G1
特点
G1采用分区的思路,用内存分为若干个大小相等的区域,每一块区域都可以为年轻代、老年代服务,因此可以动态的调整年轻代和老年代的Region个数
对比CMS:
- 和CMS一样,部分回收过程能与APP线程并发执行
- 整理空闲空间更快
- G1是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片
- G1的Stop The World(STW)更可控,G1在停顿时间上添加了预测机制,用户可以指定期望停顿时间
- HRegion存放超过Region大小一半的大对象,HRegion属于old区域,在分配前先检查initiating heap occupancy percent和the marking threshold, 如果超过的话,就启动global concurrent marking,为的是提早回收,防止 evacuation failures 和 full GC
- GC停顿时间更好预测,并且不会牺牲太多的性能
Region
Old\Eden\Survivor\Humongous(H直接分配到Old,防止反复拷贝移动,大小大于等于region一半的对象)
一个Region的大小可以通过参数-XX:G1HeapRegionSize设定

After the mark phase completes, G1 knows which regions are mostly empty(这里应该说的是被回收后的情况,感觉应该是垃圾比较多的集合). It collects in these regions first, which usually yields a large amount of free space. This is why this method of garbage collection is called Garbage-First.
G1 concentrates its collection and compaction activity on the areas of the heap that are likely to be full of reclaimable objects, that is, garbage
http://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
G1在疏散被标记为可回收的Regions时,将1个或多个Region的对象copy到一个region中,在这个过程中,压缩了和释放干净内存。
这个疏散操作是并行在多处理器上执行的,减少了停顿时间,增加了吞吐量。
H-obj在global concurrent marking阶段的cleanup 和 full GC阶段回收,
H-obj可以在新生代收集的时候被回收。
回收流程
G1提供了两种GC模式,Young GC和Mixed GC,两种都是完全Stop The World的,但是在mix gc前一般会提前进行global concurrent marking,但不是一比一的,这个阶段是部分并发执行的

GC root
- 虚拟机栈栈帧中的变量引用的对象,扫描栈时,hotspot使用oopmap加速扫描,而不用遍历每个栈帧
- 类的常量,如果类在,这个常量引用的对象就得在
- 静态变量引用的对象
- 本地方法栈中引用的对象
- classloader
Young GC
选定所有年轻代里的Region。通过控制年轻代的region个数,即年轻代内存大小,来控制young GC的时间开销。当Eden区无法申请新的内存时,开始Young GC
Young Gc和Mix GC是一个完全STW的过程,他和global concurrent marking是独立的,不过global concurrent marking的init marking是和young gc复用相同的代码,因此init marking一定会伴随一次young gc
并发标记流程
- 初始标记(STW事件) 普通的young gc会捎带这个步骤。标记 Survivor regions which may 引用了老年代 GC pause (young)(inital-mark)
- 并发标记阶段 找到所有在heap上的存活对象,这个过程可以被年轻代收集打断
- 重新标记 完成标记存活对象 in the heap,使用snapshot-at-the-beginning算法
- 清理(STW + Concurrent事件) 分为3小步:1.执行记录存活对象,并且完全的释放regions;2.刷洗rset;3.重置空的regions,返回给free list,最后这个操作是并发的
- 复制 将存活的对象copy到未使用的region,年轻代收集或mixed收集都可以做这个事情
Mixed GC
选定所有年轻代里的Region,外加根据global concurrentt marking统计得出收集收益高的若干老年代Region。在用户指定的开销目标范围内尽可能选择收益高的老年代Region。
触发时机:
当堆(总的堆)的使用比例占总Heap(整个堆,包括young)的比例超过InitiatingHeapOccupancyPercent,默认45之后,就会开始ConcurentMarking, 完成了Concurrent Marking后,G1会从Young GC切换到Mixed GC, 在Mixed GC中,G1可以增加若干个Old区域的Region到CSet中去回收,由于一次Mixed GC要考虑用户设置的MaxGcPauseMills,不一定会使老年代占用内存降低到阈值以下,所以可能会有间隔的发起多次Mixed Gc
Full GC
由上面的描述可知,Mixed GC不是full GC,它只能回收部分老年代的Region,如果mixed GC在并发阶段,无法跟上程序分配内存的速度,导致新的对象占满了所有空间,导致老年代填满无法继续进行Mixed GC,就会使用serial old GC(full GC)来收集整个GC heap。我们可以知道,G1是不提供单独full GC的,只提供了降级的单线程 old full gc,这次回收可能是很慢的。
SATB
全称是Snapshot-At-The-Beginning,是GC开始时活着的对象的一个快照。它是通过Root Tracing得到的,作用是维持并发GC的正确性。 那么它是怎么维持并发GC的正确性的呢?
根据三色标记算法,我们知道对象存在三种状态:
- 白:对象没有被标记到,标记阶段结束后,会被当做垃圾回收掉
- 灰:对象被标记了,但是它的field还没有被标记或标记完
- 黑:对象被标记了,且它的所有field也被标记完了
主要目标是解决并发标记阶段漏标的场景,发生漏标的条件:
- 1.app线程插入一个从黑色对象到白色对象的新引用
- 2.app线程删除了从灰色对象到白色对象的直接或间接引用
![]()
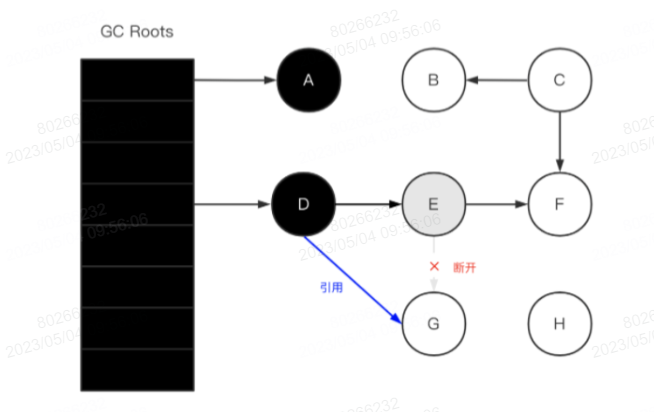
解决漏标的方法:
- 增量更新:关注新增的引用关系,把被更新的黑色或白色对象标记为灰色,打破条件1
- SATB:关注引用的删除,即对象在被赋值前,把老的引用对象记录下来,然后以这些对象为根重新标记一次,打破条件2,通过write barrier将旧引用记录下来

SATB也是有副作用的,如果被替换的白对象就是要被收集的垃圾,这次的标记会让它躲过GC,这就是float garbage。因为SATB的做法精度比较低,所以造成的float garbage也会比较多。
最佳实践
- 不要设置年轻代大小,它会使停顿时间配置无效;无法在需要时扩展年轻代空间
- XX:MaxGCPauseMillis=
,N不要设置成一个100%的目标,应该设置为能满足90%或以上的情况的目标,这是个目标,不能保证总是会被满足,所以设置的时间稍微小一点 - 防止浮动垃圾导致Full GC,多开点gc线程,-XX:ConcGCThreads=n;提前开始标记;多分配点heap内存给进程
参数说明
-XX:MaxGCPauseMillis:每次年轻代垃圾回收的最长时间(最大暂停时间), 如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值.
-XX:GCTimeRatio:设置垃圾回收时间占程序运行时间的百分比,设置吞吐量大小,它的值是一个 0-100 之间的整数。假设 GCTimeRatio 的值为 n,那么系统将花费不超过 1/(1+n) 的时间用于垃圾收集。
Card Table
在cms中,为了在并发标记阶段结束后,可以快速找到哪些card有引用更新,因此将老年代内存分为很多个Card,再使用Card Table维护每个card是否在并发标记阶段有引用变化,如果变化了,我们就说这个Card是Dirty的,这样可以提高重新标记阶段的速度

如果引用了发生了变化,则标记1。标记时,采用了bit位的方式标记,大大节省了空间,如byte=3的二进制位0000 0011,从右到左,第1位可以表示dirtyCard,第2位可以表示有引用年轻代,这样在minor gc时,也可以快速找到需要扫描的老年代card。(很多博文上说一个Card管理512Bytes的heap)
RSet
已记忆集合 Remember Set (RSet):一个谁引用了我的机制,记录引用了当前region的分区内对象的卡片索引,当要回收该分区时,通过扫描分区的RSet,来确定引用本分区内的对象是否存活,来确定本分区内的对象存活情况,如被引用的分区内对象全是垃圾了,则当前分区内的对象可能也是垃圾了。
Remembered Set是辅助GC过程的一种结构,典型的空间换时间工具,和Card Table有些类似。还有一种数据结构也是辅助GC的:Collection Set(CSet),它记录了GC要收集的Region集合,集合里的Region可以是任意年代的。在GC的时候,对于old->young和old->old的跨代对象引用,只要扫描对应的CSet中的RSet即可。
逻辑上说每个Region都有一个RSet,RSet记录了其他Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。而Card Table则是一种points-out(我引用了谁的对象)的结构,每个Card 覆盖一定范围的Heap(一般为512Bytes)。G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。 这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。
RSet究竟是怎么辅助GC的呢?在做YGC的时候,只需要选定young generation region的RSet作为根集,这些RSet记录了old->young的跨代引用,避免了扫描整个old generation。 而mixed gc的时候,old generation中记录了old->old的RSet,young->old的引用由扫描全部young generation region得到,这样也不用扫描全部old generation region。所以RSet的引入大大减少了GC的工作量。
RSET数据伪结构
[
{"region:[region`s card index]}...
]
rset记录了引用了当前region的其他region,并精确到了card
card table记录了当前region引用了哪些region
- CMS的Initial Marking和Remarking两个STW阶段在Heap区越来越大的情况下需要的时间越长,并且由于内存碎片,需要压缩的话也会造成较长停顿时间。所以需要一种高吞吐量的短暂停时间的收集器,而不管堆内存多大。如果没有Full GC,老年代的空间不会压缩整理。
- TLAB为线程本地分配缓冲区,它的目的为了使对象尽可能快的分配出来。如果对象在一个共享的空间中分配,我们需要采用一些同步机制来管理这些空间内的空闲空间指针。在Eden空间中,每一个线程都有一个固定的分区用于分配对象,即一个TLAB。分配对象时,线程之间不再需要进行任何的同步。
对TLAB空间中无法分配的对象,JVM会尝试在Eden空间中进行分配。如果Eden空间无法容纳该对象,就只能在老年代中进行分配空间。
日志
-XX:G1HeapRegionSize=n
诊断性配置
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:+PrintTenuringDistribution -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:ParallelGCThreads=4 -XX:+PrintGCApplicationConcurrentTime -XX:+PrintHeapAtGC -XX:+UnlockDiagnosticVMOptions -XX:+G1PrintRegionLivenessInfo -XX:MaxGCPauseMillis=200 -Xloggc:/export/Logs/gclogs
Java HotSpot(TM) 64-Bit Server VM (25.20-b23) for linux-amd64 JRE (1.8.0_20-b26), built on Jul 30 2014 13:13:52 by "java_re" with gcc 4.3.0 20080428 (Red Hat 4.3.0-8)
Memory: 4k page, physical 263727076k(113563148k free), swap 16777212k(16371860k free)
CommandLine flags: -XX:+DisableExplicitGC -XX:+G1PrintRegionLivenessInfo -XX:+HeapDumpOnOutOfMemoryError -XX:InitialHeapSize=2147483648 -XX:MaxHeapSize=2147483648 -XX:MaxMetaspaceSize=268435456 -XX:MetaspaceSize=134217728 -XX:ParallelGCThreads=4 -XX:+PrintGC -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution -XX:+UnlockDiagnosticVMOptions -XX:+UnlockExperimentalVMOptions -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC
2018-12-07T14:41:12.624+0800: 0.148: Application time: 0.0834746 seconds
2018-12-07T14:41:12.637+0800: 0.161: Application time: 0.0125164 seconds
2018-12-07T14:41:13.069+0800: 0.593: Application time: 0.4322354 seconds
2018-12-07T14:41:13.169+0800: 0.693: Application time: 0.0993848 seconds
2018-12-07T14:41:13.169+0800: 0.693: Application time: 0.0004720 seconds
2018-12-07T14:41:13.176+0800: 0.700: Application time: 0.0065544 seconds
2018-12-07T14:41:13.186+0800: 0.710: Application time: 0.0103469 seconds
2018-12-07T14:41:13.197+0800: 0.721: Application time: 0.0102892 seconds
2018-12-07T14:41:13.949+0800: 1.473: Application time: 0.7518253 seconds
2018-12-07T14:41:14.481+0800: 2.005: Application time: 0.5315235 seconds
{Heap before GC invocations=0 (full 0):
garbage-first heap total 2097152K, used 105472K [0x0000000080000000, 0x0000000100000000, 0x0000000100000000)
region size 1024K, 102 young (104448K), 0 survivors (0K) //年轻代一共102个,由于第一次回收,其中全是eden
Metaspace used 13539K, capacity 13806K, committed 13952K, reserved 1060864K
class space used 1471K, capacity 1563K, committed 1664K, reserved 1048576K
2018-12-07T14:41:14.481+0800: 2.005: [GC pause (G1 Evacuation Pause) (young) //撤空暂停,表示从eden copy到survior的产生的停顿,survior装不下就会gc
Desired survivor size 6815744 bytes, new threshold 15 (max 15)
, 0.0215033 secs]
[Parallel Time: 11.1 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 2005.0, Avg: 2005.0, Max: 2005.0, Diff: 0.0]
[Ext Root Scanning (ms): Min: 0.6, Avg: 0.8, Max: 1.2, Diff: 0.6, Sum: 3.3] //扫描非堆root用的时间,如classloaders,jni引用,jvm system roots....
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
[Code Root Scanning (ms): Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.3, Sum: 0.8] //从code调用来的root扫描时间 How long it took to scan the roots that came from the actual code: local vars, etc.
[Object Copy (ms): Min: 9.7, Avg: 9.9, Max: 10.2, Diff: 0.4, Sum: 39.8] //把存活的对象copy出被收集的regions的时间
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] //判断是否可以安全停止,没有更多的工作需要做的时间
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 11.0, Avg: 11.0, Max: 11.0, Diff: 0.0, Sum: 44.1] //工作线程一共工作了多次时间
[GC Worker End (ms): Min: 2016.0, Avg: 2016.0, Max: 2016.0, Diff: 0.0]
[Code Root Fixup: 0.7 ms]
[Code Root Migration: 2.1 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.2 ms]
[Other: 7.5 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 6.8 ms] //执行非强引用:清理他们或者不需要清理
[Ref Enq: 0.1 ms] //非强引用入队时间
[Redirty Cards: 0.0 ms]
[Free CSet: 0.2 ms]
[Eden: 102.0M(102.0M)->0.0B(89.0M) Survivors: 0.0B->13.0M Heap: 103.0M(2048.0M)->22.5M(2048.0M)]
Heap after GC invocations=1 (full 0):
garbage-first heap total 2097152K, used 23027K [0x0000000080000000, 0x0000000100000000, 0x0000000100000000)
region size 1024K, 13 young (13312K), 13 survivors (13312K)
Metaspace used 13539K, capacity 13806K, committed 13952K, reserved 1060864K
class space used 1471K, capacity 1563K, committed 1664K, reserved 1048576K
}
[Times: user=0.05 sys=0.01, real=0.03 secs]
https://liuzhengyang.github.io/2017/06/07/garbage-first-collector/
-XX:MetaspaceSize=2m -XX:MaxMetaspaceSize=256m -XX:+PrintTenuringDistribution -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:ParallelGCThreads=4 -XX:+PrintHeapAtGC
-XX:MaxMetaspaceSize=256m -XX:+PrintTenuringDistribution -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:ParallelGCThreads=4 -XX:+PrintHeapAtGC -Xloggc:/export/Logs/gclogs
2018-07-05T20:02:34.115+0800: 2.949: [GC pause (G1 Evacuation Pause) (young) 表示从eden copy到survior的停顿
-XX:MetaspaceSize=2m时,会有很多mixed gc;
[GC pause (G1 Evacuation Pause) (young)
[GC pause (G1 Evacuation Pause) (mixed)
-XX:MaxMetaspaceSize=16m 2018-07-16T11:43:08.780+0800: [GC pause (Metadata GC Threshold) (young) (initial-mark)
设置-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=8m 8m是一个不足的内存
2018-07-16T15:55:09.036+0800: [Full GC (Last ditch collection) 1718K->1718K(8192K), 0.0078003 secs]
[Eden: 0.0B(4096.0K)->0.0B(4096.0K) Survivors: 0.0B->0.0B Heap: 1718.9K(8192.0K)->1718.9K(8192.0K)], [Metaspace: 7989K->7989K(1056768K)]
Heap after GC invocations=1132 (full 809):
garbage-first heap total 8192K, used 1718K [0x0000000088e00000, 0x0000000088f00040, 0x0000000100000000)
region size 1024K, 0 young (0K), 0 survivors (0K)
Metaspace used 7989K, capacity 8134K, committed 8192K, reserved 1056768K
class space used 926K, capacity 990K, committed 1024K, reserved 1048576K
}
[Times: user=0.02 sys=0.00, real=0.01 secs]
- metaspace回收:classloader无效时才会回收,相比于jdk7的permgen空间,metaspace不是一块连续的内存空间,full gc时,会根据classloader是否能回收,来确定相关联的class能否回收,即使相关联的class由于重复创建导致的错误,并未正常给用户使用,并且已满足class回收条件(此时错误class并未引用classloader,在创建class后进行的约束检查中会失败),仍然不会被回收掉。而permgen空间在full gc时,会和老年代一起做可用性分析,如果无引用,会被回收掉,这也是很多应用升级成jdk8产生metaspace oom的原因:一些框架会由于weakhashmap等缓存结构在某些情况下key被回收,导致判断class是否已存在时失败,重复创建class,但又无法通过jvm的约束校验,此时生成了重复的class,在jdk7时会在full gc时被回收,在jdk8中metaspace在full gc时,却没有回收
启动参数示例
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:+PrintTenuringDistribution -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:ParallelGCThreads=4 -Xloggc:/export/Logs/gclogs
- 打印GC日志是很重要的,对性能基本没有影响
- 设置一个合理的GC线程数是很有必要的,特别是当前容器环境,jvm可能获取到的是物理机的处理器个数来作为gc线程个数的基准,而实际上容器只是一个2核4G内存的虚拟机,无疑,GC线程数过多,反而对cpu的利用率不高,并且多线程回收时造成无谓的cpu竞争、切换上下文。
诊断性配置
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:+PrintTenuringDistribution -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:ParallelGCThreads=4 -XX:+PrintGCApplicationConcurrentTime -XX:+PrintHeapAtGC -XX:+UnlockDiagnosticVMOptions -XX:+G1PrintRegionLivenessInfo -XX:MaxGCPauseMillis=200 -Xloggc:/export/Logs/gclogs
发起GC原因
Metadata GC Threshold:metaspace空间不能满足分配时触发,这个阶段不会清理软引用;
Last ditch collection:经过Metadata GC Threshold触发的full gc后还是不能满足条件,这个时候会触发再一次的gc cause为Last ditch collection的full gc,这次full gc会清理掉软引用。
-XX:InitiatingHeapOccupancyPercent 是老年代(old+H)/ 整个heap 的比率
不要设置年轻代大小-Xmn,
设置-XX:NewRatio=1或者2 后,启动时的用 gc变少了,gc平均耗时立即突破200ms,达到209ms,因此,设置NewRatio也会导致MaxGCPauseMillis失效
参考文章
oopmap \remeberset - >https://dsxwjhf.iteye.com/blog/2201685

 浙公网安备 33010602011771号
浙公网安备 33010602011771号