Scrapy
一、简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
requests本质就是就是发送http请求,如果在requests基础上做个封装,我去某个网站或者某个域名一直去发送请求找到所有的url,下载东西的请求在写个方法源源不断的下载东西!这样我们就写了个框架。
三、结构分析
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
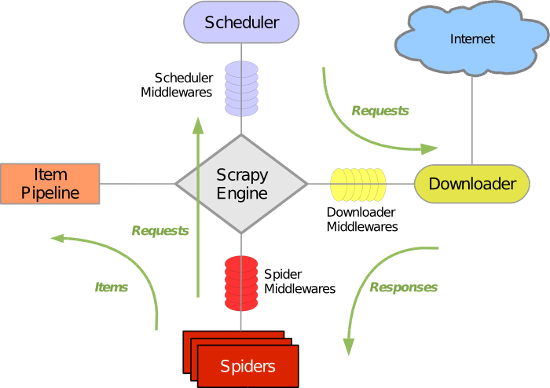
1、Scrapy组件
Scrapy主要包括了以下组件:
1、引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
2、调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
4、爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5、项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6、下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7、爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8、调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
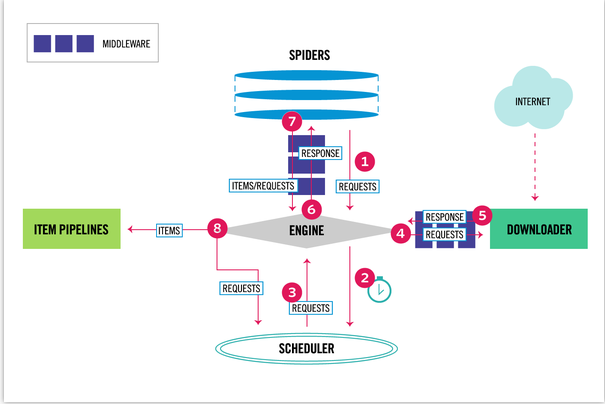
2、Scrapy数据流
Scrapy中的数据流由执行引擎控制,其过程如下:
1)引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
2)引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3)引擎向调度器请求下一个要爬取的URL。
4)调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5)一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6)引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7)Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8)引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9)(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com(初始URL)。
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第五步开始循环,直到获取完老大需要全部信息。
14.管道、调度器:好的,现在就做!
三、实例
1、创建项目
[root@localhost scrapy]# scrapy startproject firstproject New Scrapy project 'firstproject', using template directory '/usr/local/conda/lib/python3.8/site-packages/scrapy/templates/project', created in: /root/python/scrapy/firstproject You can start your first spider with: cd firstproject scrapy genspider example example.com (base) [root@localhost scrapy]# tree firstproject/ firstproject/ ├── firstproject │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ └── __init__.py └── scrapy.cfg 2 directories, 7 files
2、生成爬虫
[root@localhost scrapy]# cd firstproject/ [root@localhost firstproject]# scrapy genspider -t crawl first meijui.com Created spider 'first' using template 'crawl' in module: firstproject.spiders.first [root@localhost firstproject]# tree . . ├── firstproject │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── __pycache__ │ │ ├── __init__.cpython-38.pyc │ │ └── settings.cpython-38.pyc │ ├── settings.py │ └── spiders │ ├── first.py │ ├── __init__.py │ └── __pycache__ │ └── __init__.cpython-38.pyc └── scrapy.cfg
3、执行爬虫


[root@localhost firstproject]# scrapy crawl first 2021-08-05 18:49:27 [scrapy.utils.log] INFO: Scrapy 2.4.1 started (bot: firstproject) 2021-08-05 18:49:27 [scrapy.utils.log] INFO: Versions: lxml 4.6.3.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 21.2.0, Python 3.8.10 (default, Jun 4 2021, 15:09:15) - [GCC 7.5.0], pyOpenSSL 20.0.1 (OpenSSL 1.1.1k 25 Mar 2021), cryptography 3.4.7, Platform Linux-3.10.0-693.el7.x86_64-x86_64-with-glibc2.17 2021-08-05 18:49:27 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor 2021-08-05 18:49:27 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'firstproject', 'NEWSPIDER_MODULE': 'firstproject.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['firstproject.spiders']} 2021-08-05 18:49:27 [scrapy.extensions.telnet] INFO: Telnet Password: c93c6a31f180b440 2021-08-05 18:49:27 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.memusage.MemoryUsage', 'scrapy.extensions.logstats.LogStats'] 2021-08-05 18:49:27 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2021-08-05 18:49:27 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2021-08-05 18:49:27 [scrapy.middleware] INFO: Enabled item pipelines: [] 2021-08-05 18:49:27 [scrapy.core.engine] INFO: Spider opened 2021-08-05 18:49:27 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2021-08-05 18:49:27 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2021-08-05 18:49:27 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://meijui.com/robots.txt> (failed 1 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:27 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://meijui.com/robots.txt> (failed 2 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:27 [scrapy.downloadermiddlewares.retry] ERROR: Gave up retrying <GET http://meijui.com/robots.txt> (failed 3 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:27 [scrapy.downloadermiddlewares.robotstxt] ERROR: Error downloading <GET http://meijui.com/robots.txt>: [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] Traceback (most recent call last): File "/usr/local/conda/lib/python3.8/site-packages/scrapy/core/downloader/middleware.py", line 45, in process_request return (yield download_func(request=request, spider=spider)) twisted.web._newclient.ResponseNeverReceived: [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:27 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://meijui.com/> (failed 1 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:28 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://meijui.com/> (failed 2 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:28 [scrapy.downloadermiddlewares.retry] ERROR: Gave up retrying <GET http://meijui.com/> (failed 3 times): [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:28 [scrapy.core.scraper] ERROR: Error downloading <GET http://meijui.com/> Traceback (most recent call last): File "/usr/local/conda/lib/python3.8/site-packages/scrapy/core/downloader/middleware.py", line 45, in process_request return (yield download_func(request=request, spider=spider)) twisted.web._newclient.ResponseNeverReceived: [<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion.>] 2021-08-05 18:49:28 [scrapy.core.engine] INFO: Closing spider (finished) 2021-08-05 18:49:28 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/exception_count': 6, 'downloader/exception_type_count/twisted.web._newclient.ResponseNeverReceived': 6, 'downloader/request_bytes': 1314, 'downloader/request_count': 6, 'downloader/request_method_count/GET': 6, 'elapsed_time_seconds': 1.068143, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2021, 8, 5, 10, 49, 28, 519183), 'log_count/DEBUG': 4, 'log_count/ERROR': 4, 'log_count/INFO': 10, 'memusage/max': 47726592, 'memusage/startup': 47726592, 'retry/count': 4, 'retry/max_reached': 2, 'retry/reason_count/twisted.web._newclient.ResponseNeverReceived': 4, "robotstxt/exception_count/<class 'twisted.web._newclient.ResponseNeverReceived'>": 1, 'robotstxt/request_count': 1, 'scheduler/dequeued': 3, 'scheduler/dequeued/memory': 3, 'scheduler/enqueued': 3, 'scheduler/enqueued/memory': 3, 'start_time': datetime.datetime(2021, 8, 5, 10, 49, 27, 451040)} 2021-08-05 18:49:28 [scrapy.core.engine] INFO: Spider closed (finished)
四、模块分析
NAME scrapy - Scrapy - a web crawling and web scraping framework written for Python PACKAGE CONTENTS __main__ cmdline commands (package) contracts (package) core (package) crawler downloadermiddlewares (package) dupefilters exceptions exporters extension extensions (package) http (package) interfaces item link linkextractors (package) loader (package) logformatter mail middleware pipelines (package) pqueues resolver responsetypes robotstxt selector (package) settings (package) shell signalmanager signals spiderloader spidermiddlewares (package) spiders (package) squeues statscollectors utils (package) CLASSES builtins.dict(builtins.object) scrapy.item.Field parsel.selector.Selector(builtins.object) scrapy.selector.unified.Selector(parsel.selector.Selector, scrapy.utils.trackref.object_ref) scrapy.item.DictItem(collections.abc.MutableMapping, scrapy.item.BaseItem) scrapy.item.Item scrapy.utils.trackref.object_ref(builtins.object) scrapy.http.request.Request scrapy.http.request.form.FormRequest scrapy.selector.unified.Selector(parsel.selector.Selector, scrapy.utils.trackref.object_ref) scrapy.spiders.Spider class Field(builtins.dict) | Container of field metadata | | Method resolution order: | Field | builtins.dict | builtins.object | | Data descriptors defined here: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined) | | ---------------------------------------------------------------------- | Methods inherited from builtins.dict: | | __contains__(self, key, /) | True if the dictionary has the specified key, else False. | | __delitem__(self, key, /) | Delete self[key]. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(...) | x.__getitem__(y) <==> x[y] | | __gt__(self, value, /) | Return self>value. | | __init__(self, /, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __ne__(self, value, /) | Return self!=value. | | __repr__(self, /) | Return repr(self). | | __setitem__(self, key, value, /) | Set self[key] to value. | | __sizeof__(...) | D.__sizeof__() -> size of D in memory, in bytes | | clear(...) | D.clear() -> None. Remove all items from D. | | copy(...) | D.copy() -> a shallow copy of D | | get(self, key, default=None, /) | Return the value for key if key is in the dictionary, else default. | | items(...) | D.items() -> a set-like object providing a view on D's items | | keys(...) | D.keys() -> a set-like object providing a view on D's keys | | pop(...) | D.pop(k[,d]) -> v, remove specified key and return the corresponding value. | If key is not found, d is returned if given, otherwise KeyError is raised | | popitem(...) | D.popitem() -> (k, v), remove and return some (key, value) pair as a | 2-tuple; but raise KeyError if D is empty. | | setdefault(self, key, default=None, /) | Insert key with a value of default if key is not in the dictionary. | | Return the value for key if key is in the dictionary, else default. | | update(...) | D.update([E, ]**F) -> None. Update D from dict/iterable E and F. | If E is present and has a .keys() method, then does: for k in E: D[k] = E[k] | If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v | In either case, this is followed by: for k in F: D[k] = F[k] | | values(...) | D.values() -> an object providing a view on D's values | | ---------------------------------------------------------------------- | Class methods inherited from builtins.dict: | | fromkeys(iterable, value=None, /) from builtins.type | Create a new dictionary with keys from iterable and values set to value. | | ---------------------------------------------------------------------- | Static methods inherited from builtins.dict: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Data and other attributes inherited from builtins.dict: | | __hash__ = None class FormRequest(scrapy.http.request.Request) | FormRequest(*args, **kwargs) | | Inherit from this class to a keep a record of live instances | | Method resolution order: | FormRequest | scrapy.http.request.Request | scrapy.utils.trackref.object_ref | builtins.object | | Methods defined here: | | __init__(self, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | ---------------------------------------------------------------------- | Class methods defined here: | | from_response(response, formname=None, formid=None, formnumber=0, formdata=None, clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs) from builtins.type | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | valid_form_methods = ['GET', 'POST'] | | ---------------------------------------------------------------------- | Methods inherited from scrapy.http.request.Request: | | __repr__ = __str__(self) | Return str(self). | | __str__(self) | Return str(self). | | copy(self) | Return a copy of this Request | | replace(self, *args, **kwargs) | Create a new Request with the same attributes except for those | given new values. | | ---------------------------------------------------------------------- | Class methods inherited from scrapy.http.request.Request: | | from_curl(curl_command, ignore_unknown_options=True, **kwargs) from builtins.type | Create a Request object from a string containing a `cURL | <https://curl.haxx.se/>`_ command. It populates the HTTP method, the | URL, the headers, the cookies and the body. It accepts the same | arguments as the :class:`Request` class, taking preference and | overriding the values of the same arguments contained in the cURL | command. | | Unrecognized options are ignored by default. To raise an error when | finding unknown options call this method by passing | ``ignore_unknown_options=False``. | | .. caution:: Using :meth:`from_curl` from :class:`~scrapy.http.Request` | subclasses, such as :class:`~scrapy.http.JSONRequest`, or | :class:`~scrapy.http.XmlRpcRequest`, as well as having | :ref:`downloader middlewares <topics-downloader-middleware>` | and | :ref:`spider middlewares <topics-spider-middleware>` | enabled, such as | :class:`~scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware`, | :class:`~scrapy.downloadermiddlewares.useragent.UserAgentMiddleware`, | or | :class:`~scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware`, | may modify the :class:`~scrapy.http.Request` object. | | To translate a cURL command into a Scrapy request, | you may use `curl2scrapy <https://michael-shub.github.io/curl2scrapy/>`_. | | ---------------------------------------------------------------------- | Data descriptors inherited from scrapy.http.request.Request: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined) | | body | | cb_kwargs | | encoding | | meta | | url | | ---------------------------------------------------------------------- | Static methods inherited from scrapy.utils.trackref.object_ref: | | __new__(cls, *args, **kwargs) | Create and return a new object. See help(type) for accurate signature. class Item(DictItem) | Item(*args, **kwargs) | | Base class for scraped items. | | In Scrapy, an object is considered an ``item`` if it is an instance of either | :class:`Item` or :class:`dict`, or any subclass. For example, when the output of a | spider callback is evaluated, only instances of :class:`Item` or | :class:`dict` are passed to :ref:`item pipelines <topics-item-pipeline>`. | | If you need instances of a custom class to be considered items by Scrapy, | you must inherit from either :class:`Item` or :class:`dict`. | | Items must declare :class:`Field` attributes, which are processed and stored | in the ``fields`` attribute. This restricts the set of allowed field names | and prevents typos, raising ``KeyError`` when referring to undefined fields. | Additionally, fields can be used to define metadata and control the way | data is processed internally. Please refer to the :ref:`documentation | about fields <topics-items-fields>` for additional information. | | Unlike instances of :class:`dict`, instances of :class:`Item` may be | :ref:`tracked <topics-leaks-trackrefs>` to debug memory leaks. | | Method resolution order: | Item | DictItem | collections.abc.MutableMapping | collections.abc.Mapping | collections.abc.Collection | collections.abc.Sized | collections.abc.Iterable | collections.abc.Container | BaseItem | _BaseItem | scrapy.utils.trackref.object_ref | builtins.object | | Data and other attributes defined here: | | __abstractmethods__ = frozenset() | | fields = {} | | ---------------------------------------------------------------------- | Methods inherited from DictItem: | | __delitem__(self, key) | | __getattr__(self, name) | | __getitem__(self, key) | | __hash__(self, /) | Return hash(self). | | __init__(self, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | __iter__(self) | | __len__(self) | | __repr__(self) | Return repr(self). | | __setattr__(self, name, value) | Implement setattr(self, name, value). | | __setitem__(self, key, value) | | copy(self) | | deepcopy(self) | Return a :func:`~copy.deepcopy` of this item. | | keys(self) | D.keys() -> a set-like object providing a view on D's keys | | ---------------------------------------------------------------------- | Static methods inherited from DictItem: | | __new__(cls, *args, **kwargs) | Create and return a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Data descriptors inherited from DictItem: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined) | | ---------------------------------------------------------------------- | Methods inherited from collections.abc.MutableMapping: | | clear(self) | D.clear() -> None. Remove all items from D. | | pop(self, key, default=<object object at 0x000001D13D89E070>) | D.pop(k[,d]) -> v, remove specified key and return the corresponding value. | If key is not found, d is returned if given, otherwise KeyError is raised. | | popitem(self) | D.popitem() -> (k, v), remove and return some (key, value) pair | as a 2-tuple; but raise KeyError if D is empty. | | setdefault(self, key, default=None) | D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D | | update(*args, **kwds) | D.update([E, ]**F) -> None. Update D from mapping/iterable E and F. | If E present and has a .keys() method, does: for k in E: D[k] = E[k] | If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v | In either case, this is followed by: for k, v in F.items(): D[k] = v | | ---------------------------------------------------------------------- | Methods inherited from collections.abc.Mapping: | | __contains__(self, key) | | __eq__(self, other) | Return self==value. | | get(self, key, default=None) | D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. | | items(self) | D.items() -> a set-like object providing a view on D's items | | values(self) | D.values() -> an object providing a view on D's values | | ---------------------------------------------------------------------- | Data and other attributes inherited from collections.abc.Mapping: | | __reversed__ = None | | ---------------------------------------------------------------------- | Class methods inherited from collections.abc.Collection: | | __subclasshook__(C) from scrapy.item.ItemMeta | Abstract classes can override this to customize issubclass(). | | This is invoked early on by abc.ABCMeta.__subclasscheck__(). | It should return True, False or NotImplemented. If it returns | NotImplemented, the normal algorithm is used. Otherwise, it | overrides the normal algorithm (and the outcome is cached). class Request(scrapy.utils.trackref.object_ref) | Request(*args, **kwargs) | | Inherit from this class to a keep a record of live instances | | Method resolution order: | Request | scrapy.utils.trackref.object_ref | builtins.object | | Methods defined here: | | __init__(self, url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None, flags=None, cb_kwargs=None) | Initialize self. See help(type(self)) for accurate signature. | | __repr__ = __str__(self) | | __str__(self) | Return str(self). | | copy(self) | Return a copy of this Request | | replace(self, *args, **kwargs) | Create a new Request with the same attributes except for those | given new values. | | ---------------------------------------------------------------------- | Class methods defined here: | | from_curl(curl_command, ignore_unknown_options=True, **kwargs) from builtins.type | Create a Request object from a string containing a `cURL | <https://curl.haxx.se/>`_ command. It populates the HTTP method, the | URL, the headers, the cookies and the body. It accepts the same | arguments as the :class:`Request` class, taking preference and | overriding the values of the same arguments contained in the cURL | command. | | Unrecognized options are ignored by default. To raise an error when | finding unknown options call this method by passing | ``ignore_unknown_options=False``. | | .. caution:: Using :meth:`from_curl` from :class:`~scrapy.http.Request` | subclasses, such as :class:`~scrapy.http.JSONRequest`, or | :class:`~scrapy.http.XmlRpcRequest`, as well as having | :ref:`downloader middlewares <topics-downloader-middleware>` | and | :ref:`spider middlewares <topics-spider-middleware>` | enabled, such as | :class:`~scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware`, | :class:`~scrapy.downloadermiddlewares.useragent.UserAgentMiddleware`, | or | :class:`~scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware`, | may modify the :class:`~scrapy.http.Request` object. | | To translate a cURL command into a Scrapy request, | you may use `curl2scrapy <https://michael-shub.github.io/curl2scrapy/>`_. | | ---------------------------------------------------------------------- | Data descriptors defined here: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined) | | body | | cb_kwargs | | encoding | | meta | | url | | ---------------------------------------------------------------------- | Static methods inherited from scrapy.utils.trackref.object_ref: | | __new__(cls, *args, **kwargs) | Create and return a new object. See help(type) for accurate signature. class Selector(parsel.selector.Selector, scrapy.utils.trackref.object_ref) | Selector(*args, **kwargs) | | An instance of :class:`Selector` is a wrapper over response to select | certain parts of its content. | | ``response`` is an :class:`~scrapy.http.HtmlResponse` or an | :class:`~scrapy.http.XmlResponse` object that will be used for selecting | and extracting data. | | ``text`` is a unicode string or utf-8 encoded text for cases when a | ``response`` isn't available. Using ``text`` and ``response`` together is | undefined behavior. | | ``type`` defines the selector type, it can be ``"html"``, ``"xml"`` | or ``None`` (default). | | If ``type`` is ``None``, the selector automatically chooses the best type | based on ``response`` type (see below), or defaults to ``"html"`` in case it | is used together with ``text``. | | If ``type`` is ``None`` and a ``response`` is passed, the selector type is | inferred from the response type as follows: | | * ``"html"`` for :class:`~scrapy.http.HtmlResponse` type | * ``"xml"`` for :class:`~scrapy.http.XmlResponse` type | * ``"html"`` for anything else | | Otherwise, if ``type`` is set, the selector type will be forced and no | detection will occur. | | Method resolution order: | Selector | parsel.selector.Selector | scrapy.utils.trackref.object_ref | builtins.object | | Methods defined here: | | __init__(self, response=None, text=None, type=None, root=None, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | ---------------------------------------------------------------------- | Data descriptors defined here: | | response | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | selectorlist_cls = <class 'scrapy.selector.unified.SelectorList'> | The :class:`SelectorList` class is a subclass of the builtin ``list`` | class, which provides a few additional methods. | | ---------------------------------------------------------------------- | Methods inherited from parsel.selector.Selector: | | __bool__(self) | Return ``True`` if there is any real content selected or ``False`` | otherwise. In other words, the boolean value of a :class:`Selector` is | given by the contents it selects. | | __getstate__(self) | | __nonzero__ = __bool__(self) | Return ``True`` if there is any real content selected or ``False`` | otherwise. In other words, the boolean value of a :class:`Selector` is | given by the contents it selects. | | __repr__ = __str__(self) | Return str(self). | | __str__(self) | Return str(self). | | css(self, query) | Apply the given CSS selector and return a :class:`SelectorList` instance. | | ``query`` is a string containing the CSS selector to apply. | | In the background, CSS queries are translated into XPath queries using | `cssselect`_ library and run ``.xpath()`` method. | | .. _cssselect: https://pypi.python.org/pypi/cssselect/ | | extract = get(self) | Serialize and return the matched nodes in a single unicode string. | Percent encoded content is unquoted. | | get(self) | Serialize and return the matched nodes in a single unicode string. | Percent encoded content is unquoted. | | getall(self) | Serialize and return the matched node in a 1-element list of unicode strings. | | re(self, regex, replace_entities=True) | Apply the given regex and return a list of unicode strings with the | matches. | | ``regex`` can be either a compiled regular expression or a string which | will be compiled to a regular expression using ``re.compile(regex)``. | | By default, character entity references are replaced by their | corresponding character (except for ``&`` and ``<``). | Passing ``replace_entities`` as ``False`` switches off these | replacements. | | re_first(self, regex, default=None, replace_entities=True) | Apply the given regex and return the first unicode string which | matches. If there is no match, return the default value (``None`` if | the argument is not provided). | | By default, character entity references are replaced by their | corresponding character (except for ``&`` and ``<``). | Passing ``replace_entities`` as ``False`` switches off these | replacements. | | register_namespace(self, prefix, uri) | Register the given namespace to be used in this :class:`Selector`. | Without registering namespaces you can't select or extract data from | non-standard namespaces. See :ref:`selector-examples-xml`. | | remove_namespaces(self) | Remove all namespaces, allowing to traverse the document using | namespace-less xpaths. See :ref:`removing-namespaces`. | | xpath(self, query, namespaces=None, **kwargs) | Find nodes matching the xpath ``query`` and return the result as a | :class:`SelectorList` instance with all elements flattened. List | elements implement :class:`Selector` interface too. | | ``query`` is a string containing the XPATH query to apply. | | ``namespaces`` is an optional ``prefix: namespace-uri`` mapping (dict) | for additional prefixes to those registered with ``register_namespace(prefix, uri)``. | Contrary to ``register_namespace()``, these prefixes are not | saved for future calls. | | Any additional named arguments can be used to pass values for XPath | variables in the XPath expression, e.g.:: | | selector.xpath('//a[href=$url]', url="http://www.example.com") | | ---------------------------------------------------------------------- | Data descriptors inherited from parsel.selector.Selector: | | __weakref__ | list of weak references to the object (if defined) | | attrib | Return the attributes dictionary for underlying element. | | namespaces | | root | | text | | type | | ---------------------------------------------------------------------- | Static methods inherited from scrapy.utils.trackref.object_ref: | | __new__(cls, *args, **kwargs) | Create and return a new object. See help(type) for accurate signature. class Spider(scrapy.utils.trackref.object_ref) | Spider(*args, **kwargs) | | Base class for scrapy spiders. All spiders must inherit from this | class. | | Method resolution order: | Spider | scrapy.utils.trackref.object_ref | builtins.object | | Methods defined here: | | __init__(self, name=None, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | __repr__ = __str__(self) | | __str__(self) | Return str(self). | | log(self, message, level=10, **kw) | Log the given message at the given log level | | This helper wraps a log call to the logger within the spider, but you | can use it directly (e.g. Spider.logger.info('msg')) or use any other | Python logger too. | | make_requests_from_url(self, url) | This method is deprecated. | | parse(self, response, **kwargs) | | start_requests(self) | | ---------------------------------------------------------------------- | Class methods defined here: | | from_crawler(crawler, *args, **kwargs) from builtins.type | | handles_request(request) from builtins.type | | update_settings(settings) from builtins.type | | ---------------------------------------------------------------------- | Static methods defined here: | | close(spider, reason) | | ---------------------------------------------------------------------- | Data descriptors defined here: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined) | | logger | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | __annotations__ = {'custom_settings': typing.Union[dict, NoneType], 'n... | | custom_settings = None | | name = None | | ---------------------------------------------------------------------- | Static methods inherited from scrapy.utils.trackref.object_ref: | | __new__(cls, *args, **kwargs) | Create and return a new object. See help(type) for accurate signature. DATA __all__ = ['__version__', 'version_info', 'twisted_version', 'Spider',... twisted_version = (18, 9, 0) version_info = (2, 4, 1) VERSION 2.4.1 FILE d:\learning\anaconda\lib\site-packages\scrapy\__init__.py None Process finished with exit code 0
[root@localhost scrapy]# scrapy Scrapy 2.4.1 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command
[root@localhost scrapy]# scrapy startproject Usage ===== scrapy startproject <project_name> [project_dir] Create new project Options ======= --help, -h show this help message and exit Global Options -------------- --logfile=FILE log file. if omitted stderr will be used --loglevel=LEVEL, -L LEVEL log level (default: DEBUG) --nolog disable logging completely --profile=FILE write python cProfile stats to FILE --pidfile=FILE write process ID to FILE --set=NAME=VALUE, -s NAME=VALUE set/override setting (may be repeated) --pdb enable pdb on failure
[root@localhost scrapy]# scrapy genspider Usage ===== scrapy genspider [options] <name> <domain> Generate new spider using pre-defined templates Options ======= --help, -h show this help message and exit --list, -l List available templates --edit, -e Edit spider after creating it --dump=TEMPLATE, -d TEMPLATE Dump template to standard output --template=TEMPLATE, -t TEMPLATE Uses a custom template. --force If the spider already exists, overwrite it with the template Global Options -------------- --logfile=FILE log file. if omitted stderr will be used --loglevel=LEVEL, -L LEVEL log level (default: DEBUG) --nolog disable logging completely --profile=FILE write python cProfile stats to FILE --pidfile=FILE write process ID to FILE --set=NAME=VALUE, -s NAME=VALUE set/override setting (may be repeated) --pdb enable pdb on failure
[root@localhost firstproject]# scrapy crawl 2021-08-05 18:46:41 [scrapy.utils.log] INFO: Scrapy 2.4.1 started (bot: firstproject) 2021-08-05 18:46:41 [scrapy.utils.log] INFO: Versions: lxml 4.6.3.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 21.2.0, Python 3.8.10 (default, Jun 4 2021, 15:09:15) - [GCC 7.5.0], pyOpenSSL 20.0.1 (OpenSSL 1.1.1k 25 Mar 2021), cryptography 3.4.7, Platform Linux-3.10.0-693.el7.x86_64-x86_64-with-glibc2.17 2021-08-05 18:46:41 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor Usage ===== scrapy crawl [options] <spider> Run a spider Options ======= --help, -h show this help message and exit -a NAME=VALUE set spider argument (may be repeated) --output=FILE, -o FILE append scraped items to the end of FILE (use - for stdout) --overwrite-output=FILE, -O FILE dump scraped items into FILE, overwriting any existing file --output-format=FORMAT, -t FORMAT format to use for dumping items Global Options -------------- --logfile=FILE log file. if omitted stderr will be used --loglevel=LEVEL, -L LEVEL log level (default: DEBUG) --nolog disable logging completely --profile=FILE write python cProfile stats to FILE --pidfile=FILE write process ID to FILE --set=NAME=VALUE, -s NAME=VALUE set/override setting (may be repeated) --pdb enable pdb on failure

 浙公网安备 33010602011771号
浙公网安备 33010602011771号