《RPC实战与核心原理》学习笔记Day2
 这篇文章主要关注2点:
1. RPC协议
2.对象序列化与反序列化
设计RPC协议不仅关注性能,更要关注可扩展性和灵活性。
选择序列化和反序列化框架时,不仅要关注性能、效率,更要关注安全和可靠。
这篇文章主要关注2点:
1. RPC协议
2.对象序列化与反序列化
设计RPC协议不仅关注性能,更要关注可扩展性和灵活性。
选择序列化和反序列化框架时,不仅要关注性能、效率,更要关注安全和可靠。
02 | 协议:怎么设计可扩展且向后兼容的协议?
我们为什么需要使用协议?
在网络通信的过程中,为了避免语义不一致的情况,我们需要在发送请求时设定一个边界,然后再收到请求时按照设定的边界对请求数据进行分割。这里的边界语义的表达,就是我们所说的协议。
为什么我们在RPC中不使用HTTP作为主要协议?
RPC负责应用间通信,对性能要求高,但HTTP协议的数据包大小相对请求数据来说,要大很多,包含了很多额外字符,例如换行、回车等。
HTTP协议属于无状态协议,客户端无法对请求和响应进行关联,不能很好地进行异步处理。
我们在设计协议时,一般会把协议分成两部分:
- 协议头,由一堆固定长度的参数组成。
- 协议体,根据请求接口和参数构造,长度可变。
什么是定长协议?
定长协议是指协议头长度固定。协议头示意图如下。
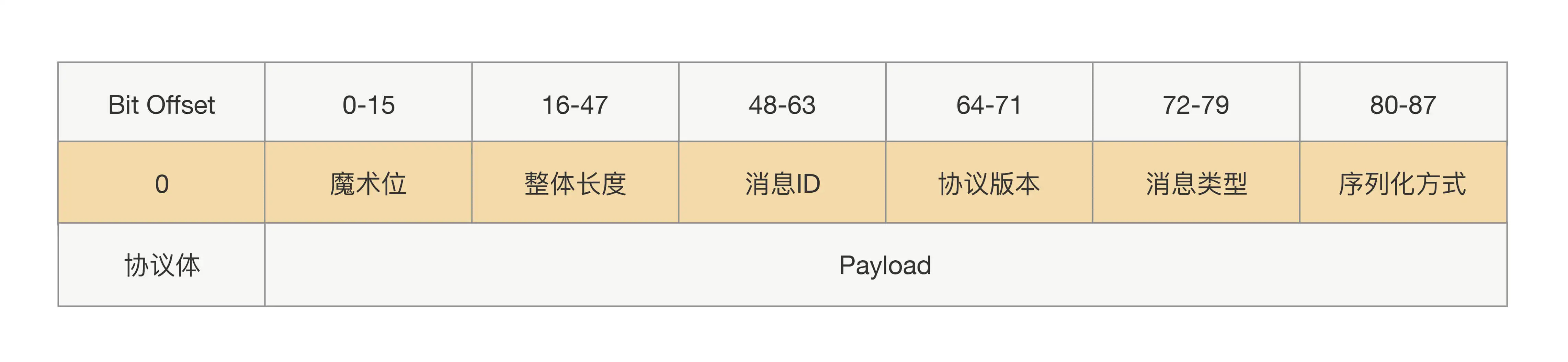
定长协议有什么缺点?
定长协议的协议头不能添加新参数,否则就会产生兼容性问题。例如我们设计了一个 88Bit 的协议头,其中协议长度占用32bit,然后为了加入新功能,在协议头里面加了2bit,并且放到协议头的最后。升级后的应用,会用新的协议发出请求,然而没有升级的应用收到的请求后,还是按照88bit 读取协议头,新加的2个bit会当作协议体前2个bit数据读出来,但原本的协议体最后2个bit会被丢弃了,这样就会导致协议体的数据是错的。
如何设计一个可扩展的协议?
我们需要让协议头支持可扩展,扩展后协议头的长度就不能定长了。这样整个协议变成了三部分:固定部分、协议头内容、协议体内容。
可扩展协议的示意图如下。
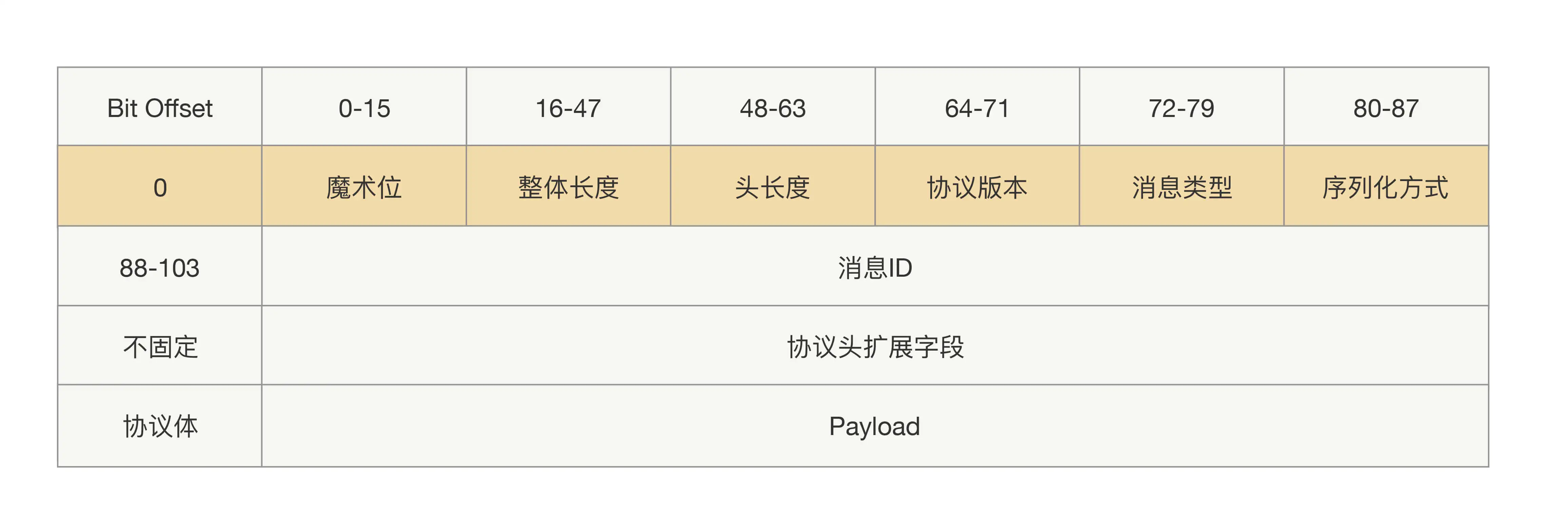
设计一个简单的RPC协议不难,难的地方在于怎么设计一个可“升级”的协议,不仅要让我们在扩展新特性的时候能够做到向下兼容,而且要尽可能地减少资源损耗。
协议头的具体内容是什么?
- Bit Offset:标识协议的起始位置。
- 魔术位:标识是什么协议。
- 整体长度:标识整个协议有多长,它减去头长度就是协议体长度
- 头长度:协议头的长度,因为协议头长度不固定,所以需要标识。
- 协议版本:标识协议的版本,主要用于兼容性控制。
- 消息类型:标识消息的类型,可能是文本、XML、JSON等。
- 序列化方式:标识用来做序列化和反序列化的方式。
- 消息ID:用于标识请求和响应的关系。
- 协议头扩展字段:用于扩展协议头,这样使得协议具有可扩展性,更加灵活。
- 协议体:协议的具体内容,二进制格式。
03 | 序列化:对象怎么在网络中传输?
什么是“序列化”和“反序列化”?
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是不能直接在网络中传输,所以我们需要提前把它转变成可传输的二进制,并且要求转换算法是可逆的,这个过程称为“序列化”。
根据请求类型和序列化类型,服务提供方将请求传来的二进制数据还原成请求对象,这个过程称为“反序列化”。
序列化就是将对象转换成二进制数据的过程,而反序列化就是把二进制数据转换成对象的过程。
有哪些常用的序列化方式?
- JDK原生序列化
- JSON
- Hessian
- Protobuf
- Protostuff
- Thrift
- Avro
任何一种序列化框架,核心思想就是设计一种序列化协议,将对象的类型、属性类型、属性值一一按照固定的格式写到二进制字节流中来完成序列化,再按照固定的格式一一读出对象的类型、属性类型、属性值,通过这些信息重新创建出一个对象,来完成反序列化。
JSON进行序列化存在哪些问题?
- JSON额外空间开销比较大,对于大数据量服务意味着巨大的内存和磁盘开销。
- JSON没有类型,但Java属于强类型语言,这需要通过反射来解决类型问题,所以会影响性能,这样就要求服务提供者和调用者之间传输的数据量要小。
Hessian有什么缺点?
Hessian不支持Java一些常见类型,例如:
- Linked系列
- Locale类
- Byte/Short在反序列化时会变成Integer
如何选择合适的序列化框架?
对于服务提供者来说,服务的可靠性要比性能更重要,因此,我们在选择序列化框架时,更关注协议在版本升级后的兼容性是否很好、是否支持更多的对象类型、是否跨平台、跨语言、是否有很多人已经用过并且踩过坑了,其次,我们才会考虑性能、效率和空间开销。
另外序列化协议的安全也是需要考虑的一个重要因素。
综合考虑,当我们选择序列化协议时,考虑因素如下所示:

RPC框架在使用序列化协议时有哪些注意事项?
- 对象要尽量简单,没有太多的依赖关系,属性不要太多,尽量高内聚。
- 入参对象与返回值对象体积不要太大,更不要传太大的集合。
- 尽量使用简单的、常用的、开发语言原生的对象,尤其是集合类。
- 对象不要有复杂的继承关系,最好不要有父子类的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号