获取内网路由器管理页面出口ip
获取内网路由器管理页面出口ip
一、唠嗑前言
话说我们有个埋点系统,其中有一列是统计使用我们阅卷系统的ip。
问题来了,这个ip记录不是那么智能的。我们公司也有测试人员要登入阅卷系统做测试,这样这个埋点系统也会把他出口的ip记录下来,然而这个记录信息对运营分析人员是没有任何作用的,我要知道用户使用我们系统的情况,而不是本公司人测试的情况呀~~~

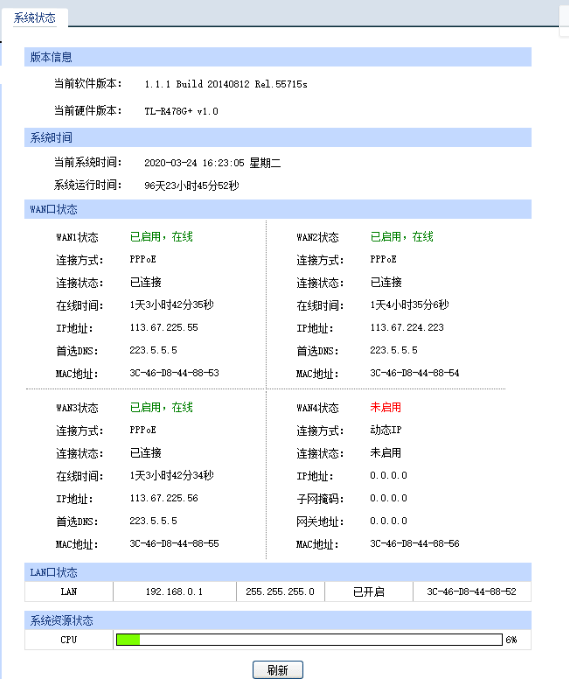
先介绍一下我们公司出口ip的组成情况,实际上公司任意一台电脑包括虚拟机,最终都是汇集起来,通过我们的主路由器出去的,其中有3条电信线路,都不是固定ip(因为贵),会不定时自己更换,有时一天,有时几个小时,甚至几分钟都有可能。现在需要把公司出口ip的信息不要记录到这个埋点系统,因为这个信息没有任何采集和分析的价值。跟开发讨论过,我只需要把这3个ip定时写到一个文件中,让应用程序去读就能实现不记录了。
二、需求实现
主路由器管理页面登录进去长这个样子:
部署环境如下,用的是跟主路由器同一网段的一台虚拟机写的python脚本实现的:
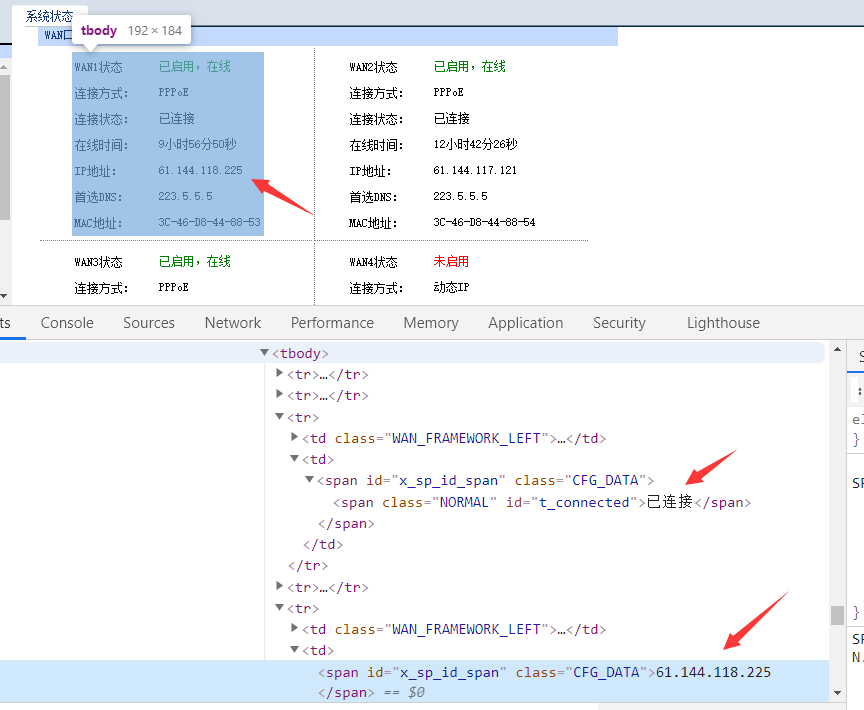
1 #!/usr/bin/env python 2 3 # -*- coding: utf-8 -*- 4 # vim: set fileencoding=utf-8 : 5 6 import logging 7 logging.basicConfig() 8 9 from selenium import webdriver 10 from selenium.webdriver.chrome.options import Options 11 from datetime import * 12 import time 13 from bs4 import BeautifulSoup 14 import urllib.request 15 import json 16 import requests 17 18 from shutil import copyfile #覆盖文件模块 19 import os #运行linux命令模块 20 import paramiko #登录模块 21 22 #1、模拟浏览器登录 23 chrome_options = Options() 24 chrome_options.add_argument('--headless') 25 chrome_options.add_argument('--no-sandbox') 26 chrome_options.add_argument('--disable-gpu') 27 chrome_options.add_argument('--disable-dev-shm-usage') 28 chrome_options.add_argument('--window-size=1920,1080') 29 30 chrome_browser = webdriver.Chrome('chromedriver',chrome_options=chrome_options) 31 chrome_browser.delete_all_cookies() 32 chrome_browser.get("http://192.168.0.1:8008/logon/logon.htm") 33 chrome_browser.find_element_by_id('txt_usr_name').send_keys('admin') 34 chrome_browser.find_element_by_id('txt_password').send_keys('ever8888') 35 chrome_browser.find_element_by_id("btn_logon").click() 36 time.sleep(2) 37 38 #2、判断继续按钮是否存在,存在则点击确认 39 soupconfirm = BeautifulSoup(chrome_browser.page_source, 'lxml') 40 #通过id找到btn_confirm 41 res = soupconfirm.find_all(attrs={"id": "btn_confirm"}) 42 if len(res) != 0: 43 #点击继续,进行下一步 44 chrome_browser.find_element_by_id("btn_confirm").click() 45 print("success: 继续按钮存在") 46 else: 47 print("false: 继续按钮不存在") 48 49 chrome_browser.switch_to.frame("mainFrame") 50 time.sleep(2) 51 52 #获取有ip的iframe页面 53 chrome_browser.switch_to.frame("ifr_wan_sysinfo") 54 time.sleep(2) 55 56 ip = open("/root/router/ip_new", 'w+') 57 soup = BeautifulSoup(chrome_browser.page_source, 'lxml') 58 # 通过class获取有可能含有IP的元素列表 59 els = soup.find_all(attrs={"class": "CFG_DATA"}) 60 for index in range(len(els)): 61 val = els[index].text 62 # 筛选含IP的值,从规则来看,端口显示"已连接"后第二值就是IP 63 if val.find("已连接") > -1: 64 print(els[index + 2].text, file=ip) 65 ip.close() 66 #关闭浏览器 67 chrome_browser.quit() 68 os.system("ps -ef | grep chrome | grep -v grep |awk '{print $2}' | xargs kill -9") 69 70 71 ##是否替换文件ip.txt(有新ip) 72 result=os.system("diff /root/router/ip_new /root/router/ip_old") 73 74 if result != 0 : 75 copyfile('/root/router/ip_new', '/root/router/ip.txt') 76 77 #上传到服务器上 78 transport = paramiko.Transport(('埋点系统线上服务器ip', '埋点系统线上服务器ssh端口')) 79 transport.connect(username='埋点系统线上服务登录账号',password='登录密码') 80 sftp = paramiko.SFTPClient.from_transport(transport) 81 sftp.put('/root/router/ip.txt', '/home/ljy/data/mnt/ip.txt') 82 83 #最新的ip_new覆盖到ip_old 84 copyfile('/root/router/ip_new', '/root/router/ip_old')
几个点我拎出来说明下:
1、前面获取ip,需要有点前端代码基础
首先找到登录接口,传账号密码参数登进去路由器上,然后利用页面元素的组合位置找到 IP 地址那一行(规律是我的开发朋友帮我找的,当然后来我自己也写了个,但方法有点蠢,要对各种符号例如双引号作空白替换的。代码写出来健壮性是很重要的呢~所以俺就不献丑了)
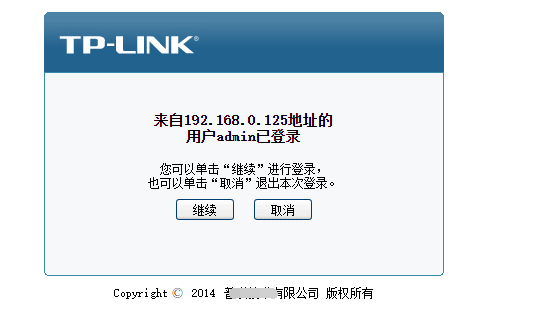
2、“继续”按钮的判断
因为有可能定时脚本跑的时候刚好有人在用,比如我,公司老板,或者最极端的是,上一次定时跑脚本的时候,服务器没有正常退出管理页面,导致要点击“继续” 强制登录
3、ip_new , ip_old, ip.txt 文件
ip_new 和 ip_old 都是在内网虚拟机下的,ip.txt是真正让埋点系统读的ip
(1)ip_new:是当前运行py脚本的时候,进入路由器管理界面获取的ip
(2)ip_old:上一次定时脚本获取的出口ip
如果出口ip没变化(diff比较两个文件),就不上传到线上,不覆盖ip.txt
最后说下,这个脚本定时20分钟跑一次,所以跑的频率其实是不够频繁的,会导致无用测试信息有可能会被记录到 :如果刚好20分钟内,这3条线路的ip变了,测试人员也在测试,那么埋点系统还是会记录这些无价值的信息。为什么调成20分钟一次呀,因为有段时间我经常得进去路由器管理页面操作,这个脚本老是把我挤出去,哪天心情好再调回到每5分钟跑一次。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号