Git subtree用法与常见问题分析
相信有过几年前端开发经验的同学都曾遇到过一个问题:前端如何在拆分工程的场景下共用代码。 一般有四个选择:
- npm包共享
- dll共享
- submodule
- subtree
一、方案对比
(一)、npm包共享
最容易想到的方法就是通过npm包共享,实践起来发现有如下缺点:
- 管理困难
- 单一负责人发布方式 负责人工作量很大,因为负责人需要处理代码上线关系,使得高版本包含低版本代码,而实际又经常因为进度原因,低版本后上线,对负责人要求比较高。 此外,开发发布需要和负责人沟通也是不小的成本。
- 开发自行发布方式 没有自动化流程,代码包含关系难以管理,很容易出现A发布的包缺少B的代码的情况,导致线上出问题。
- 先上线后测试
要部署测试环境,就必须先发布上线,由于这种不合常理的操作,需要配合诸如临时修改引用侧版本号等各种操作,操作繁琐且易出错。
(二)、dll共享
dll共享就是将公共模块单独作为一个工程打包,最终由使用方通过script标签引用,模块内的方法通过全局变量暴露给使用方。这种方式相比其他几种方式,最大的好处是公共模块可独立升级部署。但这个模式存在以下问题:
- 重复包、按需加载问题
dll模块必须经过打包,但打包后就会造成重复打包和无法按需加载的问题。
- 开发不便
公共模块是运行时加载的,编辑器在引用的工程内无法取得这个模块的任何定义,编辑器的补全、校验功能无法使用,降低了开发效率。如果是使用ts的话,可以考虑在公共模块写一份ts定义,在开发时,用软链接的方式把ts定义链接的引用工程,可一定程度上解决这个问题。
(三)、submodule
submodule是之前公司用来取代npm包的做法,原理是在一个git工程(父工程)下保存另一个git工程(子工程)的commitID,通过submodule的命令可以把这个commitID的代码同步到父工程。
由于submodule实际上只是把公共模块代码作为父工程的一个目录,与父工程共同运行,所以没有npm包、dll包这种独立于工程外引用造成的各种问题,submodule本身是git的功能,整个开发过程是纯git操作,所以也没有npm包管理上的麻烦,相比npm包优势明显,目前实践下来只发现几个小问题:
- 操作略显繁琐
父工程会记录一个submodule的commitId,这个id一旦变化,就需要执行submodule命令重新同步这个commitId的代码到本地,也就是切换分支,拉取新代码,所有引起commitID变化的操作,都需要执行额外的submodule命令。
这个问题可以规避,通过配置git config --global submodule.recurse true,使得每次切换分支或拉取代码时,自动update一下submodule。
另外修改submodule的代码需要同时操作父工程和子工程两个git,相比只操作单一工程更加繁琐。 - 学习成本
需要一定实践才能理解submodule的逻辑,在整个团队推广需要一些时间。
(四)、subtree
subtree实际和submodule有很多相似的地方,网上经常被拿来对比。
- submodule 在父工程维护子工程的git地址、当前代码绑定的commitID等,通过命令来同步这个commitID对应的代码到父工程,并且在git操作上,父工程和子工程也是分开操作的。
- subtree 不记录任何子工程的信息,每次输入命令,都必须带上git地址、分支名等信息,根据命令,把命令中指定的分支代码拷贝到本工程的指定目录,也能用命令把本工程指定目录的代码push到子工程,在开发过程中,完全不用管subtree的存在,直接当成只有一个工程开发提交就好了,等需要把代码同步到subtree仓库时再执行subtree push命令。
从表面上看,subtree有submodule好处,操作还比submodule简单,也更容易理解,因此目前团队选用了subtree作为跨工程共用代码方案,但实际并没有这么简单,详见三、subtree源码阅读。
二、subtree使用
以下命令均是在my-app工程执行、以/subtree/subtreeA为subtree的目录, subtree工程为subtree-project举例
(一)、git subtree add
- 完整命令: git subtree add --prefix=subtrees/subtreeA http://xxxxxxxxxxxx/subtree-project.git master
- 使用场景: 首次添加subtree。
- 实际操作: 该命令把subtree-project工程的master代码添加到my-app的subtrees/subtreeA目录下,可以看到执行后subtree-project工程的README已经在my-app工程下了,并产生一个提交记录。
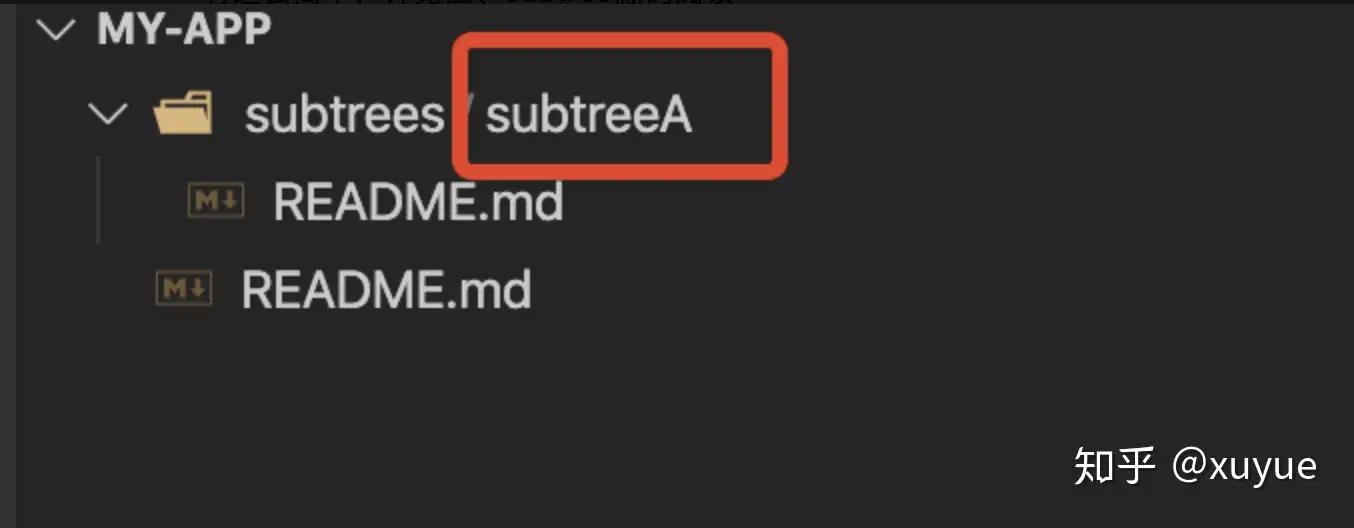

(二)、git subtree pull
- 完整命令: git subtree pull --prefix=subtrees/subtreeA http://xxxxxxxx/subtree-project.git master
- 使用场景: subtree代码有更新,需要同步到本工程。
- 实际操作: 该命令把subtree-project的master分支新增的提交merge过来,形成下面的提交记录。 my-app的提交记录:

my-app的subtrees/subtreeA下多了firstFile文件
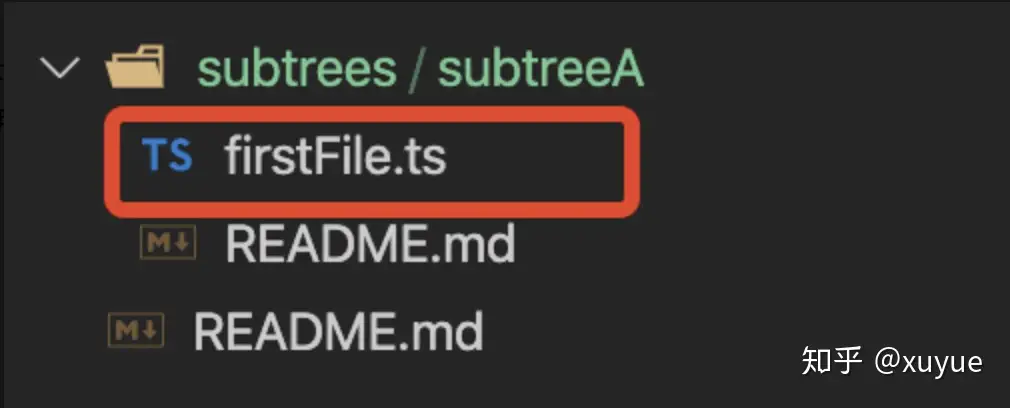
(三)、git subtree push
- 完整命令: git subtree push --prefix=subtrees/subtreeA http://xxxxxxxx/subtree-project.git master
- 使用场景: 在父工程修改了subtree的内容,需要把修改同步到subtree的git仓库。
- 实际操作: 首先在my-app添加三个文件 /subtrees/subtreeA/secondFile.ts /notSubtreeFileA.ts /notSubtreeFileB.ts 把/subtrees/subtreeA/secondFile和/notSubtreeFileA作为一次提交 has subtree file commit 把/notSubtreeFileB作为一次提交 no subtree file commit
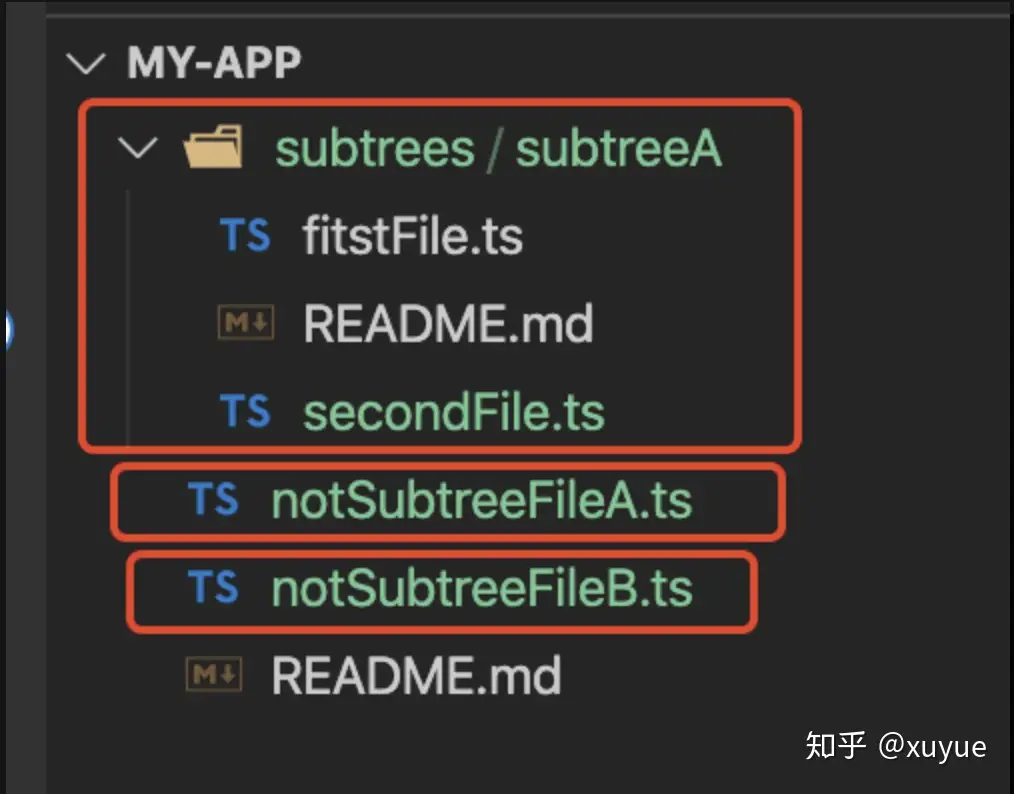
my-app的提交记录:
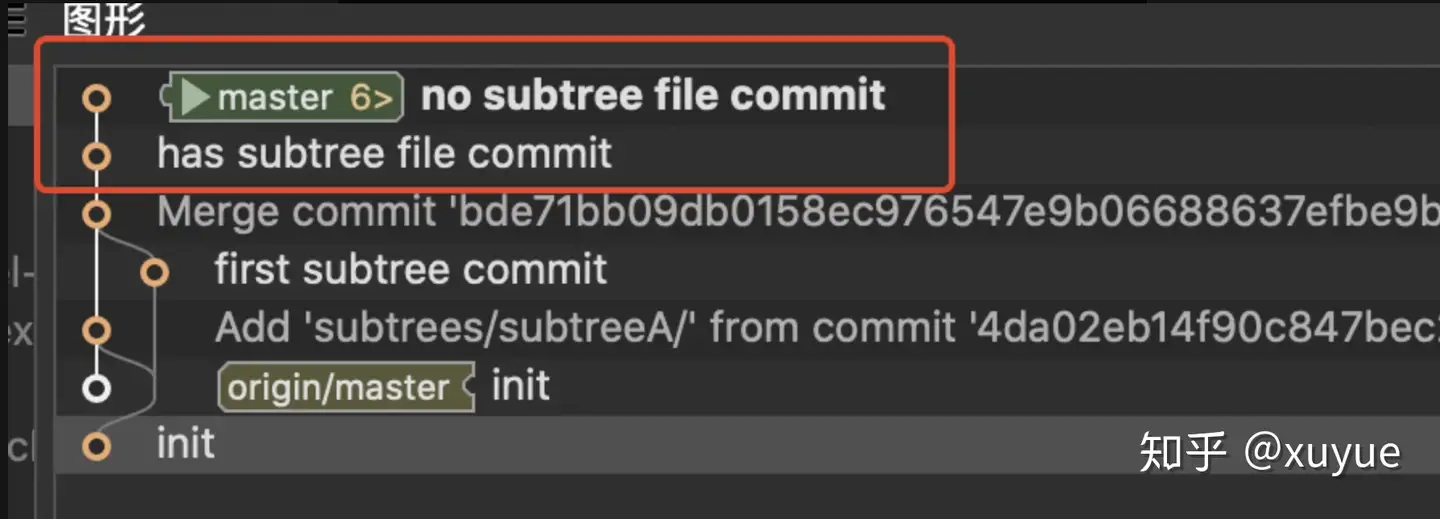
subtree-project的提交记录:

执行subtree push命令后,会发现刚才的两次提交,已经被同步到subtree-project工程了,且commit message和my-app上的提交信息一致,其中has subtree file commit这次提交只摘了subtree目录下的文件,忽略了notSubtreeFileA,由于no subtree file commit这个提交没有subtree目录的文件,所以整个提交被忽略了。
subtree-project的提交记录:

(四)、git subtree split
- 完整命令: git subtree split --prefix=subtrees/subtreeA --rejoin
- 使用场景: 提升subtree push效率。
- 实际操作: 从subtree push命令的功能可以看出,subtree push实际上是遍历本工程每一次提交,把提交文件涉及到subtree目录的挑出来,同步到subtree工程,如果提交有很多,遍历提交的过程是有严重的性能问题的,在2.19版本以前的git是可以执行的,但是很慢,在2.19以上的版本,会直接抛出异常。

spilt命令可以解决这个问题,执行split命令后,会看到my-app工程的提交记录,产生了一个新的分支,且这个分支和subtree push操作的逻辑一样,只把涉及subtree目录的提交摘出来了,最终这个分支合并到原分支,产生了一个Split xxxxx的提交记录。
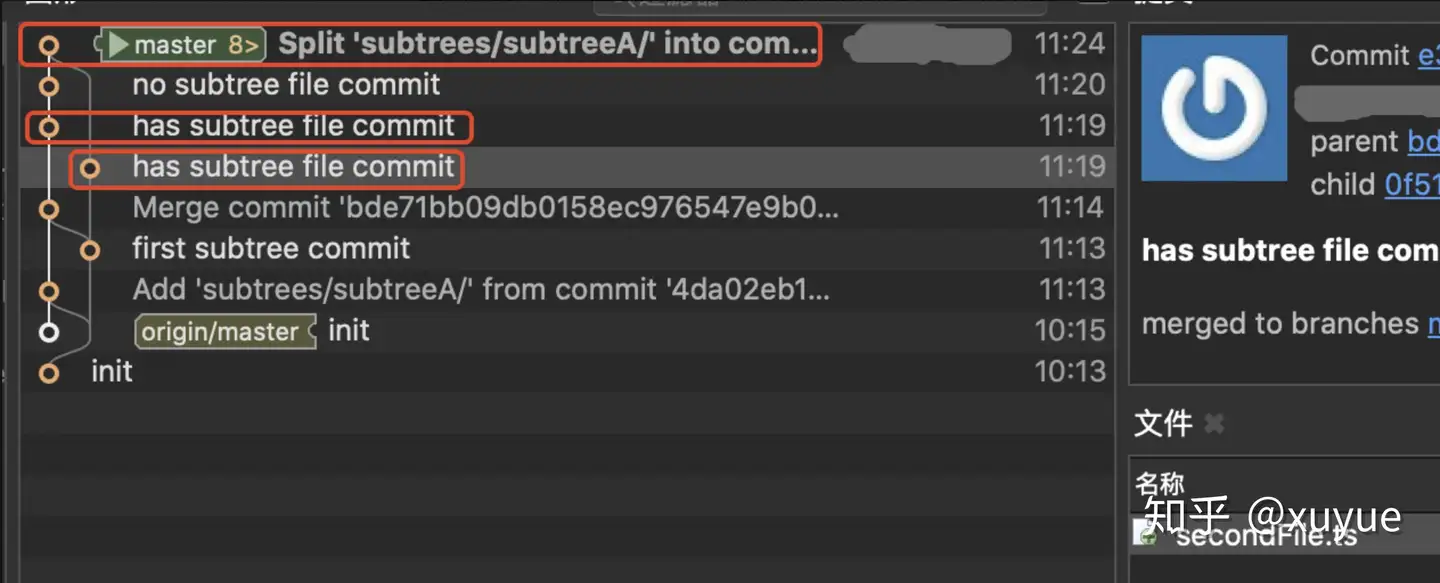
后续再执行subtree push操作,git只会检索split以后的提交,达到减少检索次数的目的,提升push性能。
三、subtree源码阅读
网上关于subtree的资料非常少,几乎都是只有简单用法,关于问题的解法、subtree原理的文章基本一篇都找不到,以下是在分析问题过程中阅读subtree源码的小结。
subtree到底如何遍历提交的
相信这个问题是很多人对subtree最大的疑问,因为引用subtree的工程是不保存任何和subtree工程相关的信息的,因此每次输入命令都需要带上git地址和分支名,那subtree push是如何做到只遍历到split或add的commit就停止的呢,他怎么能知道哪个commit是split的commit,我们通过查看源码分析这个问题。
在Mac上subtree脚本文件为/Library/Developer/CommandLineTools/usr/libexec/git-core/git-subtree,这份脚本代码是可以直接调试。
cmd_push () {
if test $# -ne 2
then
die "You must provide <repository> <ref>"
fi
ensure_valid_ref_format "$2"
if test -e "$dir"
then
repository=$1
refspec=$2
echo "git push using: " "$repository" "$refspec"
localrev=$(git subtree split --prefix="$prefix") || die
git push "$repository" "$localrev":"refs/heads/$refspec"
else
die "'$dir' must already exist. Try 'git subtree add'."
fi
}subtree push命令入口在cmd_push方法内,可以看出,这个方法实际上执行了一下subtree split,并把这个命令的输出push到subtree工程的git仓库,即subtree push = subtree split + git push,通过实验可以知道,subtree split在不带--rejoin参数的情况,输出是一个commitId,也就是这个命令生成了一个新commit。 从之前subtree split的执行结果可以看出,subtree split就是把包含subtree目录的提交摘出来的这个步骤,--branch就是把摘出来的提交放入一个指定分支,--rejoin就是不产生新分支,而是直接把摘出来的提交重新合入当前分支。
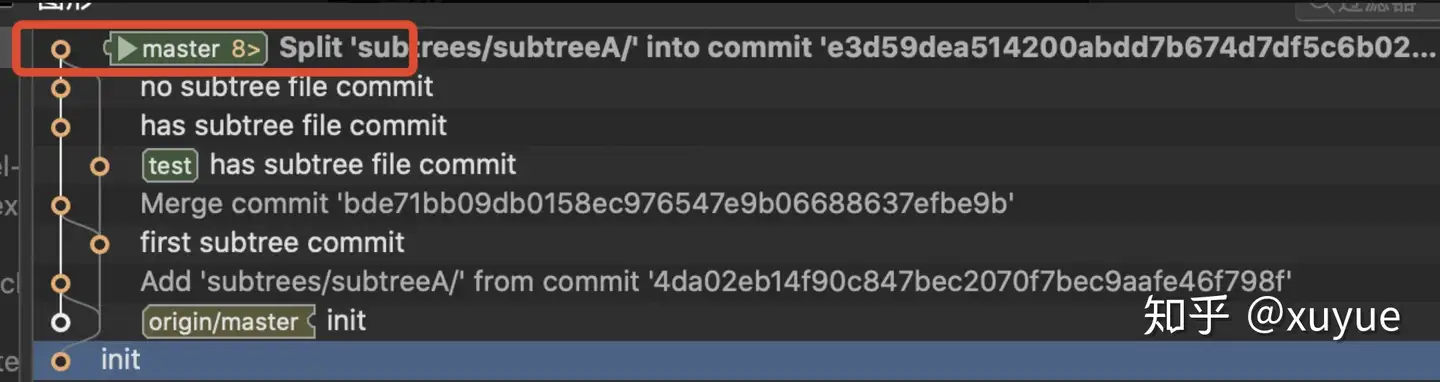
上述分析并没有解答我们的问题,subtree push是怎么找到split的提交的,继续看subtree split的代码。 这里由于split方法比较长,只贴出部分
cmd_split () {
debug "Splitting $dir..."
cache_setup || exit $?
if test -n "$onto"
then
debug "Reading history for --onto=$onto..."
git rev-list $onto |
while read rev
do
# the 'onto' history is already just the subdir, so
# any parent we find there can be used verbatim
debug " cache: $rev"
cache_set "$rev" "$rev"
done
fi
unrevs="$(find_existing_splits "$dir" "$revs")"
# We can't restrict rev-list to only $dir here, because some of our
# parents have the $dir contents the root, and those won't match.
# (and rev-list --follow doesn't seem to solve this)
grl='git rev-list --topo-order --reverse --parents $revs $unrevs'
revmax=$(eval "$grl" | wc -l)
revcount=0
createcount=0
extracount=0
eval "$grl" |
while read rev parents
do
process_split_commit "$rev" "$parents" 0
done || exit $?这里有两句重要代码,一个是find_existing_splits的调用,一个是git rev-list的调用,看方法名就知道,这个find_existing_splits方法就是用来找split的。
find_existing_splits () {
debug "Looking for prior splits..."
dir="$1"
revs="$2"
main=
sub=
local grep_format="^git-subtree-dir: $dir/*\$"
if test -n "$ignore_joins"
then
grep_format="^Add '$dir/' from commit '"
fi
git log --grep="$grep_format" \
--no-show-signature --pretty=format:'START %H%n%s%n%n%b%nEND%n' $revs |
while read a b junk
do
case "$a" in
START)
sq="$b"
;;
git-subtree-mainline:)
main="$b"
;;
git-subtree-split:)
sub="$(git rev-parse "$b^0")" ||
die "could not rev-parse split hash $b from commit $sq"
;;
END)懂shell的同学应该都明白了,大概翻译一下就是commit message带有git-subtree-dir、git-subtree-mainline、git-subtree-spilt的提交就认为是split的提交,subtree add的提交记录和subtree split类似也符合这个规则,所以这个规则能同时找出split提交的add提交。
从上面的git树可以看到,split提交是由两个提交合成的,并且split提交message里也有记录,一个是subtree-mainline,一个是subtree-split,找到split提交后,会从split的提交message里找到subtree-mainline和subtree-split的commitId,把这两个提交输出,作为git rev-list的参数。
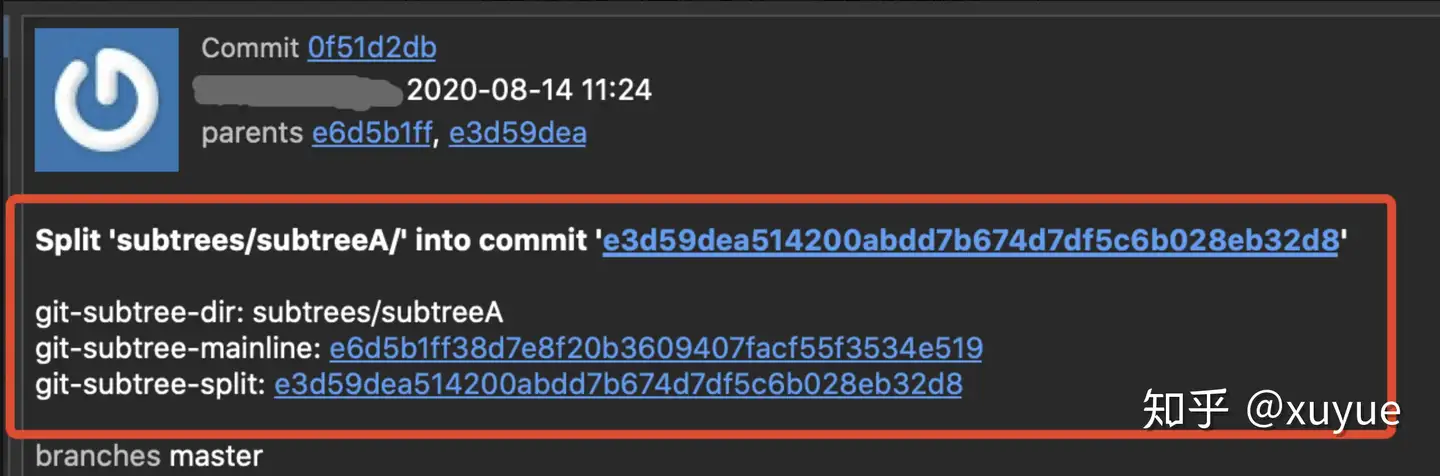
再查一下git rev-list的功能,整个命令git rev-list --topo-order --reverse --parents \$revs \$unrevs,意思是输出所有能到达$revs的commit且不能到达\$unrevs的commit,即在\$revs和\$unrevs之间的commit,其中\$revs是在脚本开始执行时赋值的,为执行命令时所在的commitId,\$unrevs则是find_existing_splits方法找到的commitId,就是这样,subtree push能只遍历当前提交和上一个split或add之间的提交。
通过一波阅读,基本明白了subtree push做了什么,subtree push遍历commit的规则,subtree是怎么找到subtree add 和subtree split的,为下面的问题解答提供思路。
四、subtree常见问题
(一)subtree push或subtree split报Segmentation fault

Segmentation fault错误的常见原因就是访问的内存超过了系统所给这个程序的内存空间,结合subtree push和subtree split做的事情,可以推测是遍历的commit太多了,有以下几种原因。
1.太久没split
上次split的提交到这次提交的数量已经超越了内存范围。
解决办法:
(1)先备份一个分支,然后在当前分支删了subtree再subtree add,重新生成一个subtree add的提交记录,这时subtree还原到master状态,再从备份的分支把对subtree的操作pick过来,最后subtree push。
(2)在mac上执行$ ulimit -s unlimited,把栈大小限制设置为不限制,再执行subtree split可执行成功,只是会很慢,因为还是遍历了很多次提交,只是没有超过栈大小限制。window设置方法网上也有一些,未做测试。
2.存在没有subtree add和subtree split的分支合入当前分支
这个情况在项目刚引入subtree时很容易发生。原因是有类似这样的提交树,test1在某个提交执行了subtree add,test2在subtree add之前就checkout出来了,最后再合入test。
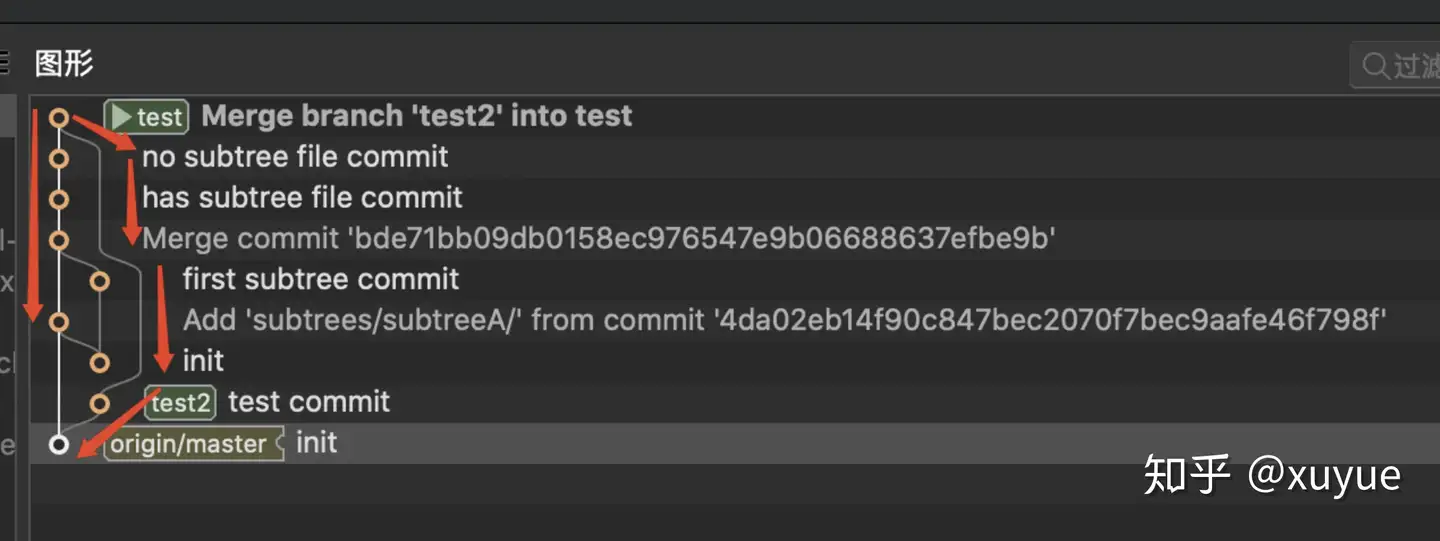
在遍历提交时,遍历到merge提交时,会往两个方向遍历,其中主干这个方向存在一个subtree add的提交,所以遍历到这里截止,但是test2这个分支是在subtree add之前就拉出来的,所以他的提交路径没有subtree add,最终绕过subtree add,把所有提交都遍历了,产生segmentation fault。
项目刚引入subtree时,由于其他同事的需求分支是在引入subtree之前就checkout出来的,最终合入master时就会产生这个情况,导致后续执行subtree push报错。
解决方法:
在引入subtree后,通知全员把正在开发的分支执行一下git rebase master。
(二)split没作用
这个问题是无意中发现的,如果有类似这样的提交,split提交的上一次提交,是一个merge提交,那这次split是无效的,分析了脚本代码,感觉应该是git的bug。
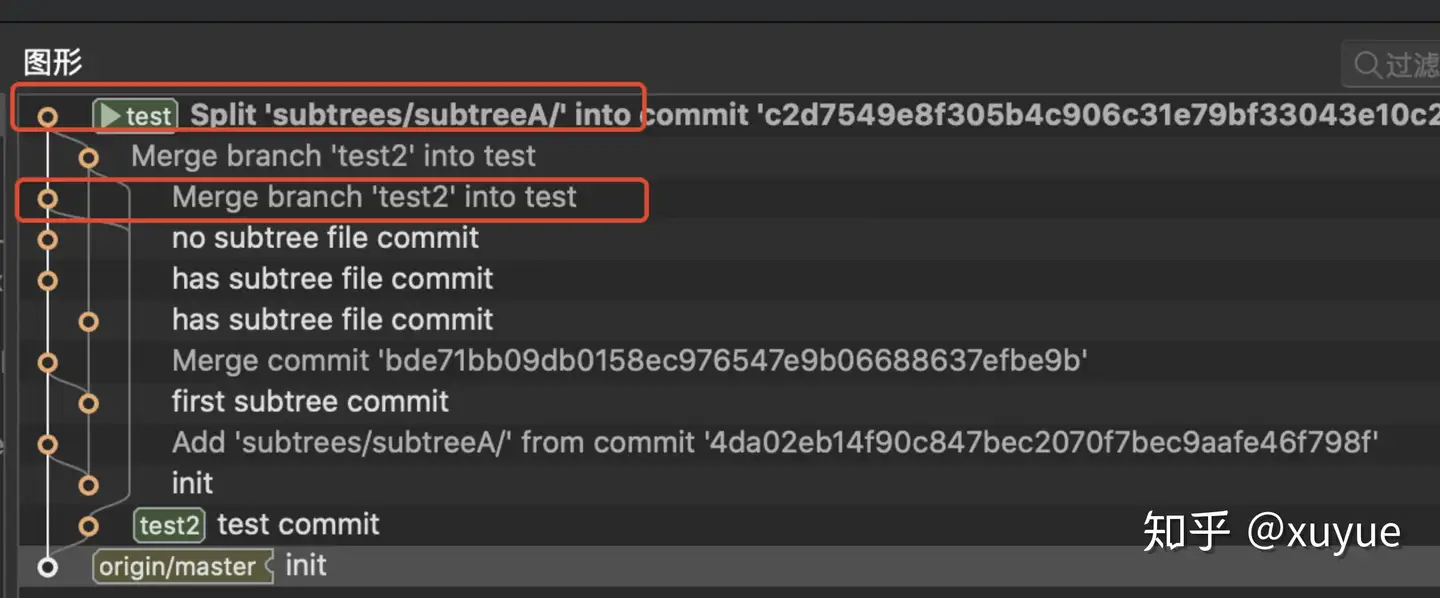
回到上面代码阅读时的find_existing_splits方法,找到了split commit后,会调用try_remove_previous输出结果,输出为\^commitId\^,这个语法的处理优先级为\^(commitId\^),(commitId\^)表示取这个commitId的第一个parent,\^commitId表示非这个commitId,在git rev-list命令中表示排除掉能到达这个commitId的提交,到达reachable这个词是官方文档写的,能到达它的提交就是这个提交的所有parent(包括parent的parent),不能到达它的提交就是这次提交的后续提交,综合起来就是输出(这个commitId的第一个parent)的后续提交。
try_remove_previous () {
if rev_exists "$1^"
then
echo "^$1^"
fi
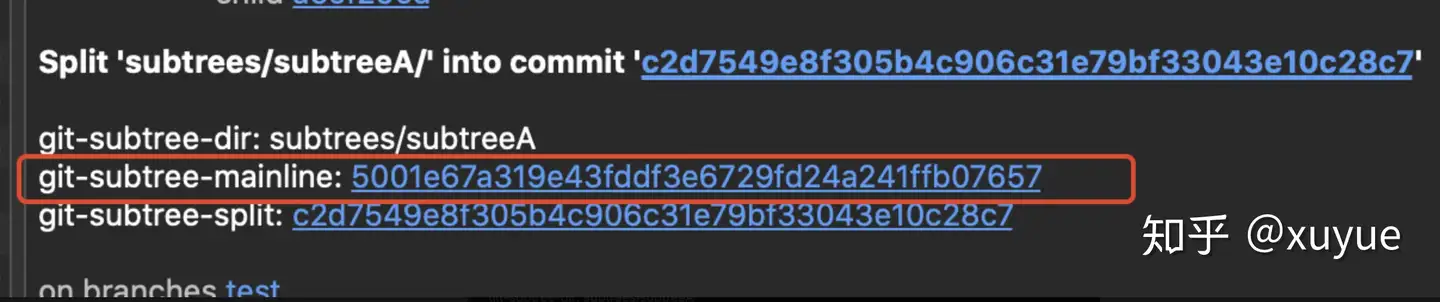
}当subtree push遍历提交时,不是遍历到一个split commit就截止遍历,而是会从这个split commit message中找到记录的subtree-mainline和subtree-split的commitId,然后再分别取这两个提交的第一个parent,作为截止点。
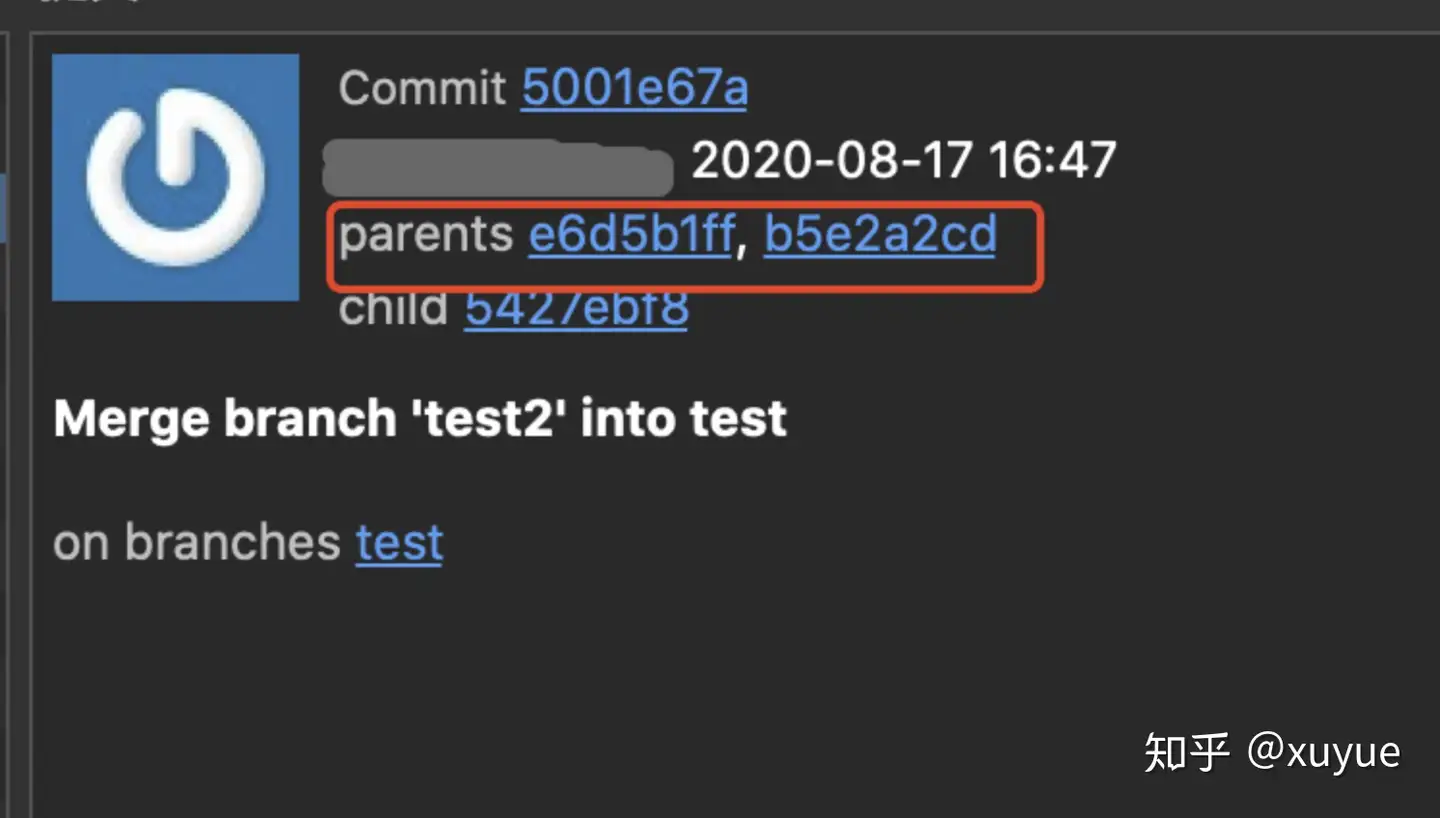
问题出在(comitId\^)取的是第一个parent,如果这个提交是一个merge提交,那会有两个parent,只取了第一个parent导致另外一个parent的分支绕过了这个split,没有截止点,整条分支被遍历。
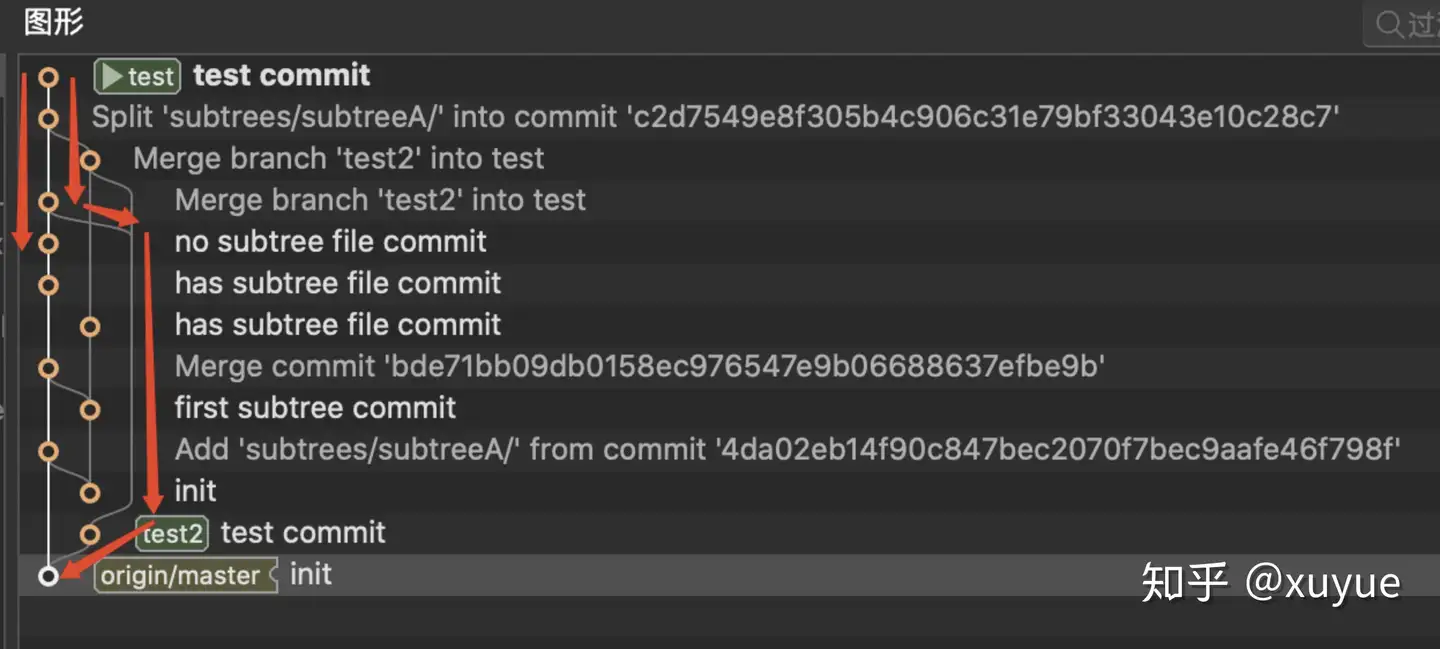
最终的遍历顺序如下,找到了split,从split的message里找到了subtree-mainline,也就是那个merge提交,取他的第一个parent也就是no subtree file commit作为截止点,但是另一边,merge的第二个parent,没有设置截止点,就一直遍历到init了(实际情况是会遍历到上一个split或add提交产生的截止点),最终的结果是这次split几乎等于无效。
五、总结
(一)、四个方案个人认为的排序是subtree = submodule > dll > npm,subtree由于git命令长+资料匮乏,一点问题就要看源码,稍微减分,和submodule相同。
(二)、subtree通过commit message来找到split和add的commit,截止遍历提交,因此split和add命令自动生成的提交信息不能随便修改。
(三)、如果split提交前一个提交是merge提交,则这次split无效,可以通过在两个提交中间提交一个空commit规避这个问题。
(四)、subtree所有问题都可以通过删掉subtree重新add解决,实在没办法可以先这样。
作者: jacksonyxu
链接:https://zhuanlan.zhihu.com/p/253148857
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号