


Linux调度系统全景指南(终结篇)
多核调度
在单核系统中,调度器只需要考虑任务执行先后顺序的问题,在多核系统中,除了任务先后问题,调度器还需要考虑CPU分配问题。也就是说,在多核系统中,调度器还需要决定任务在哪个CPU上运行,需要尽量做到公平和整体性能最大化。一般来说,调度器可以被划分为以下几类:
(1)全局类(Global):即一个调度器就可以管理系统中的所有CPU,任务可以在CPU之间自由迁移。
(2)集群类(Clustered):系统中的CPU被分成互不相交的几个cluster,调度器负责调度任务到cluster内的CPU上去。
(3)分区类(Partitioned ):每个调度器只管自己的那个CPU,系统有多少个CPU就有多少个调度器实体。
(4)任意类(Arbitrary ):每一个任务都可以运行在任何一个CPU集合上。
内核调度系统针对CPU架构演进:单CPU->SMP->NUMA->复杂混合架构, 做了针对性的优化设计;
SMP
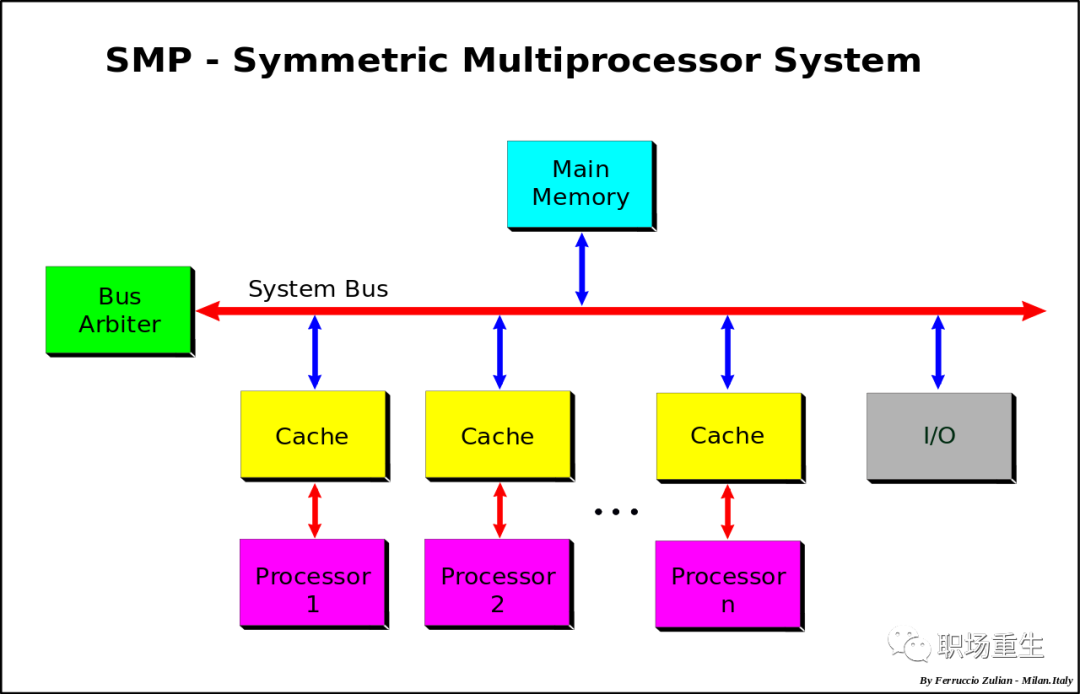
SMP (Symmetric Multiprocessing),对称多处理器. 顾名思义, 在SMP中所有的处理器都是对等的, 它们通过总线连接共享同一块物理内存,这也就导致了系统中所有资源(CPU、内存、I/O等)都是共享的,其架构简单,但是拓展性能比较差。
多处理器系统上,内核必须考虑几个额外的问题,以确保良好的调度效率。
-
CPU负荷必须尽可能公平地在所有的处理器上共享。如果一个处理器负责3个并发的应用程序,而另一个只能处理空闲进程,那是没有意义的。
-
进程与系统中某些处理器的亲合性(affinity)必须是可设置的。例如在4个CPU系统中,可以将计算密集型应用程序绑定到前3个CPU,而剩余的(交互式)进程则在第4个CPU上运行。
-
内核必须能够将进程从一个CPU迁移到另一个。但该选项必须谨慎使用,因为它会严重危害性能。在小型SMP系统上CPU高速缓存是最大的问题。对于真正大型系统, CPU与迁移进程此前使用的物理内存距离可能有若干米,因此对该进程内存的访问代价高昂。
-
进程对特定CPU的亲合性 ,定义在task_struct的 cpus_allowed 成 员 中 。Linux 提供了sched_setaffinity系统调用,可修改进程与CPU的现有分配关系
在SMP系统上,每个调度器类的调度方法必须增加两个额外的函数:
load_balance:允许从最忙的就绪队列分配多个进程到当前CPU,但移动的负荷不能比max_load_move更多,每当内核认为有必要重新均衡时,核心调度器代码都会调用这些函数;
move_one_task:move_one_task则使用了iter_move_one_task,从最忙碌的就绪队列移出一个进程,迁移到当前CPU的就绪队列;
在SMP系统上,周期性调度器函数scheduler_tick按上文所述完成所有系统都需要的任务之后,会调用trigger_load_balance函数,这会引发
SCHEDULE_SOFTIRQ软中断softIRQ,该中断确保会在适当的时机执行run_rebalance_domains。该函数最终对当前CPU调用rebalance_domains,实现负载均衡。
NUMA
-
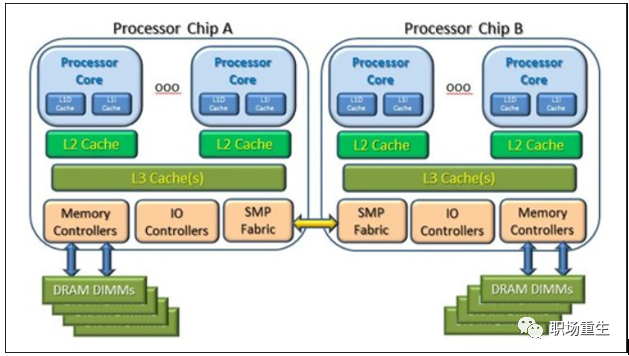
非统一内存访问架构(英语:Non-uniform memory access,简称NUMA)是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些;
-
非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存;
-
在NUMA中还有三个节点的概念:
本地节点:对于某个节点中的所有CPU,此节点称为本地节点。
邻居节点:与本地节点相邻的节点称为邻居节点。
远端节点:非本地节点或邻居节点的节点,称为远端节点。
-
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作Node Distance。正是因为有这个特点,所以我们的应用程序要尽量的减少不通CPU模块之间的交互,也就是说,如果你的应用程序能有方法固定在一个CPU模块里,那么你的应用的性能将会有很大的提升;
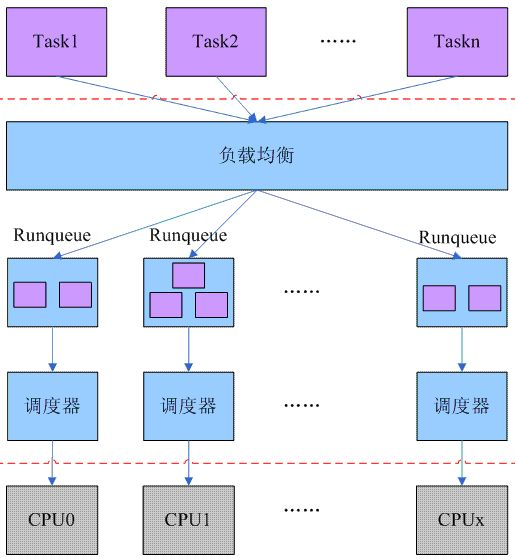
调度域(Scheduling Domain)
Scheduling Domains 是现代硬件技术尤其是多 CPU 多核技术发展的产物。现在,一个复杂的高端系统由上到下可以这样构成:
-
它是一个 NUMA 架构的系统,系统中的每个 Node 访问系统中不同区域的内存有不同的速度。
-
同时它又是一个 SMP 系统。由多个物理 CPU(Physical Package) 构成。这些物理 CPU 共享系统中所有的内存。但都有自己独立的 Cache 。
-
每个物理 CPU 又由多个核 (Core) 构成,即 Multi-core 技术或者叫 Chip-level Multi processor(CMP) 。这些核都被集成在一块 die 里面。一般有自己独立的 L1 Cache,但可能共享 L2 Cache 。
-
每个核中又通过 SMT 之类的技术实现多个硬件线程,或者叫 Virtual CPU( 比如 Intel 的 Hyper-threading 技术 ) 。这些硬件线程,逻辑上看是就是一个 CPU 。它们之间几乎所有的东西都共享。包括 L1 Cache,甚至是逻辑运算单元 (ALU) 以及 Power 。
在上述系统中,最小的执行单元是逻辑 CPU,进程的调度执行也是相对于逻辑 CPU 的。因此,后文皆简称逻辑 CPU 为 CPU,是物理 CPU 时会特别说明。在这样复杂的系统,调度器要解决的一个首要问题就是如何发挥这么多 CPU 的性能,使得负载均衡。不存某些 CPU 一直很忙,进程在排队等待运行,而某些 CPU 却是处于空闲状态。但是在这些 CPU 之间进行 Load Balance 是有代价的,比如对处于两个不同物理 CPU 的进程之间进行负载平衡的话,将会使得 Cache 失效。造成效率的下降。而且过多的 Load Balance 会大量占用 CPU 资源,为了解决上述的这些问题,内核开发人员 Nick Piggin 等人在 Linux 2.6 中引入基于 Scheduling Domains 的解决方案。
-
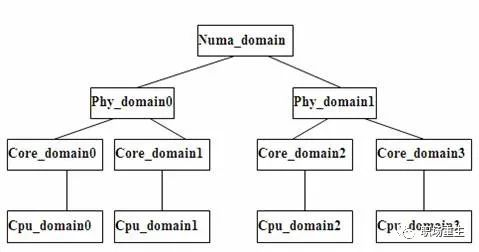
每个 Scheduling Domain 其实就是具有相同属性的一组 cpu 的集合。并且跟据 Hyper-threading, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别。不同级之间通过指针链接在一起,从而形成一种的树状的关系;
-
负载平衡就是针对 Scheduling domain 的。从叶节点往上遍历。直到所有的 domain 中的负载都是平衡的。当然对不同的 domain 会有不同的策略识别是否负载不平衡,以及不同的调度策略。通过这样的方式,从而很好的发挥众多 cpu 的效率;
-
基于 Scheduling Domains 的调度器引入了一组新的数据结构。下面先讲一下两个主要的数据结构:
-
struct sched_domain: 代表一个 Scheduling Domain,也就是一个 CPU 集合,这个集合里所有的 CPU 都具有相同的属性和调度策略。Load Balance 是针对每个 domain 里的 CPU 进行的。这里要注意 Scheduling Domains 是分级的。像上节所讲的复杂系统就分为 Allnuma_domain,Numa_domain, Phy_domain, Core_domain, Smt_domain(Cpu_domain) 五个等级。
-
struct sched_group: 每个 Scheduling domain 都有一个或多个 CPU group,每个 group 都被 domain 当做一个单独的单元来对待。Load Balance 就是在这些 CPU group 之间的 CPU 进行的。
调度优化
当前主流服务器都是多核,多处理器,多NUMA等多CPU架构系统,很多程序都同时跑着服务器里面,怎么最大化利用当前CPU资源, 让整体运行效率更高呢?
调度优化的本质
CPU资源和任务之间最优匹配
这里讨论CPU调度优化一些比较常见的优化点,即包括怎么提升CPU性能,怎么提升单个程序性能,也包括怎么提升整个系统的性能,后面计划会详细讨论关于性能优化等内容,本篇探讨了一些优化点:
性能瓶颈
在进行任何性能优化前,有个很重要的前提原则是要找到性能瓶颈点,然后才能针对性优化,这要求我们学会用性能分析工具:
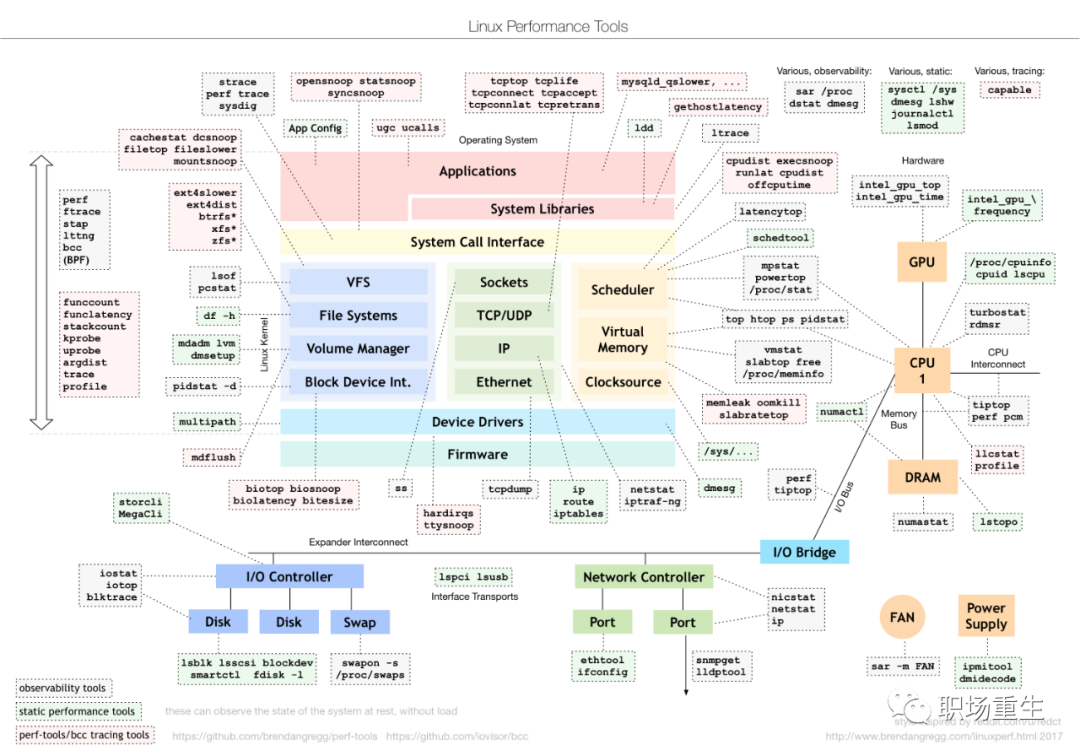
perf
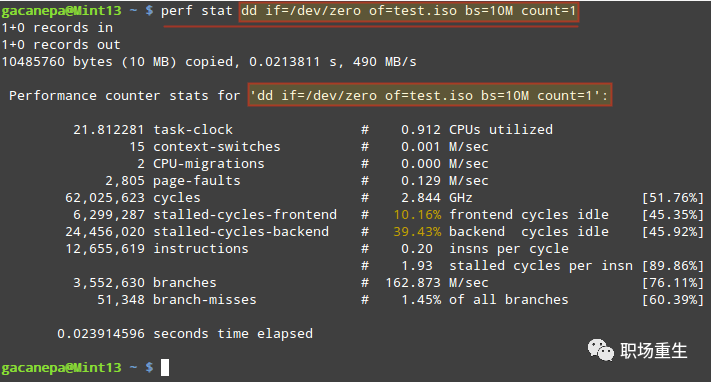
perf stat 采集程序运行事件,用于分析指定程序的性能概况:
-
task-clock:目标任务真真占用处理器的时间,单位是毫秒,我们称之为任务执行时间,后面是任务的处理器占用率(执行时间和持续时间的比值)。持续时间值从任务提交到任务结束的总时间(总时间在stat结束之后会打印出来)。CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
-
context-switches:上下文切换次数,前半部分是切换次数,后面是平均每秒发生次数(M是10的6次方)。
-
cpu-migrations:处理器迁移,linux为了位置各个处理器的负载均衡,会在特定的条件下将某个任务从一个处理器迁往另外一个处理器,此时便是发生了一次处理器迁移。即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
-
page-fault:缺页异常,linux内存管理子系统采用了分页机制,
-
当应用程序请求的页面尚未建立、请求的页面不在内存中或者请求的页面虽在在内存中,
-
但是尚未建立物理地址和虚拟地址的映射关系是,会触发一次缺页异常。
-
cycles:任务消耗的处理器周期数;处理器时钟,一条机器指令可能需要多个 cycles;
-
instructions:任务执行期间产生的处理器指令数,IPC(instructions perf cycle)
-
IPC(Instructions/Cycles )是评价处理器与应用程序性能的重要指标。(很多指令需要多个处理周期才能执行完毕),
-
IPC越大越好,说明程序充分利用了处理器的特征。
-
branches:程序在执行期间遇到的分支指令数。
-
branch-misses:预测错误的分支指令数
-
cache-misses:cache时效的次数
-
cache-references:cache的命中次数
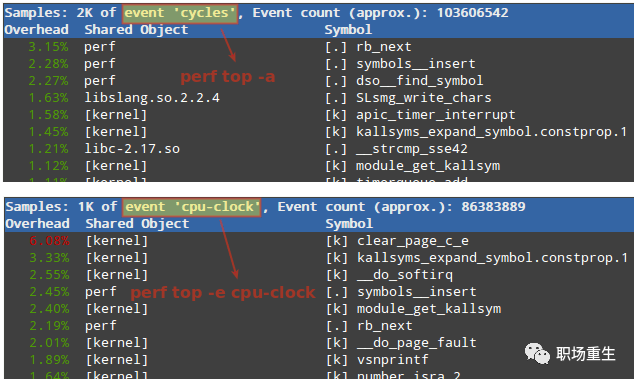
perf top 对系统性能进行实时分析:
-
可以观察到当前函数CPU使用占比;
-
可以查看当前系统最耗时的内核函数或某个用户进程;
-
可以查看到当前耗时的指令;
CPU 火焰图
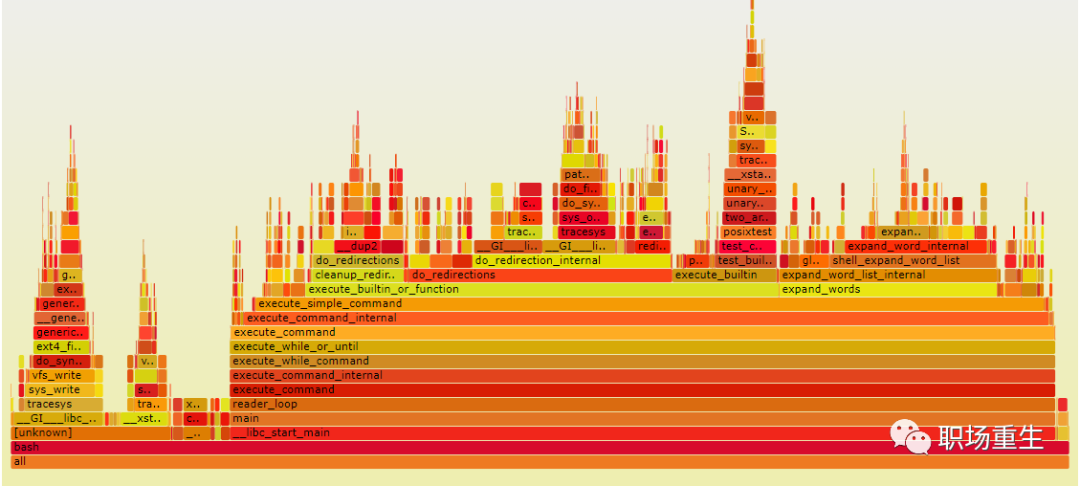
-
支持多种工具源,可以从包含堆栈跟踪的任何配置文件数据生成火焰图,包括从以下配置文件工具生成:
Linux: perf, eBPF, SystemTap, and ktap
Solaris, illumos, FreeBSD: DTrace
Mac OS X: DTrace and Instruments
Windows: Xperf.exe
-
可以查看哪些代码路径很热(CPU占有率高)。
-
可以显示堆栈路径上CPU消耗,找到耗时的最多的函数;
gperf 性能检测
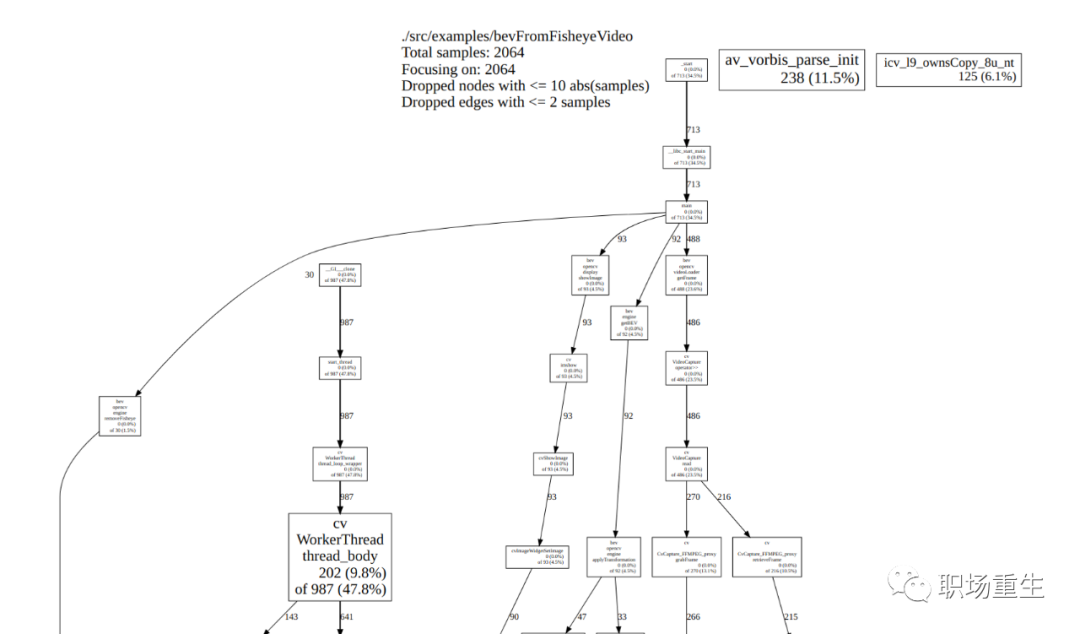
-
Gperftools是可以对用户程序进行性能统计分析。主要优点之一是非常好的图形输出,低开销和使用非常简单(检查的应用程序不需要任何重新编译,只需预加载探查器的库即可启用分析,并且在需要时可以进行可选的库链接编译);
-
可以显示各个调用连上函数执行占比,找到耗时异常的函数,找到性能瓶颈点;
性能优化
局部性原理
局部性有两种,即时间局部性和空间局部性。时间局部性是指当一个数据被访问后,它很有可能会在不久的将来被再次访问,比如循环代码中的数据或指令本身。而空间局部性指的是,当程序访问地址为x的数据时,很有可能会紧接着访问x周围的数据,比如遍历数组或指令的顺序执行。由于这两种局部性存在于大多数的程序中,硬件系统可以很好地预测哪些数据可以放入缓存,从而运行得很好。
-
缓存优化-缓存亲和性
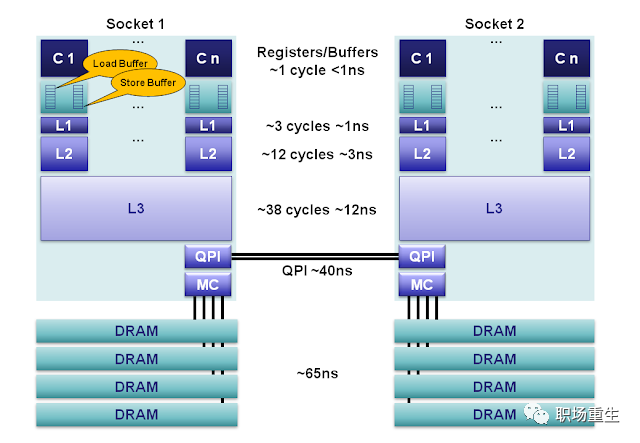
缓存访问在设计多处理器调度时遇到的最后一个问题,是所谓的缓存亲和度(cache affinity)。这个概念很简单:一个进程在某个CPU上运行时,会在该CPU的缓存中维护许多状态。下次该进程在相同CPU上运行时,由于缓存中的数据而执行得更快。相反,在不同的CPU上执行,会由于需要重新加载数据而很慢(好在硬件保证的缓存一致性可以保证正确执行)。因此多处理器调度应该考虑到这种缓存亲和性,并尽可能将进程保持在同一个CPU上。
NUMA优化
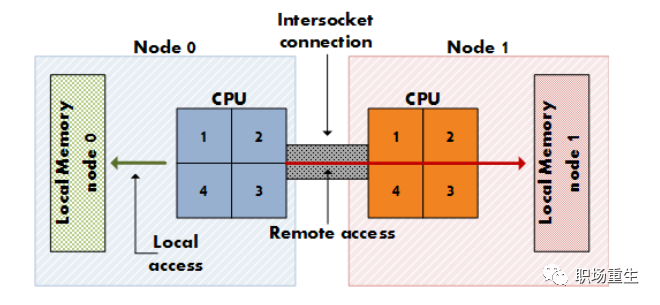
比起访问remote memory,local memory 访问不仅延迟低(100ns),而且也减少了对公共总线(interconnect)的竞争。因此合理地放置数据(比如直接调用NUMA api) , 软件调优化基本上还是围绕在尽量访问本地内存这一思路上。如果本地内存已用完,那么尽量访问本CPU下相临节点的内存,避免访问跨CPU访问最远端的内存,可以提高20-30%性能,具体数据和当前应用相关。
CPU资源优化
-
CPU独占:独占CPU资源,减少调度影响,提高系统性能;
-
CPU绑定:减少CPU上下文切换,提高系统性能;
-
中断亲和 : 中断负载均衡,减轻其他CPU负担,提高系统性能;
-
进程亲和:减少CPU上下文切换,提高系统性能;
-
中断隔离:减少中断对CPU调度影响,提高系统性能;
内存优化
-
采用更大容量的内存,减少内存不足对性能影响,实现用空间换时间的性能优化;
-
使用新内存技术,比如DDR4,好的内存硬件可以减少内存延迟,提高内存访问速度,从而提高系统性能。
时钟优化
-
时钟芯片:采用更高精度时钟芯片可以获得更精确的时间,可以让系统控制粒度更细;
-
时钟频率:时钟频率调整,调高->可以达到更细的计时精度,提高任务调度的效率;调低->可以降低时钟中断的打扰和降低功耗;
优先级优化
-
优先级调整(nice):调整进程优先级,可以让进程运行更快;
调度算法优化
linux 系统一些主线调度算法演进:
O(n)调度算法 -2.4时代
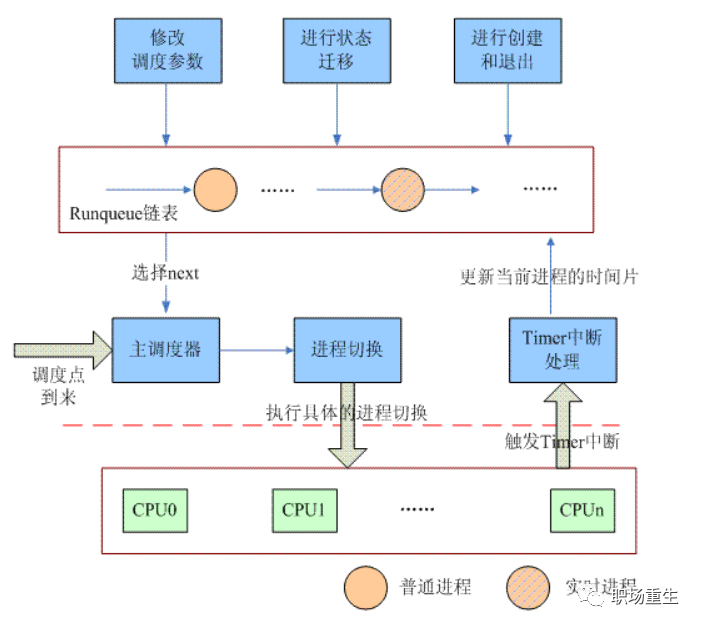
O(n)调度器
-
调度器采用基于优先级的设计;
-
pick next算法非常简单:对runqueue中所有进程的优先级进行依次进行比较,选择最高优先级的进程作为下一个被调度的进程;
-
每次进程切换时, 内核扫描可运行进程的链表, 计算优先级,然后选择”最佳”进程来运行;
O(n)调度器面临的问题
-
时间复杂度问题,时间复杂度是O(n),当系统中的进程很少的时候性能还可以,但是当系统中的进程逐渐增多,选择下一个进程的时间则是逐渐增大。而且当系统中无可运行的进程时,重新初始化进程的时间片也是相当耗时,在系统中进程很多的情况系下。
-
SMP扩展问题。当需要picknext下一个进程时,需要对整个runqueue队列进行加锁的操作,spin_lock_irq(&runqueue_lock);当系统中进程数目比较多的时候,则在临界区的时间就比较长,导致其余的CPU自旋比较浪费
-
实时进程的运行效率问题,因为实时进程和普通进程在一个列表中,每次查实时进程时,都需要全部扫描整个列表,导致实时进程不是很“实时”
-
CPU资源浪费问题:因为系统中只有一个runqueue,则当运行队列中的进程少于CPU的个数时,其余的CPU则几乎是idle状态,浪费资源
-
cache缓存问题:当系统中的进程逐渐减少时,原先在CPU1上运行的进程,不得不在CPU2上运行,导致在CPU2上运行时,cacheline则几乎是空白的,影响效率。
-
总之O(n)调度器有很多问题,不过有问题肯定要解决的。所以在Linux2.6引入了O(1)的调度器。
O(1)调度算法 -2.6时代
O(1)调度器:
-
pick next算法借助于active数组,调度器只需按优先级将下一个任务从特定活动的运行队列中取出即可,无需遍历runqueue,schedule()函数的时间复杂度为O(1)(把O(n)复杂度操作分摊到常规每一次操作中),改进了前任调度器的可扩展性问题;
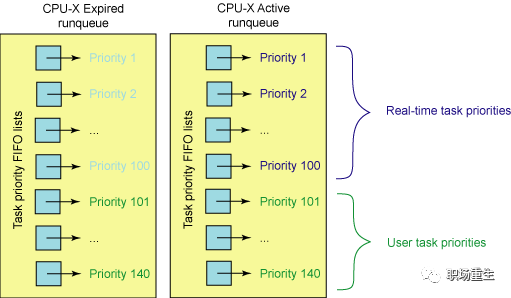
-
消了前任算法定期更新所有进程counter的操作,动态优先级的修改分布在进程切换,时钟tick中断以及其它一些内核函数中进行;
-
O(1)调度器还更好地区分了交互式进程和批处理式进程,提供了大量启示用于确定任务是受 I/O 限制还是受处理器限制算法,使调度更精细;
O(1)调度器面临的问题
-
O(1)调度器对NUMA支持不完善;
-
算法的主要复杂性来自动态优先级的计算,调度器根据平均睡眠时间和一些很难理解的经验公式来修正进程的优先级以及区分交互式进程,导致调度系统代码的日趋复杂,难以维护;
CFS调度算法 -如今主流
-
CFS 背后的主要想法是维护为任务提供处理器时间方面的平衡(公平性)。这意味着应给进程分配相当数量的处理器。分给某个任务的时间失去平衡时(意味着一个或多个任务相对于其他任务而言未被给予相当数量的时间),应给失去平衡的任务分配时间,让其执行;
-
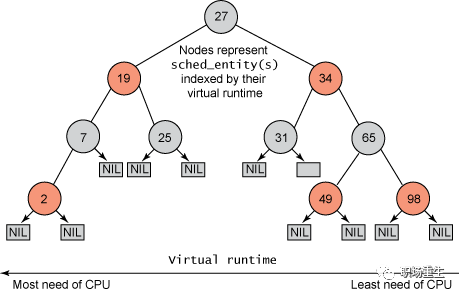
CFS 在叫做vruntime-虚拟运行时 的地方维持提供给某个任务的时间量。任务的虚拟运行时越小, 意味着任务被允许访问服务器的时间越短 — 其对处理器的需求越高;
-
CFS 不直接使用优先级而是将其用作允许任务执行的时间的衰减系数。低优先级任务具有更高的衰减系数,而高优先级任务具有较低的衰减系数。这意味着与高优先级任务相比,低优先级任务允许任务执行的时间消耗得更快。这是一个绝妙的解决方案,可以避免维护按优先级调度的运行队列;
-
CFS 维护了一个以时间为顺序的红黑树,任务存储在以时间为顺序的红黑树中,对处理器需求最多的任务 (最低虚拟运行时)存储在树的左侧,处理器需求最少的任务(最高虚拟运行时)存储在树的右侧,pick_next算法选择vruntime最小进程运行,即选取红黑树最左端的节点调度为下一个以便保持公平性;
BFS & MuqSS-面向桌面或移动设备调度器
BFS的原理十分简单,其实质正是使用了O(1)调度器中的位图的概念,所有进程被安排到103个queue中,各个进程不是按照优先级而是按照优先级区间被排列到各自所在的区间,每一个区间拥有一个queue:
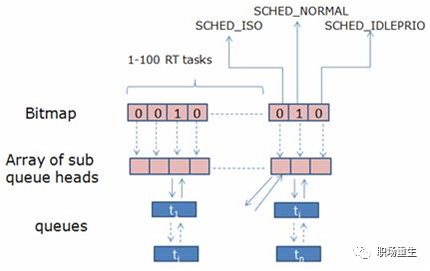
BFS 是一个适用于桌面或移动设备的调度器,设计地比较简洁,用于改善桌面应用的交互性,减小响应时间,提升用户体验。它采用了全局单任务队列设计,不再让每个 CPU 都有独立的运行队列。虽然使用单个全局队列,需要引入队列锁来保证并发安全性,但是对于桌面系统而言,处理器通常都比较少,锁的开销基本可以忽略。BFS 每次会在任务链表中选择具有最小 virtual deadline 的任务运行。
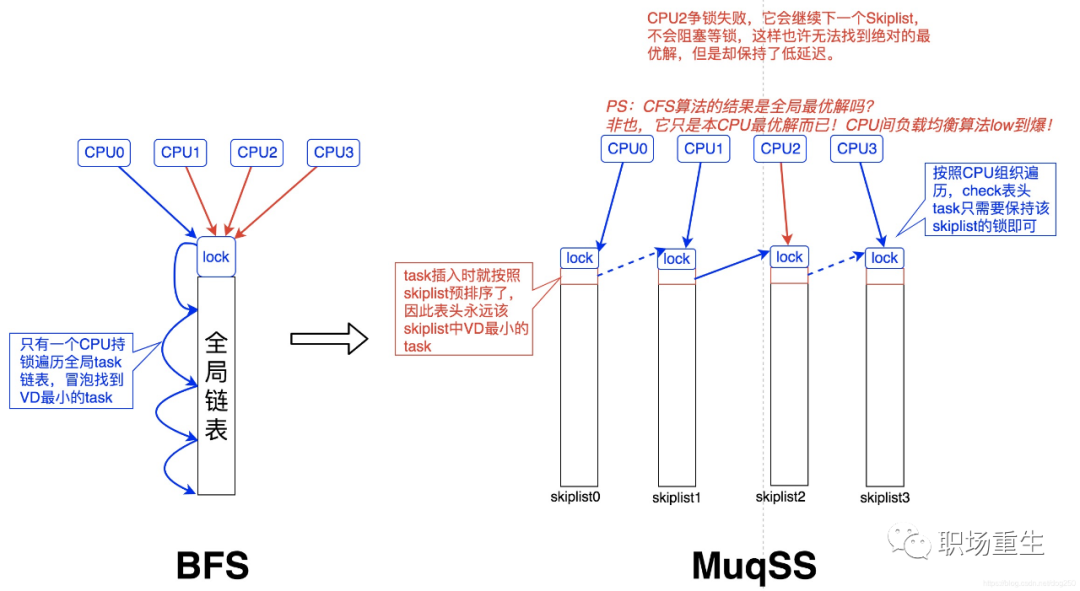
MuqSS 是作者后来基于 BFS 改进的一款调度器,同样是用于桌面环境任务调度。它主要解决了 BFS 的两个问题:
-
每次需要在对应优先级链表中遍历查找需要执行任务,这个时间复杂度为 O(n)。所以新的调度器引入了跳表来解决该问题,从而将时间复杂度降低到 O(1)。
-
全局锁争夺的开销优化,采用 try_lock 替代 lock。
并行优化
并行:多个任务在同一时刻一起发生;
并发:多个任务在同一时刻只能有一个发生,CPU快速切换-操作系统分时复用,给人的感觉还是同时在跑,本质还是串行执行;并发的关键是你有处理多个任务的能力,不一定要同时;并行的关键是你有同时处理多个任务的能力,必须在多核系统上。
在多核系统中需要并行编程提高CPU运行效率
-
一般采用多线程来实现并行计算来缩短计算时间,提高多核系统整体性能;
-
通常是一个线程绑定一个核,可以实现多线程程序CPU利用率最大化;
-
尽量使用线程 local 数据,减少共享数据访问;
-
尽量使用线程栈内存(local变量),减少指针引用,数据结构内存对齐(利用编译指令),减少cache miss;
-
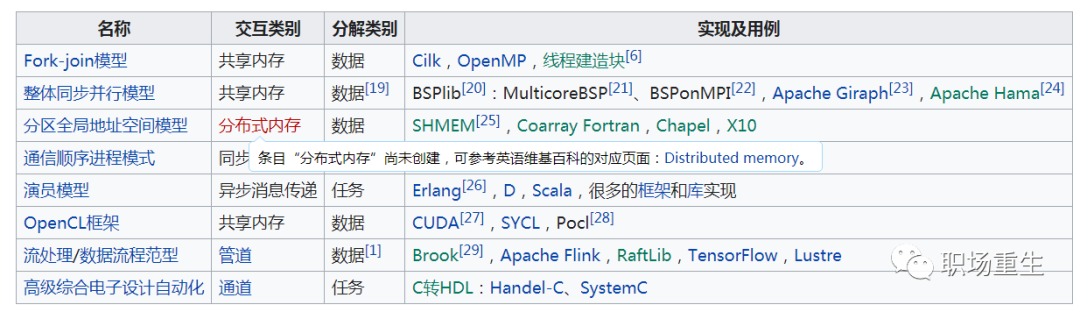
了解参考一些经典成熟并行编程模型对你设计多线程并行程序大有裨益:
-
了解一些典型并行编程思想,OpenCL的GPU并行设计,FPGA里面的多pipeline并行设计,MapReduce大数据计数里面的分而治之;
-
如果不得不访问共享数据,尽量让共享访问代价最小化,让锁范围最小,比如采用原子操作,无锁编程等技术;
锁和无锁设计优化
如何正确有效的保护共享数据是编写并行程序必须面临的一个难题,通常的手段就是同步。同步可分为阻塞型同步(Blocking Synchronization)和非阻塞型同步( Non-blocking Synchronization),多线程里面难免需要访问"共享内存",如果不加锁很容易导致结果异常,程序首先要保证正确,即使影响性能低也需要加锁来防止错误,此时该怎么提高CPU执行性能呢? 一个比较重要的优化工作是锁需要精心设计。
阻塞锁
阻塞锁通过改变了线程的运行状态。让线程进入阻塞状态进行等待,当获得相应的信号(唤醒,时间) 时,才可以进入线程的准备就绪状态,准备就绪状态的线程,通过竞争,进入运行状态;
-
mutex 主要用于线程间互斥访问资源场景;
-
semaphore 主要用于多个线程同步场景;
-
读写锁针主要用于读多写少场景;
非阻塞锁
非阻塞锁不会改变线程状态,使用时不会产生调度,通过CPU忙等待或者基于CAS(Compare - And - Swap)原子操作指令实现非阻塞访问资源;
-
自旋锁底层通过控制原子变量的值,让其他CPU忙等待,cache亲和性高和控制好锁粒度,可以提高多线程访问资源效率,主要用于加锁时间极短且无阻塞点场景;
-
RCU锁(Read-Copy Update)--非常重要一种无锁设计,对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它(因此不会导致锁竞争,不会导致锁竞争,内存延迟以及流水线停滞,读效率极高),但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作,RCU实际上是一种改进的读写锁,更能提高读多写少场景的系统性能;
-
原子操作可以保证指令以原子的方式执行(锁总线或者锁CPU缓存)——执行过程不被打断,主要用于全局统计、引用计数,无锁设计等场景;
-
CAS操作(Compare And Set或是 Compare And Swap),现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构,主要用于各种追求极限高性能场景,比如内存数据库,内存消息队列,DPDK的内存池mempool,java 的Disruptor等;
-
真正无锁-没有资源冲突,每个线程只使用local数据,最高级别的无锁设计,适合分而治之算法场景;
IO优化
-
零拷贝: 减少驱动到协议栈之间内存拷贝,减少用户空间到内核空间内存拷贝,提升IO性能;
-
网卡硬件升级:10G->25G->40G->100G->200G->400G->...;
-
kernelbypass:绕过内核协议栈(路径长,多核性能差),提高IO吞吐量;
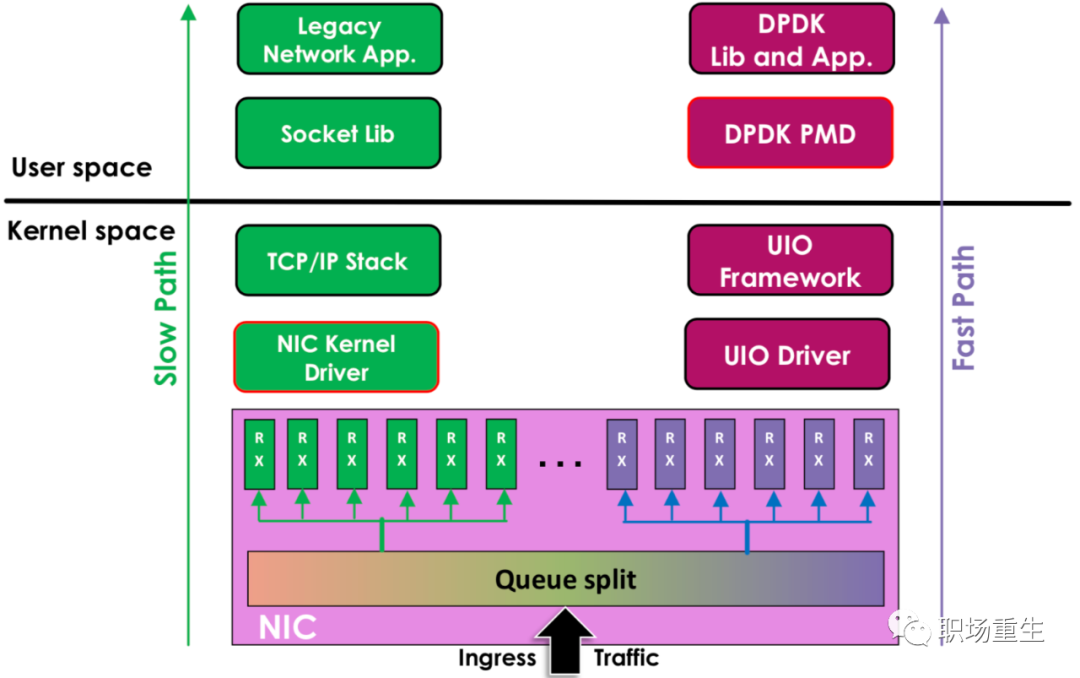
DPDK:
-
Intel DPDK全称Intel Data Plane Development Kit,是intel提供的数据平面开发工具集,为Intel architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,它不同于Linux系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理,适合高性能网关(IO需求大)场景;
-
PMD用户态驱动,使用无中断方式直接操作网卡的接收和发送队列;
-
采用HugePage减少TLB Miss;
-
DPDK采用向量SIMD指令优化性能;
-
CPU亲缘性和独占;
-
内存对齐:根据不同存储硬件的配置来优化程序,确保对象位于不同channel和rank的起始地址,这样能保证对象并并行加载,性能也能够得到极大的提升;
-
Cache对齐,提高cache访问效率:
-
NUMA亲和,提高numa内存访问性能;
-
减少进程上下文切换:保证活跃进程数目不超过CPU个数;减少堵塞函数的调用,尽量采样无锁数据结构;
-
利用空间局部性,采用预取Prefetch,在数据被用到之前就将其调入缓存,增加缓存命中率;
-
充分挖掘网卡的潜能:借助现代网卡支持的分流(RSS, FDIR)和卸载(TSO,chksum)等特性;
XDP:
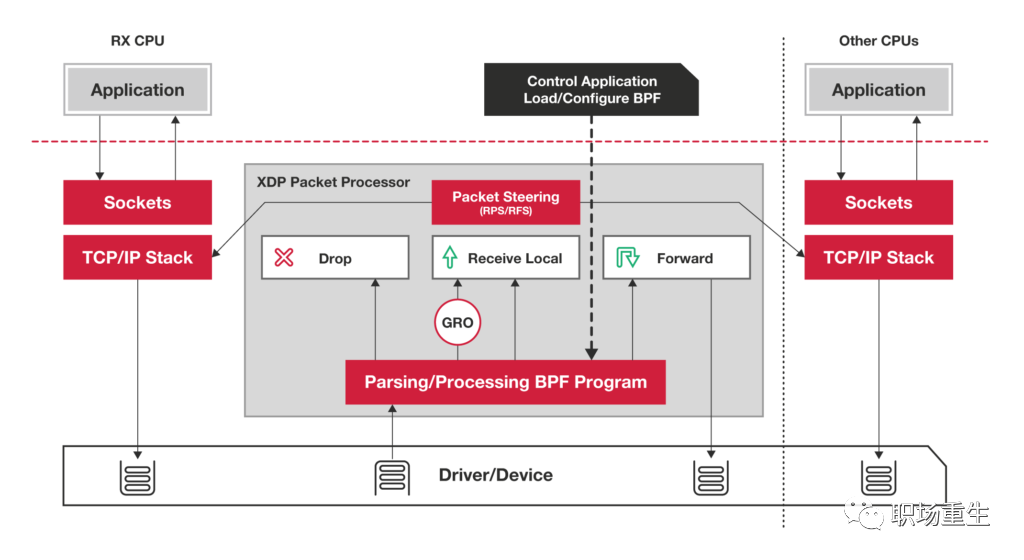
-
XDP(eXpress Data Path)为Linux内核提供了高性能、可编程的网络数据路径。由于网络包在还未进入网络协议栈之前就处理,它给Linux网络带来了巨大的性能提升(性能比DPDK还要高)
-
在网络协议栈前处理
-
无锁设计
-
批量I/O操作
-
轮询式
-
直接队列访问
-
DDIO(网卡直接IO),支持硬件offload加速
-
支持eBPF,高效开发,安全可靠,性能好
-
和内核耦合紧密,适合基于内核网络组件平滑演进高性能方案,比如DDOS防护,网络采样,高性能防火墙;
P4
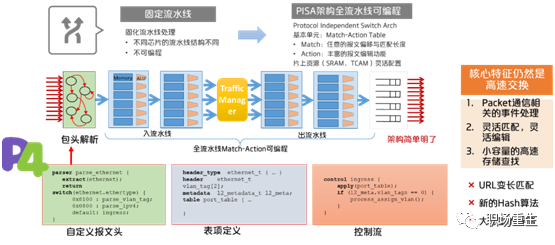
-
p4 为一种高级可编程协议无关处理语言,结合可编程交换机芯片,编程能力强,可以实现业务offload 到硬件,转发面 p4lang 定制开发,控制面可通过 Apache Thrift、gRPC 接口远程管理,生态繁荣包括P4 Runtime、Stratum;
-
性能高,1.8T ~ 6.5T 线速转发,更低时延;
-
每Tbps设备成本大幅降低;
-
主要应用场景是大流量的边界网关,大流量无状态网关,大流量状态网关(当前P4交换机对内存容量支持有限,对配置量有一定的限制);
时空互换
-
Per CPU
Per-CPU是基于空间换时间的方法, 让每个CPU都有自己的私有数据段(放在L1中),并将一些变量私有化到 每个CPU的私有数据段中. 单个CPU在访问自己的私有数据段时, 不需要考虑其他CPU之间的竞争问题,也不存在同步的问题. 注意只有在该变量在各个CPU上逻辑独立时才可使用。
-
指令并行
通过展开循环降低循环开销,提高指令并行执行效率;
-
向量指令
采用SIMD扩展指令集来优化指令执行效率;
-
分支预测
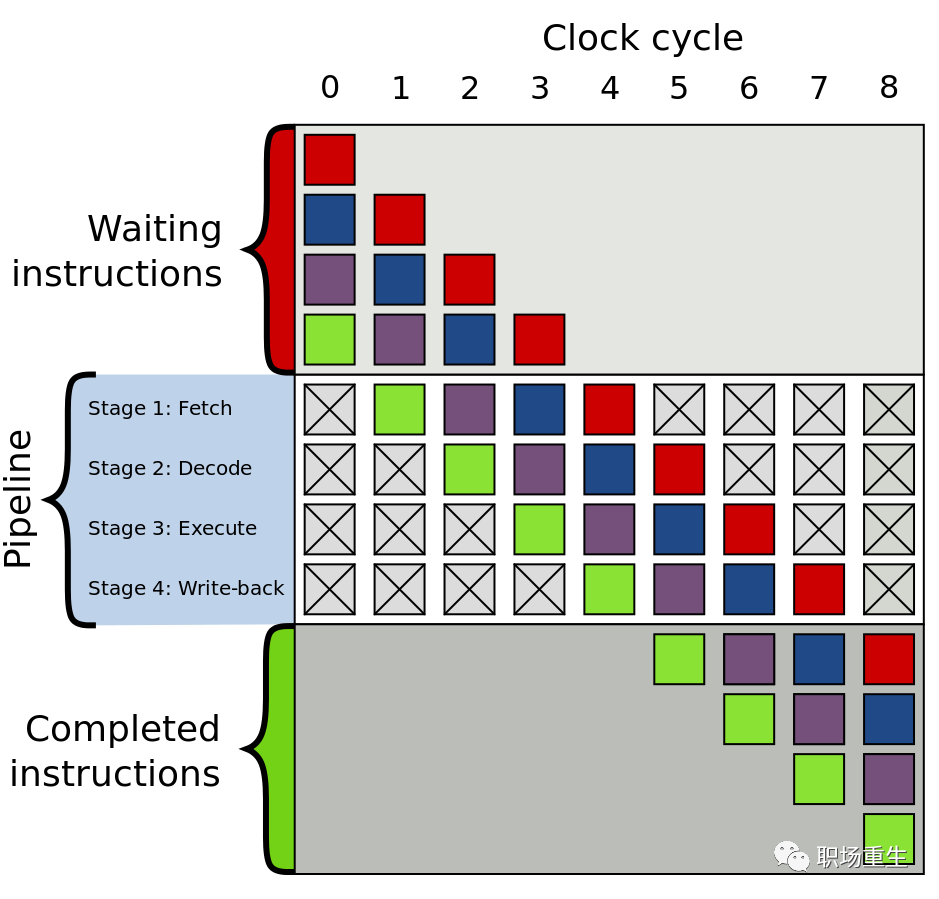
分支预测采用空间换时间方式,直接预测分支条件,把分支指令填入流水线,如果预测失败,再回滚清空流水线,重新选择分支,通过采用有效的预测算法,可以极大提高CPU流水线的执行效率,我们需要合理利用这个特性,减少分支判断,在代码中采用编译指令优化提供分支预测准确性,比如在linux内核中,提分支预测的信息提供给编译器: likely(x) 表示x的值为真的可能性更大;unlikely(x) 表示x的值为假的可能性更大;这样编译器对代码进行优化,以减少指令跳转带来的性能下降。
-
缓存系统:各种cache优化,用空间换时间;
BIOS优化
BIOS(基本输入/输出系统)是主板上的一个小内存,其数据定义了系统的配置。某些数据被写入死存储器(ROM),因此无法更改。另一方面,某些配置可以从BIOS配置中访问,我们在启动PC时通过按键激活该配置。
-
超线程优化(Hyper-Threading)
超线程,是一种用于提升CPU计算并行度的处理器技术,用一个物理核模拟两个逻辑核。这两个逻辑核拥有自己的中断、状态,但是共用物理核的计算资源(寄存器)。超线程技术旨在提高CPU计算资源的使用率,从而提高计算并行度。但是超线程也有副作用,会产生访问cache的竞争,会导致更多的cache不命中(cache-miss),增加线程间的通信负载。加大内存的通信带宽,I/O总线的压力,所以对于一些高性能程序,一般是需要关闭超线程的;
-
电源模式
如果服务器想获得最大的吞吐量或最低的延迟,修改电源模式为最大性能,可以提高服务器的性能;
-
Lockstep模式
锁步模式对内存进行了更高的校验,提升了系统的可靠性,但是降低了内存访问的带宽和延时,对于实时性要求高,吞吐量大的业务场景不适用,对于这些场景从系统,软件和方案层面都有完善的保护机制,所以建议关闭;
-
Turbo Mode
Turbo boost就是Intel的睿频加速技术,通常所说的自动超频技术,主要用于提升处理器的频率,最大程度发挥处理器性能;
批量合并
-
网络 IO 和磁盘 IO,合并操作和批量操作往往能提升吞吐量,提高性能。
-
redis,mysql,kafak等采用批量操作都可以极大提升性能;
预处理
-
预处理策略就是提前做好一些准备工作,这样可以提高后续处理性能;
-
比如网站页面资源的提前加载,可以显著地提升页面下载性能;
-
比如CPU 预取指令,提前将所需要的数据和指令取出来,可以提高流水线效率和缓存效率;
惰性求值
-
惰性处理策略就是尽量将操作(比如计算),推迟到必需执行的时刻,这样很可能避免多余的操作。
-
Linux COW(Copy On Write,写时复制)机制,比如fork 调用只有真正用到资源时候才拷贝;
-
中断后半部分优化,把可延迟函数放到延后处理,从而提高中断处理整体效率;
-
缺页中断处理,不需要进程把所有内存页载入内存,只有需要的时候再加载,这样可以减少大量无效内存操作,提高整体性能;
架构优化
-
系统资源优化: 物理机器->集群->虚拟化->云计算->容器->k8s编排器;
-
应用架构优化: 单体应用->基于组件->面向服务->微服务;
-
软件工程优化: 瀑布模型->敏捷开发->DevOps->智能化工程,主要是提高研发效能,建设产品的性能测试CI/CD自动化流水线,每个优化点都可以及时查看到性能指标变化和对比,从小作坊到标准化,工业化,智能化发展;
算法优化
-
算法复杂度优化:O(1) < O(lgn) < O(n) < O(nlgn) < O(n^2)< O(n^3)<O(2^n) < O(n!) < O(n^n);
-
数据结构优化:hash结构 > 树型结构 > 线性结构;
代码优化
-
循环优化:适当展开循环,可以让指令并行执行,提供搞性能;
-
条件判断:减少条件判断语句,可以减少分支预测失败概率,提升CPU流水线效率,从而提升性能;
-
表达式优化: 优化布尔逻辑可以减少不必要计算;使++i而不使用i++可以减少中间临时变量;
-
采用位运算:如果没有越界风险,使用位运算符合计算机计算模型,效率更高;
-
内存&cache对齐:数据结构最好是cache 对齐的整数倍,把高频使用的属性,放到最前面,这样可以提高cache命中效率,减少Cache miss;
-
指针优化:尽量减少指针使用,指针跳转会导致Cache miss;
-
向量化:合适使用SIMD高级指令可以优化代码;
-
插入其他语言:插入汇编,优化高频函数;采用CPython优化python代码;
-
递归优化:尽量把递归修改为循环,减少递归调用代价;
编译优化
-
编译器优化:O0 -->> O1 -->> O2 -->> O3,来额外的性能提升;
-
编译器API:使用内联函数,使用内存对齐API,使用cache对齐API等 ,可以更好让编译器优化代码,减少调用指令,提高性能;
-
JIt编译器优化:使用Jit技术,可以把中间代码生成本地指令,提升代码执行效率;

