《RPC实战与核心原理》学习笔记Day14
 这篇文章主要描述如何定位RPC问题以及如何使用时钟轮来管理RPC中的定时任务,主要包括如何设计合适的异常机制,如何使用分布式链路跟踪系统,以及如何使用时钟轮来管理RPC中的超时控制和心跳检测。
这篇文章主要描述如何定位RPC问题以及如何使用时钟轮来管理RPC中的定时任务,主要包括如何设计合适的异常机制,如何使用分布式链路跟踪系统,以及如何使用时钟轮来管理RPC中的超时控制和心跳检测。
19 | 分布式环境下如何快速定位问题?
分布式环境下定位问题有什么难点?
分布式环境下定位问题的难点在于,各子应用、子服务之间有复杂的依赖关系,我们有时很难确定是哪个服务的哪个环节出现的问题。如果要通过日志来排查问题,就需要对每个子应用、子服务逐一进行排查,很难一步到位。
在分布式环境下如何快速定位问题?
有两种方式:
- 借助合理封装的异常信息
- 借助分布式链路跟踪
RPC框架打印的异常信息中,需要包含定位问题所需要的异常信息的,比如哪些异常引起的问题(如序列化问题或网络超时问题),是调用端还是服务端出现的异常,调用端与服务端的IP是多少,以及服务接口与服务分组是什么等等。
异常的示意图如下所示。

一款优秀的RPC框架要对异常进行详细地封装,还要对各类异常进行分类,每类异常都要有明确的异常标识码,并整理成一份简明的文档。适用房可以快速地通过异常标识码在文档中查阅,从而快速定位问题,找到原因,并且异常信息中药包含排查问题时所需要的重要信息,比如服务接口名、服务分组、调用端和服务端的IP,以及产生异常的原因。总之,要让适用房在复杂的分布式应用系统重,根据异常信息快速地定位到问题。
分布式链路跟踪可以让我们快速的知道整个服务调用的链路信息以及被调用的各个服务是否存在问题。例如服务A调用下游服务B,服务B又调用了B依赖的下游服务,如果服务A可以清楚的知道整个调用链路,并且能准确的直到调用链路中个服务的状态,那么就可以快速的定位问题。
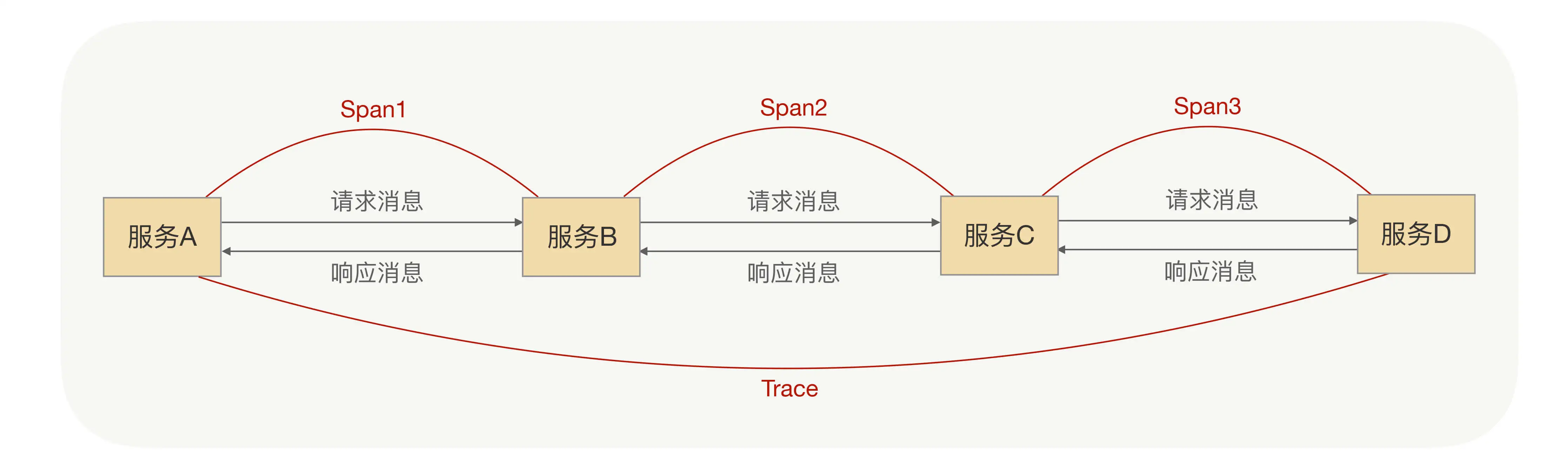
分布式链路跟踪有Trace和Span两个关键概念:
- Trace:代表整个链路,每次分布式都会产生一个Trace,每个Trace都有它的唯一标识,即TraceId,在分布式链路跟踪系统重,就是通过TraceId来区分每个Trace的。
- Span:代表了整个链路的一段链路,也就说Trace是由多个Span组成的。在一个Trace下,每个Span也有唯一的标识SpanId,而Span之间是存在父子关系的。
Trace和Span的关系如下图所示。
RPC在整合分布式链路跟踪所需要做的核心事情有2件:
- 埋点:分布式链路跟踪系统要想获得一次分布式调用的完整链路信息,就必须对这次分布式调用进行数据采集,而采集这些数据的方法就是通过RPC框架对分布式链路跟踪进行埋点。RPC调用端在访问服务端时,在发送请求消息前会触发分布式跟踪埋点,在接收到服务端响应时,也会触发分布式跟踪埋点,并且在服务端也会有类似的埋点。这些埋点最终可以记录一个完整的Span,而这个链路的源头会记录一个完整的Trace,最终Trace信息也会上报给分布式链路跟踪系统。
- 传递:上游调用端将Trace信息与父Span信息传递给下游服务的服务端,由下游触发埋点,对这些信息进行处理,在分布式链路跟踪系统重,每个子Span都存有父Span的相关信息以及Trace的相关信息。
20 | 详解时钟轮在RPC中的应用
RPC中的定时任务应该如何处理?
- 针对有定时需求的请求,建立额外的线程,使用Thread.sleep方法来处理。
- 建立一个单独的线程,来持续扫描有定时需求的请求,判断是否到时间了。
- 使用时钟轮方法
在时钟轮机制中,有时间槽和时钟轮的概念,时间槽相当于时钟的刻度,时钟轮箱单与秒针与分针等跳动的一个周期,我们会将每个人物放到相应的时间槽位上。
时钟轮的运行机制和生活中的时钟是一样的,每隔固定的单位时间,就会从一个时间槽位调到下一个时间槽位,这就相当于我们的秒针跳动了一次;时钟轮可以分为多层,下一层时钟轮中每个槽位的单位时间是当前时间轮整个周期的时间,这就相当于1分钟等于60秒钟;当时钟轮将一个周期的所有槽位都跳动完后,就会从下一层时钟轮中取出一个槽位的任务,重新分不到当前的时钟轮中,当前时钟轮则从第0槽位开始重新跳动,这就相当于下一分钟的第1秒。
在RPC框架中哪些功能会用到时钟轮?
- 调用端请求超时处理,我们每发一次请求,都创建一个处理请求超时的定时任务放到时钟轮里,在高并发、高访问量的情况下,时钟轮每次只轮询一个时间槽位中的任务,这样会节省大量的CPU。
- 心跳检测,对于这种需要重复执行的定时任务,我们可以在定时任务执行逻辑的最后,重设这个任务的执行时间,把它重新丢回到时钟轮里面。
在使用时间轮时,我们需要注意两件事情:
- 时间槽位的单位时间越短,时间轮触发任务的时间就越精确。
- 时间轮的槽位越多,那么一个任务呗重复扫描的概率就越小,因为只有在多层时钟轮中的任务才会被重复扫描。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号