

FoveaBox 笔记

2019 年 4 月放到 arxiv 上的(似乎投的是 ICCV2019,没有中?)然后又投了 ICLR2020,没有中,在 这里 可以看到 ICLR 的公开审稿意见,这篇笔记也是关于 ICLR2020 版本的(应该相差不大)。
这也是一篇 anchor-free 的文章,FoveaBox 不用 anchor,直接学类别和回归坐标。通过以下两点来实现:
- 对于存在物体的概率预测类别敏感的语义图
- 对于每一个位置生成与类别无关的 bbox
目标检测需要解决两个任务:识别和定位。给定一张图片,需要确定图片中是否含有给定类别范围的物体,如果有,还要返回物体的坐标。在之前,定位主要依靠滑动窗口法(sliding window)
深度学习可以自动从数据中学到特征表示,从 Faster RCNN 开始,两阶段的检测器通常使用 anchor-based RPN(region proposal network)来提取局部特征。简而言之,anchor 的目的在于将图片分成离散的盒子,然后在各自盒子中完成对 bbox 的精细调整。anchor 可以看成特征共享的滑动窗口法,其目的仍然是尽可能地去覆盖目标所有可能出现地位置。
但是,anchor 必须精心设计:
- anchor 覆盖的密集程度需要精心设计,为了达到尽可能高的召回,需要用到数据集的统计信息
- 对于一个数据集的设计并不总能应用到其他地方,影响泛化能力
- 在训练时,anchor-based 需要计算 IoU 来进行正负样本的定义,这一步骤耗时并且引入了超参。(讲道理我觉得 IoU 的计算时间没那么夸张吧)
而与之相对,我们人眼并不需要预先定义的形状模板就可以识别并完成定位。也就是说,人类根本不需要枚举候选框,所以很自然地想到 anchor 也许并不是必要的。
FoveaBox 的动机来源于人眼的 fovea:视觉域的中心有着最强烈的视觉敏锐度。

整体的结构我感觉和 FCOS 很像,也是基于 FPN,然后 detection head 由两个子网络构成:分类和定位

核心部分:
- 物体出现概率(Object Occurrence Possibility)
ground truth 定义为 分别表示左上角和右下角的坐标,首先将其映射到目标 feature level 上:
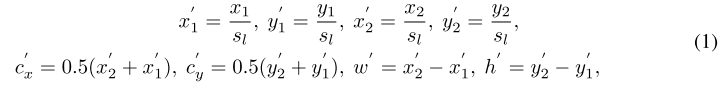
为 feature level 的 stride (FoveaBox 用的 FPN 的尺度为 8, 16, 32, 64, 128), 为中心点的坐标,然后定义正样本区域 :
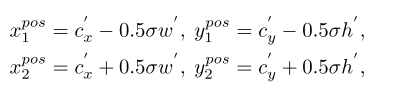
其中 是缩减因子,所以正样本区域就是 gt 映射到 feature level 之后形成框框的中间区域;而负样本区域就是剩下所有的区域。预测时每个 feature level 出来的 subnet 维度为 其中 是种类数, 是 feature map 的大小,每个 channel 表示该类别的概率。由于正样本区域相较于整个区域较小,因此使用了 Focal Loss。
- 尺度分配 (Scale Assignment)
目标是预测每个物体的坐标,但是直接回归是不稳定的,因为有的很大,有的很小。因此定义一系列的尺度范围,每个 feature level 都对应一个范围,每个 feature level 有一个基准 scale ,这个范围计算为:
是用来控制范围的, 对于 FPN 出来的 5 个 feature level 的取值为 32,64,128,256,512。
- bbox 预测
每个 gt 是 ,从 中的一个正样本点 出发,FoveaBox 直接计算 和 四个边界之间的归一化的偏移:
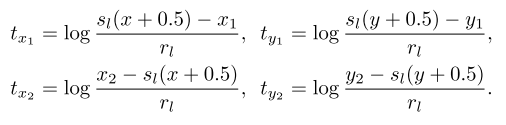
即首先将 映射回原图,然后计算归一化之后的偏移。
使用 Smooth L1 loss 进行计算。在 box subnet 中,每层 feature level 由 4 个 channel,分别回归
- 网络结构

- 实现
很常规,没什么需要很注意的
实验部分
- 消融实验
不同的 anchor 密度: 通常认为一个位置的 anchor 数量越多,效果越好,但是实验证明,超过 6-9 个时并不会带来更多的提升。

过于密集的 anchor 不仅会增加前景后景的优化难度,还会产生模糊的位置定义问题。每一个位置有 A 个 anchor,他们的分类目标通过其与 gt 之间的 IoU 来确定,同一个位置对应的 anchor 中,可能有些对应的是正样本,有些对应的是负样本,但是他们共享相同的输入特征,因此分类器不单单要分辨来自不同位置的样本,还要分辨来自相同位置的不同 anchor,这进一步加剧了训练难度。
作为对比,FoveaBox 在每个位置明确预测一个目标。和 anchor-based 相比,有以下好处:
- 输出空间降为了原来的 1/A
- 没有模糊的位置定义问题,优化目标也更加直接
- FoveaBox 有更少的参数,更加灵活
FoveaBox 对于框的分布更加鲁棒: 将 box 根据不同的长宽比进行分类查看效果,发现 FoveaBox 的效果更加鲁棒

生成高质量的 region proposals: 将分类目标改成类别无关的头是很直接的,并且可以生成 region proposal,FoveaBox 的效果更好。
IoU-based assignment vs. fovea area: 正负样本的定义不同造成的影响:
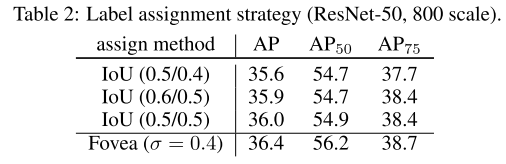
更好的检测头+特征对齐: RefineDet 和 RepPoints 都建议进行 feature alignment,所以论文中也用 deformable convolution 搞了一把,效果很好。

总体对比:

这个 feature alignment 的操作还是很有意思的,可以涨一个点。

简单总结:看完 FCOS 后再看这篇,就会发现两者的思想惊人的一致。而 FCOS 后来的 center sampling 的改进其实本质就是 FoveaBox 里面这种选取正样本的操作。
再看看 ICLR 的 review 意见吧,reject 的原因主要还是性能不足,我主观来看确实同期的 FCOS 做的更好一些(FCOS 还有一个 centerness 的分支),但是其实在 FCOS 没有加 center sampling 等一系列的改进之前,效果其实应该是差不多的(R50-FPN 大概在 37.1)

摘一些比较有启发性的 review:
The scale is still discretized. So that is essentially anchors in the scale space. I wonder how could the approach applies to scale to?

