Java并发编程实战(1)- 并发程序的bug源头
概述
并发编程一般属于编程进阶部分的知识,它会涉及到很多底层知识,包括操作系统。
编写正确的并发程序是一件很困难的事情,由并发导致的bug,有时很难排查或者重现,这需要我们理解并发的本质,深入分析Bug的源头。
并发程序问题的源头
为了提升系统性能,在过去几十年中,我们一直在不断的提升硬件的设计,包括CPU、内存以及I/O设备,但存在一个主要矛盾:三者之间速度有很大差异,CPU最快,内存其次,I/O设备最慢。
我们编写的程序,在运行过程中,上述三者都会使用到,在这种情况下,速度慢的内存和I/O设备就会成为瓶颈,为了解决这个问题,计算机体系结构、操作系统和编译程序做了如下改进:
- CPU增加了缓存,以均衡与内存的速度差异。
- 操作系统增加了进程、线程以及分时复用CPU,从而均衡CPU与I/O设备的速度差异。
- 编译程序优化指令执行次序,使得缓存能够得到更加合理的利用。
并发程序的问题根源也基本来源于上述改进:
- 缓存引发的可见性问题
- 线程切换引发的原子性问题
- 编译优化引发的有序性问题
接下来我们分别展开描述。
缓存引发的可见性问题
什么是可见性?
可见性是说一个线程对共享变量的修改,另外一个线程能够立刻看到。
可见性问题是由CPU缓存引起的,它是在CPU变为多核后才出现的,单核CPU并不会存在可见性问题。
我们可以参考下面的示意图。
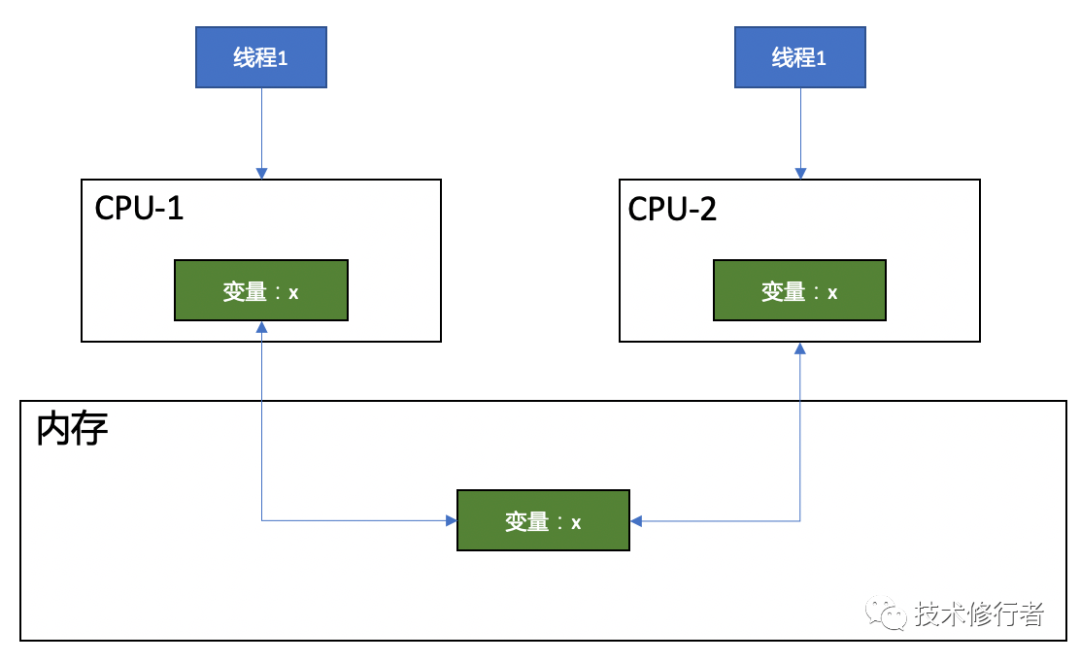
如图所示,当有2个线程同时访问内存中的变量x时,2个线程运行在不同的CPU上,每个CPU缓存都会保存变量x,线程运行时,会通过CPU缓存来操作x,那么当线程1进行操作后,线程2并不会立刻得到更新后的x,从而引发了问题。
我们来看下面的代码示例,它显示了对同一个变量使用多个线程进行加操作,最后判断变量值是否符合预期。
public class ConcurrencyAddDemo {
private long count = 0;
private void add() {
int index = 0;
while (index < 10000) {
count = count + 1;
index++;
}
}
private void reset() {
this.count = 0;
}
private void addTest() throws InterruptedException {
List<Thread> threads = new ArrayList<Thread>();
for (int i = 0; i < 6; i++) {
threads.add(new Thread(() -> {
this.add();
}));
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
threads.clear();
System.out.println(String.format("Count is %s", count));
}
public static void main(String[] args) throws InterruptedException {
ConcurrencyAddDemo demoObj = new ConcurrencyAddDemo();
for (int i = 0; i < 10; i++) {
demoObj.addTest();
demoObj.reset();
}
}
}
程序运行的结果如下。
Count is 18020
Count is 18857
Count is 16902
Count is 16295
Count is 54453
Count is 59475
Count is 56772
Count is 37376
Count is 60000
Count is 60000
我们可以看到,并不是每次返回的结果都是60000。
线程切换引发的原子性问题
什么是原子性?
一个或者多个操作在CPU执行的过程中不被中断的特性,被称为原子性。原子性可以保证操作执行的中间状态,对外是不可见的。
CPU可以保证的原子操作是在CPU指令级别的,并不是高级语言的操作符,而高级语言中的一个操作,可能会包含多个CPU指令。
以上述代码中的count = count + 1为例,它至少包含了三条CPU指令:
- 指令1:首先需要把变量count从内存加载到CPU寄存器。
- 指令2:在寄存器中执行+1操作。
- 指令3:将结果进行保存,这里可能会保存在CPU缓存,也可能保存在内存中。
上述指令执行过程中,可能会产生”线程切换“,如果多个线程同时执行相同的语句,那么因为线程切换,就会导致结果不是我们期望的。
原子性问题并不只在多核CPU中存在,在单核CPU中也是存在的。
编译优化引发的有序性问题
什么是有序性?
有序性是指程序按照代码的先后顺序执行。
编译器为了优化性能,有时候会改变程序中语句的先后顺序,一般情况下,这并不会影响程序的最终结果,但有时也会引发意想不到的问题。
我们以典型的单例模式为例进行说明,示例代码如下。
public class SingletonDemo {
private static SingletonDemo instance;
public static SingletonDemo getInstance() {
if (instance == null) {
synchronized(SingletonDemo.class) {
if (instance == null) {
instance = new SingletonDemo();
}
}
}
return instance;
}
}
一般情况下,假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null ,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
但是,如果我们仔细分析getInstance()方法中的new操作,会发现它包含以下几步:
- 分配一块内存M。
- 在内存M上初始化SingletonDemo对象。
- 将M的地址赋值给instance变量。
但编译器可能会做一些优化,变成下面的样子:
- 分配一块内存M。
- 将M的地址赋值给instance变量。
- 在内存M上初始化SingletonDemo对象。
这样很可能导致线程 B获取instance之后,在instance初始化没有完全结束的情况下,调用它的方法,从而引发空指针异常。
上述是我们常见的并发程序的bug源头,只要我们能够深刻理解可见性、原子性和有序性在并发场景下的原理,很多并发bug就很容易理解了。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号