


有关string的处理[rev.1]
ToDo:有关string的处理
2009年12月22日
13:55
By viki
转载请注明出处
*.斜体字部分援引自MSDN
ASCII与UNICODE以及其他
字符串编码有3种编码模式,对应3种字符类型。
第一种编码类型是单子节字符集(single-byte character set or SBCS)。在这种编码模式下,所有的字符都只用一个字节表示。ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是SBCS。一个字节表示的0用来标志SBCS字符串的结束。
Unicode即UCS-2,用两个字节表示一个字符的编码方法。
实际上是Unicode标准中的UTF-16(两字节的Unicode,具体可以叫做utf16 little endian格式)。
Unicode是一种所有的字符都使用两个字节编码的编码模式。Unicode字符有时也被称作宽字符(Wide Character),因为它比单子节字符宽(使用了更多的存储空间)。注意,Unicode不能被看作MBCS。MBCS的独特之处在于它的字符使用不同长度的字节编码。Unicode字符串使用两个字节表示的0作为它的结束标志。
在Windows里,除了UNICODE(实际是UTF16,在Windows里叫WideChar),其他任何编码(什么GBK、JIS、BIG5、 UTF-8、ANSI)都叫多字节码(MultiByte)。
多字节字符集(multi-byte character set or MBCS)。一个MBCS编码包含一些一个字节长的字符,而另一些字符大于一个字节的长度。
用在Windows里的MBCS包含两种字符类型,单字节字符(single-byte characters)和双字节字符(double-byte characters)。由于Windows里使用的多字节字符绝大部分是两个字节长,所以MBCS常被用DBCS(double- byte character set or DBCS)代替。
在DBCS编码模式中,一些特定的值被保留用来表明他们是双字节字符的一部分。
例如,在Shift-JIS编码中(一个常用的日文编码模式),0x81-0x9f之间和0xe0-oxfc之间的值表示"这是一个双字节字符,下一个子节是这个字符的一部分。"这样的值被称作"leading bytes",他们都大于0x7f。跟随在一个leading byte子节后面的字节被称作"trail byte"。在DBCS中,trail byte可以是任意非0值。像SBCS一样,DBCS字符串的结束标志也是一个单字节表示的0。
MBCS字符串对应于char*,而UNICODE字符串对应于wchar_t*。
单个UNICODE字符占用2字节空间,而单个ANSI字符(ASCII编码)占用1字节。
针对128个ASCII码表里面的字符来说(英文字母,数字,半角标点,制表符等),相对应的UNICODE字符只是扩展了一字节的0.即
char x = 'a';//ASCII 0x61
对应的
wchara_t y = 'a';//UNICODE 0x0061 (内存中为 61 00)
由于这扩展的0,导致将一个含英文字母的UNICODE字符串直接拿来当char*用的时候,字符串会被截断。
128个ASCII字符之后的UNICODE编码见《Unicode编码表清单》
完整UNICODE码表见http://zh.wikibooks.org/w/index.php?title=Unicode&variant=zh-hans
汉字Unicode编码的区间为:0x4E00--0x9FA5
在把有汉字的UNICODE字串直接拿来当char*用的时候,字符串会显示一串乱码。
MSDN:Unicode 和 MBCS
为支持国际编程,启用了 Microsoft 基础类库 (MFC)、Visual C++ 的 C 运行时库和 Visual C++ 开发环境。它们:
- 在 Windows 2000(以前为 Windows NT)上提供对 Unicode 标准的支持。
Unicode 是为所有语言提供足够编码的 16 位字符编码。所有 ASCII 字符都作为“加宽”字符包含在 Unicode 中。
|
注意 |
|
Windows 95、Windows 98 或 Windows Millennium Edition 上不支持 Unicode 标准。 |
- 在所有平台上,支持称为双字节字符集 (DBCS) 的多字节字符集 (MBCS) 形式。
DBCS 字符由一个或两个字节构成。某些范围的字节留出用作“前导字节”。前导字节指定由它和后面的“尾字节”构成单个双字节宽字符。必须清楚哪些字节是前导字 节。在某个多字节字符集内,前导字节位于某个特定范围内,尾字节也一样。当这两种范围重叠时,可能需要计算上下文以确定某个给定的字节是用作前导字节还是 尾字节。 - 对简化 MBCS 编程的工具提供支持(MBCS 编程用于为国际市场编写的应用程序)。
当 在支持 MBCS 的 Windows 操作系统版本上运行时,Visual C++ 开发系统(包括集成的源代码编辑器、调试器和命令行工具)完全支持 MBCS。有关更多信息,请参见 Visual C++ 中的 MBCS 支持。
|
注意 |
|
在本文档中,MBCS 用于描述所有对多字节字符的非 Unicode 支持。在 Visual C++ 中,MBCS 始终是指 DBCS。不支持比两个字节宽的字符集。 |
按照定义,ASCII 字符集是所有多字节字符集的子集。在许多多字节字符集中,0x00 到 0x7F 范围内的每个字符都与 ASCII 字符集中具有相同值的字符相同。例如,在 ASCII 和 MBCS 字符串中,单字节 NULL 字符(“\0”)的值都是 0x00 并且指示终止空字符。
源文档 <http://msdn.microsoft.com/zh-cn/library/cwe8bzh0(VS.80).aspx>
为什么要使用Unicode
为国际市场开发应用程序的一个重要方面就是要适当地表示本地字符集。ASCII 字符集在 0x00 到 0x7F 的范围内定义字符。还有其他一些字符集(主要是欧洲字符),它们在 0x00 到 0x7F 的范围内定义与 ASCII 字符集相同的字符,还在 0x80 到 0xFF 的范围内定义了扩展字符集。因此,8 位的单字节字符集 (SBCS) 足以表示 ASCII 字符集以及许多欧洲语言的字符集。但是,一些非欧洲字符集(如日文汉字)包含许多单字节代码方案无法表示的字符,因此要求使用多字节字符集 (MBCS) 编码。
源文档 <http://msdn.microsoft.com/zh-cn/library/06b9yaeb(VS.80).aspx>
由于Windows内部是用UNICODE来实现的,所以程序里使用UNICODE是最高效。全球化的趋势也要求软件做到最容易扩展,适应不同地区的语言和文字,可以一次编码,到处运行。这就是为什么要使用Unicode的最根本原因。
(1)可以很容易地在不同语言之间进行数据交换。
(2)使你能够分配支持所有语言的单个二进制.exe文件或DLL文件。
(3)提高应用程序的运行效率。
Windows 2000是使用Unicode从头进行开发的,如果调用任何一个Windows函数并给它传递一个ANSI字符串,那么系统首先要将字符串转换成 Unicode,然后将Unicode字符串传递给操作系统。如果希望函数返回ANSI字符串,系统就会首先将Unicode字符串转换成ANSI字符串,然后将结果返回给你的应用程序。进行这些字符串的转换需要占用系统的时间和内存。通过从头开始用Unicode来开发应用程序,就能够使你的应用程序更加有效地运行。
Windows CE 本身就是使用Unicode的一种操作系统,完全不支持ANSI Windows函数
Windows 98 只支持ANSI,只能为ANSI开发应用程序。
Microsoft公司将COM从16位Windows转换成Win32时,公司决定需要字符串的所有COM接口方法都只能接受Unicode字符串。
程序字符集设置
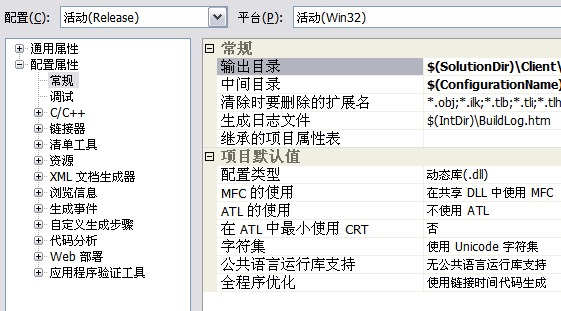
字符集设置有3个选项:
未设置:默认等效于多字节字符集
使用Unicode字符集:也叫宽字节字符集
使用多字节字符集:即MBCS
需要说明的是,多字节字符集并不是单纯的指ANSI。在Windows里,除了UNICODE(实际是UTF16,在Windows里叫WideChar),其他任何编码(什么GBK、JIS、BIG5、 UTF-8、ANSI)都叫多字节码(MultiByte)。
字符集在代码里的判别
#ifdef _UNICODE
#ifndef UNICODE
#define UNICODE // UNICODE is used by Windows headers
#endif
#endif
#ifdef UNICODE
#ifndef _UNICODE
#define _UNICODE // _UNICODE is used by C-runtime/MFC headers
#endif
#endif
#ifdef UNICODE//指的是图中字符集的设置,是否是UNICODE
#define TCHAR wchar_t
#else
#define TCHAR char
#endif
MSDN:支持多字节字符集 (MBCS)
多字节字符集 (MBCS) 是一种替代 Unicode 以支持无法用单字节表示的字符集(如日文和中文)的方法。为国际市场编程时应考虑使用 Unicode 或 MBCS,或使程序能够通过更改开关来生成支持两种字符集之一的程序。
最常见的 MBCS 实现是双字节字符集 (DBCS)。一般来说,Visual C++(尤其是 MFC)完全支持 DBCS。
有关示例,请参见 MFC 源代码文件。
对于语言使用大字符集的市场所使用的平台,代替 Unicode 的最佳方法是 MBCS。MFC 通过使用可国际化的数据类型和 C 运行时函数来支持 MBCS。您也应在自己的代码中这样操作。
在 MBCS 下,字符被编码为单字节或双字节。在双字节字符中,第一个字节(即前导字节)表示它和下一个字节将被解释为一个字符。第一个字节来自留作前导字节的代码范围。哪个范围的字节可以用作前导字节取决于所使用的代码页。例如,日文代码页 932 使用 0x81 到 0x9F 范围内的字节作为前导字节,而朝鲜语代码页 949 则使用其他范围的字节。
在 MBCS 编程中需考虑下列所有因素。
环 境中的 MBCS 字符
MBCS 字符可以出现在文件名和目录名等字符串中。
编 辑操作
MBCS 应用程序上的编辑操作应在字符上操作,而非在字节上操作。插入符号不应拆分字符,向右键应向右移动一个字符等。Delete 应删除一个字符;Undo 则应将字符重新插入。
字符串处理
在 使用 MBCS 的应用程序中,字符串处理引起特殊问题。两种宽度的字符混合在一个字符串中;因此必须记住检查前导字节。
运 行时库支持
C 运行时库和 MFC 支持单字节、MBCS 和 Unicode 编程。单字节字符串用 str 运行时函数族处理,MBCS 字符串用相应的 _mbs 函数处理,而 Unicode 字符串用相应的 wcs 函数处理。MFC 类成员函数的实现使用可移植运行时函数,这些可移植运行时函数在正常情况下映射到标准 str 函数族、MBCS 函数或 Unicode 函数,如“MBCS/Unicode 可移植性”中所述。
MBCS/Unicode 可移植性
使用 Tchar.h 头文件可以用同一个源生成单字节的 MBCS 应用程序和 Unicode 应用程序。Tchar.h 定义以 _tcs 为前缀的宏,这些宏根据相应的情况映射到 str、_mbs 或 wcs 函数。若要生成 MBCS,请定义 _MBCS 符号。若要生成 Unicode,请定义 _UNICODE 符号。默认情况下,为 MFC 应用程序定义的是 _MBCS。 有关更多信息,请参见 Tchar.h 中的一般文本映射。
|
注意 |
|
如果同时定义了 _UNICODE 和 _MBCS,则行为不确定。 |
Mbctype.h 和 Mbstring.h 头文件定义了 MBCS 特定的函数和宏,在某些情况下可能需要这些函数和宏。例如,_ismbblead 能告诉您某个字符串中的特定字节是否为前导字节。
为获得国际可移植性,使用 Unicode 或多字节字符集 (MBCS) 编码程序。
源文档 <http://msdn.microsoft.com/zh-cn/library/5z097dxa(VS.80).aspx>
MSDN:支持 Unicode
Unicode 是支持所有字符集(包括无法以单个字节表示的字符集)的规范。为国际市场编程时应考虑使用 Unicode 或多 字节字符集 (MBCS),或使程序能够通过更改开关来生成支持两种字符集之一的程序。
宽字符是双字节多语言字符代码。在当今的全球计算业内使用的大多数字符(包括技术符号和特殊的发布字符),都可以根据 Unicode 规范表示为宽字符形式。无法以 1 个宽字符表示的字符可以通过 Unicode 的代理项功能以 Unicode 对表示。由于每个宽字符总是以固定的 16 位大小表示,因此使用宽字符可以简化使用国际字符集进行的编程。
宽字符字符串表示为一个 wchar_t[] 数组并由 wchar_t* 指针指向它。可以通过用字母 L 作为字符的前缀将任何 ASCII 字符表示为宽字符形式。例如,L'\0' 是终止宽(16 位)NULL 字符。同样,可以通过用字母 L 作为 ASCII 字符串的前缀 (L"Hello") 将任何 ASCII 字符串表示为宽字符字符串形式。
通常,宽字符在内存中占用的空间比多字节字符多,但处理速度更快。另外,在多字节编码中一次只能表示一个区域设置,而世界上的所有字符集都同时以 Unicode 表示形式表示。
除数据库类外,MFC 框架完全支持 Unicode。(ODBC 不支持 Unicode。)MFC 通过始终使用可移植的宏来实现对 Unicode 的支持,如下表所示:
MFC 中的可移植数据类型
|
不可移植的数据类型 |
由该宏替换 |
|
char |
_TCHAR |
|
char*, LPSTR(Win32 数据类型) |
LPTSTR |
|
const char*, LPCSTR(Win32 数据类型) |
LPCTSTR |
CString 类使用 _TCHAR 作为基,并提供构造函数和运算符以方便转换。可以通过使用与处理 Windows ANSI 字符集相同的逻辑来编写大多数 Unicode 的字符串操作(只是基本操作单位是 16 位字符,而非 8 位字节)。与使用多字节字符集 (MBCS) 不同,不必(也不应)将 Unicode 字符视为两个不同的字节。
源文档 <http://msdn.microsoft.com/zh-cn/library/2dax2h36(VS.80).aspx>
A,W,T
win32编程里,ANSI的char*被定义为PSTR/LPSTR,而UNICODE的wchar_t*被定义为PWSTR/LPWSTR
带不带L仅仅是由于32位的指针和64位的指针的区别
凡是使用ANSI的函数,带A字母
使用UNICODE的函数,带W字母

TCHAR和LPTSTR
定义:
|
LPSTR |
char* |
|
LPCSTR |
const char* |
|
LPWSTR |
wchar_t* |
|
LPCWSTR |
const wchar_t* |
另外,为了编译工程时候自适应字符集,所以微软定义了TCHAR
#ifdef UNICODE
#define TCHAR wchar_t
#else
#define TCHAR char
#endif
于是有了
TCHAR* 在ANSI字符集设置下,对应于char*,LPSTR
TCHAR* 在UNICODE字符集设置下,对应于wchar_t*,LPWSTR
|
LPTSTR |
TCHAR* |
|
LPCTSTR |
const TCHAR* |
所以,带T的地方(包括_T宏),就意味着此处字符串的类型依赖于你的工程字符集设定。
关于_T,TEXT,L
L代表UNICODE字符串
_T则是自适应字符集
TEXT等同于_T
关于CString
CString最初出现在MFC里,现在ATL也已经使用CString
typedef CStringT< wchar_t, StrTraitATL< wchar_t > > CAtlStringW;
typedef CStringT< char, StrTraitATL< char > > CAtlStringA;
typedef CStringT< TCHAR, StrTraitATL< TCHAR > > CAtlString;
typedef CAtlStringW CStringW;
typedef CAtlStringA CStringA;
typedef CAtlString CString;
要记住的是,CString是自适应字符集设定的,即你的字符集是UNICODE的时候,你通过GetBuffer得到的缓冲区指针是UNICODE字符串指针(LPWSTR)。而多字节字符集(MBCS)的情况下,你将得到ANSI字符串指针(LPSTR)。
如果要使用特定字符集的CString,比如在UNICODE工程里面想使用ANSI的CString,那么用CStringA即可。同理,在ANSI工程里使用UNICODE的CString就使用CStringW
即
字符集是UNICODE的时候:
CString 即 CStringW,存储的字符属于Unicode
CStringA,存储的字符属于MBCS
字符集是多字节的时候:
CString 即 CStringA,存储的字符属于MBCS
CStringW,存储的字符属于Unicode
以上等价于说,CString里面的缓冲区指针其实是LPCTSTR类型的,使用LPCTSTR强制转换CString来得到缓冲区指针总是正确的。
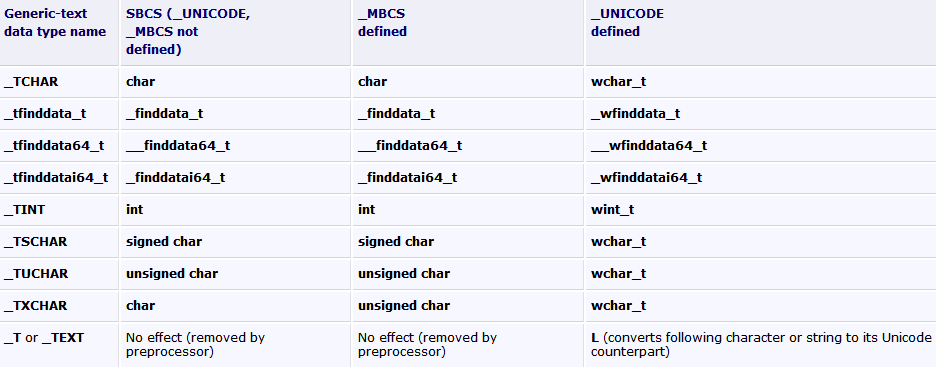
MSDN:Tchar.h 中的一般文本映射
为简化代码传输以方便国际使 用,Microsoft 运行时库为许多数据类型、例程和其他对象提供 Microsoft 特定的“一般文本”映射。您可以使用 Tchar.h 中定义的这些映射,根据使用 #define 语句定义的清单常数,编写可以为单字节、多字节或 Unicode 编译的一般代码。一般文本映射是与 ANSI 不兼容的 Microsoft 扩展。
使用 Tchar.h 可以从同一个源中生成单字节、MBCS 和 Unicode 应用程序。Tchar.h 定义以 _tcs 为前缀的宏,这些宏根据正确的预处理器定义映射到适当的 str、_mbs 或 wcs 函数。若要生成 MBCS,请定义 _MBCS 符号。若要生成 Unicode,请定义 _UNICODE 符号。若要生成单字节应用程序,请不进行任何定义(默认)。默认情况下,为 MFC 应用程序定义的是 _MBCS。
在 Tchar.h 中根据条件定义 _TCHAR 数据类型。如果为您的版本定义了 _UNICODE 符号,则 _TCHAR 被定义为 wchar_t;否则,对于单字节和 MBCS 版本,_TCHAR 被定义为 char。((wchar_t 是基本的 Unicode 宽字符数据类型,它是 8 位有符号 char 的 16 位对等项。)对于国际应用程序,使用以 _TCHAR(而 非字节)为单位进行操作的 _tcs 函数族。例如,_tcsncpy 复制 n 个 _TCHAR, 而不是 n 个字节。
由于某些 SBCS 字符串处理函数采用(有符号的)char* 参数,因此定义 _MBCS 时将产生类型不匹配的编译器警告。有三种方法避免此警告,按效率高低的顺序依次为:
- 在 Tchar.h 中使用类型安全内联函数 thunk。这是默认行为。
- 通过在命令行上定义 _MB_MAP_DIRECT, 在 Tchar.h 中使用直接宏。如果这样做,必须手动匹配类型。这是最快的方法,但不是类型安全的方法。
- 在 Tchar.h 中使用“类型安全”静态链接库函数 thunk。若要这样做,请在命令行上定义 _NO_INLINING 常数。这是最慢的方法,但却是类型安全性最高的方法。
一般 文本映射的预处理器指令
|
# define |
编译版本 |
示例 |
|
_UNICODE |
Unicode(宽 字符) |
_tcsrev 映射到 _wcsrev |
|
_MBCS |
多字节字符 |
_tcsrev 映射到 _mbsrev |
|
无(默认:既未定义 _UNICODE 也未定义 _MBCS) |
SBCS (ASCII) |
_tcsrev 映射到 strrev |
例如,如果在程序中定义了 _MBCS,则 Tchar.h 中定义的一般文本函数 _tcsrev 映射到 _mbsrev。或者如 果在程序中定义了 _UNICODE,则 _tcsrev 映射到 _wcsrev。否则 _tcsrev 映射到 strrev。在 Tchar.h 中还提供了其他数据类型映射以方便编程,但 _TCHAR 是最有用的。
一般文本数据类型映射
|
一般文本 数据类型名称 |
_UNICODE 和 _MBCS 未定义 |
_MBCS 已定义 |
_UNICODE 已定义 |
|
_TCHAR |
char |
char |
wchar_t |
|
_TINT |
int |
int |
wint_t |
|
_TSCHAR |
signed char |
signed char |
wchar_t |
|
_TUCHAR |
unsigned char |
unsigned char |
wchar_t |
|
_TXCHAR |
char |
unsigned char |
wchar_t |
|
_T 或 _TEXT |
无 效(由预处理器移除) |
无效(由预处理器移除) |
L(将后面 的字符或字符串转换成相应的 Unicode 形式) |
有关例程、 变量和其他对象的一般文本映射的完整列表,请参见“运行时库参考”中的一 般文本映射。
|
注意 |
|
Unicode 字符串有可能包含嵌入空字节,所以不要在 Unicode 字符串中使用 str 函数族。同样道理,不要在 MBCS(或 SBCS)字符串中使用 wcs 函数族。 |
下列代码片段阐释了有关映射到 MBCS、Unicode 和 SBCS 模型的 _TCHAR 和 _tcsrev 的用法。
_TCHAR *RetVal, *szString;
RetVal = _tcsrev(szString);
如果已定义 _MBCS,则预处理器将此片段映射到下列代码:
char *RetVal, *szString;
RetVal = _mbsrev(szString);
如果已定义 _UNICODE,则预处理器将此片段映射到下列代码:
wchar_t *RetVal, *szString;
RetVal = _wcsrev(szString);
如果既未定义 _MBCS 也未定义 _UNICODE,则预处理器将此片段映射到单字节 ASCII 代码:
char *RetVal, *szString;
RetVal = strrev(szString);
因此可以编写、维护和编译与三种字符集中任何一种的特定例程一起运行的单个源代码文件。
源文档 <http://msdn.microsoft.com/zh-cn/library/c426s321(VS.80).aspx>
OLE
OLECHAR和OLESTR
BSTR与CComBSTR
COM中的数据类型
stl里面的string与我们的tstring
STL的string是一个模板特化出来的类
typedef basic_string<char, char_traits<char>, allocator<char> > string
typedef basic_string<wchar_t, char_traits<wchar_t>, allocator<wchar_t> > wstring
对应的UNICODE的string是wstring
由于STL里面没定义自适应字符集的版本
所以仿照TCHAR我们可以定义如下
#ifdef UNICODE
#define tstringstream wstringstream
#define tstring wstring
#define tcout wcout
#define tcin wcin
#else
#define tstringstream stringstream
#define tstring string
#define tcout cout
#define tcin cin
#endif
这样的话,tstring就如同TCHAR一样神通广大了,可以兼容并包
并且如果工程里同时用到了CString和tstring的话
转换也是非常容易的
//CString => tstring
#define CS2TS(STR) tstring((LPCTSTR)(STR))
//tstring => CString
#define TS2CS(STR) CString((STR).c_str())
小结
要编写自适应字符集的程序,所有用""定义的字符串请加上_T宏。所有要用到字符串指针的地方请用
LPTSTR/LPCTSTR。
为了使用方便,可以使用CString,但是记住不要CString也是自适应字符集的,所以不要直接把CString拿来直接用char*或者wchar_t*进行强制转换操作,而应该和TCHAR*/LPTSTR/LPCTSTR等进行配合。
//正确
CString str = _T("Hello");
LPCTSTR p = (LPCTSTR)str;
LPCTSTR pbuffer = str.GetBuffer(0);
//错误
CString str = _T("Hello");
char* p = (char*)str;
函数
1.ANSI 操作函数以str开头 strcpy
2.Unicode 操作函数以wcs开头 wcscpy
3.MBCS 操作函数以_mbs开头 _mbscpy
4.ANSI/Unicode 操作函数以_tcs开头 _tcscpy(C运行期库)
5.ANSI/Unicode 操作函数以lstr开头 lstrcpy(Windows函数)
6.所有新的和未过时的函数在Windows2000中都同时拥有ANSI和 Unicode两个版本。ANSI版本函数结尾以A表示;Unicode版本函数结尾以W表示。
关于_t系列的函数
有了以上的前提,和对T字母的认识,那么可以知道,_t函数就是一个特定字符集的函数的代称(注意不是重载,只是一个define而已,宏替换之后就成了对应字符集的函数),无论你的工程字符集设置是UNICODE还是ANSI,_t函数都能正确地工作,而不用在每次更改了工程字符集设置的时候变更代码。
比如_tcslen
#ifdef _UNICODE
#define _tcslen strlen
#else
#define _tcslen wcslen
#endif
一般来说,_t函数的形式都是在原型函数前面加_t,但是也有例外
比如sprintf的_t,不是_tsprintf,而是_stprintf
lstr系列的函数基本等同于t系列函数,它们也是自适应ANSI/Unicode字符集的。
例外还要提一下_s系列函数,这个是C++库函数的安全版本,一般来说就是加了一个额外的参数,指定缓冲区大小。
一般来讲,还是最好体会到微软的这份用心,尽量使用_s版本。如果觉得懒得每个都改,并且能自己确保缓冲区不越界的话,那就
#pragma warning(disable:4996)
吧
完整的_t函数定义请参见
C:\Program Files\Microsoft Visual Studio 8\VC\include\tchar.h
字符串的比较
CompareString来实现。
标志含义
NORM_IGNORECASE 忽略字母的大小写
NORM_IGNOREKANATYPE 不区分平假名与片假名字符
NORM_IGNORENONSPACE 忽略无间隔字符
NORM_IGNORESYMBOLS 忽略符号
NORM_IGNOREWIDTH 不区分单字节字符与作为双字节字符的同一个字符
SORT_STRINGSORT 将标点符号作为普通符号来处理
字符串字符集的转换
1.ATL宏
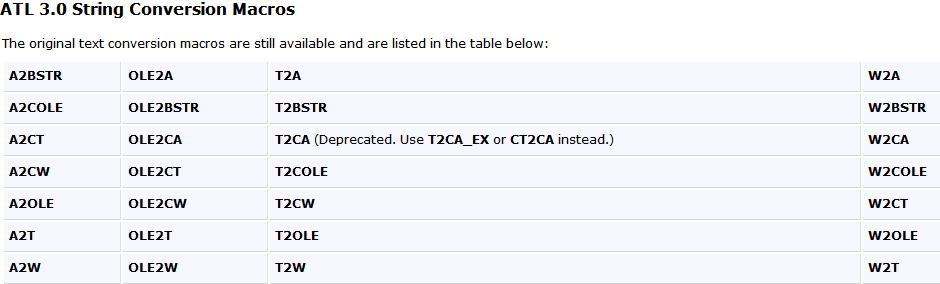
用这些函数之前使用USES_CONVERSION宏。
包含文件为afxpriv.h 或者 atlconv.h
ATL3和ATL7的转换函数是有区别的,详情参见MSDN
2.简单版本的字符集转换函数
size_t wcstombs( char *mbstr, const wchar_t *wcstr, size_t count );
size_t mbstowcs( wchar_t *wcstr, const char *mbstr, size_t count );
3.
int MultiByteToWideChar(
UINT CodePage,
DWORD dwFlags,
LPCSTR lpMultiByteStr,
int cbMultiByte,
LPWSTR lpWideCharStr,
int cchWideChar
);
int WideCharToMultiByte(
UINT CodePage,
DWORD dwFlags,
LPCWSTR lpWideCharStr,
int cchWideChar,
LPSTR lpMultiByteStr,
int cbMultiByte,
LPCSTR lpDefaultChar,
LPBOOL lpUsedDefaultChar
);
MultiByteToWideChar和WideCharToMultiByte这两个函数就是在这个之间转换的。
不过要注意只能在UNICODE和MultiByte之间转,不能在MultiByte内部互相转。
所有转换都是先转成utf16 little endian格式,这一步使用MultiByteToWideChar,然后再转成目的格式,这一步一般使用WideCharToMultiByte
// Unicode字符 转换成UTF-8编码
LPCTSTR UnicodeToUTF8Char(LPTSTR pOut,WCHAR wcText)
{
// 注意 WCHAR高低字的顺序,低字节在前,高字节在后
LPTSTR pchar = (LPTSTR)&wcText;
pOut[0] = (0xE0 | ((pchar[1] & 0xF0) >> 4));
pOut[1] = (0x80 | ((pchar[1] & 0x0F) << 2)) + ((pchar[0] & 0xC0) >> 6);
pOut[2] = (0x80 | (pchar[0] & 0x3F));
pOut[3] = '\0';
return pOut;
}
如何编写符合ANSI和Unicode的应用程序
先摘录网络上的一段描述,基本点到了关键:
(1)将文本串视为字符数组,而不是chars数组或字节数组。
(2)将通用数据类型(如TCHAR和PTSTR)用于文本字符和字符串。
(3)将显式数据类型(如BYTE和PBYTE)用于字节、字节指针和数据缓存。
(4)将TEXT宏用于原义字符和字符串。
(5)执行全局性替换(例如用PTSTR替换PSTR)。
(6)修改字符串运算问题。例如函数通常希望在字符中传递一个缓存的大小,而不是字节。这意味着不应该传递sizeof(szBuffer),而应该传递(sizeof(szBuffer)/sizeof(TCHAR)。另外,如果需要为字符串分配一个内存块,并且拥有该字符串中的字符数目,那么请记住要按字节来分配内存。这就是说,应该调用malloc(nCharacters *sizeof(TCHAR)),而不是调用malloc(nCharacters)。【3】
把工程从ANSI移植到UNICODE
第一步,设置工程字符集为UNICODE
第二步,将所有""定义的字符串用_T("")包起来【1】
第三步,替换char为TCHAR,char*为LPTSTR,const char*为LPCTSTR,注意这里不是全部搜索替换,个别情况要小心对待【2】
第四步,将个别特化的A版本函数替换为自适应版本
如MessageBoxA => MessageBox
第五步,把strcpy,strlen等替换为 _t版本,_tcscpy,_tcslen【3】
第六步,编译,仔细检查,针对每个error再处理。
把工程改造为自适应MBCS/UNICODE
第一步,将所有""定义的字符串用_T("")包起来【1】
第二步,替换char/wchar_t为TCHAR,char*/wchar_t*为LPTSTR,const char*/const wchar_t*为LPCTSTR,注意这里不是全部搜索替换,个别情况要小心对待【2】
第三步,将个别特化的A/W版本函数替换为自适应版本
如MessageBoxA => MessageBox
第四步,把strcpy,strlen,wcscpy,wcslen等替换为 _t版本,_tcscpy,_tcslen【3】
第五步,必要的地方进行ANSI和UNICODE的字符串转换
第六步,编译,仔细检查,针对每个error再处理。
注意
【1】特殊的函数
GetProcAddress只有char*版本,所以传入GetProcAddress的参数不能用_T("")
【2】上面第二步提到,某些情况下ANSI的类型还是不要替换为T版本了,为什么呢?
主要有下面的情况
第一,二进制文件读写时候//写文本文件为ANSI或者UNICODE格式将会另外讲到
第二,socket通信时候的send和recv等
其实socket的函数很多都是char*版本
比如
unsigned long PASCAL FAR inet_addr (IN const char FAR * cp);
char FAR * PASCAL FAR inet_ntoa (IN struct in_addr in);
struct hostent FAR * PASCAL FAR gethostbyaddr(IN const char FAR * addr, IN int len, IN int type);
struct hostent FAR * PASCAL FAR gethostbyname(IN const char FAR * name);
int PASCAL FAR gethostname (OUT char FAR * name,IN int namelen);
这个时候要么用ATL的宏T2A转成ANSI传入,要么自己写一个这几个函数的t版本在自己的函数里去转换,以备后用
unsigned long PASCAL FAR _tinet_addr (IN LPCTSTR FAR cp)
{
USES_CONVERSION;
return inet_addr(T2A(cp));
}
第三,内存操作的时候
其实以上这几种情况有很好的解决方案,就是把数据看做二进制流,统一用LPBYTE做参数(需要附带一个长度的参数),这样根本不用管字符串的字符集是什么,操作起来不容易出错
【3】拷贝函数和内存分配时候,特别要注意函数的“长度”参数!
一般来讲,和内存操作相关的长度是指字节长度,需要用sizeof来获取
而和字符串操作相关的是指的字符个数,一般是_tcslen获取(可能需要考虑到\0,那就要+1)
考虑
wchar_t s[] = L"some one";
TCHAR buffer[MAX_PATH];
int nlen = _tcslen(s);
_tcscpy_s(buffer,MAX_PATH,s);
memcpy_s(buffer,MAX_PATH,s,nlen*sizeof(TCHAR));
已使用 Microsoft OneNote 2010 创建
一个用于存放所有笔记和信息的位置
