

Faster RCNN 笔记

NIPS2015 的 paper,扩展版本投了 TPAMI
2015年时最先进的目标检测的网络依赖于 region proposal 算法来假设物体的位置,SPPnet 和 Fast RCNN 减少了这些网络的运行时间,展示了 计算 region proposal 是运行时间的瓶颈。本文提出了 Region Proposal Network (RPN) ,可以使整个图片的卷积特征和检测网络共享,实现了几乎没有时间消耗的 region proposal 。一个 RPN 是一个全卷积网络,它可以在每个位置同时预测物体的检测框以及 objectness scores。RPN 可以进行端到端的训练来生成高质量的 region proposal,随后可以用 Fast RCNN 来实现检测。通过一个简单的交替优化,RPN 和 Fast RCNN 可以在训练的时候共享卷积特征。在 VGG-16 模型上,我们的检测系统在一个 GPU 上可以达到 5fps,在 PASCAL VOC 2007 和 2012 上可以分别达到 73.2% 70.4% mAP,其中每张图片使用了 300 个 proposal。
目标检测因为 region proposal method 的发展(如 selective search)而发展,刚开始的时候 region-based CNNs 计算量很大,随着 SPPNet 和 Fast RCNN 的出现,由于在 proposal 之间贡献卷积特征,在不考虑生成 proposal 的情况下降低了运算量。现在 proposal 是计算的瓶颈。
region proposal 的方法典型依赖于低计算量的特征以及inference。Selective Search 根据设计的低层特征来贪心地聚合超像素。当时和高效的检测网络相比,SS 还是太慢了,CPU 上跑每张图需要 2 s。EdgeBoxes 提供了 proposal 的质量和速度之间的均衡,达到了 0.2s/img。但是 region proposal 仍然赵局了大部分的时间。
把提 proposal 的实现改成 GPU 也许可以缓解问题,但是这种工程上的做法忽略了一些可以共享计算量的可能性。
本文提供了一种算法角度的改进:用 deep cnn 来计算 proposal,这样得到的 proposal 需要的计算量很小。提出的即为 RPN (Region Proposal Networks) ,它共享了卷积层的特征,在测试时,计算 proposal 的时间非常小(10ms/img)
我们的观察是:Fast RCNN 中使用的卷积特征也可以用来生成 proposal,在这些卷积特征之上,我们通过添加一些额外的卷积层来构建一个 RPN,RPN 在一个整齐的格子的每个位置同时回归区域的边界和 objectness score,RPN 是一种全卷积网络,因此可以进行端到端的训练,尤其对于生成 proposal 的任务来说。
RPN 的设计目标是用宽范围的 scale 和 aspect ratio 来对 region proposal 进行高效地预测。与一些流行的方法(如 OverFeat,Fast RCNN. SPPNet)不同,他们有些使用图像金字塔(pyramids of images),或者滤波器金字塔(pyramid of filters),我们提出 anchor boxes 来作为多尺度和多宽高比的参考。我们的方法可以看作是回归参考金字塔(pyramid of regression references),这样避免了枚举多尺度多宽高比的图像或滤波器。当用单一尺度图像进行训练或测试时,效果很好,所以有利于运行时间。
为了把 RPN 和 Fast RCNN 结合在一起,我们提出了一种训练方法,可以在训练 region proposal 和 object detection 之间交替进行。
相关工作:
- object proposal
提 proposal 方法的文章有很多,略
- deep networks for object detection
RCNN 通过对 CNN 进行端到端的训练来把 proposal 分为物体类别或背景。RCNN 主要的作用是分类器,他不能够预测物体的边界(除了通过 bbox regression 去 refining)他的准确率取决于 region proposal 模块的质量。有很多文章提出了使用深度网络来预测物体 bbox 的方法,比如 OverFeat, 
在 OverFeat 中,它训练了一个全连接层来预测物体的坐标(做的 localization task,其中只有一个物体),全连接层然后变成了一个卷积网络来检测多个类别的物体。MultiBox [26,27] 从一个网络生成 region proposal,该网络的最后一个全连接层同时预测多个类别无关的 box,泛化了 OverFeat 的 “single-box” 的模式。这些类别无关的 box 然后被用作 RCNN 的 proposal,MultiBox proposal network 可以用在单一图像或者多个大的 image crop 上。MultiBox 在 proposal 和 detection network 之间并不共享特征。DeepMask 的目的则是学习 segmentation proposals
共享卷积的计算逐渐吸引了很多的注意力。OverFeat 从一个 image pyramid 计算卷积特征来进行分类,定位和检测。在 SPPNet 设计了 Adaptively-sized pooling 来进行更加高效的基于区域的检测。Fast RCNN 在共享的卷积特征上使用了端到端的 detector 的训练,准确率和速度都很好~
Faster RCNN
Faster RCNN 包含两个模块,第一个模块是一个深度全卷积网络,用来提 proposal,第二个模块是 Fast RCNN 检测器,使用这些 proposal 来预测结果,整个系统是一个统一的目标检测的框架。使用最近流行的 “attention” 机制的叫法,RPN 告诉 Fast RCNN 去看哪里。

Region Proposal Networks
RPN 的输入是一个任意大小的图片,输出是一系列的矩形 proposal ,每个 proposal 有一个 objectness score,我们用一个全卷积网络来对这个过程进行建模。因为我们最终的目标是和 Fast RCNN 目标检测网络共享计算,我们假设两个网络都都共享一系列相同的卷积层。在我们的实验中,我们使用 ZF 模型,有 5 个共享的卷积层,还有 VGG-16,有 13 个共享的卷积层。
为了生成 region proposal,我们用一个小的网络在最后一层特征图上进行滑窗。这个小网络的输入是 的卷积特征图,每个滑动窗口被映射到一个较低维度的特征上去(ZF 是 256-d,VGG 是 512-d),该特征再喂到两个全连接层分支:box-regression layer 和 box-classification layer,本文 ,映射到原图得到的有效的感受野是比较大的(分别对于 ZF 和 VGG 是 171,228 ),注意到因为这个小网络用的是滑动窗口法,全连接层是被所有的空间位置所共享的。这个框架可以通过 卷积,后面跟两个 卷积层来实现(分别用在 reg 和 cls 分支)

Anchors
在滑动窗口的每个位置上,我们同时预测多个 region proposal,每个位置最多有的可能的 proposal 的数量是 ,所以 reg 分支的输出为 ,表示 个框的四个坐标,cls 输出 个数,表示每个框对应的有物体和没有物体的概率(此处使用的是 two-class softmax layer,也可以使用 logistic regression)。这 个 proposal 的参数是 个 reference box ,我们称之为 anchor,anchor 的中心在滑动窗口的位置,并且有一个对应的 scale 和 aspect ratio,默认使用 3 个 scale 和 3 个 aspect ratio,在每个滑动窗口的位置总共 9 个 anchor,对于一个大小为 WxH 的卷积层来说,总共有 kWH 个 anchor
Translation-Invariant Anchors 具有平移不变性的 anchor
我们的方法的一个重要的性质是它具有平移不变性,anchor 具有这个性质,用于计算从 anchor 到 proposal 的函数也具有平移不变性。而对于 MultiBox 来说,它用 k-means 来生成 800 个 anchor,是不具备平移不变性的,因此 MultiBox 不能保证假如一个物体发生了平移,仍然能够产生相同的 proposal
这个性质还减少了模型的大小。MultiBox 有 (4+1)x800 维度的全连接输出层,而我们的方法在 的情况下有 (4+2)x9 维的卷积输出层。因此我们的输出层有 个参数(使用 VGG-16:),而 MultiBox 有 个参数(使用 GoogleNet:)。如果考虑特征映射层,我们的 proposal layer 仍然比 MultiBox 的参数要少。
Multi-Scale Anchor as Regression Reference (作为回归参照物的多尺度 anchor)
我们对 anchor 的设计表现了解决多尺度问题的一个新颖方法,如图 1 中所示,有两种用来多尺度检测的常用方法:
- 根据 image/feature pyramids: 比如在 DPM 以及 OverFeat,SPPNet,Fast RCNN 中出现。图像被缩放成多个尺度,以及在多个 sclae 上计算出来的 feature map 。这种方法很有用,但是太耗时了。
- 在 feature map 上使用不同尺度的 sliding window:比如在 DPM 中,不同宽高比的模型是用不同大小的 filter 单独进行训练的。如果这种方法被用来解决多尺度问题,那么可以称其为 pyramid of filters,这一种方法通常和第一种方法结合起来一块用。
作为比较,我们基于 anchor 的方式是建立在 a pyramid of anchors 的基础之上,效率更高。我们的方法以不同尺度和宽高比的 anchor 作为基准参照来对 bbox 进行分类和回归。它只使用了单一尺度的图像和特征图,并且也只是用了单一大小的 filter(其实就是卷积核大小)我们通过实验来证明这种方法来解决多尺度问题的有效性。
因为这些基于 anchor 的多尺度的设计,我们可以简单地使用在单一尺度图像上计算得到的卷积特征。多尺度的 anchor 是高效共享特征的关键方法。
Loss Function (损失函数)
在训练 RPN 时,我们对每个 anchor 赋一个二元类别标签(是否为物体的标签),我们把两种类型的 anchor 定义为正样本:
- 和一个 ground truth 有最高 IoU 的 anchor
- 一个 anchor 和任意一个 ground truth 有大于 0.7 的 IoU
注意到一个 ground truth 可能赋给多个 anchor 正样本。通常来讲,第二个条件就已经充分确定正样本,但是我们还是使用了第一个条件,是因为在一些极端情况下仅仅第二个条件可能找不到正样本。假如一个 anchor 和所有的 ground truth 之间的 IoU 值都小于 0.3,则给这个 anchor 打上负样本的标签,既不是正样本也不是负样本的 anchor 不参与训练。
有了这些定义之后,我们可以使 multi-task loss 最小化,定义为:

其中 是 anchor 的 index, 是预测 anchor 有物体的概率,假如 anchor 是正样本,ground truth label 是 1,否则为 0, 是一个四维向量,表示预测出的 bbox 的含参坐标, 是正样本 anchor 的 ground truth box,分类的 loss 是两个类别(有物体/无物体)之间的对数损失,对于回归损失,我们使用 ,其中 是 smooth L1 loss (在 Fast RCNN 中定义), 表示只对正样本()有回归损失,否则不算入回归损失。cls 和 reg 层分别输出 和 。
这两项通过 和 来进行归一化,又添加了一个平衡因子 ,在我们现在的实现中,对于 cls 分支,用的是 mini-batch 的大小进行的归一化(),对于 reg 分支,使用的是 anchor location 的数量() ,默认设置 ,这样的话 cls 和 reg 之间大概的 loss 值是等权重的,我们通过实验证明在 取得一个相当大的范围内,结果对其是不敏感的,我们还指出上述的归一化并不是必要的,可以进行简化。
对于 bounding box regression,我们采用了将四个坐标参数化的方法,具体操作如下:
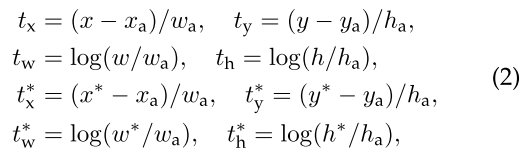
其中 表示 box 的中心坐标和宽高,变量 分别表示预测的 box ,anchor box,ground truth box 的中心 坐标,其他变量同理。这样可以认为是从 anchor box 回归到一个附近的 ground truth box
尽管如此,我们的方法用跟之前不同的方法来进行 bounding box regression,在 SPPNet 和 Fast RCNN 中,bounding box regression 在任意大小的 RoI 对应的特征上进行,回归的权值在所有区域的大小上都进行共享,在我们的构造中,用于回归的特征和特征图上的空间大小()是相同的。为了考虑变化的尺寸,学习了 个 bbox 的回归器。每个回归器考虑一种尺度和宽高比,这 个回归器不共享权值。尽管如此,还是能够预测出不同尺度的物体,即使特征是固定大小和尺度的,这多亏了 anchor 的设计。
训练 RPN
可以通过反向传播算法以及 SGD 来训练。我们使用 “image-centric” 的采样策略来训练这个网络,每个 mini-batch 包含一个图片产生的正负样本 anchor 。优化所有 anchor 的 loss 函数是有可能的,但是这样会更加偏向于负样本,因为负样本占了大部分。我们随机从一个图片中采样 256 个 anchor 来计算这一个 mini-batch 的 loss,采样得到的正负样本的比例为 ,假如说在一张图片中少于 128 个正样本,那么我们用负样本来补充。
我们用零均值 0.01 标准差的高斯分布对所有的新层进行初始化。所有其他的层初始化为 ImageNet pretrain 的权值。我们使用 0.001 的学习率,60k 个 mini-batch 后改用 0.0001 的学习率再训练 20k,使用 momentum=0.9,weight decay = 0.0005
Sharing Features for RPN and Fast RCNN 在 RPN 和 Fast RCNN 之间共享特征
现在我们已经描述了如何为生成 region proposal 来进行训练,此时并没有考虑将要使用这些 proposal 的 region based detector,对于 detection network,我们使用了 Fast RCNN,然后我们描述如何训练一个共享卷积层权值的统一的 RPN 和 Fast RCNN 的框架。
RPN 和 Fast RCNN 在单独训练时会通过不同的方式改变他们的卷积层,因此需要让这两个网络能够共享卷积层,而不是分别学两个网络,我们讨论了三种方法可以在特征共享的情况下进行训练:
- Alternating training:交替训练。在这种方法中,我们首先训练 RPN,然后用 proposal 训练 Fast RCNN,Fast RCNN 微调后的网络再作为 RPN 的初始化,然后这些步骤迭代进行,这是这篇 paper 使用的方法
- Approximate joint training:近似的联合训练,在这种方法中,RPN 和 Fast RCNN 合并到了一个网络中,见图 2 .在每个 SGD 迭代中,前向传播生成的 proposal 就看成喂给 Fast RCNN detector 的 proposal,反向传播没什么特别的,对于共享的层,要合并 RPN 的 loss 和 Fast RCNN 的 loss,这种方法很容易实现,但是它忽略了关于 proposal boxes’ coordinates 的导数,所以是近似的,在我们的实验中,我们发现这个方法的结果很接近 alternating training,并且减少了 25-50% 的训练时间。
- Non-approximate joint training:正如之前讨论的那样,由 RPN 预测出来的 bbox 也是输入的函数,Fast RCNN 中的 RoI pooling layer 接受卷积特征和预测的 bbox 作为输入,所以一个理论上可行的反向传播求解方法应当包含对于 box coordinates 的导数,这一部分的梯度在上述的 approximate joint training 中是忽略了的,在 non-approximate joint training 中,我们需要一个可以对 box coordinate 求微分的 RoI pooling layer,这是一个非平凡的问题,解决方案可以通过 RoI warping layer 来解决,见 [15]:
4-Step Alternating Training
在本文中,我们采用实用的四步训练法通过交替优化来学习共享特征,第一步,我们训练 RPN,网络初始化为 ImageNet pretraining 的权值;第二步,用第一步产生的 proposal 来训练 Fast RCNN,detection network 的权值也是 ImageNet pretraining 初始化的,此时这两个网络还没有共享权值;第三步,我们使用 detector network 来初始化 RPN 但是我们固定共享卷积层的权重,只微调 RPN 独有的层,现在两个网络已经共享了卷积层;最后,保持共享的卷积层参数不变,我们微调 Fast R-CNN 独有的层,这样,两个网络都共享了相同的卷积层,形成了一个统一的网络。相似的交替训练可以进行多个迭代过程,但是只观察到了可以忽略的一点点改进。
实现细节
我们只在单一尺度图像上训练并测试 region proposal 和 object detection networks,我们改变图像的尺度,使得他们的短边为 600,使用 image pyramid 进行多尺度的特征提取可能会改进准确率,但是并不是一个很好的 speed-accuracy trade-off,在一个 re-scale 的图像上,ZF 和 VGG 在最后一个卷积层上的 total stride 是 16,因此在 PASCAL image 中,resize 之前大概是 10 pixel,即使这样大的 stride 有一个很好的结果,尽管 stride 小一点可以改进结果。
对于 anchor,我们使用 3 个尺度的 anchor,每个大小是 ,3 个 aspect ratios 分别为 ,这些超参数并不是为单独一个数据集精心选择的,我们的结果不需要 image pyramid 和 filter pyramid 来预测多个尺度的 region,节省了大量的时间,图 3 右显示了我们我们的方法可以处理很大范围的 scale 和 aspect ratio,表 1 显示了用 ZFnet 学到的每一个 anchor 的平均的 proposal 的大小,我们注意到我们的算法允许预测出比潜在的感受野更大的 bbox。这样的预测并不是不可能的,只看一个物体的中间部分也可能大概推断处一个物体的范围。

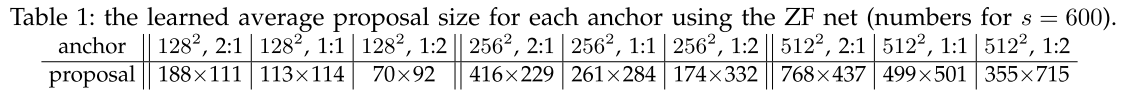
越过图像边界的 anchor 需要细心处理,在训练的时候,我们忽略所有跨越边界的 anchor,因此他们对 loss 不做贡献,对于一个典型的 的图像,大概一共会有 个 anchor ,不考虑跨越边界的 anchor 的话,大概每张图只有 6000 个 anchor,假如说在训练时不忽略跨越边界的 anchor 的话,他们会在目标函数中引入很大的、难以修正的误差项,最终训练无法收敛。在测试时,我们仍然在整张图上使用全卷积 RPN,这样可能会生成跨越边界的 proposal,随后这些 proposal 会 clip 到图像的边缘。
一些 RPN 的 proposal 互相之间会有很高的重叠,为了减少冗余,我们在 proposal 上根据他们的 cls scores 使用了非极大值抑制(non-maximum suppression, NMS),其中 IoU threshold 为 0.7,这样的话每张图大概只剩 2000 个 proposal,我们会展示,NMS 不会损害最终的检测准确率,但是会大量减少 proposal 的数量。在 NMS 之后,我们使用 top-N 的 proposal 来进行检测,接下来,我们使用 2000 个 RPN proposal 来训练 Fast RCNN,但是在测试时对不同数量的 proposal 进行评估。
实验
PASCAL VOC 上的实验
在 PASCAL VOC 2007 上进行实验,包含 5k trainval 和 5k test ,总共有 20 个物体类别,对于 ImageNet pretrained model,我们使用了 fast version of ZFnet ,有 5 个卷积层和 3 个全连接层,以及 VGG-16,有 13 个卷积层和 3 个全连接层,我们主要评估 mAP(而不是 object proposal proxy metrics)
表 2 top 显示了使用不同的 region proposal methods 得到的 Fast RCNN 的结果,这些结果使用的 ZFnet,对于 Selective Search 来讲,我们通过 fast mode 生成大约 2000 个 proposal,对于 EdgeBoxes,我们用默认的 EdgeBoxes 的设置,IoU=0.7。SS 的 mAP=58.7,EB 的 mAP=58.6。而 RPN with Fast RCNN 得到的结果是 59.9,而只是用了 300 个 proposal,使用 RPN 的速度要比 SS 和 EB 快得多,因为共享了卷积计算,更少的 proposal 也减少了 region-wise fully-connected layers’ cost
RPN 上的消融实验
为了研究 RPN 的性质,我们进行了许多消融实验。首先,我们展示了在 RPN 和 Fast RCNN 之间共享卷积层的影响,首先我们停止四步训练过程中的第二步,使用单独的网络会使性能降低到 58.7,原因是在第三步假如用 detector-tuned 特征去 fine-tune RPN 的话,proposal 的质量会提高。
下一步,我们将 RPN 对 Fast RCNN 训练的影响分开,我们用 2000 个 SS proposal 来训练 Fast RCNN,我们固定这个 detector 然后通过改变测试时使用的 proposal region 来评估检测的 AP,在这个实验中,RPN 不和 detector 共享特征。
在测试时用 300 个 RPN 的 proposal 来代替 SS 会给出 56.8 的 mAP,mAP 的降低是因为训练和测试 proposal 之间的不一致,这个结果作为以下比较的 baseline
令人惊讶的是,当在测试时使用 100 个 proposal 时, RPN 仍然有很好的表现(55.1),这意味着 top-ranked RPN proposal 是准确的,在另外一个极端,使用 top-ranked 6000 RPN proposal (不用 NMS)的结果是 55.2,意味着 NMS 不会降低检测 AP,并且能够减少 false alarm (虚警或 false positive)
下一步,我们分别研究 RPN 的 cls 和 reg 的输出所扮演的角色,通过在测试时依次关掉他们来进行观察。当 cls 层在测试时被去掉时(因此没有用 NMS/ranking),我们从没有分数的区域随机采样 个 proposal。当 时,mAP(55.8%) 几乎没有改变,但是当 时,mAP 只有 44.6,因此 cls scores 可以保证高 rank proposal 的准确率
另一个角度来说,在测试时去掉 reg 层(此时 proposal 为 anchor box),mAP 降到了 52.1 ,这意味着高质量的 proposal 是由 regression branch 生成的。即使原始的 anchor box 具有不同的 scale 和 aspect ratio,也并不足以得到准确的检测结果。
我们还在更强的 backbone 上测试了 RPN 的效果,我们在 VGG-16 上训练了 RPN,仍然使用上述 SS+ZF 的检测器,mAP 从 56.8 提高到了 59.2,这意味着 RPN+VGG 生成的 proposal 要比 RPN+ZF 生成的 proposal 要好,因为 RPN+ZF 的 proposal 和 SS 的质量差不多(都是 58.7),因此可以猜测 RPN+VGG 的效果是要比 SS 好的,以下实验证明了这一假设
表 3 展示了使用 VGG-16 的结果,使用 RPN+VGG,不共享特征时的结果时 68.5,比 SS 稍微高一点,这是因为 RPN+VGG 生成的 proposal 比 SS 更加准确,不像 SS 是提前定义好的,RPN 是主动训练得到的并且能够从更好的 backbone 中受益。对于共享特征的变种,结果是 69.9 ,比 SS 要好很多,并且 proposal 的计算量也很小。我们进一步在 PASCAL VOC 2007+2012 上进行了训练,mAP=73.2,图 5 展示了 PASCAL VOC 2007 测试集上的结果,达到了 70.4,更多的结果见表 6,7



表 5 中总结了整个目标检测系统的运行时间,SS 大概要用 1-2s ,Fast RCNN with VGG-16 要 320ms(用 2000 SS proposal),我们的用上 VGG-16 总共需要 198ms,同时完成了 proposal 和 检测。共享了卷积特征后,RPN 单独只消耗 10ms,我们 region-wise computation 比较慢,但是因为使用的 proposal 比较少(每张图 300 个),因此用 ZFnet 时我们可以达到 17fps
超参数的敏感性
表 8 展示了不同 anchor 的情况,默认我们 3 个尺度和 3 个宽高比(69.9),假如每个位置只用一个 anchor 的话,mAP 会将 3-4,使用 3x1 或 1x3 的话效果也差不多,说明使用不同大小的 anchor 作为回归的 reference 是有效的做法。

表 9 我们比较了 取不同值的影响。默认取 来使两个 loss 差不多等权重,Table 9 shows that our result is impacted just marginally (by ~ 1%) when is within a scale of about two orders of magnitude (1 to 100). This demonstrates that the result is insensitive to in a wide range.
分析 Recall-to-IoU:下一步我们计算和 gt 不同的 IoU 下的 proposal 的 recall。值得注意的是,Recall-to-IoU 只是很弱地和最终检测准确率有关,更适合用这个指标来诊断 proposal 的方法而不是评估它[19,20,21]。

在图 4 中,我们展示了使用 300,1000,2000 个 proposal 对应的结果。可以看到 2000 到 300 时 RPN 的结构变化不大,这解释了为什么 RPN 只需要 300 个 proposal 就能够达到很好的效果。而在 proposal 较少时, SS 和 EB 的 recall 降得比 RPN 快多了。

One-stage Detection vs. Two-stage Proposal+Detection
OverFeat 提出了在卷积特征图上使用回归器和分类器来进行检测,它是一个 one-stage, class-specific 的检测流程,而我们的是 two-stage cascade 包含类别无关的 proposal 和 类别相关的 detection。在 OverFeat 中,region-wise feature 来源于在一个 scale pyramid 上进行的滑动窗口。这些特征被用来同时确定物体的位置和类别。在 RPN 中,特征来源于 的滑动窗口,然后根据不同尺度、宽高的 anchor 来预测 proposal。尽管两种方法都用了滑动窗口法,region proposal task 只是 Faster RCNN 的第一个阶段,随后的 Fast RCNN 接收这些 proposal 然后 refine 他们,在我们级联的第二个阶段,region-wise feature are adaptively pooled from proposal boxes that moew faithfully cover the features of the regions. 我们认为这些特征能够得到更加准确的检测结果。
为了比较 one-stage 和 two-stage,我们通过 one-stage 的 Fast RCNN 模拟了 OverFeat 系统(所以消除了实现细节之间的差异)。在系统中,“proposal” 是密集的滑动窗口,有 3 个尺度(128,256,512) 和 3 个宽高比(1:1,1:2,2:1),Fast RCNN 从这些滑动窗口来预测类别相关的分数以及回归框的位置。因为 OverFeat 使用了 image pyramid,我们也用 5 个尺度提出来的卷积特征进行评估。
表 10 比较了 two-stage 的系统以及 one-stage 系统的两个变种,使用 ZFnet,one-stage 系统的 mAP=53.9,比双阶段系统 58.7 低 4.8。这个实验验证了级联 region proposal 的有效性。在 Fast RCNN 和 RCNN minus R 中有着相似的观测,他们将 SS 换成滑动窗口的 region proposal,结果降低了大约 6 。仍需要注意的是,one-stage 系统要更慢,因为它处理了大量的 proposal。
MSCOCO 上的实验
COCO 有 80 个类别,我们的系统对于这个数据集有一些小改动。我们的模型在 8 张 GPU 上进行训练,对于 RPN 来说,有效的 mini-batch 的大小是 8 (1/img),对于 Fast RCNN 来说有效的 batch-size=16 (2/img)两个都是以 0.003 的学习率训练了 240k 个迭代,然后以 0.0003 的学习率训练了 80k 个迭代。我们把学习率从 0.001 改到了 0.003 ,因为 batch-size 的大小发生了变化,对于 anchor,我们使用了 3 种宽高比和 4 个尺度(加上了 ),目的是解决数据集中较小的样本。另外,在我们的 Fast RCNN 的步骤中,negative sample 的定义为 IoU 范围在 而不是 SPPNet 和 Fast RCNN 原来用的 。我们注意到在 SPPNet 中, 的负样本用来进行网络微调, 的负样本在 SVM step with hard-negative mining 中仍然使用。但是 Fast RCNN 去掉了 SVM 的步骤,因此 内的负样本永远都没有用到过。用上这些负样本对 COCO 的 mAP@0.5 是有帮助的(对于 Fast RCNN 和 Faster RCNN 都是有帮助的),但是在 PASCAL VOC 上的帮助不大。
剩下的实现细节和 PSACAL VOC 是一样的,也就是说,我们仍然使用了 300 个 proposal,并在单一尺度()上进行测试。在 COCO 数据集上,测试的时间仍然是 200ms/img。
在表 11 中我们首先报告了 Fast RCNN 的结果。我们 Fast RCNN baseline 在 test-dev 上有 39.3 的 mAP@0.5,比原论文中要高,我们猜测其原因是负样本的定义以及 mini-batch size 的变化,而 mAP@[.5,.95] 和原论文相比差不多。

然后我们评估我们的 Faster RCNN 系统,使用 COCO training set 来进行训练,Faster RCNN 有 42.1 的 mAP@0.5 和 21.5 的 mAP@[.5,.95] 。比 Fast RCNN 高了 2.8, 2.2。


