谱多流形聚类SMMC
今天是2015年的最后一天,决定尽量乘着这三天休息把毕设主题的博客给更完,今天写smmc的算法,接下来三天会对前面的三个算法kmeans、SC以及smmc应用在今年的研究生建模提供的数据中进行matlab实现从而进行效果对比,还有一件高兴的事情是进入沪江三年多了,第一次被cctalk里面的老师抱上麦进行真正意义上的英文对话,搞得都想转行去魔都发展英文了。哈哈,言归正传,进入学术世界吧~
注意:这里的文字很多摘抄于发表在IEEE上的英文论文《Spectral Clustering on Multiple Manifolds》,觉得人家总结的很好,拿过来拜读一下(部分图片来自于该论文,侵删)~
在前面的文章谱聚类算法的描述中,我们举出了谱聚类算法的各种貌似靠谱的切割方式。然而,这里的谱聚类的良好聚类结果强烈的依赖于邻接矩阵W,也就是说,当来自不同类的点之间的权重(关系)很小时该算法才能成功发挥效用!这么说可能难以理解,请看以下图片:
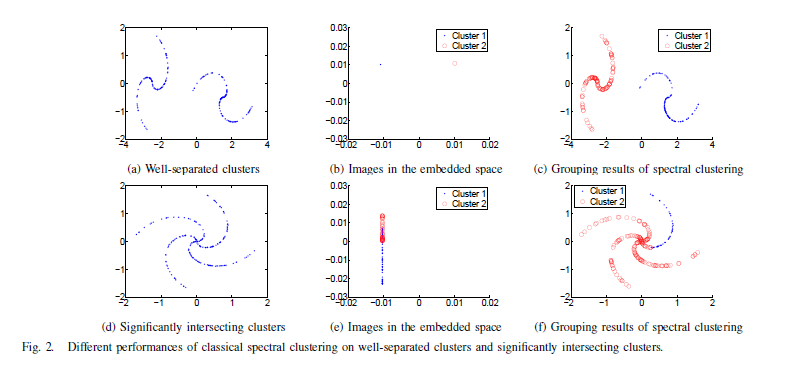
上图中,a、b、c来自于良好分离的两个类的数据聚类结果演示,d、e、f来自有明显相交的数据聚类演示。从图a的数据可视化结果,我们能轻易的了解到两个"S"型的数据簇良好分离,可以被轻易的分割为两个类。通过仔细调整最近邻参数K或者数值参数![]() 轻易获得邻接矩阵W的特征。最理想的情况就是来自不同簇的点之间的权重为w=0;这时,谱方法就会将同一个簇内的点映射到
轻易获得邻接矩阵W的特征。最理想的情况就是来自不同簇的点之间的权重为w=0;这时,谱方法就会将同一个簇内的点映射到![]() 空间的一个独立的点,依次类推,在这样的一个k维空间中就存在k个互相正交的点(如图b所示)。最后将这些点返回映射到原始数据中,聚类结果就如图c所示。
空间的一个独立的点,依次类推,在这样的一个k维空间中就存在k个互相正交的点(如图b所示)。最后将这些点返回映射到原始数据中,聚类结果就如图c所示。
然而,当遇到图d所示的数据时,我们可以看到上图d中的数据之间存在明显的相交处,此时邻接矩阵将会因为成对点之间的不靠谱的相似度而不能很好的反映数据之间的关系。比如说,一般情况下,不同簇内的点之间的相似度很低(接近0)但是在上图中数据的交汇处的点之间的相似度将会因为它们的欧式距离很小变得很高。简而言之,我们试图将上图d中的数据聚为两类,但是因为这两个类彼此之间关系相当紧密导致无法将其分为两个子集。
实际上,广义特征问题(D-W)*u=lambda*D*u(lambda为特征值,u为特征向量,这里我不明白作者为啥在等式右边多写一个D)类似于LEM(拉普拉斯特征映射)的最优化问题,该问题是一个经典的流形学习问题。我们很容易本例中的前两个特征向量是由拥有相同值的标量组成,该标量最优的保留了原始数据的局部领域信息。导致两个不同簇的相交结构被保留到了映射空间中(如图e所示),后面的kmeans算法也就无法将这个结构分离开来。
现在,我们知道了谱聚类的弱点,俗话说:学无止境。因此,我们借助了亲爱的多流形学习方法引入了谱多流形聚类(smmc)。
先挖个坑,先去老哥那里过完元旦第二天继续补~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号