Python 3 快速入门 3 —— 模块与类
本文假设你已经有一门面向对象编程语言基础,如Java等,且希望快速了解并使用Python语言。本文对重点语法和数据结构以及用法进行详细说明,同时对一些难以理解的点进行了图解,以便大家快速入门。一些较偏的知识点在大家入门以后根据实际需要再查询官方文档即可,学习时切忌胡子眉毛一把抓。同时,一定要跟着示例多动手写代码。学习一门新语言时推荐大家同时去刷leetcode,一来可以快速熟悉新语言的使用,二来也为今后找工作奠定基础。推荐直接在网页上刷leetcode,因为面试的时候一般会让你直接在网页编写代码。leetcode刷题路径可以按我推荐的方式去刷。以下代码中,以 >>> 和 ... 开头的行是交互模式下的代码部分,>?开头的行是交互模式下的输入,其他行是输出。python代码中使用 #开启行注释。
模块
模块是包含 Python 定义和语句的文件,文件后缀名为 .py,文件名即是模块名。在pycharm中创建名为python-learn的项目,然后创建fib.py文件,并输入以下代码后保存:
# 斐波拉契数列
def print_fib(n: int) -> None:
"""打印斐波拉契数列
:param n: 数列截至范围
:return: None
"""
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def get_fib(n: int) -> list:
"""获取斐波拉契数列
:param n: 数列截至范围
:return: 存有数列的list
"""
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
接着,打开pycharm中的Python Console,使用import语句导入该模块:
# 导入 fib 模块
>>> import fib
# 使用 fib 模块中定义的函数
>>> fib.print_fib(10)
0 1 1 2 3 5 8
>>> fib.get_fib(10)
[0, 1, 1, 2, 3, 5, 8]
# 如果经常使用某个函数,可以把它赋值给局部变量
>>> print_fib = fib.print_fib
>>> print_fib(10)
0 1 1 2 3 5 8
# 每个模块中都有一个特殊变量 __name__ 记录着模块的名字
>>> print(fib.__name__)
fib
使用as关键字为导入的模块指定别名:
# 导入 fib 并指定别名为 fibonacci
>>> import fib as fibonacci
>>> fibonacci.get_fib(10)
[0, 1, 1, 2, 3, 5, 8]
# 模块名依然为 fib
>>> print(fibonacci.__name__)
fib
当我们通过import语句导入模块时:
- 首先查找要导入的模块是否为内置模块;
- 没找到就会根据
sys.path(list)中的路径继续查找。(sys.path默认值包含:当前路径、环境变量PYTHONPATH中的路径等)
查看sys.path的值:
>>> print("======= start =======")
... for path in sys.path:
... print(path)
... print("======= end =======")
======= start =======
C:\software\jetbrains\PyCharm 2021.2.3\plugins\python\helpers\pydev
C:\software\jetbrains\PyCharm 2021.2.3\plugins\python\helpers\pycharm_display
C:\software\jetbrains\PyCharm 2021.2.3\plugins\python\helpers\third_party\thriftpy
C:\software\jetbrains\PyCharm 2021.2.3\plugins\python\helpers\pydev
C:\software\anaconda3\envs\python-learn\python310.zip
C:\software\anaconda3\envs\python-learn\DLLs
C:\software\anaconda3\envs\python-learn\lib
C:\software\anaconda3\envs\python-learn
C:\software\anaconda3\envs\python-learn\lib\site-packages
C:\software\jetbrains\PyCharm 2021.2.3\plugins\python\helpers\pycharm_matplotlib_backend
D:\code\python\python-learn # fib 模块所在目录
D:/code/python/python-learn # 对应linux路径形式
======= end =======
当我们要导入的模块路径不在sys.path中时,通过append或extend函数可以将目标路径手动加入sys.path中。前面的例子里,为什么我们没有手动将项目路径加入sys.path中就可以导入fib模块呢?答案是pycharm帮我们做了。在项目中,当我们打开Python Console时,pycharm执行了以下脚本:
sys.path.extend(['D:\\code\\python\\python-learn', 'D:/code/python/python-learn'])
注意:为了保证运行效率,每次解释器会话只导入一次模块。如果更改了模块内容,必须重启解释器;仅交互测试一个模块时,也可以使用 importlib.reload(),例如 import importlib; importlib.reload(modulename)。
以脚本方式执行模块
.py文件(模块)还可以通过python解释器以脚本的方式执行。在pycharm项目中打开Terminal并执行以下命令可以解释执行fib模块(也可点击图形界面的执行按钮):
python fib.py
执行fib.py时,解释器从上到下依次解释执行,由于代码中没有任何输出动作所以终端没有任何输出。
当一个.py文件(模块)被当作脚本执行时,会被认为是程序的入口,类似于其他语言中的main函数,于是python解释器会将该模块的特殊变量__name__置为__main__。
现在,我们给fib.py文件添加一些内容:
# 斐波拉契数列
def print_fib(n: int) -> None:
"""打印斐波拉契数列
:param n: 数列截至范围
:return: None
"""
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def get_fib(n: int) -> list:
"""获取斐波拉契数列
:param n: 数列截至范围
:return: 存有数列的list
"""
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
# 只有当前文件(模块)被当作脚本执行时 if 语句才为真
if __name__ == "__main__":
import sys
# argv[0]始终为文件名
print(sys.argv[0], end=" ")
# 传入的第一个参数
print(sys.argv[1], end=" ")
# 传入的第二个参数
print(sys.argv[2])
# 测试 print_fib 函数
print_fib(int(sys.argv[1]))
# 测试 get_fib 函数
fibSeries = get_fib(int(sys.argv[2]))
print(fibSeries)
输入以下命令并执行:
PS D:\code\python\python-learn> python fib.py 10 20
fib.py 10 20
0 1 1 2 3 5 8
[0, 1, 1, 2, 3, 5, 8, 13]
包
如果你了解Java,那么Python中的包你就不会感到陌生。包是命名空间的一种实现方式,不同包中的同名模块互不影响。包的写法类似于A.B.C,A是包,B是A的子包,C可以是B的子包也可以是模块。包在磁盘上的表现就是目录或者说是路径,以包结构A.B.C为例,若C为模块,那么对应的路径为项目路径/A/B/C.py。同时Python只把含 __init__.py 文件的目录当成包。(后面解释这个文件的用处)
以之前创建的python-learn项目为例,在根目录下创建包com.winlsr,然后将fib.py移动到com.winlsr下,目录结构如下:
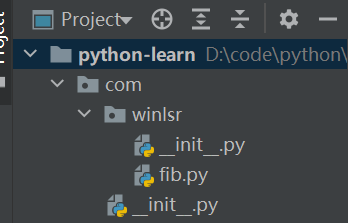
从包中导入fib模块:
# 导入 fib 模块
>>> import com.winlsr.fib
# 使用时必须引用模块的全名
>>> com.winlsr.fib.print_fib(10)
0 1 1 2 3 5 8
使用from package import ...导入模块、函数(建议重启一下解释器):
# 导入 fib 模块
>>> from com.winlsr import fib
# 使用时直接输入模块名
>>> fib.print_fib(10)
0 1 1 2 3 5 8
# 直接导入 fib 模块中的 print_fib 函数
>>> from com.winlsr.fib import print_fib
# 直接使用方法即可
>>> print_fib(10)
0 1 1 2 3 5 8
使用 from package import item 时,item 可以是包的子模块(或子包),也可以是包中定义的函数、类或变量等其他名称。使用 import item 时,item 只可以是模块或包。有的同学会疑问,导入包有什么用?以当前项目为例,我们导入com包(建议重启一下解释器):
# 导入 com 包
>>> import com
>>> com
# 包其实也是模块,对应的文件是包下的 __init__.py 文件?
<module 'com'="" from="" 'd:\\code\\python\\python-learn\\com\\__init__.py'="">
# 验证猜想:
# 将该 __init__.py 文件中添加如下内容
def print_info():
print("name :", __name__)
# 重启解释器后再次导入 com 包
>>> import com
# 成功调用 __init__.py 文件中定义的函数,猜想正确
>>> com.print_info()
name : com
从包中导入 *
from package import *不会导入package中的任何模块或子包,除非你在该package下的__init__.py文件中添加了如下显示说明:
__all__ = ["子模块名1", "子包名1"]
添加该说明后,执行from package import *语句会导入指定的子模块、子包。
同样以之前创建的python-learn项目为例,我们执行如语句(建议重启一下解释器):
# 希望导入 com.winlsr 包下的 fib 模块
>>> from com.winlsr import *
# 发现并没有导入
>>> fib
Traceback (most recent call last):
File "<input>", line 1, in <module>
NameError: name 'fib' is not defined
在 com.winlsr下的__init__.py文件中添加如下内容:
__all__ = ["fib"]
执行同样的语句(建议重启一下解释器):
>>> from com.winlsr import *
# 导入成功
>>> fib
<module 'com.winlsr.fib'="" from="" 'd:\\code\\python\\python-learn\\com\\winlsr\\fib.py'="">
注意:通常不建议采用该小结讲解的方法导入模块或子包,而是采用from package import specific_submodule。
dir()函数
内置函数 dir()用于查找模块或子包中定义的名称(变量、模块(子包)、函数等),返回结果是经过排序的字符串列表。没有参数时,dir()列出当前定义的名称。
>>> from com.winlsr import fib
>>> dir(fib)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'get_fib', 'print_fib']
>>> dir()
['__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'fib', 'sys']
类
封装
Python中定义类使用class关键字,类中可以定义变量和函数,起到封装的作用。沿用之前创建的项目,在com.winlsr包中创建rectangle模块并定义矩形类:
class Rectangle:
# 一个类只能有一个构造函数
def __init__(self): # 无参构造,self 类似于 this,指向实例对象本身
self.length = 0.0 # 构造函数中对实例对象的成员变量width和length进行初始化
self.width = 0.0 # 只有创建的实例才有这两个变量
# 计算面积
def area(self):
return self.length * self.width
# 计算周长
def perimeter(self):
return (self.length + self.width) * 2
打开Python Console,输入以下语句来使用Rectangle类:
>>> from com.winlsr.rectangle import Rectangle
# 使用无参构造创建类的实例对象
>>> rec = Rectangle()
# 调用rec实例的方法
>>> rec.perimeter()
0.0
>>> rec.area()
0.0
>>> rec.length
0.0
# Rectangle 类中没有length这个成员变量,只有实例对象中才有
>>> Rectangle.length
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: type object 'Rectangle' has no attribute 'length'
Python中实例对象的成员变量也可以不在__init__()中定义和初始化,而是直接在类中定义并初始化。原来的Rectangle类可以改写为:
class Rectangle:
# 成员变量直接定义在类中并初始化,类和实例都有两个变量
length = 0.0
width = 0.0
def area(self):
return self.length * self.width
def perimeter(self):
return (self.length + self.width) * 2
注意,如果变量直接定义在类中,那么创建实例时,实例中的变量是类中变量的浅拷贝。重启解释器执行以下语句:
>>> from com.winlsr.rectangle import Rectangle
>>> rec0 = Rectangle()
>>> rec0.width is Rectangle.width
True
>>> rec1 = Rectangle()
>>> rec1.length is Rectangle.length
True
实例rec0和rec1创建后的内存分布如下:
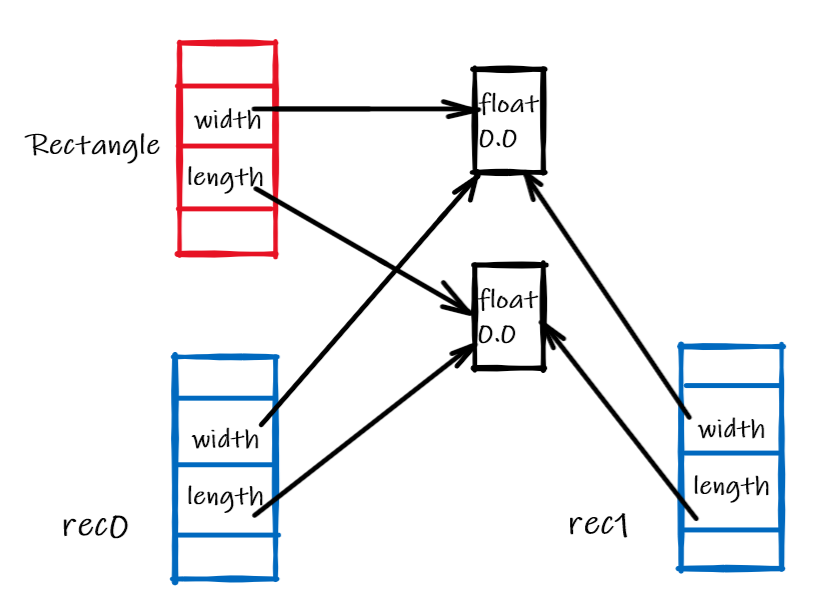
对实例rec0和rec1中的成员变量进行修改:
# 修改实例的成员变量
>>> rec0.width = 1.0
... rec0.length = 2.0
... rec1.width = 3.0
... rec1.length = 4.0
# 打印
>>> print(Rectangle.width)
... print(Rectangle.length)
... print(rec0.width)
... print(rec0.length)
... print(rec1.width)
... print(rec1.length)
0.0
0.0
1.0
2.0
3.0
4.0
根据结果可以发现rec0和rec1实例之间的成员变量(不可变 immutable 类型)相互之间不影响,修改后它们的内存分布如下:
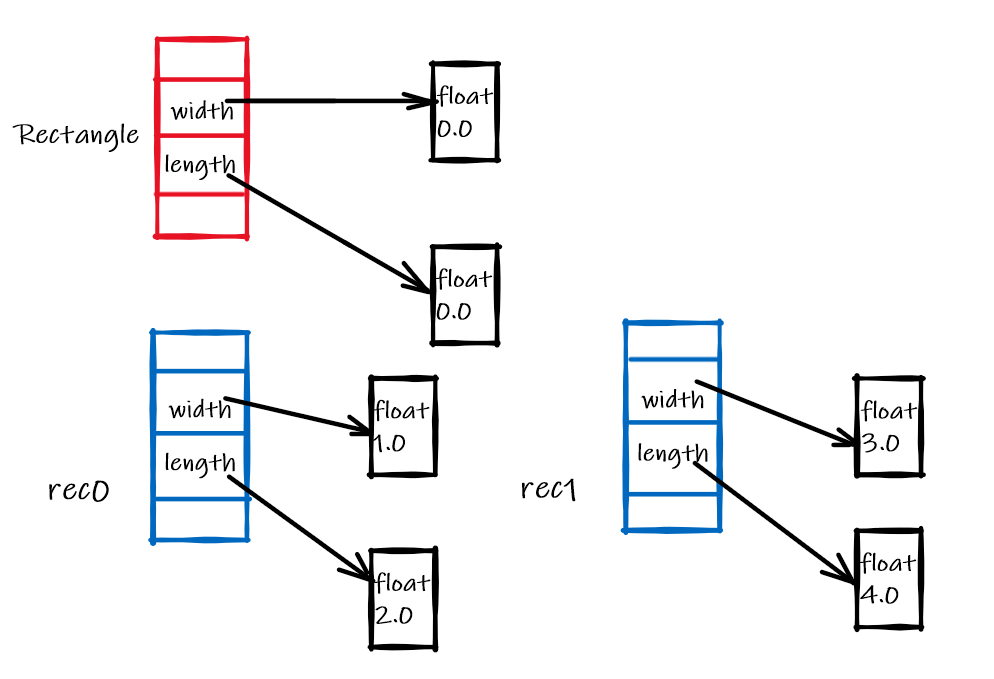
注意,如果直接定义在类中的变量是可变(mutable)类型,使用时就应该谨慎。如下,依然在com.winlsr包中创建actor模块并定义演员类:
class Actor:
# 参演的电影
movies = []
def get_movies(self):
return self.movies
def add_movie(self, movie):
self.movies.append(movie)
使用Actor类:
>>> from com.winlsr.actor import Actor
... lixiaolong = Actor()
... xuzheng = Actor()
... lixiaolong.add_movie("猛龙过江")
... xuzheng.add_movie("我不是药神")
... print(lixiaolong.get_movies())
... print(xuzheng.get_movies())
# 发现两个对象的 movies list 是共享的
['猛龙过江', '我不是药神']
print(xuzheng.get_movies())
['猛龙过江', '我不是药神']
以上情况是因为多个Actor类的实例中的movies变量(引用)指向同一个list对象,实例lixiaolong和xuzheng内存分布如下:
创建后实例后,调用add_movie()之前的内存分布:

调用add_movie()之后的内存分布:
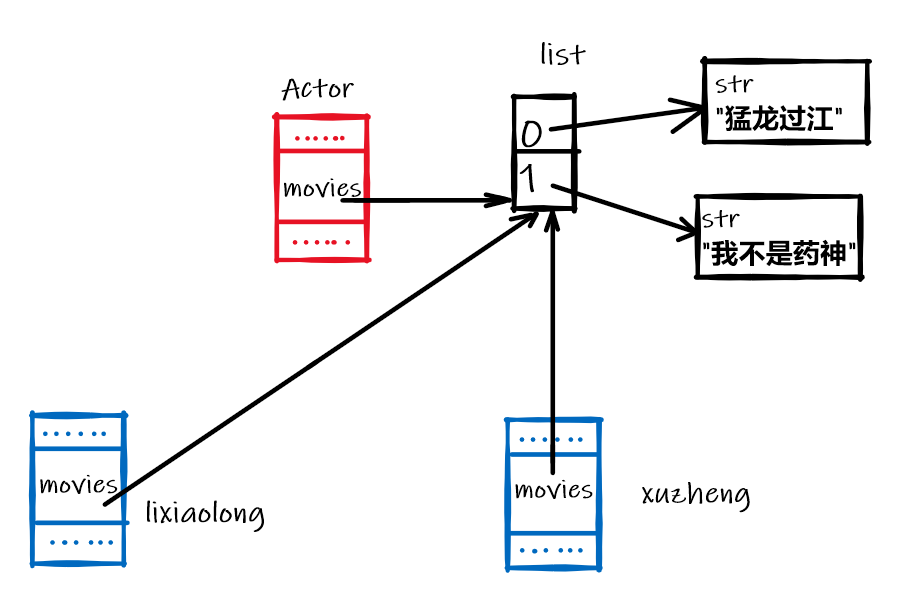
为了使每个演员的参演电影列表相互独立,在创建Actor类的实例时应该为每个实例创建一个新的list:
class Actor:
# 参演的电影
# 该语句没有用,可以删掉。实例在创建时会通过构造函数改变指向movies的指向
movies = []
def __init__(self):
self.movies = []
def get_movies(self):
return self.movies
def add_movie(self, movie):
self.movies.append(movie)
重启解释器,再次执行以下语句:
>>> from com.winlsr.actor import Actor
... lixiaolong = Actor()
... xuzheng = Actor()
... lixiaolong.add_movie("猛龙过江")
... xuzheng.add_movie("我不是药神")
... print(lixiaolong.get_movies())
... print(xuzheng.get_movies())
['猛龙过江']
['我不是药神']
综上,根据前面的示例,如果你不希望多个实例之间共享变量,建议直接将变量定义在__init__函数中。最后,Python支持静态语言不支持的实例属性动态绑定特性:
# 给 lixiaolong 这个实例动态添加 age 属性
>>> lixiaolong.age = 41
>>> lixiaolong.age
41
# 不影响其他实例
>>> xuzheng.age
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'Actor' object has no attribute 'age'
访问控制
前面的实例中,我们可以通过instance.var的形式来直接访问实例的成员变量。但通常我们不希望实例中的成员变量被直接访问,而是通过getter和setter来访问,这需要我们将成员变量设置为private。
Python中:
- 带有一个下划线的变量,形如
_var应该被当作是API(常用于模块中)的非公有部分 (函数或是数据成员)。虽然可以正常访问,但我们应遵循这样一个约定; - 类中私有成员变量应当用两个前缀下划线,至多一个后缀下划线标识,形如:
__var。但该变量并不是真正的不能访问,这是因为Python实现的机制是”名称改写“。这种机制在执行时会将__var改为_classname__var,但你仍然可以通过_classname__var来访问。 - 形如
__var__的变量是特殊变量,可以访问,但通常我们不需要定义此类变量。
实验验证,将Rectangle类改为如下代码:
class Rectangle:
def __init__(self, length, width):
self.__length = length
self.__width = width
def area(self):
return self.__length * self.__width
def perimeter(self):
return (self.__length + self.__width) * 2
重启解释器,执行如下语句:
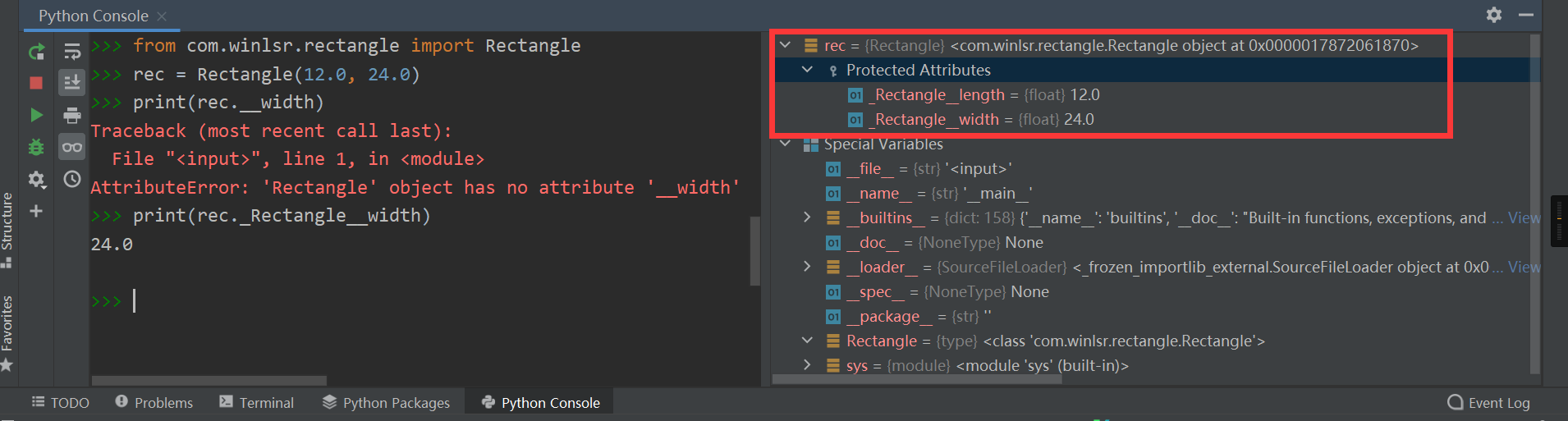
>>> from com.winlsr.rectangle import Rectangle
>>> rec = Rectangle(12.0, 24.0)
# 直接访问私有变量 __width,失败
>>> print(rec.__width)
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'Rectangle' object has no attribute '__width'
# 访问私有变量改写后的名称 _Rectangle__width,成功
>>> print(rec._Rectangle__width)
24.0
对应Python Console如下:
继承
Python继承语法如下,所有类都默认继承:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-n>
下面我们在com.winlsr包下创建person模块并定义Person类,作为Actor和Teacher类的基类:
class Person:
def __init__(self, name, id_number):
self.__name = name
self.__id_number = id_number
def set_name(self, name):
self.__name = name
def get_name(self):
return self.__name
def set_id_number(self, id_number):
self.__id_number = id_number
def get_id_number(self):
return self.__id_number
在com.winlsr包下创建actor模块并定义Actor类,它是Person类的派生类:
from .person import Person
class Actor(Person):
def __init__(self, name, id_number):
self.__movies = []
# 三种调用父类构造函数的方式
super().__init__(name, id_number)
# super(Actor, self).__init__(name, id_number)
# Person.__init__(self, name, id_number)
def add_movie(self, movie):
self.__movies.append(movie)
def print_info(self):
print(self.get_name(), self.get_id_number(), self.__movies, sep=" : ")
在com.winlsr包下创建teacher模块并定义Teacher类,它也是Person类的派生类:
from .person import Person
class Teacher(Person):
# 无构造函数,创建对象时会调用父类构造函数
def print_info(self):
print(self.get_name(), self.get_id_number(), sep=" : ")
重启解释器,执行如下语句:
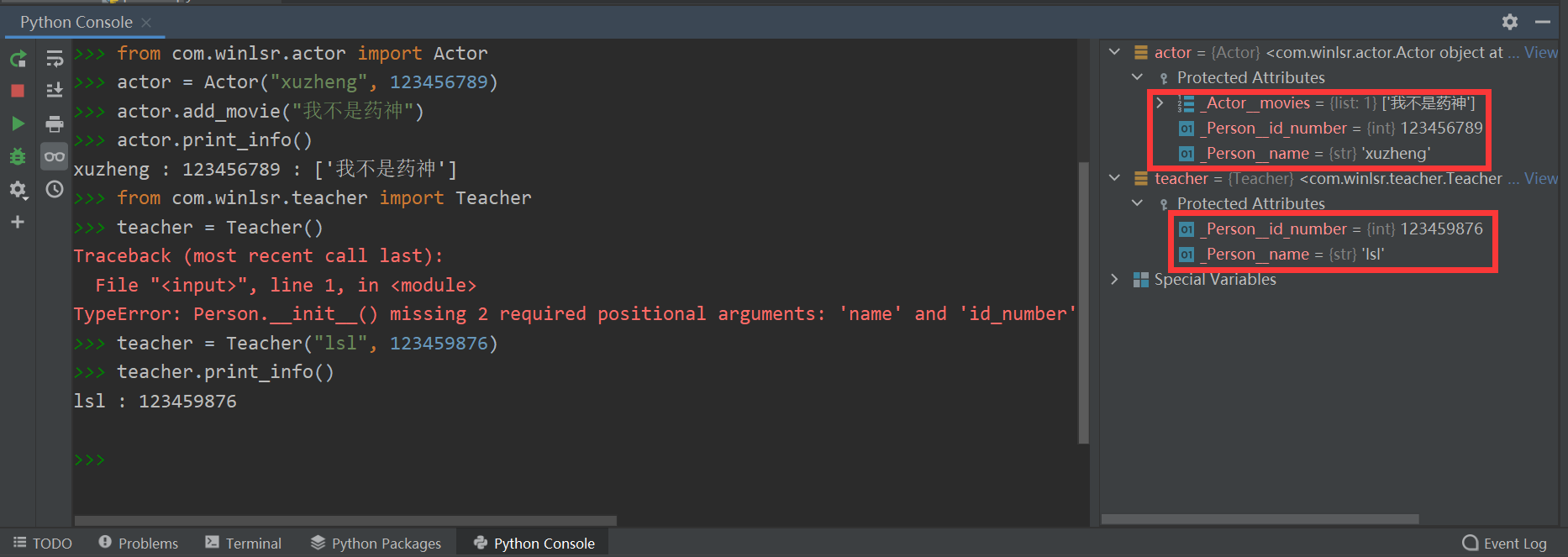
>>> from com.winlsr.actor import Actor
>>> actor = Actor("xuzheng", 123456789)
>>> actor.add_movie("我不是药神")
>>> actor.print_info()
xuzheng : 123456789 : ['我不是药神']
>>> from com.winlsr.teacher import Teacher
>>> teacher = Teacher()
# Teacher 类中没有定义 __init__(),这里会调用父类 Person 的构造并传入参数
>>> teacher = Teacher("lsl", 123459876)
>>> teacher.print_info()
lsl : 123459876
对应Python Console如下:
Python 也支持一种多重继承。 带有多个基类的类定义语句如下所示:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-n>
派生类实例如果某一属性在 DerivedClassName 中未找到,则会到 Base1 中搜索它,然后(递归地)到 Base1 的基类中搜索,如果在那里未找到,再到 Base2 中搜索,依此类推。
其他
结语
教程到这里就结束了,最后推荐大家再去看看廖雪峰老师讲解的异常处理和IO的内容(也可以用到的时候再看),他比官网讲解的更有条理。学完这些内容就基本入门了,今后可以根据自己应用的领域再进一步学习即可,比如深度学习、web开发等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号