py报表脚本放到win7定时任务的各种坑
py报表脚本放到win7定时任务的各种坑
2021-04-25----22:18:49
一、前言背景
上一篇写到,因为我考虑问题不够周全,导致win7虚拟机中毒不得不恢复快照,然后各种修修补补,终于手动把报表脚本调好了。当我放到定时任务上,发现它并不按预期发展,出现各种各样的问题。大致交代下这个py脚本实现的需求:从别人的系统查询并导出报表,下载到本地环境,再导入到我们的系统。这个脚本实质是模拟人为登录,各种点击,页面切换,到最终报表导出导入。
二、遇到的问题
1、下载报表需要人为干预
(1)问题现象:
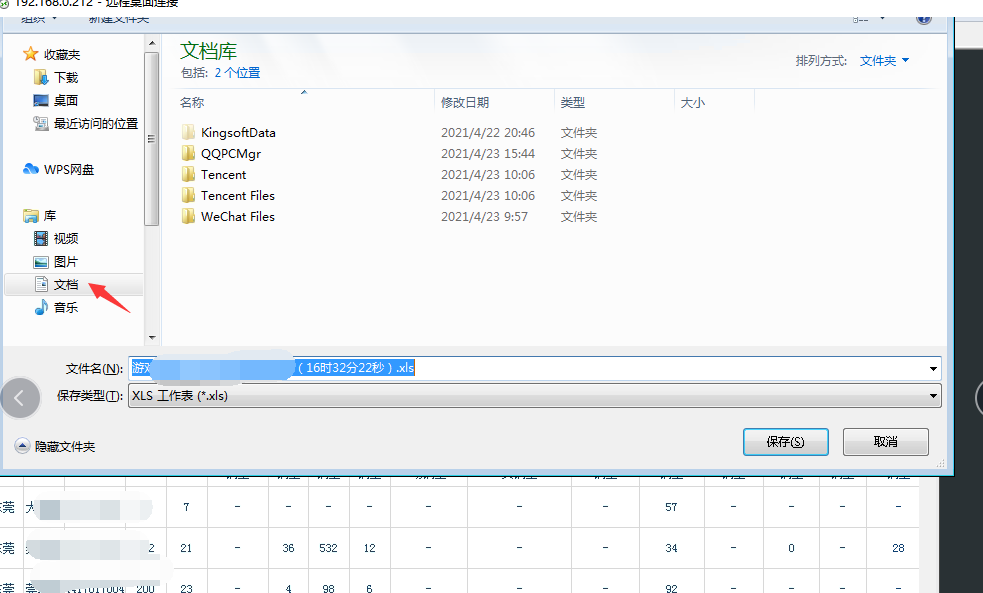
(2)排查过程:
放到定时任务本质上就是解放人的工作,如果还要人为确认点击“保存”就违背了自动化的理念了。当时我以为是因为安全中心给的查杀工具,修复之后重置了电脑文件导致的(公司的一个开发给我这样说,我还真以为是工具的锅),所以今天上班第一件事就是恢复2018年光秃秃的快照,只部署了报表脚本依赖的环境(python+chrome浏览器+chrome驱动),这种现象还有。
测试过,定时任务调脚本的运行路径是( 用函数 os.getcwd ):C:\Windows\system32
网上有说,python selenium爬虫下载文件的时候,如果用chrome浏览器点击下载,文件会自动存放到默认文件夹,但是谷歌浏览器设置的下载地址是:C:\Users\用户\Downloads。所以感觉这个说法不太靠谱。
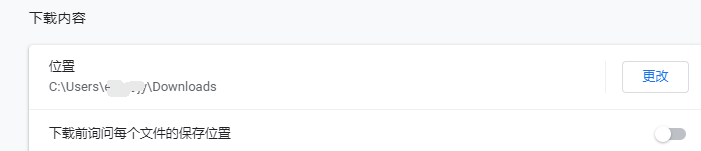
另外,system32 这个路径暂时未知是从哪里蹦出来的,可能是系统默认运行路径。
(3)问题解决:
我在E盘单独开了一个目录用来存放报表:E:\table。然后在启动driver的时候,添加参数(保存在prefs变量上)来设置谷歌浏览器自动保存文件。参考链接:
https://blog.csdn.net/zhouxuan623/article/details/91860189
def browser_page(): path_get = os.getcwd() # path_get = 'E:\\table' print("当前路径: %s" % path_get) time.sleep(3) options = webdriver.ChromeOptions() prefs = {'download.default_directory': path_get, # prefs = {'download.default_directory': 'E:\\table', 'download.prompt_for_download': False, "download.directory_upgrade": False, "safebrowsing.enabled": False } options.add_experimental_option('prefs', prefs)
如果单纯运行os.getcwd(),会给我返回当前路径是:C:\Windows\system32
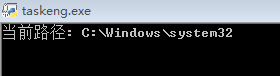
当然我没说这个路径一定不行,但是后面文件损坏的情况应该是跟system32有关。只要你定时任务设置成“最高权限运行”,保存到system32 是可以自动保存的。
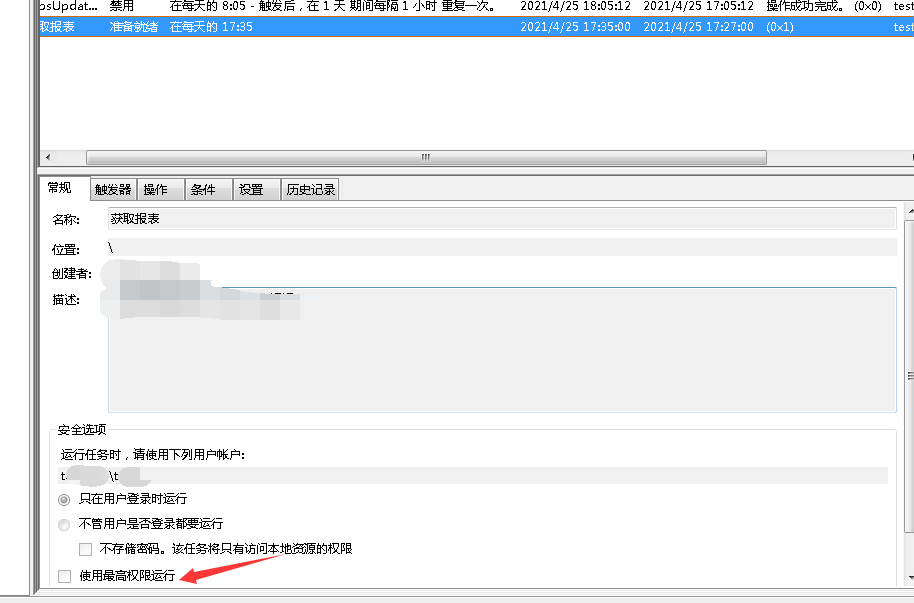
如果不勾选“使用最高权限运行”,可以将 path_get 设置为 'E:\\table'。但是我强烈建议放到这个'E:\\table'下,第二个问题会说到。
2、下载的报表进行改名权限不足
(1)报错现象
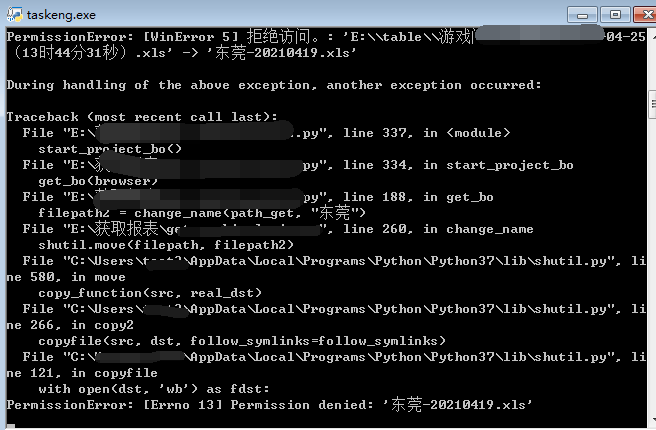
(2)排查过程
我一直以为是我新建的目录权限不够导致的,但是即使我给了完全控制的权限,还是没有权限。我还怀疑python的shutil.move函数需要先新建目标文件,才有权限改名,都不是这些原因。
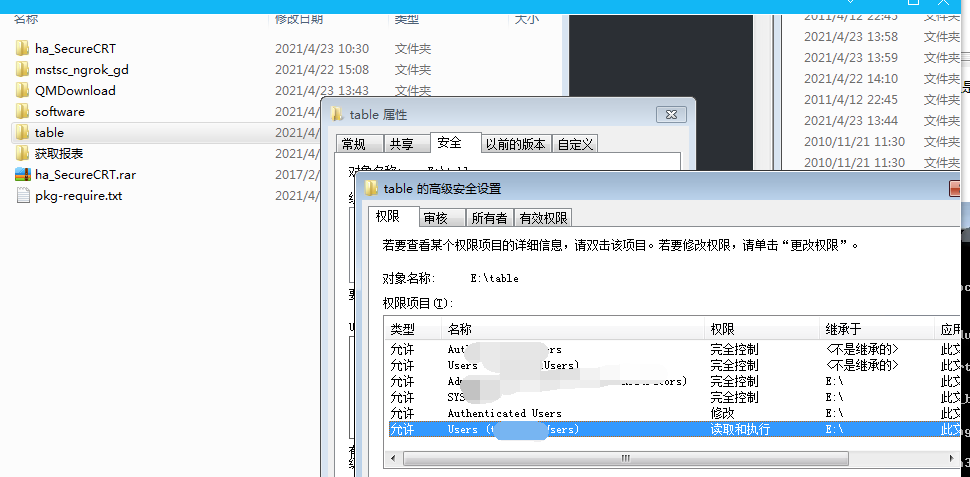
(3)问题解决
导出报表有个接收函数os.getcwd()的变量:path_get。这个路径原来写的是 os.getcwd(),而不是E:\\table,实际上改名后存到的路径是:
C:\Windows\system32 ,所以当我在定时任务上没有勾线“最高权限运行”的时候,是没办法改名保存到system32的。后来我开了发现可以保存了,然后文件损坏了
# path_get = os.getcwd() path_get = 'E:\\table' time.sleep(5) filepath2 = change_name(path_get, "东莞") push_bo(filepath2, "东莞")
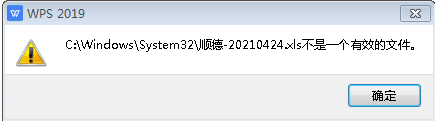
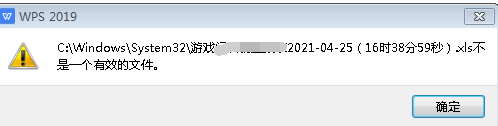
这个文件损坏的报错,即使用了shutil.copy,也是会损坏,而且是原文件和复制文件都损坏。
所以最终我在py上强制指定改名路径,下面的url变量接收改名路径,add是接收地市名称。
def change_name(url, add): url = 'E:\\table' print("改名,当前路径: %s" % url) lists = os.listdir(url) print(lists) 。。。。 filepath2=url+"\\"+add+"-"+last_workdays.replace("-","")+".xls" print(filepath2) time.sleep(5) # dir1 = os.path.dirname() #print("路径名字是: %s" % dir1) # os.rename(filepath, filepath2) shutil.copy(filepath, filepath2) push_bo(filepath2, add) return filepath2
url强制指定改名路径,filepath2原来是没有url+"\\”的,直接是这样,这样会默认下载到system32上(前提开了最高权限运行定时任务)
filepath2=add+"-"+last_workdays.replace("-","")+".xls" ##错误写法
相应的,报表导入到我们系统的函数也要修改,即: push_bo(filepath2, add), 不然会报错。因为这个函数里面,path原来接收变量是不带 url 路径的,直接是文件名,而且用数组去取地市名称,还是原来写成
path[:2]
是不对的,所以我为了省事,写死是地市名称。
def push_bo(path, add): # city_name=path[:2] city_name=add
filepath2 = change_name(path_get, "东莞")
三、复测+总结(2021-04-26--22:46:54)
今天复测了下,推翻和验证了自己的一些猜测,算是给读者有个交代了 ^___^
1、首先排除脚本浏览器初始化的时候,引用的chromedriver路径不同,是不会影响下载的。什么意思?
即使把谷歌驱动chromdriver放到谷歌浏览器的安装目录下,或者放到E盘报表脚本下,另存为要手动确实的情况还是有!留意下图的browser变量
2、win7计划任务设置,为了避免权限问题,还是乖乖勾选“使用最高权限运行”
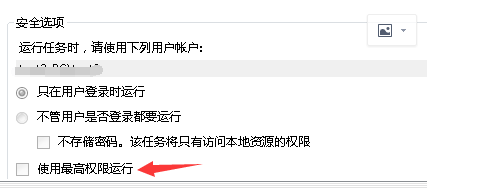
如果不勾选,脚本默认运行路径都会放到C盘上,会导致报表导出之后要人为点击“另存为”,除非显式声明运行路径。
3、对于py脚本的任何一个函数模块,关于当前运行路径最好还是显式指定某个路径,能写全路径都建议写全它。假设某个函数get_bo,是用来实现导出报表的功能的
def get_bo(browser): 。。。 ###### 6.3 操作地市 path_get = 'E:\\table' #原来是 path_get = os.getcwd() time.sleep(5) filepath2 = change_name(path_get, "东莞")
path_get = 'E:\\table' ,不然打印出来是目录: C:\Windows\system32。然后change_name获取到的路径是system32的话,改名操作就会因为找不到指定源文件,而无法进行了。
def change_name(url, add): url = 'E:\\table' #原来没有添加,直接在get_bo上调 。。。 filepath2=url+"\\"+add+"-"+last_workdays.replace("-","")+".xls" 。。。 push_bo(filepath2, add) # 原来为: push_bo(filepath2)
filepath2前面的 url+"\\" 是我新加上去的,原来直接是 add 后面一串。如果不加,push_bo导入报表函数是找不到具体报表位置的,又默认去到C盘去找了,所以强制加了绝对路径,万无一失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号