test/Loss", total_test_loss, i)
writer.add_scalar("test/accuracy", total_accuracy/test_data_len, i)
# 保存每轮训练后的模型
torch.save(cifar10_model.state_dict(),
"cifar10_model_state_dict_{}_epoch.pth".format(i))
writer.close()
end_time = time.time()
print("耗时:{}".format(end_time - start_time))
如上代码中调用模型的train()和eval()方法主要是对模型中的Dropout、BatchNorm等Module有用(如果存在),官方解释如下:


tensorboard可视化结果如下:

利用GPU训练
没有GPU的同学可以想办法使用google colab,他提供了免费的GPU使用时长,使用起来和jupyter notebook很像。
利用GPU训练很简单:
方式一:.cuda()
只需要对 网络模型、数据(输入、标注)、损失函数调用.cuda()方法:
import time
from torch.utils import tensorboard
from torch.utils.data import DataLoader
from _07_cifar10_model.cifar10_model import MyModel
import torchvision
import torch.nn
if __name__ == "__main__":
start_time = time.time()
# 准备训练数据集和测试数据集
transform = torchvision.transforms.Compose({
torchvision.transforms.ToTensor()
})
train_data = torchvision.datasets.CIFAR10("./dataset", train=True,
transform=transform,
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=transform,
download=True)
train_data_len = len(train_data)
test_data_len = len(test_data)
print("训练集的长度: {}".format(train_data_len))
print("测试集的长度: {}".format(test_data_len))
# 创建训练集和测试集的dataloader
train_dataloader = DataLoader(dataset=train_data, batch_size=64,
shuffle=True,
num_workers=16)
test_dataloader = DataLoader(dataset=test_data, batch_size=64,
shuffle=True,
num_workers=16)
# 创建网络
cifar10_model = MyModel()
if torch.cuda.is_available():
cifar10_model = cifar10_model.cuda()
# 创建损失函数
loss_func = torch.nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_func = loss_func.cuda()
# 创建优化器
# 学习率,科学计数的形式方便改动
learning_rate = 1e-2
optimizer = torch.optim.SGD(cifar10_model.parameters(), lr=learning_rate)
# 训练次数
total_train_step = 0
# 训练轮次
epoch = 20
# 创建 tensorboard SummaryWriter
writer = tensorboard.SummaryWriter("logs")
for i in range(epoch):
print("----------第 {} 轮训练开始-----------".format(i))
# 模型进入训练模式,该方法在当前模型可有可无(加上是个好习惯)
cifar10_model.train()
for data in train_dataloader:
images, targets = data
if torch.cuda.is_available():
images = images.cuda()
targets = targets.cuda()
outputs = cifar10_model(images)
loss = loss_func(outputs, targets)
# 清空上一轮计算的梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 优化器优化参数(执行梯度下降)
optimizer.step()
total_train_step += 1
writer.add_scalar("train/Loss", loss.item(), total_train_step)
if total_train_step % 100 == 0:
print("训练次数: {}, Loss: {}".
format(total_train_step, loss.item()))
total_test_loss = 0.0
total_accuracy = 0.0
# 每轮 epoch 后计算模型在测试集上的loss表现
# 测试时无需计算梯度,可加快计算速度
# 模型进入验证(测试)模式,该方法在当前模型可有可无(加上是个好习惯)
cifar10_model.eval()
with torch.no_grad():
for data in test_dataloader:
images, targets = data
if torch.cuda.is_available():
images = images.cuda()
targets = targets.cuda()
outputs = cifar10_model(images)
loss = loss_func(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("测试准确率:{}".format(total_accuracy/test_data_len))
writer.add_scalar("test/Loss", total_test_loss, i)
writer.add_scalar("test/accuracy", total_accuracy/test_data_len, i)
# 保存每轮训练后的模型
torch.save(cifar10_model.state_dict(),
"cifar10_model_state_dict_{}_epoch.pth".format(i))
writer.close()
end_time = time.time()
print("耗时:{}".format(end_time - start_time))
方式二:.to()
对 网络模型、数据(输入、标注)、损失函数调用.to()方法,方法中传入torch.device()对象。这种方式的好处在于不但可以使用GPU,还可以在有多块GPU时指定使用某块GPU。
如下:
# cpu
CPU_device = torch.device("cpu")
# gpu 只有一块显卡无需指明使用第几块
GPU_device = torch.device("cuda")
# 第0块 gpu
GPU_0_device = torch.device("cuda:0")
完整代码如下:
import time
from torch.utils import tensorboard
from torch.utils.data import DataLoader
from _07_cifar10_model.cifar10_model import MyModel
import torchvision
import torch.nn
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
start_time = time.time()
# 准备训练数据集和测试数据集
transform = torchvision.transforms.Compose({
torchvision.transforms.ToTensor()
})
train_data = torchvision.datasets.CIFAR10("./dataset", train=True,
transform=transform,
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=transform,
download=True)
train_data_len = len(train_data)
test_data_len = len(test_data)
print("训练集的长度: {}".format(train_data_len))
print("测试集的长度: {}".format(test_data_len))
# 创建训练集和测试集的dataloader
train_dataloader = DataLoader(dataset=train_data, batch_size=64,
shuffle=True,
num_workers=16)
test_dataloader = DataLoader(dataset=test_data, batch_size=64,
shuffle=True,
num_workers=16)
# 创建网络
cifar10_model = MyModel()
cifar10_model = cifar10_model.to(device)
# if torch.cuda.is_available():
# cifar10_model = cifar10_model.cuda()
# 创建损失函数
loss_func = torch.nn.CrossEntropyLoss()
loss_func = loss_func.to(device)
# if torch.cuda.is_available():
# loss_func = loss_func.cuda()
# 创建优化器
# 学习率,科学计数的形式方便改动
learning_rate = 1e-2
optimizer = torch.optim.SGD(cifar10_model.parameters(), lr=learning_rate)
# 训练次数
total_train_step = 0
# 训练轮次
epoch = 20
# 创建 tensorboard SummaryWriter
writer = tensorboard.SummaryWriter("logs")
for i in range(epoch):
print("----------第 {} 轮训练开始-----------".format(i))
# 模型进入训练模式,该方法在当前模型可有可无(加上是个好习惯)
cifar10_model.train()
for data in train_dataloader:
images, targets = data
images = images.to(device)
targets = targets.to(device)
# if torch.cuda.is_available():
# images = images.cuda()
# targets = targets.cuda()
outputs = cifar10_model(images)
loss = loss_func(outputs, targets)
# 清空上一轮计算的梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 优化器优化参数(执行梯度下降)
optimizer.step()
total_train_step += 1
writer.add_scalar("train/Loss", loss.item(), total_train_step)
if total_train_step % 100 == 0:
print("训练次数: {}, Loss: {}".
format(total_train_step, loss.item()))
total_test_loss = 0.0
total_accuracy = 0.0
# 每轮 epoch 后计算模型在测试集上的loss表现
# 测试时无需计算梯度,可加快计算速度
# 模型进入验证(测试)模式,该方法在当前模型可有可无(加上是个好习惯)
cifar10_model.eval()
with torch.no_grad():
for data in test_dataloader:
images, targets = data
images = images.to(device)
targets = targets.to(device)
# if torch.cuda.is_available():
# images = images.cuda()
# targets = targets.cuda()
outputs = cifar10_model(images)
loss = loss_func(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("测试准确率:{}".format(total_accuracy/test_data_len))
writer.add_scalar("test/Loss", total_test_loss, i)
writer.add_scalar("test/accuracy", total_accuracy/test_data_len, i)
# 保存每轮训练后的模型
torch.save(cifar10_model.state_dict(),
"cifar10_model_state_dict_{}_epoch.pth".format(i))
writer.close()
end_time = time.time()
print("耗时:{}".format(end_time - start_time))
模型验证
前面的小节中,我们已经将模型训练好了,且保存了每轮训练后的模型参数。现在我们选择一个在测试集上表现最好的模型进行恢复,然后在网上随便找些图片,看我们的模型能否分类正确。根据tensorboard的显示,表现最好的模型是在第18轮训练后的模型,能达到65%左右的正确率。预测图片如下:


根据CIFAR10数据集中定义,dog的target为5,airplane的target为0:

预测代码如下:
import torch
from PIL import Image
import torchvision
from _07_cifar10_model.cifar10_model import MyModel
dog_img_path = "dog.png"
airplane_img_path = "airplane.png"
dog_img_PIL = Image.open(dog_img_path)
airplane_img_PIL = Image.open(airplane_img_path)
# 将4通道RGBA转成3通道RGB
dog_img_PIL = dog_img_PIL.convert("RGB")
airplane_img_PIL = airplane_img_PIL.convert("RGB")
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
dog_img_tensor = transform(dog_img_PIL)
airplane_img_tensor = transform(airplane_img_PIL)
# print(dog_img_tensor.shape)
dog_img_tensor = torch.reshape(dog_img_tensor, (-1, 3, 32, 32))
airplane_img_tensor = torch.reshape(airplane_img_tensor, (1, 3, 32, 32))
cifar10_model = MyModel()
cifar10_model.load_state_dict(torch.load(
"../_10_train_model/cifar10_model_state_dict_18_epoch.pth"))
cifar10_model.eval()
with torch.no_grad():
output = cifar10_model(dog_img_tensor)
print(output.argmax(1))
output = cifar10_model(airplane_img_tensor)
print(output.argmax(1))
输出如下:
tensor([7]) # 预测错误
tensor([0]) # 预测正确

 浙公网安备 33010602011771号
浙公网安备 33010602011771号