
MySQL数据库优化
概念:MySQL其实就是一个文件。
概念:主键是索引,索引不一定是主键。表中的主键和外键一定要为其建立索引
概念:即使你只想查询id=8的分数,但是其他数据(比如题目和答案字段)也会被扫描的。一行行的扫描,一行里的每个数据都会被扫描到(垂直拆分)。
概念:有100亿个用户,可以采用【取模】的方式,将其分到100张表里面。(水平拆分)。
概念:索引不能太多,不然会拖慢写入速度(因为要建立索引),也会影响查询速度。
// 可能的原因:
1、连接超时
2、慢查询导致的无法加载
3、阻塞早餐无法提交
// 效果从低到高:
硬件 -> 系统配置 -> 表设计 -> SQL及索引
会发现,成本越低,反而效果还更明显。所以应尽量提高表设计和SQL及优化
——————如何开启慢查询日志——————
1、登录并查询:
mysql -uroot -pxxxxx; //登录mysql show variables like 'slow_query_log'; //看下是否开启了慢查询日志
2、查找所有关于log的变量设置:
show variables like '%log%';
——会看到log_queries_not_using_indexes的状态是OFF
3、设置开启慢查询记录日志:
set global log_queries_not_using_indexes=on;
4、查找变量long_query_time:
show variables like 'long_query_time'; //查询超时时间的设置
——会发现是10.0000,也就是当前设置查询时间超过10秒的才会被记录。
5、修改慢查询日志记录时间为1秒:
set global long_query_time=1;
——此时需要退出mysql并重新进入,执行4的语句,就变成1了。
6、设置慢查询日志开启:
set global slow_query_log=on;
——那么慢查询日志就开启成功了。
7、通过变量查看慢查询日志被记录到哪个位置:
show variables like 'slow%';
——发现慢查询日志状态ON,位置为:VM_33_41_centos-slow.log。这个位置意味着,是和当前mysql位置之下的该文件。
退出 mysql,并查找该文件的路径:
find / -name VM_33_41_centos-slow.log //其他命令也可以
——查找到这个文件位于/usr/local/mariadb/var/VM_33_41_centos-slow.log
8、可以通过vim或者tail可以查看该文件:
//查看慢查询日志内容 vim /usr/local/mariadb/var/VM_33_41_centos-slow.log //或 tail -50 /usr/local/mariadb/var/VM_33_41_centos-slow.log
————————慢查询日志工具————————
第一款:mysqldumpslow
安装mysql后,这款工具也就被安装了。
所以直接输入命令就可以分析:
mysqldumpslow -t 10 /usr/local/mariadb/var/VM_33_41_centos-slow.log | more //最新10条慢查询日志的分析
第二款:pt-query-digest (这款比较推荐,更强大)
1、下载:
wget percona.com/get/pt-query-digest //安装 chmod u+x pt-query-digest //赋予权限 mv pt-query-digest /usr/bin/pt-query-digest //当前目录移动到usr/bin下 //以下可选,看提示缺少什么 yum -y install perl-Time-HiRes yum -y install perl perl-devel perl-Time-HiRes perl-DBD-MySQL yum -y install perl-Digest-MD5
分析结果:
pt-query-digest /usr/local/mariadb/var/VM_33_41_centos-slow.log | more //将慢查询日志slow_log的分析结果输出到slow_log.report
————可以分析出非常详细的分析
————————索引优化————————
//一般方法:排序、分组、查询、联合查询频率高的。
1、执行次数多,且占用时间长的。 - 通常为pt-query-digest分析的前几项
2、I/O大的SQL。 - 注意pt-query-digest分析的Rows examine项(扫描的行数越多,IO越大)
3、未命中索引的SQL - 注意pt-query-digest分析的Rows examine和Rows Send的对比(扫描行数和发送行数。索引命中率比较低)。
//分析SQL:
使用example,可以查看sql的执行计划。example有很多不同的用法,有需要再详细了解。
——explain + 查询SQL – 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
//索引维护的方法
问题:对于一些没有用的索引,我们需要进行删除。
目前mysql没有记录索引的使用情况。但是PerconMySQL和mariaDB中可以通过INDEX_STATISTICS表进行查看哪些索引未使用。
要特别注意,如果是一主多从的数据库分布,要每个都分析。
————————创建索引————————
// 创建普通索引:
create index index_name on table_name(column_name)
——index_name:索引名称,将来删除(操作)索引需要用到。
——table_name:对应表名
——cloumn_name:需要创建索引的列名称
// 创建唯一索引:
create unique index 索引名 on 表名(列名)
// 创建主键索引:
alter table 表名 add primary key(列名);
// 创建组合索引:
create index ix_name_email on in3(name,email);
——注意:对于同时搜索n个条件时,组合索引的性能好于多个单一索引合并。
————————MySQL数据库结构优化————————
// 选择【合适】的数据类型:
1、选择可以存下你的数据的最小数据类型。
2、使用简单的数据类型。Int要比varchar在mysql上的处理简单。
3、尽可能的使用not null定义字段,尽量给出默认值。
4、尽量少用text类型,非要使用时候,考虑分表。
例子:使用BIGINT来存储IP地址,使用int来存储时间。
// 表的范式化和反范式化
——范式化:一般指的是第三范式,即不存在非关键字段对任意候选字段的传递函数依赖。这个将的有点概念,请看以下例子:
以下例子是不符合第三范式的:

——为什么不符合:
1、每一条数据都有分类和分类描述,而分类和分类描述其实是相同的,数据冗余了。
2、假设删除了饮料类型的所有商品,那么相当于饮料这个分类就消失了。
3、更新的时候,相当于要更新表上所有的分类描述。
——进行改进:拆分三张表。分别是:商品表,分类表,商品分类关联表。
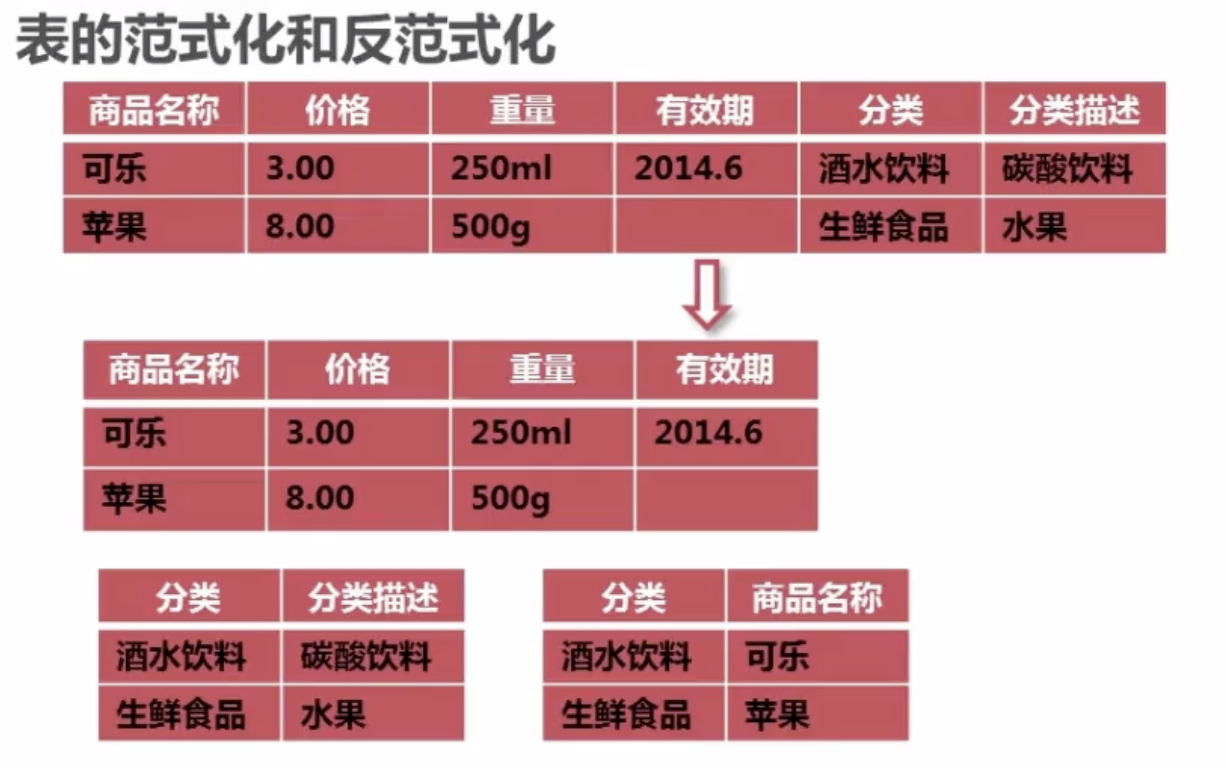
//反范式化
范式化是基本没有冗余的。但是有时候为了效率,而不用查询很多张表,为什么会允许适当冗余。
比如说,订单表里面,我们也会直接记录用户电话,姓名等。其实这些是在用户表里面可以查询的,但是这样得去多查询一张表。所以直接写入订单表会提升效率。
——————————垂直拆分——————————
原则(其实很灵活):把不经常的专门拆出来。比如用到text,这种大文本,基本查询的时候不会作为查询条件。
——————————水平拆分————————
//目的:解决数据条数过多的问题。
每一份表结构都是相同的。
方法:如何把数据平均分到N张表:对N取模。
//挑战:
1、跨分区表进行数据查询
2、统计及后台报表操作。
方法:前台使用拆分的表,后台使用汇总表。后台对时效性要求没那么高。
————————系统的优化————————
//操作系统优化:
1、增加TCP支持的队列数
2、减少断开连接时候,资源回收。
3、关闭防火墙/限制软件。
//mysql本身的优化:
1、配置文件的innodb_buffer_pool_size,如果只有innoDB表,非常推荐配置为总内存的75%
2、innodb_buffer_pool_instances,这个可以控制缓冲池个数,默认1个。可以设置4份或8份。
——还有很多的配置优化。不赘述。
//系统优化配置第三方工具:
1、去以下网址:https://tools.percona.com/wizard,输入数据库对应的信息。如内存,是否独立mysql服务器等等。
2、会发邮件给你建议的设置。
————————硬件的优化————————
特点:成本高,效果不明显
//单核更快CPU还是多核的cpu
单核更快的,因为mysql很多特性只会用到单核。(注意:最多不要超过32核,国外测试性能会下降。)
———————— MySQL自带的压力测试工具mysqlslap ————————
例子:测试100个并发线程,测试次数1次,自动生成SQL测试脚本,读、写、更新混合测试,自增长字段,测试引擎为innodb,共运行5000次查询:
mysqlslap -uroot -p123456 --concurrency=100 --iterations=1 --auto-generate-sql --auto-generate-sql-load-type=mixed --auto-generate-sql-add-autoincrement --engine=innodb --number-of-queries=5000 --debug-info
结果说明:
Benchmark
Running for engine innodb
Average number of seconds to run all queries: 1.211 seconds //100个客户端(并发)同时运行这些SQL语句平均要花1.211秒
Minimum number of seconds to run all queries: 1.211 seconds
Maximum number of seconds to run all queries: 1.211 seconds
Number of clients running queries: 100 //总共100个客户端(并发)运行这些sql查询
Average number of queries per client: 50 //每个客户端(并发)平均运行50次查询
————5000次 = 100个客户端*每个客户端平均运行50次
————占位符


 浙公网安备 33010602011771号
浙公网安备 33010602011771号