pandas
在日常的数据处理中,经常会对一个DataFrame进行逐行、逐列和逐元素的操作,对应这些操作,Pandas中的map、apply和applymap可以解决绝大部分这样的数据处理需求。
本文演示的数据集是模拟生成的
import pandas as pd import numpy as np boolean=[True,False] gender=["男","女"] color=["white","black","yellow"] data=pd.DataFrame({ "height":np.random.randint(150,190,100), "weight":np.random.randint(40,90,100), "smoker":[boolean[x] for x in np.random.randint(0,2,100)], "gender":[gender[x] for x in np.random.randint(0,2,100)], "age":np.random.randint(15,90,100), "color":[color[x] for x in np.random.randint(0,len(color),100) ] } )
Series数据处理
1、map
如果需要把数据集中gender列的男替换为1,女替换为0,怎么做呢?绝对不是用for循环实现!!!使用Series.map()可以很容易做到,最少仅需一行代码。
#①使用字典进行映射 data["gender"] = data["gender"].map({"男":1, "女":0}) #②使用函数 def gender_map(x): gender = 1 if x == "男" else 0 return gender #注意这里传入的是函数名,不带括号 data["gender"] = data["gender"].map(gender_map)
不论是利用字典还是函数进行映射,map方法都是把对应的数据逐个当作参数传入到字典或函数中,得到映射后的值。
2、apply
同时Series对象还有apply方法,apply方法的作用原理和map方法类似,区别在于apply能够传入功能更为复杂的函数。怎么理解呢?一起看看下面的例子。
假设在数据统计的过程中,年龄age列有较大误差,需要对其进行调整(加上或减去一个值),由于这个加上或减去的值未知,故在定义函数时,需要加多一个参数bias,此时用map方法是操作不了的(传入map的函数只能接收一个参数),apply方法则可以解决这个问题。
def apply_age(x,bias): return x+bias #以元组的方式传入额外的参数 data["age"] = data["age"].apply(apply_age,args=(-3,))
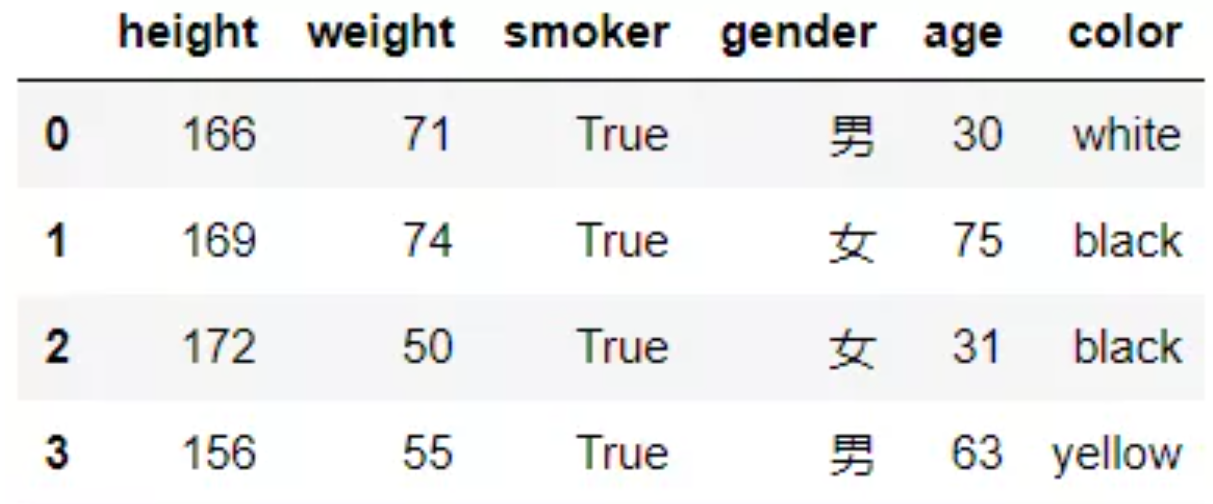
可以看到age列都减了3,当然,这里只是简单举了个例子,当需要进行复杂处理时,更能体现apply的作用。
总而言之,对于Series而言,map可以解决绝大多数的数据处理需求,但如果需要使用较为复杂的函数,则需要用到apply方法。
DataFrame数据处理
apply
对DataFrame而言,apply是非常重要的数据处理方法,它可以接收各种各样的函数(Python内置的或自定义的),处理方式很灵活,下面通过几个例子来看看apply的具体使用及其原理。
在进行具体介绍之前,首先需要介绍一下DataFrame中axis的概念,在DataFrame对象的大多数方法中,都会有axis这个参数,它控制了你指定的操作是沿着0轴还是1轴进行。axis=0代表操作对列columns进行,axis=1代表操作对行row进行,如下图所示。
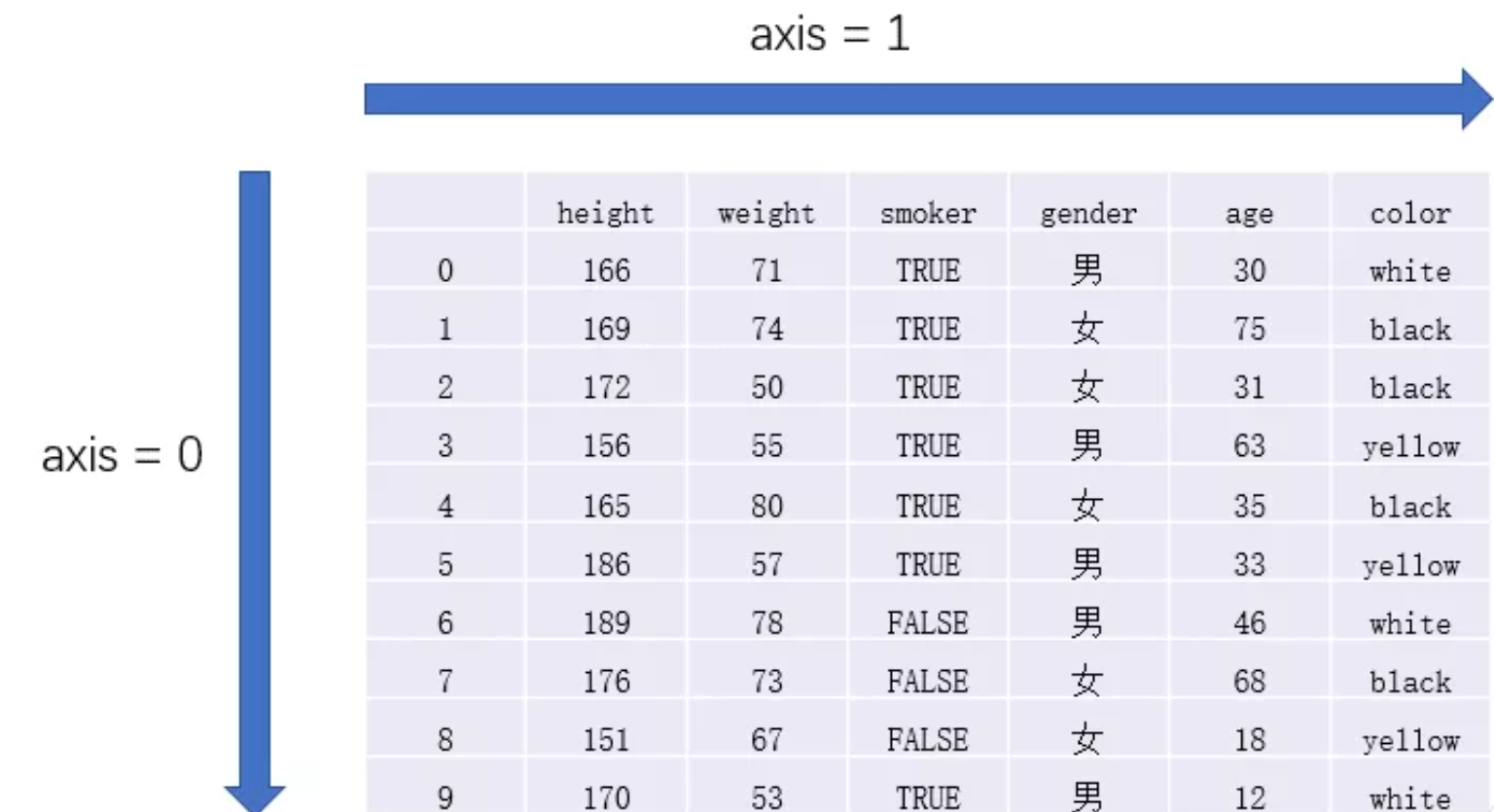
假设现在需要对data中的数值列分别进行取对数和求和的操作,这时可以用apply进行相应的操作,因为是对列进行操作,所以需要指定axis=0,使用下面的两行代码可以很轻松地解决我们的问题。
# 沿着0轴求和 data[["height","weight","age"]].apply(np.sum, axis=0) # 沿着0轴取对数 data[["height","weight","age"]].apply(np.log, axis=0)
当沿着轴0(axis=0)进行操作时,会将各列(columns)默认以Series的形式作为参数,传入到你指定的操作函数中,操作后合并并返回相应的结果。
那如果在实际使用中需要按行进行操作(axis=1),那整个过程又是怎么实现的呢?
在数据集中,有身高和体重的数据,所以根据这个,我们可以计算每个人的BMI指数(体检时常用的指标,衡量人体肥胖程度和是否健康的重要标准),计算公式是:体重指数BMI=体重/身高的平方(国际单位kg/㎡),因为需要对每个样本进行操作,这里使用axis=1的apply进行操作,代码如下:
def BMI(series): weight = series["weight"] height = series["height"]/100 BMI = weight/height**2 return BMI data["BMI"] = data.apply(BMI,axis=1)
applymap
applymap的用法比较简单,会对DataFrame中的每个单元格执行指定函数的操作,虽然用途不如apply广泛,但在某些场合下还是比较有用的,如下面这个例子。
为了演示的方便,新生成一个DataFrame为了演示的方便,新生成一个DataFrame
df = pd.DataFrame( { "A":np.random.randn(5), "B":np.random.randn(5), "C":np.random.randn(5), "D":np.random.randn(5), "E":np.random.randn(5), } ) df
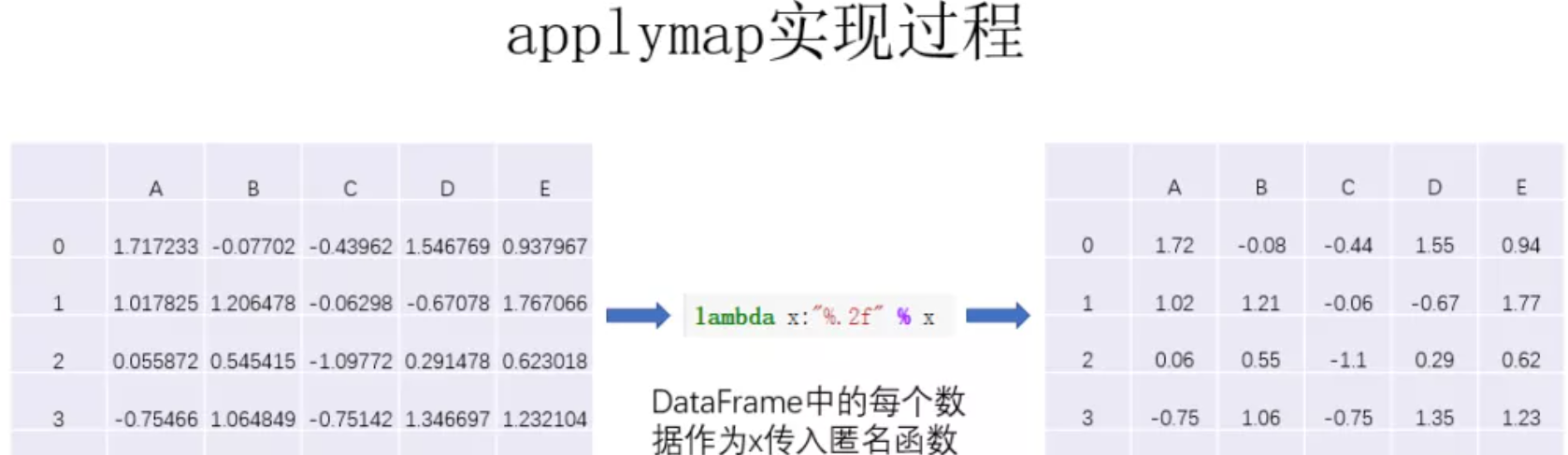
现在想将DataFrame中所有的值保留两位小数显示,使用applymap可以很快达到你想要的目的,代码和图解如下:
df.applymap(lambda x:"%.2f" % x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号