《分布式技术原理与算法解析》学习笔记Day22
 这篇文章主要描述分布式数据存储系统中的数据分片方法,包括哈希方法、一致性哈希方法、带有限负载的一致性哈希方法以及带虚拟节点的一致性哈希方法。
这篇文章主要描述分布式数据存储系统中的数据分片方法,包括哈希方法、一致性哈希方法、带有限负载的一致性哈希方法以及带虚拟节点的一致性哈希方法。
哈希与一致性哈希
在分布式系统中,哈希和一致性哈希是数据索引或者数据分布的常见实现方式。
数据分布设计原则
在分布式数据存储系统中,做存储方案选型时,一般会考虑以下因素:
- 数据均匀
- 数据稳定
- 节点异构性
- 隔离故障域
- 性能稳定性
数据均匀有两重含义:
- 不同存储节点中存储的数据要尽量均衡,避免让某一个或者某几个节点存储压力过大,而其他节点几乎没有什么数据。
- 用户访问也要做到均衡,避免出现某一个或者某几个节点的访问量很大,但其他节点却无人问津的情况。
数据稳定是指当存储节点出现故障需要移除或者扩增时,数据按照分布规则得到的结果应该尽量保持稳定,不要出现大范围的数据迁移。
节点异构性是指不同存储节点的硬件配置可能差别很大,这样平均分配数据就是一种不均衡。
隔离故障域是指为了保证数据的可用和可靠性,需要做数据备份,但是如果主数据和备份数据都放到了同一个硬盘或者节点,就违背了备份的初衷。一个好的数据分布算法,应该为每个数据映射一组存储节点,这些节点应该尽量在不同的故障域。
性能稳定是指数据存储和查询的效率要有保证,不能因为节点的添加或者删除,造成存储或者访问性能的严重下降。
数据分布方法
我们会涉及4种不同的数据分布方法。
哈希
哈希是指将数据按照提前规定好的函数映射到相应的存储节点,即进行一个哈希计算,得到的结果就是数据应该存储的节点。
它是一种非常常用的数据分布方法,核心思想是:1)确定一个哈希函数,2)通过计算得到数据对应的存储节点。
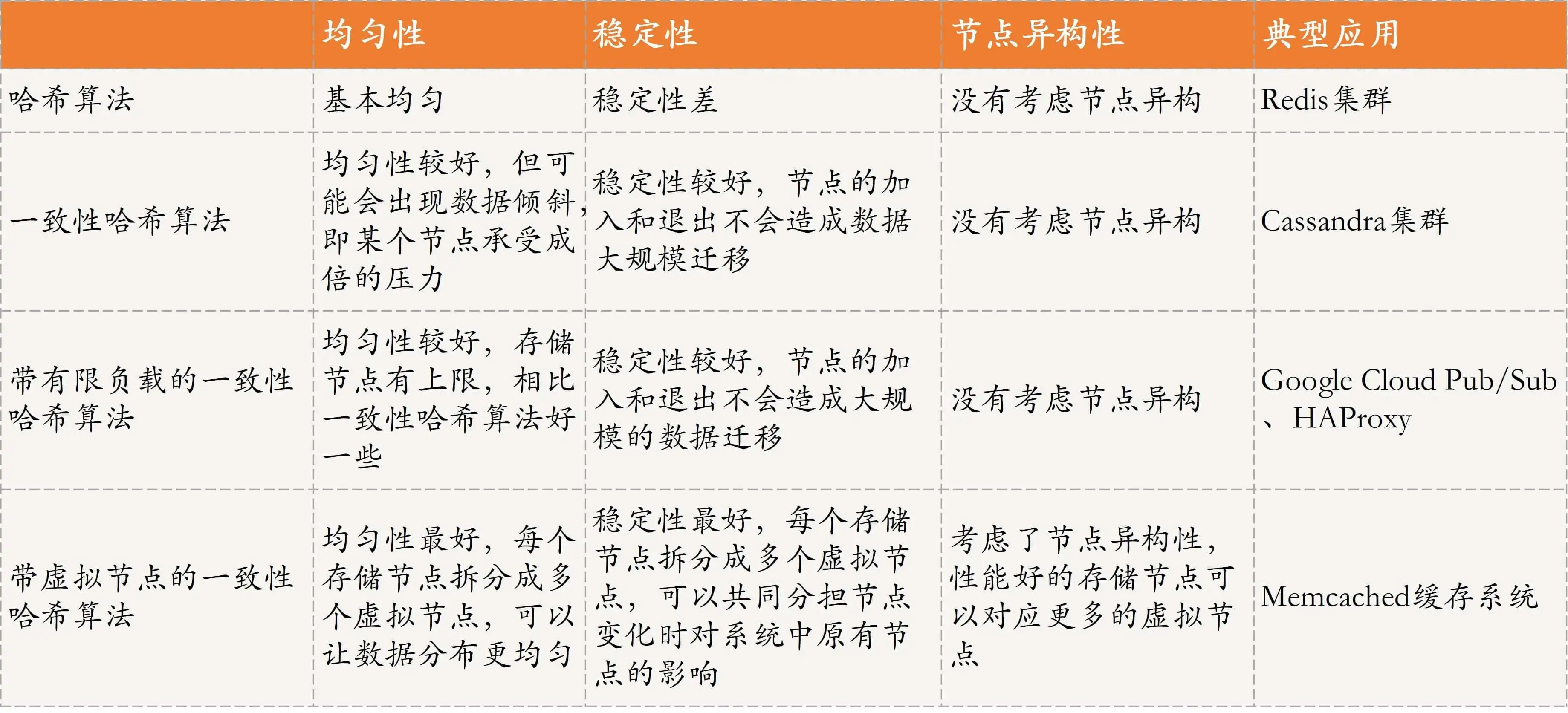
哈希算法的一个优点是只要哈希函数设置得当,可以很好的保证数据均匀性,但缺点是稳定性差,当节点数量发生变化时,需要大规模数据迁移。
哈希方法适用于同类型节点且节点数量比较固定的场景。
一致性哈希
一致性哈希也是采取哈希函数,但是进行两步哈希:
- 对存储节点进行哈希计算,即对存储节点进行哈希映射。
- 当对数据进行存储或者访问时,首先对数据进行映射得到一个结果,然后找到比该结果大的第一个存储节点,就是该数据应该存储的节点。
一致性哈希将存储节点和数据都映射到一个首尾相连的哈希环上,存储节点可以根据IP地址进行哈希,数据通常按照顺时针方向寻找的方式,来确定自己所属的存储节点,即从数据映射在环上的位置开始,顺时针方向找到的第一个存储节点。
一致性哈希是对哈希方法的改进,在数据存储时采用哈希方式确定存储位置的基础上,又增加了一层哈希,也就是在数据存储前,对存储节点预先进行了哈希映射。
这种改进很好的解决哈希方法存在的稳定性问题,当节点加入或退出时,仅影响该节点在哈希环上顺时针相邻的后继节点。
一致性哈希带来的主要问题是均匀性问题,即对后继节点的负载会变大,当有节点退出时,该节点的后继节点需要承担该节点的所有负载,如果后继节点承受不住,便会出现节点故障,导致后继节点的后继节点也面临同样的问题。
一致性哈希方法比较适合同类型节点、节点规模会发生变化的场景。
带有限负载的一致性哈希
带有限负载的一致性哈希方法的核心原理是:给每个存储节点设置一个存储上限值,来控制存储节点添加或者删除造成的数据不均匀。当数据按照一致性哈希算法找到相应的存储节点后,要先判断该存储节点是否达到了存储上限,如果已经达到了上限,则需要继续寻找该存储节点顺时针方向之后的节点进行存储。
带有限负载的一致性哈希方法适合同类型节点、节点规模会发生变化的场景。
带虚拟节点的一致性哈希
带虚拟节点的一致性哈希方法的核心思想是:根据每个节点的性能,为每个节点划分不同数量的虚拟节点,并将这些虚拟节点映射到哈希环中,然后再按照一致性哈希算法进行数据映射和存储。
带虚拟节点的一致性哈希方法比较适合异构节点、节点规模会发生变化的场景。
这种方法不仅解决了节点异构性问题,还提高了系统稳定性,当节点发生变化时,会有多个节点共同分担系统的变化。但是这种方法需要维护虚拟节点,增加了维护和管理的复杂度,同时,节点变化带来的数据迁移等操作也会变得复杂。
下面是4种不同的数据分片方法的详细比较。
数据分区和数据分片的区别
数据分区是从数据存储块的维度进行划分,不同的分区在物理上归属于不同的节点。数据分区中可以存储不同的数据,也可以存储相同的数据来实现数据备份。
数据分片是从数据维度进行划分,它将一个数据结合按照一定的方式划分成多个数据子集,不同的数据子集存储在不同的存储块上,这些存储块可以在不同的节点上,也可以在同一个节点上。
数据分区和数据分片是两个不同的概念,属于分布式存储系统中不同角色的技术。数据分区是“数据存储”相关的技术,数据分片是“数据索引”现骨干的技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号