

《分布式技术原理与算法解析》学习笔记Day16
 这篇文章主要描述分布式系统中的流水线计算模式,它来自于工业领域的流水线作业模式,将一个任务分为多个步骤执行,可以提高系统效率。文章描述了ETL流水线以及机器学习中常用的模型训练流水线。
这篇文章主要描述分布式系统中的流水线计算模式,它来自于工业领域的流水线作业模式,将一个任务分为多个步骤执行,可以提高系统效率。文章描述了ETL流水线以及机器学习中常用的模型训练流水线。
分布式计算模式:流水线
计算机中的流水线技术是一种将每条指令拆分为多个步骤,多条指令的不同步骤重叠操作,从而实现几条指令并行处理的技术。
分布式领域的流水线计算模式,参考了工业生产中的流水线作业模式,将一个任务分为多个步骤执行,使得不同任务可以并行执行,从而提高系统效率。
输入流水线(ETL)
TensorFlow运用了流水线模式对输入数据进行预处理,也称为ETL流水线,它包括3个步骤:
- 提取(Extract),通过多种途径读取数据。
- 转换(Transform),使用CPU对输入的数据进行解析以及预处理操作。
- 加载(Load),将转换后的数据加载到执行机器学习模型的加速器设备上,例如GPU或者TPU。
机器学习流水线
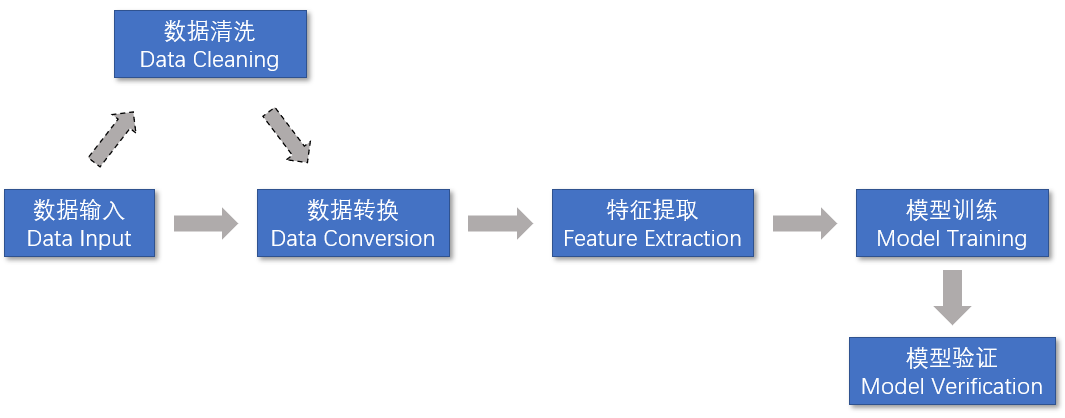
一个典型的机器学习训练模型按照流水线计算模式进行拆分,可以分为5个步骤:
- 数据输入,从不同的数据源中导入数据。
- 数据转换,将输入的无结构的数据转换成合适的格式。
- 特征提取,从数据集中提取特征数据。
- 模型训练,提供一个算法,并提供一些训练数据让模型可以学习。
- 模型验证,通过训练得到的结果,对模型进行错误率验证。
整个流水线示示意图如下所示。
流水线模式和MapReduce中对任务划分的区别?
首先它们划分的粒度不同:
- MapReduce以任务为粒度,将大的任务划分成多个小任务,每个任务都需要执行完整的、相同的步骤,同一任务能被并行执行,这是任务并行的一种计算模式。
- 流水线计算模式以步骤为粒度,一个任务拆分为多个步骤,每个步骤执行的事不同的逻辑,多个同类型任务通过此步骤重叠来实现不同任务的并行计算,它是数据并行的一种模式。
另外,它们划分出来的子任务之间的关系也不同:
- MapReduce中各个子任务可以独立执行,互不干扰,多个子任务执行完成后,进行结果合并得到整个任务的结果,因此要求子任务之间是没有依赖关系的。
- 流水线模式中多个子任务之间具有依赖关系,前一个子任务的输出是下一个子任务的输入。
流水线计算模式和流计算有什么区别?
流水线模式把一个问题分成不同的步骤,必须按照严格的顺序处理,它的核心是错开了时间,提高了时间利用率,但是最终结果是相同的。
流计算模式侧重数据输入方式和流动方向,处理数据时可以多方向流动,最终输出不同的结果,在流计算的过程中,可能会用到流水线模式,把一个大的处理流程拆分成小的流程。
流计算对数据处理是实时的,流水线模式对数据处理可以是实时的,也可以是批处理方式。
流计算关注的是计算的实时性,对数据依赖性没有流水线计算模式那么高。
作者:李潘
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通