

《分布式技术原理与算法解析》学习笔记Day21
 分布式存储系统将用户存储的数据根据某种规则存储到不同机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器中获取。数据生产者/消费者、数据索引和数据存储是分布式存储系统的三大要素。
分布式存储系统将用户存储的数据根据某种规则存储到不同机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器中获取。数据生产者/消费者、数据索引和数据存储是分布式存储系统的三大要素。
分布式数据存储三要素
什么是分布式数据存储系统?
分布式存储系统的核心逻辑,就是将用户需要存储的数据根据某种规则存储到不同的机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器中获取。
分布式存储系统的三要素:
- 数据生产者 / 数据消费者
- 数据索引
- 数据存储
数据生产者生产数据,将数据存储到分布式数据存储系统中,数据消费者是从分布式数据存储系统中获取数据进行消费;数据索引将访问数据的请求转发到数据所在的存储节点;存储设备用来存储数据。
分布式系统数据类型
分布式系统中存在大量不同类型的数据,根据数据的特征,我们可以将其分为三类:
- 结构化数据,指关系模型数据,特征是数据关联较大、格式固定,一般采用分布式关系数据库进行存储和查询。
- 半结构化数据,指非关系模型数据,有基本固定结构模式的数据,特征是数据之间关系比较简单,一般采用分布式键值系统进行存储和使用。
- 非结构化数据,指没有固定模式的数据,特征是数据之间关联不大,这种数据一般存储到文档中,通过ElasticSearch等进行检索。
数据分片与数据复制
数据分片技术,是指分布式存储系统按照一定的规则,将数据存储到相应的存储节点中,或者到相应的存储节点中获取想要的数据。这种技术一方面可以降低单个存储节点的存储和访问压力,另一方面可以通过规定好的规则快速找到数据所在的存储节点,从而大大降低搜索延迟,提高用户体验。
数据分片可以采取不同的方式,包括:
- 数据特征分片
- 数据范围分片
- 哈希分片
- 一致性哈希分片
数据复制是指将数据进行备份,使得多个节点存储该数据。它可以通过主备方式存储的方式,提高分布式系统的可用性和可靠性。
在实际的分布式存储系统中,数据分片和数据复制通常是共存的:
- 数据通过分片方式存储到不同的节点上,以减少单节点的性能瓶颈问题。
- 数据的存储通过主备方式保证可靠性,即对每个节点上存储的分片数据,采用主备方式存储,来保证数据可靠性,其中主备节点上数据一致,是通过数据复制技术实现的。
数据存储
根据上述三种不同的数据类型,常采用的数据存储选型方案如下:
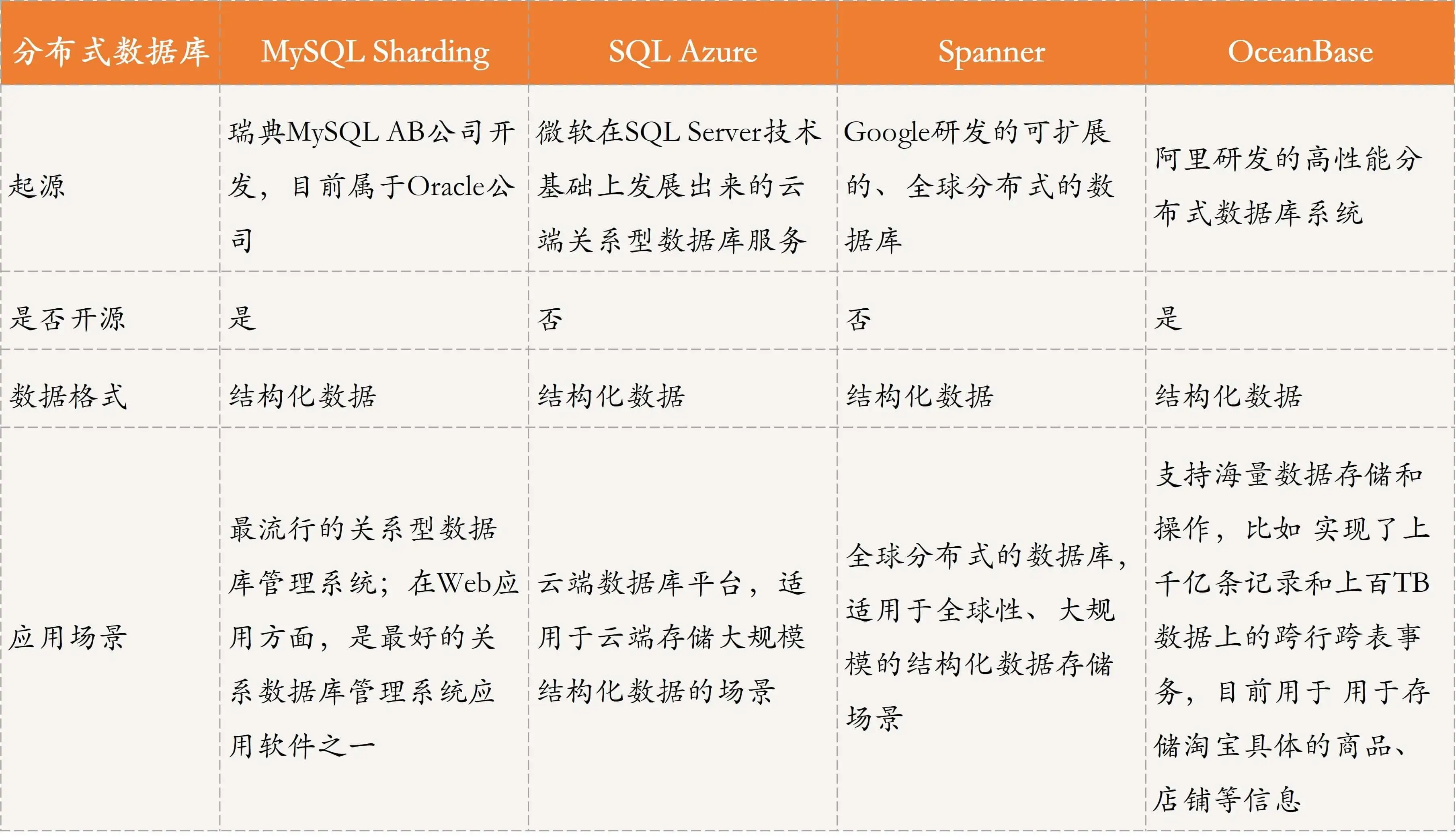
- 分布式数据库,通过表格来存储结构化数据,方便查找。常见的方案包括:MySQL Sharding、Microsoft SQL Azure、Google Spanner、Alibaba OceanBase等。
- 分布式键值系统,通过兼职对来存储半结构化数据。常见的方案包括:Redis、Memcache等。
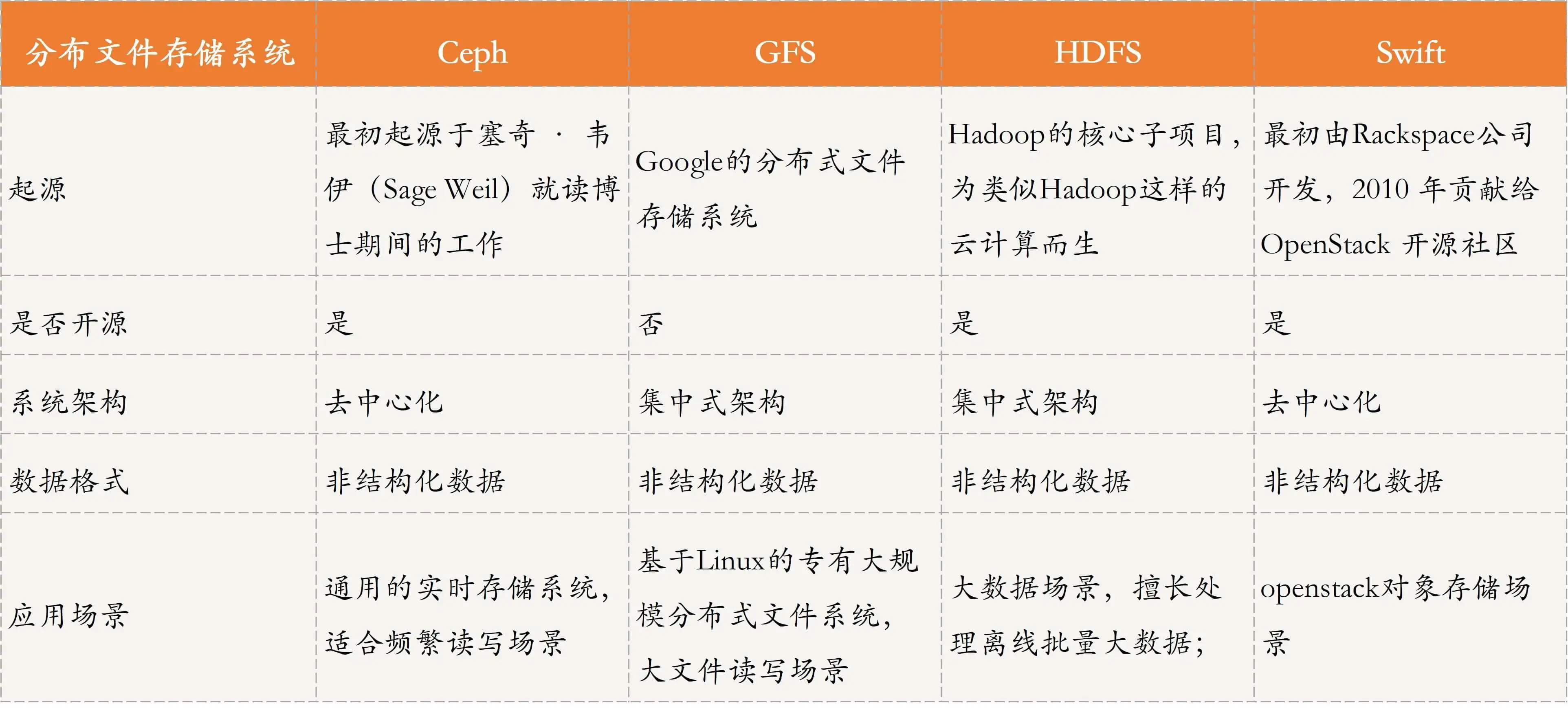
- 分布式存储系统,通过文件、块、对象等来存储非结构化数据。常见的方案包括:Ceph、GFS、HDFS、Swift等。
详细的分布式数据库比较如下。
详细的分布式存储系统比较如下。
作者:李潘
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通