羽夏看Linux内核——引导启动(下)
写在前面
此系列是本人一个字一个字码出来的,包括示例和实验截图。如有好的建议,欢迎反馈。码字不易,如果本篇文章有帮助你的,如有闲钱,可以打赏支持我的创作。如想转载,请把我的转载信息附在文章后面,并声明我的个人信息和本人博客地址即可,但必须事先通知我。
你如果是从中间插过来看的,请仔细阅读 羽夏看Linux系统内核——简述 ,方便学习本教程。
练习及参考
- 绘制执行进入保护模式的时候的内存布局状态。
🔒 点击查看答案 🔒
图是我自己画的,有的地方画的有点夸张,不是按照比例画的,仅供参考:

- 用表格的形式展示
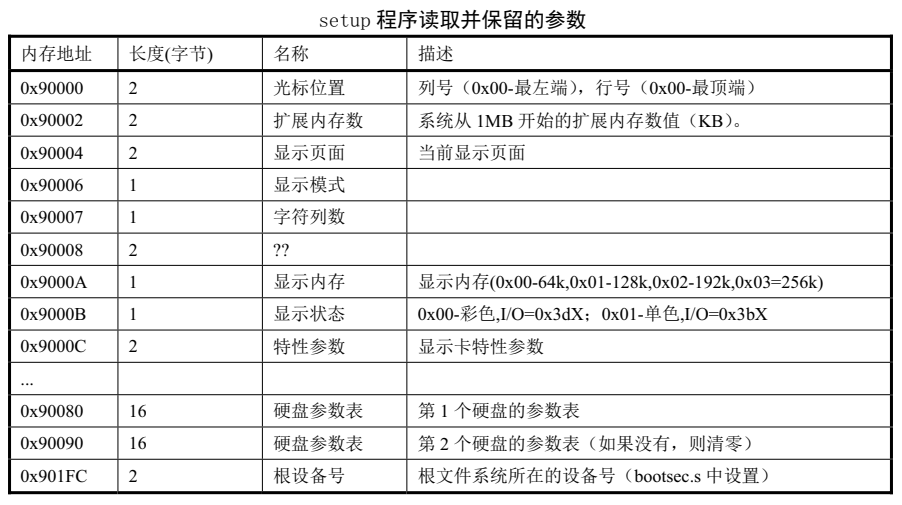
setup.s程序在内存中保存的数据。
🔒 点击查看答案 🔒
.word 0x00eb,0x00eb的作用是啥?
🔒 点击查看答案 🔒
其实就是个 jmp 指令的二进制,由于每个指令执行都需要耗费几个机器时间,这里的作用就是延时。
- 介绍到最后的
jmpi 0,8代码最终跳到了哪个地址?为什么?
🔒 点击查看答案 🔒
最终跳到了 0 地址。由于目前 CPU 处于保护模式,8 现在是段选择子,含义是以 0环 权限使用索引为 1 的段描述符,是第二个,基址为 0 ,所以是 0 地址。
当前 CPU 状态
在正式开始之前我们得梳理一下当前CPU的状态,之后再继续讲解head.s这块代码。
当前,我们CPU已经开启了保护模式,但没有开启分页保护,也就是所谓的虚拟地址,只是有了段相关的权限检查。此时,我们的CPU地址具有32位的访问能力了。
清楚了目前的状态,我们就可以继续了。
head.s
head.s程序在被编译生成目标文件后会与内核其他程序一起被链接成system模块,位于system模块的最前面开始部分。system模块将被放置在磁盘上setup模块之后开始的扇区中,即从磁盘上第6个扇区开始放置。一般情况下Linux 0.11内核的system模块大约有120 KB左右,因此在磁盘上大约占240个扇区。
从此,CPU正式运行在保护模式了。汇编语法也变了,变成了比较麻烦的AT&T语法。对于AT&T汇编不熟悉的,可以参考我的 羽夏笔记—— AT&T 与 GCC ,别的教程也可。看明白后,回来继续。
在正式开始介绍之前,我们先把目前的GDT表的内容放上,IDT表目前是空的:
gdt:
.word 0,0,0,0 ! dummy
.word 0x07FF ! 8Mb - limit=2047 (2048*4096=8Mb)
.word 0x0000 ! base address=0
.word 0x9A00 ! code read/exec
.word 0x00C0 ! granularity=4096, 386
.word 0x07FF ! 8Mb - limit=2047 (2048*4096=8Mb)
.word 0x0000 ! base address=0
.word 0x9200 ! data read/write
.word 0x00C0 ! granularity=4096, 386
第一部分代码开始:
startup_32:
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
mov %ax,%fs
mov %ax,%gs
lss _stack_start,%esp
call setup_idt
call setup_gdt
可以看到mov指令来初始化段寄存器ds/es/fs/gs,指向可读可写但不能执行的数据段。然后加载堆栈段描述符,我们来看看_stack_start到底是啥:
long user_stack [ PAGE_SIZE>>2 ] ;
struct {
long * a;
short b;
} stack_start = { & user_stack [PAGE_SIZE>>2] , 0x10 };
诶?你是找不到滴。它在linuxsrc/kernel/sched.c文件当中。lss作用在这里最终的效果是把0x10作为段选择子加载到ss中,并将user_stack的地址放到esp中。
setup_idt和setup_gdt分别对应建立新的IDT表和GDT表,我们先看看setup_idt这个函数:
/*
* setup_idt
*
* sets up a idt with 256 entries pointing to
* ignore_int, interrupt gates. It then loads
* idt. Everything that wants to install itself
* in the idt-table may do so themselves. Interrupts
* are enabled elsewhere, when we can be relatively
* sure everything is ok. This routine will be over-
* written by the page tables.
*/
setup_idt:
lea ignore_int,%edx
movl $0x00080000,%eax
movw %dx,%ax /* selector = 0x0008 = cs */
movw $0x8E00,%dx /* interrupt gate - dpl=0, present */
lea _idt,%edi
mov $256,%ecx
rp_sidt:
movl %eax,(%edi)
movl %edx,4(%edi)
addl $8,%edi
dec %ecx
jne rp_sidt
lidt idt_descr
ret
ignore_int是一个函数,作用是打印Unknown interrupt这个字符串,然后结束。想看看的给你瞅一眼:
/* This is the default interrupt "handler" :-) */
int_msg:
.asciz "Unknown interrupt\n\r"
.align 2
ignore_int:
pushl %eax
pushl %ecx
pushl %edx
push %ds
push %es
push %fs
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
mov %ax,%fs
pushl $int_msg
call _printk
popl %eax
pop %fs
pop %es
pop %ds
popl %edx
popl %ecx
popl %eax
iret
_printk是一个函数,被定义在linuxsrc/kernel/printk.c的printk函数。_printk是printk函数编译成函数模块的表示名称。
前四行有效汇编就是构造一个中断门,用来作为默认的“中断处理程序”。后面就是用构造好的“中断处理程序”向存储中断表的_idt填充256次,最后加载构造完的新IDT表,虽然没啥真正的作用,但它有了真正的中断处理能力。
接下来看GDT的:
/*
* setup_gdt
*
* This routines sets up a new gdt and loads it.
* Only two entries are currently built, the same
* ones that were built in init.s. The routine
* is VERY complicated at two whole lines, so this
* rather long comment is certainly needed :-).
* This routine will beoverwritten by the page tables.
*/
setup_gdt:
lgdt gdt_descr
ret
这个函数更简单,这个是构造好了的。我们瞅一眼,顺便把IDT带上:
idt_descr:
.word 256*8-1 # idt contains 256 entries
.long _idt
.align 2
.word 0
gdt_descr:
.word 256*8-1 # so does gdt (not that that's any
.long _gdt # magic number, but it works for me :^)
.align 3
_idt: .fill 256,8,0 # idt is uninitialized
_gdt: .quad 0x0000000000000000 /* NULL descriptor */
.quad 0x00c09a0000000fff /* 16Mb */
.quad 0x00c0920000000fff /* 16Mb */
.quad 0x0000000000000000 /* TEMPORARY - don't use */
.fill 252,8,0 /* space for LDT's and TSS's etc */
我们继续:
movl $0x10,%eax # reload all the segment registers
mov %ax,%ds # after changing gdt. CS was already
mov %ax,%es # reloaded in 'setup_gdt'
mov %ax,%fs
mov %ax,%gs
lss _stack_start,%esp
xorl %eax,%eax
然后又来了一遍加载,每次更新GDT之后,由于段描述符的变化,我们必须重新加载一遍,保证与最新的保持一致。
1: incl %eax # check that A20 really IS enabled
movl %eax,0x000000 # loop forever if it isn't
cmpl %eax,0x100000
je 1b
这部分开始检查A20是否真正的开启了,防止出了差错,否则就一直循环。
/*
* NOTE! 486 should set bit 16, to check for write-protect in supervisor
* mode. Then it would be unnecessary with the "verify_area()"-calls.
* 486 users probably want to set the NE (#5) bit also, so as to use
* int 16 for math errors.
*/
movl %cr0,%eax # check math chip
andl $0x80000011,%eax # Save PG,PE,ET
/* "orl $0x10020,%eax" here for 486 might be good */
orl $2,%eax # set MP
movl %eax,%cr0
call check_x87
jmp after_page_tables
这段代码就是检查数字协处理器芯片是否存在。这个和硬件相关,这个不是我们的重点,简单了解即可。
完成无误后,我们跳转到after_page_tables:
after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0
pushl $0
pushl $L6 # return address for main, if it decides to.
pushl $_main
jmp setup_paging
L6:
jmp L6 # main should never return here, but
# just in case, we know what happens.
到这里,我们开始压栈,这个是一个十分重要的点,我会留一个思考题在这里,这里先不讲。
压栈完毕后,然后跳转到setup_paging:
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
xorl %eax,%eax
xorl %edi,%edi /* pg_dir is at 0x000 */
cld;rep;stosl
movl $pg0+7,_pg_dir /* set present bit/user r/w */
movl $pg1+7,_pg_dir+4 /* --------- " " --------- */
movl $pg2+7,_pg_dir+8 /* --------- " " --------- */
movl $pg3+7,_pg_dir+12 /* --------- " " --------- */
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* cr3 - page directory start */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* set paging (PG) bit */
ret /* this also flushes prefetch-queue */
这些代码会让改Linux内核向现代操作系统更近了一步,开启分页保护。
在正式开始之前我们先回顾一下与分页相关的知识。

其中,有两个位我们必须清楚开启分页机制的位PG。
PG位是启用分页机制。在开启这个标志之前必须已经或者同时开启PE标志。PG = 0且PE = 0,处理器工作在实地址模式下。PG = 0且PE = 1,处理器工作在没有开启分页机制的保护模式下。PG = 1且PE = 0,在PE没有开启的情况下无法开启PG。PG = 1且PE = 1,处理器工作在开启了分页机制的保护模式下。
由于当前内存只有16 MB,所以它采用了10-10-12分页。setup_paging开始的代码将会在0地址开始设置页表,这会覆盖head.s的开头的代码。不过没关系,一切都在计算当中,并不会覆盖到当前要执行的代码。
看一下分页情况:
/*
* I put the kernel page tables right after the page directory,
* using 4 of them to span 16 Mb of physical memory. People with
* more than 16MB will have to expand this.
*/
.org 0x1000
pg0:
.org 0x2000
pg1:
.org 0x3000
pg2:
.org 0x4000
pg3:
为什么要按照0x1000都间隔进行分页呢?这个是由于CPU规定的,每个页表是0x1000字节的大小。这里一共分了4个页,对于16 MB内存足够了。
但是,为什么给_pg_dir赋值的要加个7呢?我们来看一下10-10-12分页:
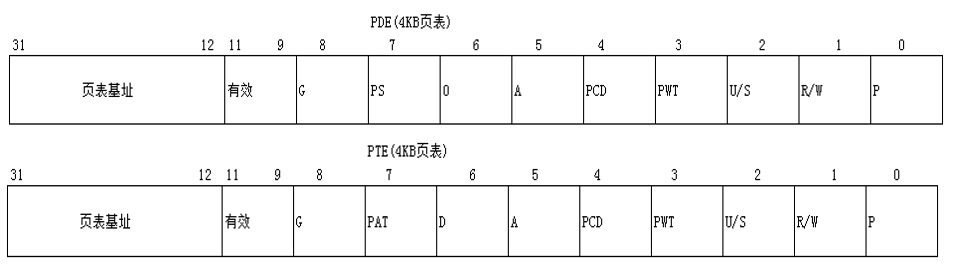
到这里,你可能就意识到了:_pg_dir其实就是所谓的PDE,如果加了7,就是加上了几个最后三个属性。其实这几张页表都是内核专用的。
这几句汇编可能比较难懂一些:
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b
我们现在的ecx是0,根据stos汇编的意思,也就是说把每一个页表填写上对应的数值,且执行一次。这么写的作用仅仅是为了更方便,更迅速。注意,它是从高地址向低地址填充页表的。
如果不理解,我们给一个最开始填充后的情况:

最后一块代码:
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* cr3 - page directory start */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* set paging (PG) bit */
ret /* this also flushes prefetch-queue */
由于访问物理内存需要CR3,它指向页目录表基址,所以给它赋值,之后开启分页保护开关,最后返回,所有的引导流程结束。
练习与思考
本节的答案将会在下一节进行讲解,务必把本节练习做完后看下一个讲解内容。不要偷懒,实验是学习本教程的捷径。
俗话说得好,光说不练假把式,如下是本节相关的练习。如果练习没做成功,就不要看下一节教程了。
- 复习本篇分析的代码流程,熟悉分页和中断门的构造。
- 在分页代码分析部分,你是怎么知道是
10-10-12分页,而不是2-9-9-12分页? - 最后的代码到底返回到了哪里?
- 绘制当前
system模块的内存分布。
下一篇
羽夏看Linux内核——内核初始化


本文来自博客园,作者:寂静的羽夏 ,一个热爱计算机技术的菜鸟
转载请注明原文链接:https://www.cnblogs.com/wingsummer/p/16581198.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号