每周一坑-公司网络访问不了个别网站及elk写不进数据
我当时挺绝望的,前台妹子说要发新闻,我说如果急着用而我又没找到问题原因的时候,可以用远程桌面连过去用着先。中午尝试终极大法:主路由器重启。好不容易熬到中午大家都去吃饭,我留了一会,先尝试主路由器的软重启(页面点击重启),再尝试主路由器的硬重启(拔电源),不行!!!想着吃完饭再回来搞,时间充足点,头脑也清醒点。回来再尝试重启电源,光猫也重启,不行。
直到我去主路由器发现一个非常重要的线索:流量统计页面里,两个wan口的流量接收差别巨大:当时WAN2的接收总字节,只有30M左右,而WAN1,差不多有2G。
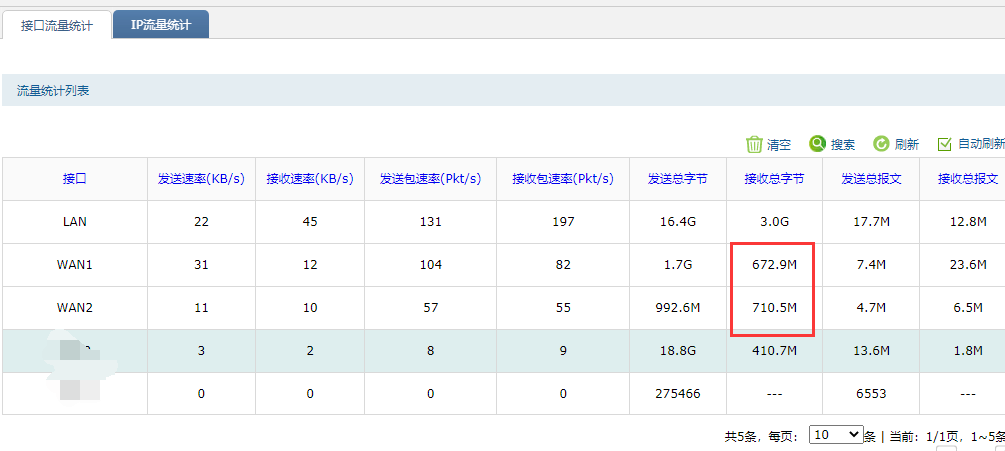
再回想下为什么虚拟机的windows能打开网站,而办公电脑不行,是恰好虚拟机从WAN2出去的,办公电脑从WAN1出去,这就解释了为什么两个网站打不开(加载的文件图片奇多),而一个网站虽然能打开,但清单内容不能完全加载出来(比另外两个网站文件少点)。
最后的解决方法:把WAN2的IP强制断开,重连,直到更新得到一个新的IP,问题即解决(不更新ip是无法解决的!)
map $http_x_forwarded_for $real_remote_addr { "" $remote_addr; ~^(?P<firstAddr>[0-9\.]+),?.*$ $firstAddr; } log_format test '{"@timestamp":"$time_iso8601",' '"host":"$hostname",' '"server_ip":"$server_addr",' '"client_ip":"$remote_addr",' '"xff":"$http_x_forwarded_for",' '"real_remote_addr":"$real_remote_addr",' '"domain":"$host",' '"url":"$uri",' '"referer":"$http_referer",' '"upstreamtime":"$upstream_response_time",' '"responsetime":"$request_time",' '"status":"$status",' '"size":"$body_bytes_sent",' '"protocol":"$server_protocol",' '"upstreamhost":"$upstream_addr",' '"file_dir":"$request_filename",' '"http_user_agent":"$http_user_agent"' '}';
logstash配置文件如下(直接抄线上的,改了es地址而已):


1 input { 2 beats { 3 port => 4555 4 client_inactivity_timeout => 600 5 } 6 } 7 8 filter { 9 # 为了兼容中文路径,这里做了下数据替换 10 mutate { 11 gsub => ["message", "\\x", "\\\x"] 12 gsub => ["message", ":-,", ":0,"] 13 } 14 json { 15 # 从数据中取出message 16 source => "message" 17 # 删除多余字段 18 remove_field => "message" 19 remove_field => "[beat][hostname]" 20 remove_field => "[beat][name]" 21 remove_field => "[beat][version]" 22 remove_field => "@version" 23 remove_field => "offset" 24 remove_field => "input_type" 25 remove_field => "tags" 26 remove_field => "type" 27 remove_field => "host" 28 } 29 30 mutate { 31 convert => ["status", "integer"] 32 convert => ["size","integer"] 33 convert => ["upstreamtime", "float"] 34 convert => ["responsetime", "float"] 35 } 36 37 geoip { 38 target => "geoip" 39 source => "real_remote_addr" 40 database => "/home/elk/elk5.2/logstash-5.2.1/config/GeoLite2-City.mmdb" 41 42 add_field => [ "[geoip][location]", "%{[geoip][longitude]}" ] 43 add_field => [ "[geoip][location]", "%{[geoip][latitude]}" ] 44 45 # 去掉显示 geoip 显示的多余信息 46 remove_field => ["[geoip][latitude]", "[geoip][longitude]", "[geoip][country_code]", "[geoip][country_code2]", "[geoip][c 47 ountry_code3]", "[geoip][timezone]", "[geoip][continent_code]", "[geoip][region_code]"] 48 } 49 50 mutate { 51 convert => [ "size", "integer" ] 52 convert => [ "status", "integer" ] 53 convert => [ "responsetime", "float" ] 54 convert => [ "upstreamtime", "float" ] 55 convert => [ "[geoip][location]", "float" ] 56 57 # 过滤 filebeat 没用的字段,这里过滤的字段要考虑好输出到es的,否则过滤了就没法做判断 58 remove_field => [ "ecs","agent","host","cloud","@version","input","logs_type" ] 59 } 60 61 if "_geoip_lookup_failure" in [tags] { drop { } } 62 useragent { 63 source => "http_user_agent" 64 target => "ua" 65 remove_field => [ "[ua][minor]","[ua][major]","[ua][build]","[ua][patch]","[ua][os_minor]","[ua][os_major]" ] 66 } 67 } 68 output { 69 #stdout { codec=> rubydebug } 70 elasticsearch { 71 hosts => ["es的ip:es的端口"] 72 index => "logstash-test" 73 } 74 }
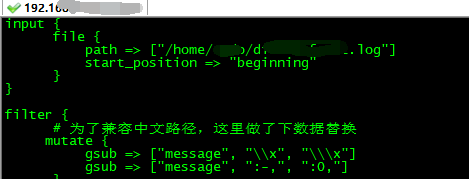
记得以前直接读系统的/var/log/secure是行的,于是我改成文本方式读本机secure文件,刷刷刷的日志在屏幕打印出来了。
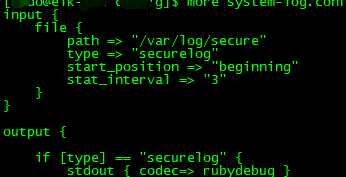
会不会是本地这个ELK有问题,于是在线上用别人的elk测了,非常成功!!!!
突然想到既然没有报错,那应该是写入的日志问题。再分析下线上和线下两个日志的不同点。real_remote_addr这个内置变量,借助logstash配置文件中的GeoLite2-City.mmdb库,用来分析访问来源地,而公司内网的ip,我模拟打开网站的时候,用的是公司局域网ip(192.168.0.x)这种,logstash配置文件中的GeoLite2-City.mmdb库压根不能辨别局域网ip的来源地,所以不能成功写入到es上,也确实就是这个原因!!!!
我把公司局域网部署的应用从内网访问,借助反向代理映射到公网访问,这样nginx日志记录的真实客户端ip就是我公司路由器出口ip,而不再是192.168.0.x,这样这个ip地址库能分析来源地,能写入到es的索引里。
不能写入:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号